Author Archives: adriancolyer
Author Archives: adriancolyer
Amazon Aurora: on avoiding distributed consensus for I/Os, commits, and membership changes, Verbitski et al., SIGMOD’18
This is a follow-up to the paper we looked at earlier this week on the design of Amazon Aurora. I’m going to assume a level of background knowledge from that work and skip over the parts of this paper that recap those key points. What is new and interesting here are the details of how quorum membership changes are dealt with, the notion of heterogeneous quorum set members, and more detail on the use of consistency points and the redo log.
Managing quorum failures is complex. Traditional mechanisms cause I/O stalls while membership is being changed.
As you may recall though, Aurora is designed for a world with a constant background level of failure. So once a quorum member is suspected faulty we don’t want to have to wait to see if it comes back, but nor do we want throw away the benefits of all the state already present on a node that might in fact come back quite quickly. Aurora’s membership change protocol is designed to support continued processing during the change, to tolerate additional failures while Continue reading
Amazon Aurora: design considerations for high throughput cloud-native relational databases Verbitski et al., SIGMOD’17
Werner Vogels recently published a blog post describing Amazon Aurora as their fastest growing service ever. That post provides a high level overview of Aurora and then links to two SIGMOD papers for further details. Also of note is the recent announcement of Aurora serverless. So the plan for this week on The Morning Paper is to cover both of these Aurora papers and then look at Calvin, which underpins FaunaDB.
Say you’re AWS, and the task in hand is to take an existing relational database (MySQL) and retrofit it to work well in a cloud-native environment. Where do you start? What are the key design considerations and how can you accommodate them? These are the questions our first paper digs into. (Note that Aurora supports PostgreSQL as well these days).
Here’s the starting point:
In modern distributed cloud services, resilience and scalability are increasingly achieved by decoupling compute from storage and by replicating storage across multiple nodes. Doing so lets us handle operations such as replacing misbehaving or unreachable hosts, adding replicas, failing over from a writer to a replica, scaling the size Continue reading
Slim: OS kernel support for a low-overhead container overlay network Zhuo et al., NSDI’19
Container overlay networks rely on packet transformations, with each packet traversing the networking stack twice on its way from the sending container to the receiving container.

There are CPU, throughput, and latency overheads associated with those traversals.
In this paper, we ask whether we can design and implement a container overlay network, where packets go through the OS kernel’s network stack only once. This requires us to remove packet transformation from the overlay network’s data-plane. Instead, we implement network virtualization by manipulating connection-level metadata at connection setup time, saving CPU cycles and reducing packet latency.
Slim comes with some caveats: it requires a kernel module for secure deployment, has longer connection establishment times, doesn’t fit with packet-based network policies, and only handles TCP traffic. For UDP, ICMP, and for its own service discovery, it also relies on an existing container overlay network (Weave Net). But for longer lasting connections managed using connection-based network policies it delivers some impressive results:
Understanding lifecycle management complexity of datacenter topologies Zhang et al., NSDI’19
There has been plenty of interesting research on network topologies for datacenters, with Clos-like tree topologies and Expander based graph topologies both shown to scale using widely deployed hardware. This research tends to focus on performance properties such as throughput and latency, together with resilience to failures. Important as these are, note that they’re also what’s right in front of you as a designer, and relatively easy to measure. The great thing about today’s paper is that the authors look beneath the surface to consider the less visible but still very important “lifecycle management” implications of topology design. In networking, this translates into how easy it is to physically deploy the network, and how easy it to subsequently expand. They find a way to quantify the associated lifecycle management costs, and then use this to help drive the design of a new class of topologies, called FatClique.
… we show that existing topology classes have low lifecycle management complexity by some measures, but not by others. Motivated by this, we design a new class of topologies, FatClique, that, while being performance-equivalent to existing topologies, is comparable to, or Continue reading
Datacenter RPCs can be general and fast Kalia et al., NSDI’19
We’ve seen a lot of exciting work exploiting combinations of RDMA, FPGAs, and programmable network switches in the quest for high performance distributed systems. I’m as guilty as anyone for getting excited about all of that. The wonderful thing about today’s paper, for which Kalia et al. won a best paper award at NSDI this year, is that it shows in many cases we don’t actually need to take on that extra complexity. Or to put it another way, it seriously raises the bar for when we should.
eRPC (efficient RPC) is a new general-purpose remote procedure call (RPC) library that offers performance comparable to specialized systems, while running on commodity CPUs in traditional datacenter networks based on either lossy Ethernet or lossless fabrics… We port a production grade implementation of Raft state machine replication to eRPC without modifying the core Raft source code. We achieve 5.5 µs of replication latency on lossy Ethernet, which is faster than or comparable to specialized replication systems that use programmable switches, FPGAs, or RDMA.
eRPC just needs good old UDP. Lossy Ethernet is just fine (no need for fancy lossness Continue reading
Exploiting commutativity for practical fast replication Park & Ousterhout, NSDI’19
I’m really impressed with this work. The authors give us a practical-to-implement enhancement to replication schemes (e.g., as used in primary-backup systems) that offers a signification performance boost. I’m expecting to see this picked up and rolled-out in real-world systems as word spreads. At a high level, CURP works by dividing execution into periods of commutative operation where ordering does not matter, punctuated by full syncs whenever commutativity would break.
The Consistent Unordered Replication Protocol (CURP) allows clients to replicate requests that have not yet been ordered, as long as they are commutative. This strategy allows most operations to complete in 1 RTT (the same as an unreplicated system).
When integrated with RAMCloud write latency was improved by ~2x, and write throughput by 4x. Which is impressive given that RAMCloud isn’t exactly hanging around in the first place! When integrated with Redis, CURP was able to add durability and consistency while keeping similar performance to non-durable Redis.
CURP can be easily applied to most existing systems using primary-backup replication. Changes required by CURP are not intrusive, and it works with any kind of backup mechanism (e.g., Continue reading
Cloud programming simplified: a Berkeley view on serverless computing Jonas et al., arXiv 2019
With thanks to Eoin Brazil who first pointed this paper out to me via Twitter….
Ten years ago Berkeley released the ‘Berkeley view of cloud computing’ paper, predicting that cloud use would accelerate. Today’s paper choice is billed as its logical successor: it predicts that the use of serverless computing will accelerate. More precisely:
… we predict that serverless computing will grow to dominate the future of cloud computing.
The acknowledgements thank reviewers from Google, Amazon, and Microsoft among others, so it’s reasonable to assume the major cloud providers have had at least some input to the views presented here. The discussion is quite high level, and at points it has the feel of a PR piece for Berkeley (there’s even a cute collective author email address: serverlessview at berkeley.edu), but there’s enough of interest in its 35 pages for us to get our teeth into…
The basic structure is as follows. First we get the obligatory attempt at defining serverless, together a discussion of why it matters. Then the authors look at some of the current limitations (cf. ‘Serverless Continue reading
Efficient synchronisation of state-based CRDTs Enes et al., arXiv’18
CRDTs are a great example of consistency as logical monotonicity. They come in two main variations:
State-based CRDTs look attractive therefore, but over time as the state grows sending the full state every time quickly becomes expensive. That’s where Delta-based CRDTs come in. These send only the delta to the state needed to reconstruct the full state.
Delta-based CRDTs… define delta-mutators that return a delta (
), typically much smaller than the full state of the replica, to be merged with the local state. The same
buffer, to be periodically propagated to remote replicas. Delta-based CRDTs have been adopted in industry as part of the Akka Distributed Data framework and IPFS.
So far so good, but Continue reading
A generalised solution to distributed consensus Howard & Mortier, arXiv’19
This is a draft paper that Heidi Howard recently shared with the world via Twitter, and here’s the accompanying blog post. It caught my eye for promising a generalised solution to the consensus problem, and also for using reasoning over immutable state to get there. The state maintained at each server is monotonic.
Consensus is a notoriously hard problem, and Howard has been deep in the space for several years now. See for example the 2016 paper on Flexible Paxos. The quest for the holy grail here is to find a unifying and easily understandable protocol that can be instantiated in different configurations allowing different trade-offs to be made according to the situation.
This paper re-examines the problem of distributed consensus with the aim of improving performance and understanding. We proceed as follows. Once we have defined the problem of consensus, we propose a generalised solution to consensus that uses only immutable state to enable more intuitive reasoning about correctness. We subsequently prove that both Paxos and Fast Paxos are instances of our generalised consensus algorithm and thus show that both algorithms are conservative in their approach.
Keeping CALM: when distributed consistency is easy Hellerstein & Alvaro, arXiv 2019
The CALM conjecture (and later theorem) was first introduced to the world in a 2010 keynote talk at PODS. Behind its simple formulation there’s a deep lesson to be learned with the power to create ripples through our industry akin to the influence of the CAP theorem. It rewards time spent ruminating on the implications. Therefore I was delighted to see this paper from Hellerstein & Alvaro providing a fresh and very approachable look at CALM that gives us an excuse to do exactly that. All we need now is a catchy name for a movement! A CALM system is a NoCo system, “No Coordination.”
When it comes to high performing scalable distributed systems, coordination is a killer. It’s the dominant term in the Universal Scalability Law. When we can avoid or reduce the need for coordination things tend to get simpler and faster. See for example Coordination avoidance in database systems, and more recently the amazing performance of Anna which gives a two-orders-of-magnitude speed-up through coordination elimination. So we should avoid coordination whenever we can.
So far so good, but when exactly can we avoid Continue reading
Efficient large-scale fleet management via multi-agent deep reinforcement learning Lin et al., KDD’18
A couple of weeks ago we looked at a survey paper covering approaches to dynamic, stochastic, vehicle routing problems (DSVRPs). At the end of the write-up I mentioned that I couldn’t help wondering about an end-to-end deep learning based approach to learning policy as an alternative to the hand-crafted algorithms. Lenz Belzner popped up on Twitter to point me at today’s paper choice, which investigates exactly that.
The particular variation of DSVRP studied here is grounded in a ride-sharing platform with real data provided by Didi Chuxing covering four weeks of vehicle locations and trajectories, and customer orders, in the city of Chengdu. With the area covered by 504 hexagonal grid cells, the centres of which are 1.2km apart, we’re looking at around 475 square kilometers. The goal is to reposition vehicles in the fleet at each time step (10 minute intervals) so as to maximise the GMV (total value of all orders) on the platform. We’re not given information on the number of drivers, passengers, and orders in the data set (nor on the actual GMV, all results are relative), but Chengdu has a Continue reading
Large scale GAN training for high fidelity natural image synthesis Brock et al., ICLR’19
Ian Goodfellow’s tweets showing x years of progress on GAN image generation really bring home how fast things are improving. For example, here’s 4.5 years worth of progress on face generation:
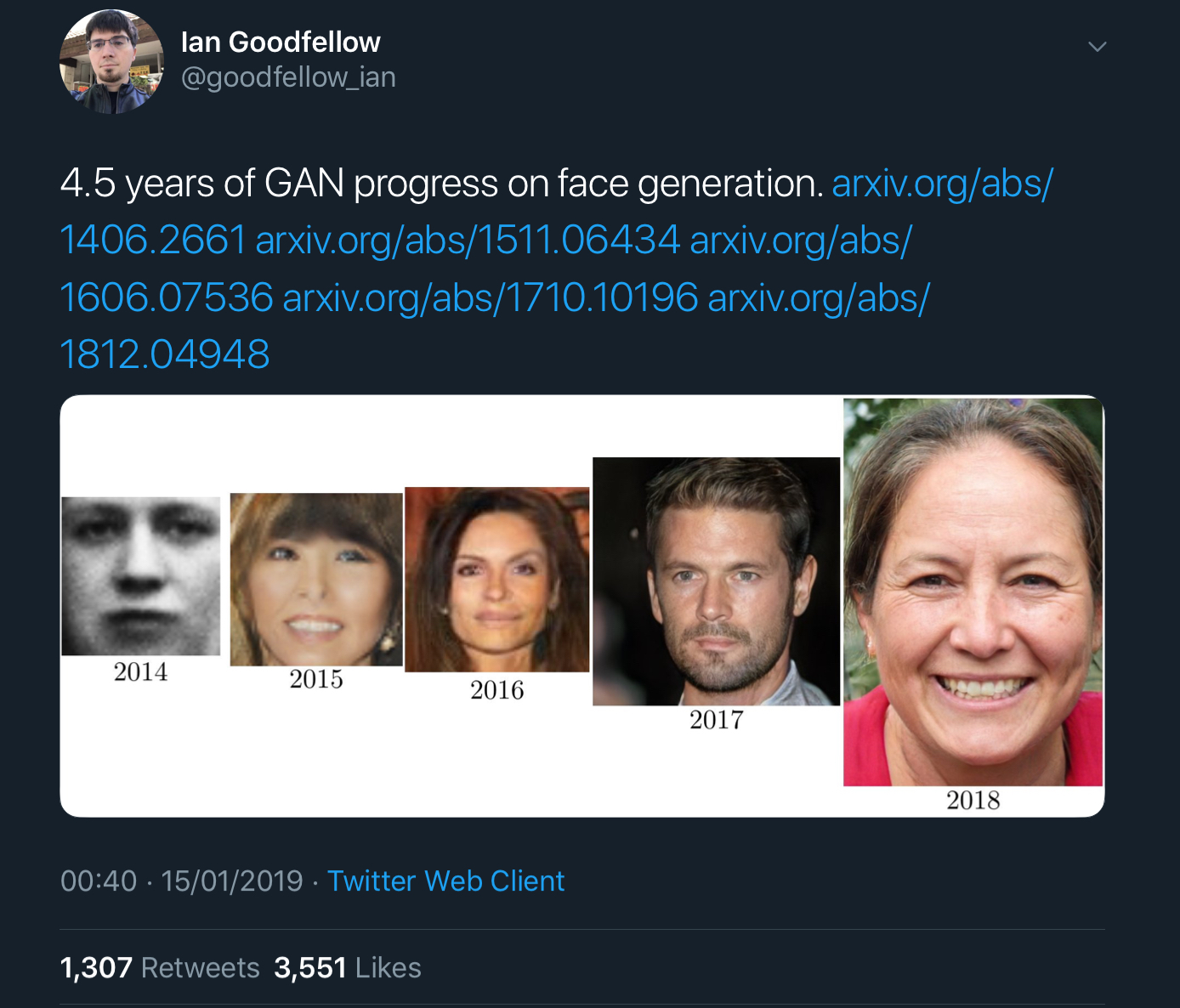
And here we have just two years of progress on class-conditional image generation:

In the case of the faces, that’s a GAN trained just to generate images of faces. The class-conditional GANs are a single network trained to generate images of lots of different object classes. In addition to feeding it some noise (random input), you also feed the generator network the class of image you’d like it to generate (condition it).
I was drawn to this paper to try and find out what’s behind the stunning rate of progress. The large-scale GANs (can I say LS-GAN?) trained here set a new state-of-the-art in class-conditional image synthesis. Here are some images generated at 512×512 resolution.

The class-conditional problem is of course much harder than the single image class problem, so we should expect the images to be not quite so stunning as the pictures of faces. In fact, using a measure called Continue reading
GAN dissection: visualizing and understanding generative adversarial networks Bau et al., arXiv’18
Earlier this week we looked at visualisations to aid understanding and interpretation of RNNs, today’s paper choice gives us a fascinating look at what happens inside a GAN (generative adversarial network). In addition to the paper, the code is available on GitHub and video demonstrations can be found on the project home page.
We’re interested in GANs that generate images.
To a human observer, a well-trained GAN appears to have learned facts about the objects in the image: for example, a door can appear on a building but not on a tree. We wish to understand how a GAN represents such a structure. Do the objects emerge as pure pixel patterns without any explicit representation of objects such as doors and trees, or does the GAN contain internal variables that correspond to the objects that humans perceive? If the GAN does contain variables for doors and trees, do those variables cause the generation of those objects, or do they merely correlate? How are relationships between objects represented?
The basis for the study is three variants of Progressive GANs trained on LSUN scene datasets. To understand what’s going Continue reading
Understanding hidden memories of recurrent neural networks Ming et al., VAST’17
Last week we looked at CORALS, winner of round 9 of the Yelp dataset challenge. Today’s paper choice was a winner in round 10.
We’re used to visualisations of CNNs, which give interpretations of what is being learned in the hidden layers. But the inner workings of Recurrent Neural Networks (RNNs) have remained something of a mystery. RNNvis is a tool for visualising and exploring RNN models. Just as we have IDEs for regular application development, you can imagine a class of IMDEs (Interactive Model Development Environments) emerging that combine data and pipeline versioning and management, training, and interactive model exploration and visualisation tools.
Despite their impressive performances, RNNs are. still “black boxes” that are difficult for humans to understand… the lack of understanding of how RNN models work internally with their memories has limited researchers’ ability to introduce further improvements. A recent study also emphasized the importance of interpretability of machine learning models in building user’s trust: if users do not trust the model, they will not use it.
The focus of RNNvis is RNNs used for NLP tasks. Where we’re headed is an interactive visualisation Continue reading
CORALS: who are my potential new customers? Tapping into the wisdom of customers’ decisions Li et al., WSDM’19
The authors of this paper won round 9 of the Yelp dataset challenge for their work. The goal is to find new target customers for local businesses by mining location-based checkins of users, user preferences, and online reviews.
Location-based social networks attract millions of users to share their social friendship and their locations via check-ins. For example, an average of 142 million users check in at local businesses via Yelp every month. Foursquare and 55 million monthly active users and 8 million daily check-ins on the Swarm application. Facebook Local, powered by 70 million businesses, facilitates the discovery of local events and places for over one billion active daily users.
(And of course these are just the explicit check-ins, location tracking has proved tempting to many businesses without requiring explicit user checkin actions. For example: Facebook is tracking your phone’s location… , Google’s location history is still recording your every move…, Google tracks your movements, like it or not, …).
Check-ins give us a location history. Preference for a given business will be influenced by the proximity of that Continue reading
Protecting user privacy: an approach for untraceable web browsing history and unambiguous user profiles Beigi et al., WSDM’19
Maybe you’re reading this post online at The Morning Paper, and you came here by clicking a link in your Twitter feed because you follow my paper write-up announcements there. It might even be that you fairly frequently visit paper write-ups on The Morning Paper. And perhaps there are several other people you follow who also post links that appear in your Twitter feed, and occasionally you click on those links too. Given your ‘anonymous’ browsing history I could probably infer that you’re likely to be one of the 20K+ wonderful people with a wide-ranging interest in computer science and the concentration powers needed to follow longer write-ups that follow me on Twitter. You’re awesome, thank you! Tying other links in the browsing history to other social profiles that have promoted them, we might be able to work out who else our mystery browser probably follows on social media. It won’t be long before you’ve been re-identified from your browsing history. And that means everything else in that history can be tied back to you too. (See ‘De-anonymizing web Continue reading
The why and how of nonnegative matrix factorization Gillis, arXiv 2014 from: ‘Regularization, Optimization, Kernels, and Support Vector Machines.’
Last week we looked at the paper ‘Beyond news content,’ which made heavy use of nonnegative matrix factorisation. Today we’ll be looking at that technique in a little more detail. As the name suggests, ‘The Why and How of Nonnegative matrix factorisation’ describes both why NMF is interesting (the intuition for how it works), and how to compute an NMF. I’m mostly interested in the intuition (and also out of my depth for some of the how!), but I’ll give you a sketch of the implementation approaches.
Nonnegative matrix factorization (NMF) has become a widely used tool for the analysis of high dimensional data as it automatically extracts sparse and meaningful features from a set of nonnegative data vectors.
NMF was first introduced by Paatero andTapper in 1994, and popularised in a article by Lee and Seung in 1999. Since then, the number of publications referencing the technique has grown rapidly:

NMF approximates a matrix 

For the discussion in this paper, we’ll assume that
A survey on dynamic and stochastic vehicle routing problems Ritzinger et al., International Journal of Production Research
It’s been a while since we last looked at an overview of dynamic vehicle routing problems: that was back in 2014 (See ‘Dynamic vehicle routing, pickup, and delivery problems’). That paper has fond memories for me, I looked at it while doing diligence for our investment in Deliveroo, and my how they’ve grown since then! With vehicle routing problems popping up in a number of interesting businesses, it’s time to take another look! Today’s paper choice is a more recent survey, focusing in on DSVRP problems.
So what exactly is a DSVRP problem? The VRP part stands for vehicle routing problems, typically you have a fleet of vehicles, and you need to use them to make a set of deliveries from point A to point B. How you assign pick-ups and deliveries to vehicles, and the routes those vehicles take, is the the VRP problem. Historically the VRP problem would be solved statically (we know up front the set of vehicles, pick-up and drop-off locations, etc.). Much more interesting (and much more realistic for many companies) is when we Continue reading
Beyond news contents: the role of social context for fake news detection Shu et al., WSDM’19
Today we’re looking at a more general fake news problem: detecting fake news that is being spread on a social network. Forgetting the computer science angle for a minute, it seems intuitive to me that some important factors here might be:
Therefore I’m a little surprised to read in the introduction that:
The majority of existing detection algorithms focus on finding clues from the news content, which are generally not effective because fake news is often intentionally written to mislead users by mimicking true news.
(The related work section does however discuss several works that include social context.).
So instead of Continue reading
ExFaKT: a framework for explaining facts over knowledge graphs and text Gad-Elrab et al., WSDM’19
Last week we took a look at Graph Neural Networks for learning with structured representations. Another kind of graph of interest for learning and inference is the knowledge graph.
Knowledge Graphs (KGs) are large collections of factual triples of the form
(SPO) about people, companies, places etc.
Today’s paper choice focuses on the topical area of fact-checking : how do we know whether a candidate fact, which might for example be harvested from a news article or social media post, is likely to be true? For the first generation of knowledge graphs, fact checking was performed manually by human reviewers, but this clearly doesn’t scale to the volume of information published daily. Automated fact checking methods typically produce a numerical score (probability the fact is true), but these scores are hard to understand and justify without a corresponding explanation.
To better support KG curators in deciding the correctness of candidate facts, we propose a novel framework for finding semantically related evidence in Web sources and the underlying KG, and for computing human—comprehensible explanations for facts. We refer to our framework as ExFaKT (Ex Continue reading
 ), typically much smaller than the full state of the replica, to be merged with the local state. The same
), typically much smaller than the full state of the replica, to be merged with the local state. The same  buffer, to be periodically propagated to remote replicas. Delta-based CRDTs have been adopted in industry as part of the Akka Distributed Data framework and IPFS.
buffer, to be periodically propagated to remote replicas. Delta-based CRDTs have been adopted in industry as part of the Akka Distributed Data framework and IPFS. (SPO) about people, companies, places etc.
(SPO) about people, companies, places etc.