Author Archives: pedrormarques
Author Archives: pedrormarques
One of the most interesting recent developments in natural language processing is the T5 family of language models. These are transformer based sequence-to-sequence models trained on multiple different tasks. The main insight is that different tasks provide a broader context for tokens and help the model statistically approximate the natural language context of words.
Tasks can be specified by providing an input context, often with a “command” prefix and then predicting an output sequence. This google AI blog article contains an excellent description of how multiple tasks are specified.
Naturally, these models are attractive to anyone working on NLP. The drawback, however, is that they are large and require very significant computational resources, beyond the resources of most developers desktop machines. Fortunately, google makes their Colaboratory platform free to use (with some resource limitations). It is the ideal platform to experiment with this family of models in order to see how their perform on a specific application.
As I decided to do so, for a text-classification problem, I had to pierce together information from a few different sources and try a few different approaches. I decided to put together a mini tutorial of how to fine-tune a T5 model Continue reading
One of the most interesting recent developments in natural language processing is the T5 family of language models. These are transformer based sequence-to-sequence models trained on multiple different tasks. The main insight is that different tasks provide a broader context for tokens and help the model statistically approximate the natural language context of words.
Tasks can be specified by providing an input context, often with a “command” prefix and then predicting an output sequence. This google AI blog article contains an excellent description of how multiple tasks are specified.
Naturally, these models are attractive to anyone working on NLP. The drawback, however, is that they are large and require very significant computational resources, beyond the resources of most developers desktop machines. Fortunately, google makes their Colaboratory platform free to use (with some resource limitations). It is the ideal platform to experiment with this family of models in order to see how their perform on a specific application.
As I decided to do so, for a text-classification problem, I had to pierce together information from a few different sources and try a few different approaches. I decided to put together a mini tutorial of how to fine-tune a T5 model Continue reading
A recurring pattern in software architecture is the need to trigger a process or workflow that is implemented across multiple microservices and then report to the user the results when the process completes.
In a previous project, I faced this issue when building a SaaS application in the Intelligent Document Processing (IDP) space. The application was supposed to take a collection of scanned pages, split it in documents, and for each document perform several document understanding tasks. There is a mix of per-page-bundle, per-page and per-document processing steps.
Given the desire to develop each step independently and be able to scale the processing independently (e.g. page OCR consumes more resources than other tasks) I designed a system around a message bus (RabbitMQ) and individual workers that pull requests from message queues.
Unfortunately there aren’t a whole lot of easy to use solutions available for this type of design. Googling for “rabbitmq workflow orchestration” the most helpful link I get is for an article that recommends the use of BPMN for this type of design. That is rather centered in the Java ecosystem. For my use case I needed something that worked well in python and would be preferably language Continue reading
A recurring pattern in software architecture is the need to trigger a process or workflow that is implemented across multiple microservices and then report to the user the results when the process completes.
In a previous project, I faced this issue when building a SaaS application in the Intelligent Document Processing (IDP) space. The application was supposed to take a collection of scanned pages, split it in documents, and for each document perform several document understanding tasks. There is a mix of per-page-bundle, per-page and per-document processing steps.
Given the desire to develop each step independently and be able to scale the processing independently (e.g. page OCR consumes more resources than other tasks) I designed a system around a message bus (RabbitMQ) and individual workers that pull requests from message queues.
Unfortunately there aren’t a whole lot of easy to use solutions available for this type of design. Googling for “rabbitmq workflow orchestration” the most helpful link I get is for an article that recommends the use of BPMN for this type of design. That is rather centered in the Java ecosystem. For my use case I needed something that worked well in python and would be preferably language Continue reading
As a fun project, I recently built a web app to play checkers online against the computer. This post tries to outline the methodology I used. If you want to checkout the results, I would encourage you to try the web link above, change the difficulty level to ‘hard’ and play a round against the computer. You will be playing against a very simple neural network model that is, as far as I can tell, reasonably effective.
The standard approach to developing a game AI for something like board games is the “MiniMax” algorithm. Implementing “MiniMax” for a game like checkers is a relatively simple task; one needs to components:
There are multiple sets of possible rules for the game of checkers. I used the “Spanish draughts” rule set popular in Portugal: men move forward only; flying kings and mandatory moves on a 8×8 board. The minimax algorithm is independent of the particular rule-set used.
The scorer function must be able to look at a given player position and determine a score. Continue reading
As a fun project, I recently built a web app to play checkers online against the computer. This post tries to outline the methodology I used. If you want to checkout the results, I would encourage you to try the web link above, change the difficulty level to ‘hard’ and play a round against the computer. You will be playing against a very simple neural network model that is, as far as I can tell, reasonably effective.
The standard approach to developing a game AI for something like board games is the “MiniMax” algorithm. Implementing “MiniMax” for a game like checkers is a relatively simple task; one needs to components:
There are multiple sets of possible rules for the game of checkers. I used the “Spanish draughts” rule set popular in Portugal: men move forward only; flying kings and mandatory moves on a 8×8 board. The minimax algorithm is independent of the particular rule-set used.
The scorer function must be able to look at a given player position and determine a score. Continue reading
When running a micro-services style application in a public cloud, one of the problems to solve is how to provide access to debug information. At Laserlike, we run our application stack on GKE. Most of the stack consists of golang Pods that run an HTTP listener that serves /debug and /metrics handlers.
For metrics scrapping we use prometheus; and grafana for visualization. Our grafana server is nodePort service behind a GCE Load Balancer which uses oauth2 based authentication for access. This still leaves a gap in terms of access to the pod debug information such as /debug/vars or /debug/pprof.
In order to address this gap, we created a simple HTTP proxy for kubernetes services and endpoints. We deploy this proxy behind a oauth2 authenticator which is then exposed via an external load balancer.
The service proxy uses the kubernetes client library in order to consume annotations on the service objects. For example, the following annotation, instructs the service proxy to expose the debug port of the endpoints of the specified service:
metadata:
annotations:
k8s-svc-proxy.local/endpoint-port: "8080"
The landing page on the proxy then displays a set of endpoints:
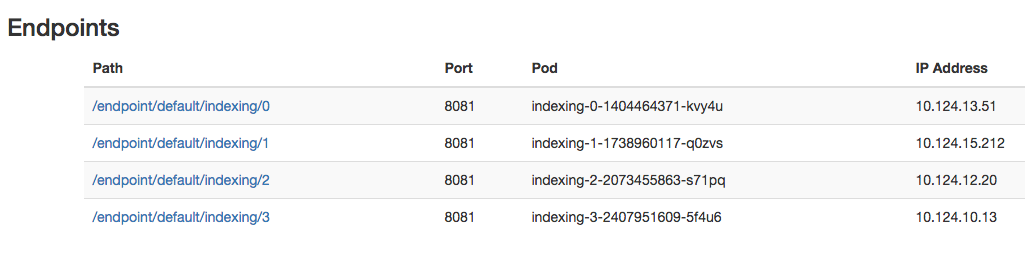
When running a micro-services style application in a public cloud, one of the problems to solve is how to provide access to debug information. At Laserlike, we run our application stack on GKE. Most of the stack consists of golang Pods that run an HTTP listener that serves /debug and /metrics handlers.
For metrics scrapping we use prometheus; and grafana for visualization. Our grafana server is nodePort service behind a GCE Load Balancer which uses oauth2 based authentication for access. This still leaves a gap in terms of access to the pod debug information such as /debug/vars or /debug/pprof.
In order to address this gap, we created a simple HTTP proxy for kubernetes services and endpoints. We deploy this proxy behind a oauth2 authenticator which is then exposed via an external load balancer.
The service proxy uses the kubernetes client library in order to consume annotations on the service objects. For example, the following annotation, instructs the service proxy to expose the debug port of the endpoints of the specified service:
metadata:
annotations:
k8s-svc-proxy.local/endpoint-port: "8080"
The landing page on the proxy then displays a set of endpoints:


For anyone interested in running a testbed with Kubernetes and OpenContrail on AWS i managed to boil down the install steps to the minimum:
The setup script will:
Please let me know if you run into any glitch… the “setup.sh” script can be rerun multiple times (the ansible provisioning is designed to be idempotent).
Next, I need to wrap this up with a Jenkins CI pipeline. And build permutations for:
The fun never stops !

One of the key decisions in designing a compute infrastructure is how to handle networking.
For platforms that are designed to deliver applications, it is now common knowledge that application developers need a platform that can execute and manage containers (rather than VMs).
When it comes to networking, however, the choices are less clear. In what scenarios are designs based on single layer preferable vs. overlay networks ?
The answer to this question is not a simplistic one based on “encapsulation overhead”; while there are overlay networking projects that do exhibit poor performance, production ready solutions such as OpenContrail have performance characteristics on both throughput and PPS similar to the Linux kernel bridge implementation. When not using an overlay, it is still necessary to use an internal bridge to demux the container virtual-ethernet interface pairs.
The key aspect to consider is operational complexity!
From a bottoms-up perspective, one can build an argument that a network design with no encapsulation that simply uses an address prefix per host (e.g. a /22) provides the simplest possible solution to operate. And that is indeed the case if one assumes that discovery, failover and authentication can be handled completely at the “session” layer (OSI model).
I’m familiar with a particular compute infrastructure where this is the Continue reading
In this post we walk through the steps required to install a 2 node cluster running kubernetes that uses opencontrail as the network provider. In addition to the 2 compute nodes, we use a master and a gateway node. The master runs both the kubernetes api server and scheduler as well as the opencontrail configuration management and control plane.
OpenContrail implements an overlay network using standards based network protocols:
This means that, in production environments, it is possible to use existing network appliances from multiple vendors that can serve as the gateway between the un-encapsulated network (a.k.a. underlay) and the network overlay. However for the purposes of a test cluster we will use an extra node (the gateway) whose job is to provide access between the underlay and overlay networks.
For this exercise, I decided to use my MacBookPro which has 16G of RAM. However all the tools used are supported on Linux also; it should be relativly simple to reproduce the same steps on a Linux machine or on a cloud such as AWS or GCE.
The first step Continue reading
I’ve been struggling a bit to understand how to use inventory, role variables and facts in the playbooks i’ve been working on (mostly around provisioning opencontrail on top of kubernetes/openshift-origin). I finally came up with a model that made sense to me. This is probably well understood by everyone else but i couldn’t quite grok it until i worked out the following example.
User configuration options should be set:
– In group_vars/all.yml for settings that affect all hosts;
– In the inventory file, for host and group variables;
As in this example:
It is useful to establish a convention for variables that are specific to the deployment (e.g. user settable variables). In this case i’m using flag_<var> as a convention for deployment specific variables.
Most of these would have defaults. In order to set the defaults, the playbook defines a role variable (flag_user_<var> in this example). The playbook role then uses flag_user_<var> rather than the original flag_<var>.
Role variables can use jinja template logic operations as well as filters. The most common operation is to use a <code>default</code> filter as in the example playbook bellow. But more complex logic can be built using {%if <expression> %}{% endif Continue reading
OpenContrail can be used to provide network micro-segmentation to kubernetes, providing both network isolation as well as the ability to attach a pod to a network that may have endpoints in using different technologies (e.g. bare-metal servers on VLANs or OpenStack VMs).
This post describes how the current prototype works and how packets flow between pods. For illustration purposes we will focus on 2 tiers of the k8petstore example on kubernetes: the web frontend and the redis-master tier that the frontend uses as a data store.
The OpenContrail integration works without modifications to the kubernetes code base (as off v1.0.0 RC2). An additional daemon, by the name of kube-network-manager, is started on the master. The kubelets are executed with the option: “–network_plugin=opencontrail”, which instructs the kubelet to execute the command:
/usr/libexec/kubernetes/kubelet-plugins/net/exec/opencontrail/opencontrail. The source code for both the network-manager and the kubelet plugin are publicly available.
When using OpenContrail as the network implementation the kube-proxy process is disabled and all pod connectivity is implemented via the OpenContrail vrouter module which implements an overlay network using MPLS over UDP as encapsulation. OpenContrail uses a standards based control plane in order to distribute the mapping between endpoint (i.e. pod) and Continue reading
OpenContrail allows the user to specify a static route with a next-hop of an instance interface. The route is advertised within the virtual-network that the interface is associated with. This script can be used to manipulate the static routes configured on an interface.
I wrote it in order to setup a cluster in which overlay networks are used hierarchically. The bare-metal nodes are running OpenStack using OpenContrail as the neutron plugin; a set of OpenStack VMs are running a second overlay network using OpenContrail which kubernetes as the compute scheduler.
In order to provide external access for the kubernetes cluster, one of the kubernetes node VMs was configured as an OpenContrail software gateway.
This is easily achievable by editing /etc/contrail/contrail-vrouter-agent.conf to include the following snippet:
# Name of the routing_instance for which the gateway is being configured routing_instance=default-domain:default-project:Public:Public # Gateway interface name interface=vgw # Virtual network ip blocks for which gateway service is required. Each IP # block is represented as ip/prefix. Multiple IP blocks are represented by # separating each with a space ip_blocks=10.1.4.0/24
The vow interface can then be created via the following sequence of shell commands:
ip link add vgw type vhost ip Continue reading
I’ve been working over the last couple of weeks in integrating OpenContrail as a networking implementation for Kubernetes and got to the point where i ‘ve a prototype working with a multi-tier application example.
Kubernetes provides 3 basic constructs used in deploying applications:
A Pod is a container environment that can execute one or more applications; each Pod executes on a host as one (typically) or more Docker processes sharing the same environment (including networking). A Replication Controller (RC) is a collection of Pods with the same execution characteristics. RCs ensure that the specified number of replicas are executing for a given Pod template.
Services are collections of Pods that are consumable as a service. Through a single IP end point, typically load-balanced to multiple backends.
Kubernetes comes with several application deployment examples. For the purpose of prototyping, I decided to use the K8PetStore example. It creates a 4-tier example: load-generator, frontend, redis-master and redis-slave. Each of these tiers, except for the redis-master) can be deployed as multiple instances.
With OpenContrail, we decided to create a new daemon that listens to the kubernetes API using the kubernetes controller framework. This daemon creates virtual networks on demand, for each Continue reading
When the Open Daylight project started, it was clear that the intent on the part of IBM and RedHat was to replicate the success of Linux.
Linux is today a de-facto monopoly on server operating systems. It is monetized by Redhat (and in smaller part by Canonical) and it essentially allowed the traditional I.T. companies such as IBM, Oracle, HP to neutralize Sun microsystems which was in the late 90s, early naughts, the platform of choice for Web application deployment.
Whether the initial target of these companies was Sun or Microsoft, the fact is that, by coming together in support of a open source project that had previously been an hobby of university students they inaugurated the era of corporate open source.
This was followed by a set of successful startup companies that used open source as a way to both create a much deeper engagement with their customers and of marketing their products. By originating and curating an open source project, a startup can achieve a much greater reach than before. The open source product becomes a free trial license, later monetized in
production deployments that typically need support. Open source also provides a way to engage with Continue reading
Recently, I’ve heard several people suggest that the advent of IPv6 changes the requirements for data-center virtual network solutions. For instance, making the claim that network overlays are no longer necessary. The assumption made is that once an instance has a globally unique IP address that all requirements are met.
In my view, this analysis fails in two dimensions:
Neither of these assumptions hold when examined in detail.
While there are IaaS use cases of users that just want to be able to fire up a single virtual-machine and use it as a personal server, the most interesting use case for IaaS or PaaS platforms is to deploy applications.
These applications, serve content for a specific virtual IP address registered in the DNS and/or global load-balancers; that doesn’t mean that this virtual IP should be associated with any specific instance. There is layer of load-balancing that maps the virtual IP into the specific instance(s) service the content. Typically this is done with a load-balancer in proxy mode.
As an aside, enabling IPv6 in the load-balancer Continue reading
Looking back at 2014, it feels like a lot of progress was achieved in the past year in both the cloud infrastructure and NFV infrastructure markets. Some of that progress is technical, some is in terms of increased understanding of the key business and technical aspects. This post is my attempt to capture some changes I’ve observed from my particular vantage point.
This December marks the second anniversary of the acquisition of Contrail Systems by Juniper Networks. In the last year the Contrail team managed to deploy the Contrail network virtualization solution in several marquee customers; to solidify the image of the OpenContrail project as a production-ready implementation of the AWS VPC functionality; but, probably, more importantly to help transform attitudes at Juniper (and in the industry) regarding NFV.
In the late 90s and early naughts, the carrier wireline business went through a significant change with the deployment of provider managed virtual networks (using BGP L3VPN). From a business perspective, this was essentially outsourcing the network connectivity for distributed enterprises. Instead of a mesh of frame relay circuits managed by the enterprise; carriers provide a managed service that includes the circuit but also the IP connectivity. This is a service Continue reading
I had the opportunity to attend last week’s OpenStack summit. With 4500 attendees, it clearly demonstrates that OpenStack is the clear mindshare leader for organizations interested in building cloud infrastructure. It is also significant to note that approximately half of the participants came from Europe which demonstrates that the “Old World” is not far behind the “New” when it comes to the desire to adopt cloud technology.
Parallel to the summit, the OpenContrail community organized both a user group meeting as well as an Advisory Board meeting. Both of these events ended up focusing the discussion in operations. While the user group presentations typically started with a description of the goals of the project most of the discussion in the room focused on topics such as automating and documenting deployment, provisioning, software upgrades and troubleshooting.
As a software developer, one often tends to focus on expanding the feature set. In both of these events there was a clear message that the user community takes reliability, scale and performance as the main reasons they adopted OpenContrail but is grappling with operational aspects. This means in one hand that testing, specifically unit testing of each component, is absolutly key is maintaining users Continue reading