Author Archives: Suresh Vina
Author Archives: Suresh Vina

In iBGP, all routers in the same AS must be fully meshed, meaning every router forms an iBGP session with every other router. This is required because iBGP by default does not advertise routes learned from one iBGP peer to another. The full mesh ensures that every router can learn all the routes.
The problem is that in a large network with many iBGP routers, a full mesh quickly becomes unmanageable. The number of sessions grows rapidly, and you could end up with hundreds of iBGP sessions. If you have 10 iBGP routers and try to build a full mesh, you would need 45 sessions. For n routers, the number of sessions is n × (n – 1) / 2. So with 10 routers, that’s 10 × 9 / 2 = 45.
This is where route reflectors come in. A route reflector reduces the need for full mesh by allowing certain routers to reflect routes to others. With this design, you only need a few sessions instead of a full mesh, making the iBGP setup much more scalable. If you have the same 10 routers, with RR, you only need 9 sessions.

In this post, we’ll be looking at how to use the Infrahub MCP server. But, before we get there, we’ll go through some background on the Model Context Protocol (MCP) itself, show a simple example to explain how it works, and then connect it back to Infrahub. This will give us the basics before moving on to the Infrahub-specific setup. Here’s what we’ll cover:
Disclaimer – OpsMill has partnered with me for this post, and they also support my blog as a sponsor. The post is originally published under https://opsmill.com/blog/getting-started-infrahub-mcp-server/
If you're doing anything with AI (and honestly, who isn’t these days), you’ve probably heard of Model Context Protocol, or MCP. Anthropic introduced MCP in November 2024, which means it hasn’t been around for long and is still evolving quickly.
MCP is a communication Continue reading

If you are a Network Engineer working for an Enterprise, you may not work with BGP as often as someone at an ISP does. In most cases, you will only run BGP at the edge of your network to peer with your ISP and leave it at that. There are many ways to connect to an ISP. If you are a small company without your own IP address space or autonomous system, you typically rely on the ISP to allocate a portion of their IP space for you, and you use a static route pointing to them (single-homed). For redundancy, you might connect to two ISPs or take two diverse links from the same ISP (dual-homed/multi-homed). In many of those setups, you may not run BGP yourself, but it depends on the design.
In this post, we will look at a scenario where you already have your own IP address space and an AS number, and you connect to two different ISPs. You will advertise your IP space to the Internet via both ISPs and, at the same time, receive the full Internet routing table from both ISPs.
If you are completely new to BGP, I recommend checking out Continue reading

Have you ever had two teams accidentally assign the same IP address? Or heard someone ask, “Can I get a VLAN? I’m not sure which one to use.” I’m also certain you have because manually managing infrastructure resources like IP addresses, IP prefixes, VLAN IDs, and BGP ASNs is still all too common in a lot of environments. Manual resource management is also time-consuming and painful, and often results in duplicate resource assignments, which means more work to clean things up later.
Disclaimer – OpsMill has partnered with me for this post, and they also support my blog as a sponsor. The post is originally published under https://opsmill.com/blog/infrahub-resource-manager-automate-allocation/
The Infrahub Resource Manager is designed to eliminate those pains while speeding up your workflows. The Resource Manager automatically hands out resources from managed pools and ensures every allocation is tracked and unique.

In this guide, we’ll show you how the Infrahub Resource Manager works and give you three ways to build pools and allocate resources with it.
The Resource Manager can be used in many areas of network design and automation. A common use case is data center expansion Continue reading

If you follow me or my blog, you may know that I moved my homelab to Proxmox. Even though I already have a physical Palo Alto firewall, I also needed to set up a Palo Alto VM. After some reading and research, and with the help of a great guide I found, I managed to get Palo Alto running on Proxmox. I thought it would be useful to write a post about it for anyone else trying to do the same.
At a high level, you need to download the Palo Alto QCOW image. I’m using PAN-OS 11.2.5 and downloaded the image called PA-VM-KVM-11.2.5.qcow2. You will also need multiple network interfaces on Proxmox. With Palo Alto, you need at least two to begin with, one for management and one for data.
When I say Proxmox interfaces or NICs, I mean the virtual network adapters that you can assign to your VM. These map to your physical or virtual bridges on the Proxmox host, and they let you connect the firewall VM to different parts of your network.
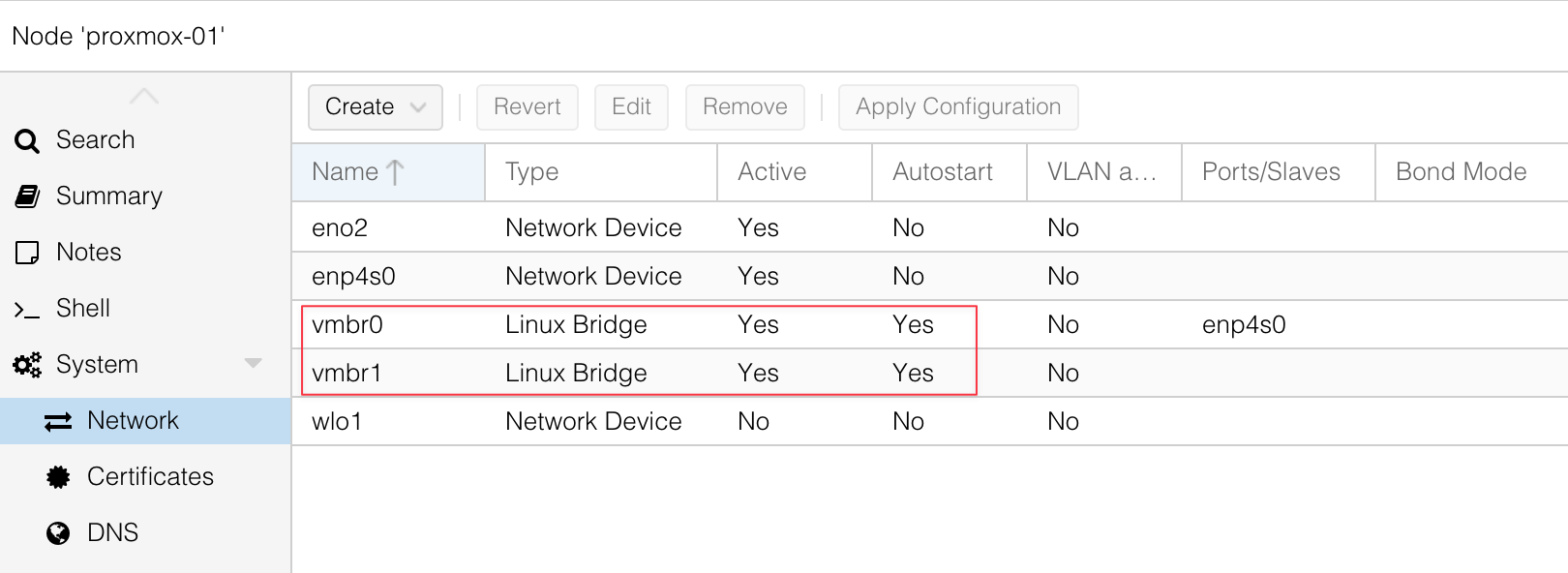
The first step is to copy the Palo Alto QCOW image over to Continue reading

Recently, I was doing some reading on MPLS and wanted to build a lab for it. For my use case, I needed five routers connected and running OSPF between them before I could even start configuring MPLS. So before doing any MPLS work, I have to spend a lot of time setting up the lab and prerequisites like configuring IP addresses on interfaces and setting up OSPF. This is tedious, and this is exactly where Netlab can help you get up to speed.
Netlab is an open source tool that makes it easy to build and share network labs. Instead of manually dragging devices in a GUI or typing the same base configs over and over, you describe your lab in a simple YAML file. Netlab then takes care of creating the topology, assigning IP addresses, configuring routing protocols, and even pushing custom configs. Netlab works with containerlab (or vagrant) so you can spin up realistic network topologies in minutes and reproduce them anywhere automagically.

As Network Engineers, we often set up labs to help us learn and practice. Most of us use tools like EVE-NG, GNS3, or Cisco CML, where you go into Continue reading

In the previous posts, we looked at how to use a site‑to‑site VPN to connect your on‑premises network to AWS, and as we saw, it is very easy to set up. So what’s the fuss about Direct Connect (DX), and why would we need one?
To give you a one‑word answer, a VPN connects through the Internet. As you would expect, that comes with some limitations. Latency can be high, and the throughput is capped at around 1.25 Gb/s (per tunnel). So what if we need something more resilient and with much higher throughput?

That is where AWS Direct Connect comes in. As the name suggests, it is a Dedicated Direct Connection (DX Connection) to AWS, giving you a dedicated network link with better performance and reliability compared to a traditional VPN over the Internet.
As always, if you find this post helpful, press the ‘clap’ button. It means a lot to me and helps Continue reading

Recently, I started self-hosting most of the apps I use, like Memos for note-taking and Paperless-NGX for document management. The next one on the list was Immich. Immich is a self-hosted photo and video backup solution that supports features like facial recognition and automatic uploads.


In this post, we’ll look at how to set up Immich as a Docker container and also how to add an NFS share as an external library.
I have a lot of pictures on my NAS that I’ve collected over the years. This includes photos of friends, family, and ones from my older phones. I wanted a way to manage and organise them from one place. I also didn’t want to upload all of them to Google or Apple, which would cost quite a bit. Continue reading

Testing individual components is a good start, but what happens when you need to validate how everything works together? In this post, we’ll show you how to run integration tests in Infrahub that verify your schema, data, and Git workflows in a real, running environment.
You’ll learn how to spin up isolated Infrahub instances on the fly using Docker and Testcontainers, automate schema and data loading, and catch issues before they reach production.
OpsMill has partnered with me for this post, and they also support my blog as a sponsor. The post is originally published under https://opsmill.com/blog/integration-testing-infrahub/
You don’t need to be a Python expert to follow along. We’ll walk through everything step by step, with example code and tooling recommendations. You can also follow this guide in video form on the Cisco DevNet YouTube channel:
All the sample data and code used here are available on the OpsMill GitHub repo, so you can set up your own test environment and try it yourself.
Previously, we covered how to write smoke and unit tests using the Continue reading

Hi all, welcome back to the AWS networking series. This is actually part 3 of just Transit Gateway. I know some of you might be thinking, why are we still talking about Transit Gateway? But please bear with me. TGW is such an important concept, and it shows up in almost every architecture you come across.
So far, we've covered what a Transit Gateway is, how to create one, how route tables work, and how to manage associations and propagations. We also looked at how to create a VPN and attach it to the TGW, and we went through the process of sharing a TGW with other AWS accounts using AWS Resource Access Manager (RAM). In this post, we'll look at how to peer a Transit Gateway with another TGW, even when they are in different regions. So let's get to it.
If you're completely new to Transit Gateway, I highly recommend checking out the earlier introductory posts listed below.

In the previous post, we covered the basics of Transit Gateway, what it is, what problem it solves, and we also looked at how to create one. We walked through attaching two VPCs to the TGW and establishing connectivity between them. We also covered the important concepts of TGW attachments, associations, and propagations.

In this post, we will build on that knowledge and look at
As always, if you find this post helpful, press the ‘clap’ button. It means a lot to me and helps me know you enjoy this type of content. If I get enough claps for this series, I’ll make sure to write more on this specific topic.
We have already seen how to create a Site-to-Site Continue reading

In the previous post, we covered VPC Peering, which is a quick and easy way to create a connection between two VPCs. We also discussed its limitations, primarily that it is non-transitive. This means if VPC 'A' is peered with VPC 'B', and VPC 'B' is peered with VPC 'C', VPC 'A' cannot communicate with VPC 'C' through VPC 'B'. Because of this, to connect multiple VPCs together, you need to create a full mesh, where every VPC has a direct peering connection to every other VPC.

This complexity (when you have many VPCs) is why, in this post, we will look at AWS Transit Gateway (TGW). A Transit Gateway is an incredibly important networking resource in AWS that solves these scaling challenges. You will see the TGW featured in many modern AWS architecture diagrams because of the flexibility and simplicity it provides.
As always, if you find this post helpful, press the ‘clap’ button. It means a lot to me and helps me know you enjoy Continue reading

Welcome back to the AWS Networking series. So far, we have covered a wide range of foundational topics. We started with the basics of building a VPC, creating subnets, configuring route tables, and providing Internet access with an Internet Gateway and a NAT Gateway. We then looked at the difference between stateful Security Groups attached to an instance's ENI and stateless Network ACLs applied at the subnet level. Most recently, we covered how to build a hybrid network using a Site-to-Site VPN.
In this post, we will continue to expand on VPC connectivity by looking at what AWS VPC Peering is and how to configure one.
If you are completely new to AWS networking, I highly recommend checking out our introductory posts linked below. However, if you are already familiar with the basics, you can carry on with this post.

As always, if you find this post helpful, press the ‘clap’ button. Continue reading

So far in the AWS Networking series, we have covered VPCs, subnets, route tables, Internet Gateways, NAT Gateways, EC2 instances, Security Groups, Network ACLs, and Elastic Network Interfaces. In this post, we will look at using a Site-to-Site VPN in AWS so you can securely connect your on-premise workloads to and from your AWS environment. This is a very important aspect of AWS networking, and this is a service you will use almost always.
If you have been following the series, you can easily follow along with this post. If you just stumbled upon this post, you can still continue, assuming you are already familiar with AWS networking basics. However, if you are completely new to AWS, I highly recommend checking out the previous posts linked below.

When we launch an instance in a public subnet with a public IP address, we have seen that we can connect to Continue reading

I have PA-440 in my home lab and was happily running PAN-OS 10.2.10-h9. But with the recent announcement that PAN-OS 10.2 will enter limited support from 26th August 2025, I decided it was time to upgrade. I was deciding between 11.1 and 11.2 for a while, but after reading through a few forums and discussions, I ended up choosing 11.2, specifically PAN-OS 11.2.4-h7.
Since I was already on 10.2, I could upgrade directly to 11.2 without going through any intermediate versions. As per the upgrade guide, all I had to do was download the 11.2.0 base image, then download and install 11.2.4-h7.


After downloading both the base image and the target image, just click 'Install' on the target image. As usual, make sure to take a backup before starting. If you’re running in HA, you can upgrade the firewalls one at a time without any downtime.


The whole process took about 10 to 15 minutes, and now I'm running 11.2.4-h7. If I come across any issues, I'll be sure to update this post.


In this blog post, we'll look at how to create a site-to-site VPN between AWS and a Palo Alto firewall. We'll go through both static routing and BGP options. This post assumes you're already somewhat familiar with AWS and Palo Alto, so we won't cover the basics like creating a VPC in AWS or setting up zones and policies on the firewall.

To create a VPN connection, you first need a compatible IPsec VPN device, like a firewall or router, at your on-premise location. In AWS, the resource you create to represent this device is called a Customer Gateway. In our example, the customer gateway is the Palo Alto firewall.
To send traffic from your VPC to your on-premise network, you route it to a Virtual Private Gateway (VGW). The VGW is a logical, redundant resource on the AWS side of the connection that you attach to your VPC. It serves as the target in your Continue reading

This is the third blog post in the AWS Networking series. If you have been following along, you can continue with the lab we have built so far. For anyone who has just landed on this page, you can still follow along as long as you are already familiar with the basics of AWS networking. If you are completely new, however, I highly recommend checking out the introductory posts linked below to get up to speed.
In this blog post, we will look at AWS Security Groups, Network ACL (NACL) and Elastic Network Interfaces (ENI).


So far, we have briefly touched on Security Continue reading

When working with AWS networking, you will often hear the terms 'public subnet' and 'private subnet'. However, if you go into the AWS console to create a subnet, you won't find any option to explicitly make it one or the other. So, what exactly makes a subnet public or private?
In this blog post, we will look at the differences between public and private subnets, see how they are defined by their routing, and understand how the AWS NAT Gateway fits into this architecture.
If you are completely new to AWS networking and want to learn the basics of setting up a VPC, feel free to check out my previous post linked below.

The key difference between a 'public' and a 'private' subnet is simply its route to the Internet. It is not an inherent setting of the subnet itself, but a behaviour defined by the route table associated Continue reading

In this blog post, we'll see how to configure bulk Address-Objects at once and then add them to an Address-Group using the pan-os-python Library. If you haven't used the pan-os-python library before, have a look at my other blog post to learn more.
 Suresh Vina
Suresh Vina
Here is the official guide for the useful methods
create() method is used to push this object to the live device, making the configuration active.
We all write code, but how do we know the changes we make in the future won’t break something that used to work? That’s where testing becomes important.
The idea is to catch problems early, ideally before they reach production. In the Python world, one of the most common ways to do this is with a tool called pytest. It lets you write tests to check that your code behaves the way you expect and helps you catch issues before they become a bigger problem.
Originally published under - https://www.opsmill.com/pytest-plugin-infrahub/
When working with Infrahub, testing is just as important. You might want to make sure your GraphQL queries are valid, your Jinja2 templates render correctly, or your transformations behave as expected.
Infrahub simplifies this by offering a pytest plugin that doesn’t require Python code; you define tests using plain YAML. This makes testing more accessible to teams across roles and speeds up the feedback loop during development.
These kinds of unit tests aren’t just about convenience, they help establish a production-ready automation system. With automated checks built into your process, every change is validated consistently, reducing the chance of something breaking unexpectedly. That consistency builds trust when your Continue reading