Author Archives: Rakesh M
Author Archives: Rakesh M
< MEDIUM: https://towardsaws.com/aws-advanced-networking-task-statement-1-3-c457fa0ed893 >
Ref: https://aws.amazon.com/elasticloadbalancing/
Why Elastic Load Balancer?
CLB — Classic Load Balancer
– AWS Recommends ALB today instead of CLB
– Intended for EC2 instances which are built in EC2-Classic Network
– Layer 4 or Layer 7 Load Balancing
– Provides SSL Offloading and IPv6 support for Classic Networks
ALB — Application Load Balancer
Why Elastic Load Balancer?
Note: This requires the purchase of a wireless router which is capable of running a Wireguard package in this case it’s Slate-Plus GL-A1300 and I do not have any affiliate or ads program with them, I simply liked it for its effectiveness and low cost.

For one reason many of us want a VPN server which does decent encryption but won’t charge us a lot of money, in some cases, it can be done free of cost and in others for not want us to install a variety of software which messes up with internal client routing and also against some of the IT-Policies, even if it’s a browser-based plugin.
Wireguard: https://www.wireguard.com/ — VPN Software, Software-based encryption, extremely fast and light-weight.
GL-A1300 Slate-Plus — Wireless Router with support for Wireguard which is not a feature in many of the current market routers, had OpenWrt as the installed software.
The GL-A1300 Slate Plus wireless VPN encrypted travel router comes packed with features that will make your life easier while travelling. Here are just a few of the most important:
A few weeks ago, I set up a bird feeder and used it to capture bird images, the classifier itself was not that accurate but was doing a decent job, what I have realised is that not every time we end up with highly accurate on-board edge classification especially while learning how to implement them.
So after a few weeks, there were a lot of images some of them sure enough had birds while some of them were taken in Pitch Dark and am not even sure what made the classifier figure out a birdie in the snapshot from the camera.
Now for me in order to make an Image, I have to rely on a re-classifier doing the job for me, initially, I thought I will write a lambda-based classifier as a learning experiment, but then I thought it was a one-time process every 6 months or so, so I went ahead with a managed service option and in this case, its AWS Rekognition, which is quite amazing.
https://aws.amazon.com/rekognition/
Code Snippet used for Classification
import os
import concurrent.futures
import boto3
def detect_birds(image_path):
# Configure AWS credentials and region
session Continue reading
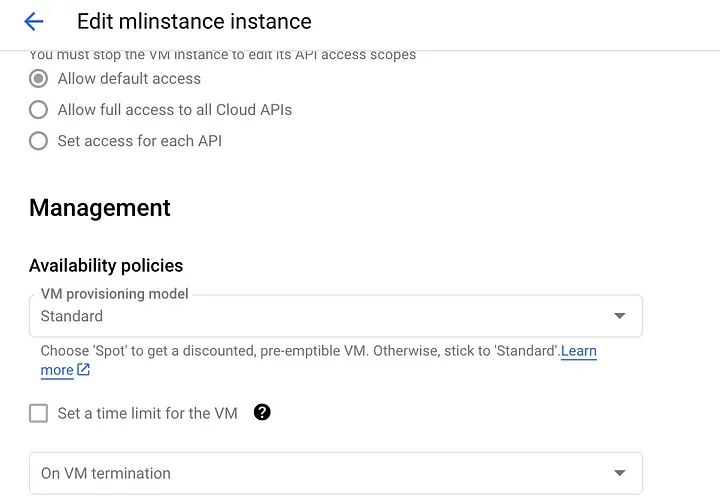
Note: One of the important tips for lab environments is to set an auto-shutdown timer, below is one such setting in GCP
I have been working on a few hosted environments which include AWS Sagemaker Notebook instances, Google Cloud Colab, Gradient (Paperspace) etc and all of them are really good and needed monthly subscriptions, I decided to have my own GPU server instance which can be personalized and I get charged on a granular basis.
Installing it is not easy, first, you need to find a cloud-computing instance which has GPU support enabled, AWS and GCP are straightforward in this section as the selection is really easy.
Let’s break this into 3 stages
For a change, I will be using GCP in this case from my usual choice of AWS here.
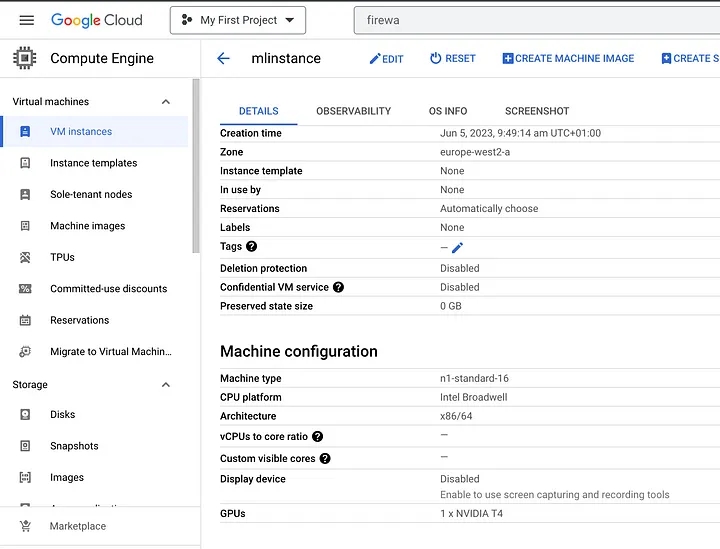
Choose GPU alongside the Instance
Generic Guidelines — https://cloud.google.com/deep-learning-vm/docs/cloud-marketplace
rakesh@instance-1:~$ sudo apt install jupyter-notebook # Step1: generate the file by typing this line in console jupyter notebook Continue reading
While browsing through various ways to get my AI-enabled bird camera setup, I came across Nvidia Jetson Nano, there are varied versions of this product and availability are limited, I Am in Europe and ordered the Nano Developer kit from Amazon US, shipping was fast with a good amount of inbound tax as well.
https://developer.nvidia.com/embedded/jetson-nano-developer-kit — is the one I have purchased while both new and old versions are available.
Unboxing Video :
Initial Impressions and disadvantages:
< MEDIUM: https://aws.plainenglish.io/image-search-with-bing-ml-ai-fast-ai-and-aws-sage-maker-61fae1647c >
If you have heard about awesome AI course that fast.ai offers which is free of charge then you should definitely checkout. https://course.fast.ai/ is where you will find out all the details.
Course takes a very hands on approach and anyone can write and bring up their ML model in under 2 hours of the course. As a part of any image classification one of the basic requirements is to have number of images which is often referred to as Dataset and this Dataset is split into Test/Train/Validation for the model training.
For some of the easier examples, you can rely on search engine to give you those images for you, previously fast.ai used Microsoft’s bing.com for image search but later they replaced it with DDG (DuckDuckGo). while DDG is really nice I had throttle issues and some of the packages were outdated and hard to read.
So, I have re-written the same image-search Python function which uses Microsoft’s bing.com search engine
What are Pre-req:
Procedure to generate keys

Image sent to Telegram
I have a small greenhouse which was in the pipeline for over 2 years and I finally decided to build it. Whoever is in gardening will agree that anything grows better in the greenhouse at least it appears to be so.
Now, the initial impression is all good but I have plans to learn and explore both the plant sides of things and also some using some part of image analysis for a predictive action, for all that to happen I need a camera and a picture to start with.
The reason I choose to go with Event-bridge Pipe is to put this more into practice and from there on connect more Lambda and step-functions for future expansion of the project.

Architecture Diagram for sending Images Continue reading
< MEDIUM: https://raaki-88.medium.com/home-automation-finally-roller-curtains-and-nightmares-b8ef1fc473d9 >
Am a fan and enthusiast of home automation, tried various things in the past and now settled with few things which I would like to share.
. . .
Lets get to the Curtain Rollers — So for these here is the catch, I have a remote for these and thats about it, nothing more nothing less, My ideas were mostly around having network connectivity and manipulating them.
< MEDIUM: https://raaki-88.medium.com/enabling-nested-virtualisation-on-google-cloud-platform-instance-7f80f3120834 >
Important Excerpt from the below page.
https://cloud.google.com/compute/docs/instances/nested-virtualization/overview
You must run Linux-based OSes that can run QEMU; you can’t use Windows Server images.
You can’t use E2, N2D, or N1 with attached GPUs, and A2 machine types.
You must use Intel Haswell or later processors; AMD processors are not supported. If the default processor for a zone is Sandy Bridge or Ivy Bridge, change the minimum CPU selection for the VMs in that zone to Intel Haswell or later. For information about the processors supported in each zone, see Available regions and zones.
Though there are many use cases, I will speak from a networking standpoint. Let us say you need to do some sort of lab based on popular vMX Juniper or Cisco or any other vendor, if you have a bare metal instance, you have the ability to access the virtualised CPU cores and allocate them to the Qemu which will be the underlying emulator.
Almost by default most of the cloud providers will disable access to VT-x because of various reasons and some instances are not capable of supporting this by default. So either choose a custom instance with Continue reading
< MEDIUM: https://raaki-88.medium.com/buffer-overflow-linux-process-stack-creation-and-i-d6f28b0239dc >
Process and what happens during process creation have been discussed in this post previously — https://medium.com/@raaki-88/linux-process-what-happens-under-the-hood-49e8bcf6173c
Now, let’s understand what is buffer overflow:
A buffer overflow is a type of software vulnerability that occurs when a program tries to store more data in a buffer (a temporary storage area) than it can hold. This can cause the program to overwrite adjacent memory locations, potentially leading to the execution of malicious code or the crashing of the program. Buffer overflow attacks are a common method used by hackers to gain unauthorized access to a system.
Generally, C and C++ languages are more vulnerable to Buffer Overflow while programming languages like Python and Go have implementations which protect stack.
I have written the program in Python but had to use underlying C functionality to achieve similarly.
#!/usr/bin/python3
import ctypes
import pdb
buffer = ctypes.create_string_buffer(8)
ctypes.memmove(buffer, b"AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA",1000)
print('end of the program')
This is a very simple implementation where we created a buffer which can hold 8 bytes of memory, next we will create a new object which moves from one block of the memory to another but with a newer size, which will Continue reading
One biggest problem with my google drive is that it’s flooded with a lot of documents, images and everything which seems really important during that instant of time with names which are almost impossible to search later.
I tried various Google APIs and Python programs with Oauth2.0 and its integration is, not something easy and needs tinkering for the OAuth consent page.
I wanted something easier, a workflow when I scan documents in the scanner-pro app on IPAD/iPhone and upload them to storage it should then be organised with certain rules which can be easily searchable and also listable. What I mean by listable is that I need some sort of Google Sheet integration which can just enter the filename and date once it’s uploaded to S3.
When there is an excel sheet even if the search is available it gives me so much pleasure to fire up pandas and analyse or search for it, just makes me happy
Note: I am a Paid user of Zapier and using S3 is a premium app, Am not an advertiser for Zapier in any way, I found the service useful
Moving on, here is the workflow
With so much focus on serverless in Re-Invent 2022 and the advantages of Step Functions, I have started to transform some of my code from Lambda to Step Functions.
Step-Function was hard until I figured out how data values can be mapped for input and how data can be passed and transformed between Lambda functions. I have made a small attempt for someone who is starting in step functions for understanding the various steps involved.
Basically, Step Functions can be used to construct business logic and Lambda can be used to transform the data instead of transporting with Lambda-Invokes from Lambda Functions.
Let’s take the following example
I have step_function_1 which has the requirement to invoke another lambda if my_var is 1 else do not do anything.
This is a simple if-else logic followed by the lambda-invoke function
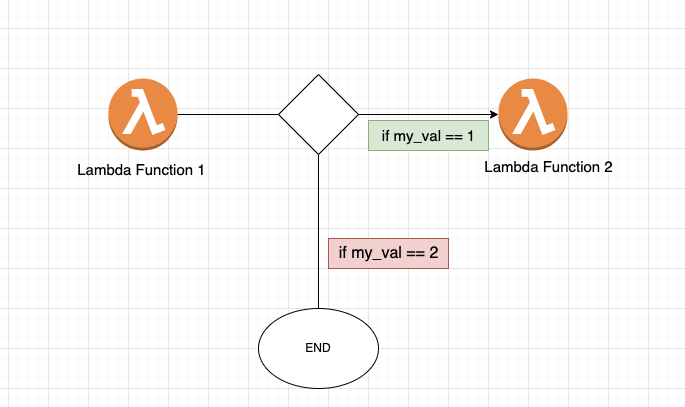
Now, the power of step-functions will come into play to write these conditional and also pass data from Lambda to Other making it super scalable for editing in future and all of the code will seem very logical and pictorial, best part is this can be designed instead of learning Amazon’s State Language.
let’s try to do Continue reading
< MEDIUM: https://medium.com/@raaki-88/lambda-sync-async-invocations-29e12a47ce85 >
A short note on Lambda Sync and Async Invocations. After Reinvent 2022, most of us started to think around Event-Driven architectures, especially using Event-Bridge, and Step-Functions at the core of state changes and function data pass.
I like these ideas very much. For me, before step-functions and event-bridge Lambda had this beautiful feature of Event/Request-Response knobs which served the purpose. With Step-Functions in place, you remove the complexity of maintaining state and time-delay logic and connectivity to different AWS services without relying on BOTO3 API connectivity. As one of the talks in Reinvent 2022 iterated that Lambda should be used to transform the data but not transfer the data.
https://www.youtube.com/watch?v=SbL3a9YOW7s
This is by far the best video that I have seen around the topic, this guy has nailed it to perfection! Please watch it if you are interested in these architectures.
For those who were looking out for using Lambda Request-Response/Event-based invocations few things that I have not seen anyone else write about some nitty gritty details
Let’s say
def call_other_lambda(lambda_payload):
lambda_client = boto3.client('lambda')
lambda_client.invoke(FunctionName='function_2',
InvocationType='Event', Payload=lambda_payload)
def lambda_handler(event, context):
print(event.keys())
get_euiid = event['end_device_ids']['device_id']
lambda_payload = json.dumps( {json. Continue reading
< MEDIUM: https://raaki-88.medium.com/a-simple-bpftrace-to-see-tcp-sendbytes-as-a-histogram-f6e12355b86c >
A significant difference between BCC and BPF is that BCC is used for complex analysis while BPF programs are mostly one-liners and are ad-hoc based. BPFTrace is an open-source tracer, reference below
https://ebpf.io/ — Excellent introduction to EBPF
https://github.com/iovisor/bpftrace — Excellent Resource.
Let me keep this short, we will try to use BPFTrace and capture TCP
We will need
To understand the efficiency of this, let’s attach a Tracepoint, a Kernel Static Probe to capture all of the new processes that get triggered, imagine an equivalent of a TOP utility with means of reacting to the event at run-time if required
https://github.com/iovisor/bpftrace/blob/master/docs/reference_guide.md#probes — Lists out type of probes and their utility
We can clearly see we invoked a BPFTrace for tracepoint system calls which takes execve privilege, I executed the ping command and various other commands and you can see that executing an inbound SSH captured invoke of execve-related commands and the system banner.
sudo bpftrace -e 'tracepoint:syscalls:sys_enter_execve { join(args->argv); }'
Attaching 1 probe...
clear
ping 1.1.1.1 -c 1
/usr/bin/clear_console -q
/usr/sbin/sshd -D -o AuthorizedKeysCommand /usr/share/ec2-instance-connect/eic_run_authorized_keys %u Continue reading
< MEDIUM: https://raaki-88.medium.com/flamegraph-htop-benchmarking-cpu-linux-e0b8a8bb6a94 >
I have written a small post on what happens at a Process-Level, now let’s throw some flame into it with flame-graphs
Am a fan of Brendan Gregg’s work and his writings and flame graph tool are his contribution to the open-source community —
https://www.brendangregg.com/flamegraphs.html
Before moving into Flamegraph, let’s understand some Benchmarking concepts.
Benchmarking in general is a methodology to test resource limits and regressions in a controlled environment. Now there are two types of benchmarking
Most Benchmarking scenario results boil down to the price/performance ratio. It can slowly start with an intention to provide proof-of-concept testing to test application/system load to identify bottlenecks in the system for troubleshooting or enhancing the system or to know about the maximum stress system simply is capable of taking.
Enterprise / On-premises Benchmarking: let’s take a simple scenario to build out a data centre which has huge racks of networking and computing equipment. As Data-centre builds are mostly identical and mirrored, benchmarking before going for Purchase-order is critical.
Cloud-based Benchmarking: This is a really in-expensive setup. While Continue reading
< MEDIUM: https://raaki-88.medium.com/aws-direct-connect-site-link-a-very-excellent-service-10c13a389c8d >
Site-link is really a nice extension to the DX Gateway’s offering. Let me simplify it.
Reference: https://aws.amazon.com/blogs/networking-and-content-delivery/introducing-aws-direct-connect-sitelink/ — I Can’t Recommend this more, this is a very very nice read.

Few Important Points
Problem — I want to connect my two Data-Centres to Direct Connect Gateway through AWS Backbone.
Let’s see a reference Architecture
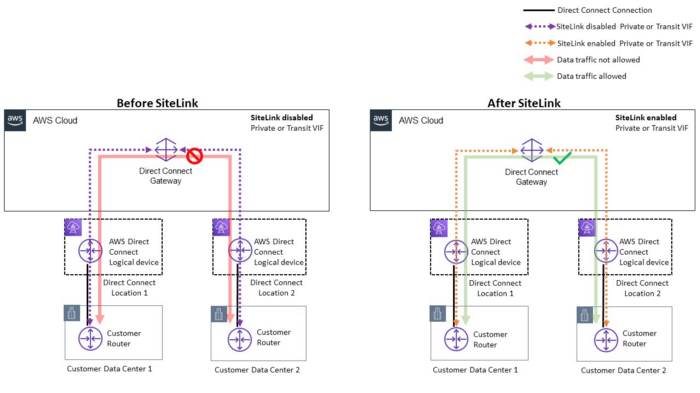
Replicating the above scenario
Few important aspects
< MEDIUM: https://towardsaws.com/transit-gateway-a-one-stop-shop-e520d2f0afe3 >
I like Transit Gateway on so many levels, truly an NG service integrating many different points of ingress in a way with VPCs

Scenario 1 — Connect your VPCs
Interconnecting VPCs’s typically done through VPC-Peering, now while that is still valid you can easily interconnect VPCs through the transit gateway attachments feature, while VPC peering does only well VPC, transit gateway can connect VPCs, DX-Gateways and you can terminate IPSEC-VPN’s directly onto the transit gateway.
< MEDIUM: https://towardsaws.com/direct-connect-part-2-public-vif-5bc0a2d2c478 >
First Post ( Direct Connect – Part 1 )- https://raaki-88.medium.com/direct-connect-part-1-dc3e9369933
Direct Connect offering though it connects to AWS has a difference in operation depending on the VIF we connect.
Public VIF
→ So when we have this setup, this is in no way related to VPC at all, all this does is advertise Amazon-owned Public Prefixes for services like S3/EC2(Elastic-IP only, not your Private IP), and that’s all to it.
→ There is flexibility at the customer end to scope the advertisement propagation t LOCAL, CONTINENT, and GLOBAL levels within AWS in an outbound direction and has the flexibility to filter inbound updates which are advertised toward him.
Here is by default, how the Community scope looks like, you also have the flexibility to filter routes inbound to customers.
Note: Outbound communities restrict the advertisement of prefixes to region/continent/global scope for any sort of Any-cast implementations.

if the Customer sends a route with a community
7224:9100 → This will be local to the region
7224:9200 → This will be local to the continent, the scope is till the EU
7224:9300 → Global, by default its global even if you don’t export Continue reading
< MEDIUM: https://raaki-88.medium.com/direct-connect-part-1-dc3e9369933 >
AWS Advanced Networking Prep and General focus
Notion — https://meteor-honeycup-16b.notion.site/Direct-Connect-a61557d18e784e778b4500197168454c
What is the Direct Connect product trying to solve?
We have seen IPSEC Site-to-Site VPN, a nice extension to that is Direct Connect offering. In IPSEC VPN, we connected to AWS VPC securely over the internet, in Direct Connect we have a cable termination onto our Data Center premises which directly connects to AWS Infrastructure and no internet service providers are needed for this to happen.
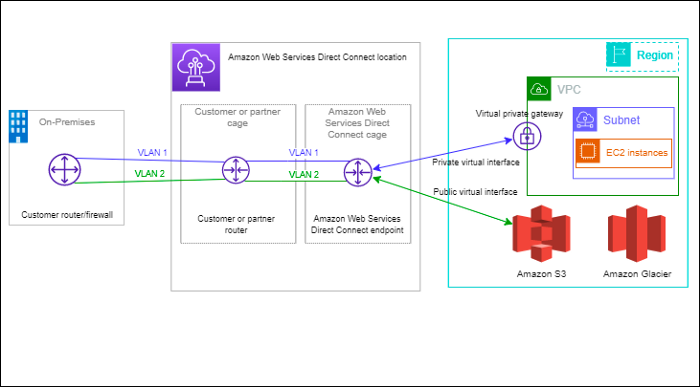
Advantages:
What are my building blocks?

Functional Building Block?
Ref:https://docs.aws.amazon.com/directconnect/latest/UserGuide/WorkingWithVirtualInterfaces.html
So, once we have a connection setup, everything revolves around VIF — Virtual Interface.
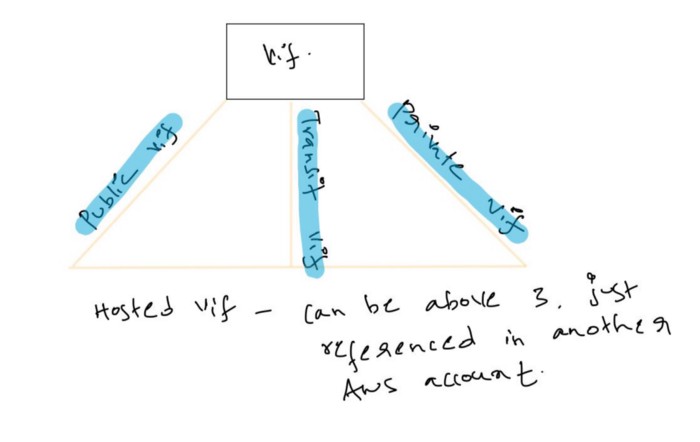
Direct Connect can be divided into two parts
a. Public VIF — we are speaking about public IP addresses routable on the internet.
< MEDIUM: https://raaki-88.medium.com/aws-advanced-networking-ipsec-vpn-with-bgp-frr-and-docker-ae29a3ec6d85 >
The previous post covered IPSEC Vpn implementation with Static Routing and also had some points about IPSEC Vpn Implementation, this post aims at building IPSEC Vpn with Dynamic routing offered by VGW which is BGP.
Article on FRR, Docker — https://towardsaws.com/configuring-bgp-and-open-source-frr-docker-on-aws-advanced-networking-d21fd0d76b33
We will re-use the same concept and will start a BGP route exchange over IPSEC VPN.
https://meteor-honeycup-16b.notion.site/Site-2-Site-VPN-BGP-FRR-Docker-d818267a1041401481554e6f30764dfb — Notes and Topology
Lab Video — https://youtu.be/PmLkHRAMfMU
Few points to note:
{kind=link}