Author Archives: Sung Park
Author Archives: Sung Park


We often put together experiments that measure hardware performance to improve our understanding and provide insights to our hardware partners. We recently wanted to know more about Hyper-Threading and Turbo Boost. The last time we assessed these two technologies was when we were still deploying the Intel Xeons (Skylake/Purley), but beginning with our Gen X servers we switched over to the AMD EPYC (Zen 2/Rome). This blog is about our latest attempt at quantifying the performance impact of Hyper-Threading and Turbo Boost on our AMD-based servers running our software stack.
Intel briefly introduced Hyper-Threading with NetBurst (Northwood) back in 2002, then reintroduced Hyper-Threading six years later with Nehalem along with Turbo Boost. AMD presented their own implementation of these technologies with Zen in 2017, but AMD’s version of Turbo Boost actually dates back to AMD K10 (Thuban), in 2010, when it used to be called Turbo Core. Since Zen, Hyper-Threading and Turbo Boost are known as simultaneous multithreading (SMT) and Core Performance Boost (CPB), respectively. The underlying implementation of Hyper-Threading and Turbo Boost differs between the two vendors, but the high-level concept remains the same.
Hyper-Threading or simultaneous multithreading creates a second hardware thread within a processor’s core, also known Continue reading

Over three years ago, we embraced the ARM ecosystem after evaluating the Qualcomm Centriq. The Centriq and its Falkor cores delivered a significant reduction in power consumption while maintaining a comparable performance against the processor that was powering our server fleet at the time. By the time we completed porting our software stack to be compatible with ARM, Qualcomm decided to exit the server business. Since then, we have been waiting for another server-grade ARM processor with hopes to improve our power efficiencies across our global network, which now spans more than 200 cities in over 100 countries.
ARM has introduced the Neoverse N1 platform, the blueprint for creating power-efficient processors licensed to institutions that can customize the original design to meet their specific requirements. Ampere licensed the Neoverse N1 platform to create the Ampere Altra, a processor that allows companies that own and manage their own fleet of servers, like ourselves, to take advantage of the expanding ARM ecosystem. We have been working with Ampere to determine whether Altra is the right processor to power our first generation of ARM edge servers.
The AWS Graviton2 is the only other Neoverse N1-based processor publicly accessible, but only made Continue reading


We are using AMD 2nd Gen EPYC 7642 for our tenth generation “Gen X” servers. We found many aspects of this processor compelling such as its increase in performance due to its frequency bump and cache-to-core ratio. We have partnered with AMD to get the best performance out of this processor and today, we are highlighting our tuning efforts that led to an additional 6% performance.

Thermal design power (TDP) and dynamic power, amongst others, play a critical role when tuning a system. Many share a common belief that thermal design power is the maximum or average power drawn by the processor. The 48-core AMD EPYC 7642 has a TDP rating of 225W which is just as high as the 64-core AMD EPYC 7742. It comes to mind that fewer cores should translate into lower power consumption, so why is the AMD EPYC 7642 expected to draw just as much power as the AMD EPYC 7742?
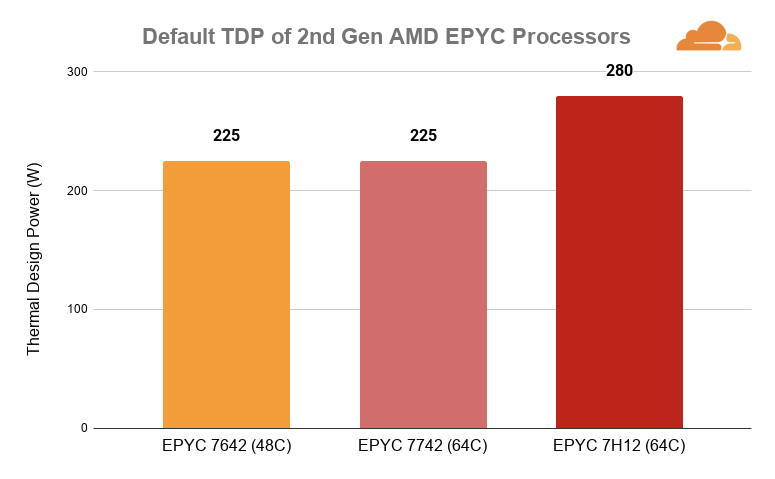
Let’s take a step back and understand that TDP does not always mean the maximum or average power that the processor will draw. At a glance, Continue reading


In the past, we didn't have the opportunity to evaluate as many CPUs as we do today. The hardware ecosystem was simple – Intel had consistently delivered industry leading processors. Other vendors could not compete with them on both performance and cost. Recently it all changed: AMD has been challenging the status quo with their 2nd Gen EPYC processors.
This is not the first time that Intel has been challenged; previously there was Qualcomm, and we worked with AMD and considered their 1st Gen EPYC processors and based on the original Zen architecture, but ultimately, Intel prevailed. AMD did not give up and unveiled their 2nd Gen EPYC processors codenamed Rome based on the latest Zen 2 architecture.
Playing with some new fun kit. #epyc pic.twitter.com/1No8Cmfzwl
— Matthew Prince ? (@eastdakota) November 8, 2019
This made many improvements over its predecessors. Improvements include a die shrink from 14nm to 7nm, a doubling of the top end core count from 32 to 64, and a larger L3 cache size. Let’s emphasize again on the size of that L3 cache, which is 32 MiB L3 cache per Core Complex Die (CCD).
This time around, we have taken steps to Continue reading