Author Archives: Todd Hoff
Author Archives: Todd Hoff

Like an amoeba the public cloud is extending fingerlike projections to the edge in a new kind of architecture that creates a world spanning distributed infrastructure under one centralized management, billing, and security domain.
This issue—the deep nature of centralization—came up as a comment on my article What Do You Believe Now That You Didn't Five Years Ago? Centralized Wins. Decentralized Loses.
Centralization can refer to the locus of computation, but it also refers to a boundary, to a domain of control.
Facebook, Netflix, and Google are all distributed across much of the world, but they are still centralized services because control is centralized. You know this because in a browser, no matter where you are in the world, you navigate to facebook.com, netflix.com, or google.com, you never enter the URL for independent shards, yet all your data and services magically follow you around like a hyperactive puppy.
That's the world we've come to expect. That's how services built on a cloud work.
In an unexpected development, the public cloud is expanding control out to the edge. As I wrote in Stuff The Internet Says On Scalability For July 27th, 2018:
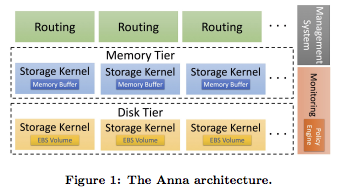
New databases used to be announced seemingly every week. While database neogenesis has slowed down considerably, it has not gone necrotic.
RISELabs, those wonderfully innovative folks over at Berkeley, have uplifted their Anna datatabase—a shared-nothing, thread-per-core architecture to achieve lightning-fast speeds by avoiding all coordination mechanisms—to become cloud-aware.
What's changed?
Anna is not only incredibly fast, it’s incredibly efficient and elastic too: an autoscaling, multi-tier, selectively-replicating cloud service. All that adaptivity means that Anna ramps down resource consumption for cold things, and ramps up consumption for hot things. You get all the multicore Anna performance you want, but you don’t pay for what you don’t need.Just to throw out some numbers, we measured Anna providing 355x the performance of DynamoDB for the dollar. No, I don’t think that is because AWS is earning a 355x margin on DynamoDB! The issue is that Anna is now orders of magnitude more efficient than competing systems, in addition to being orders of magnitude faster.
Using Anna v0 as an in-memory storage engine, we set out to address the cloud storage problems described Continue reading
Hey, it's HighScalability time:

Get antsy waiting 60 seconds for a shot? Imagine taking over 300,000 photos over 14 years, waiting for Mount Colima to erupt. Sergio Tapiro studied, waited, and snapped.
Do you like this sort of Stuff? Please lend me your support on Patreon. It would mean a great deal to me. And if you know anyone looking for a simple book that uses lots of pictures and lots of examples to explain the cloud, then please recommend my new book: Explain the Cloud Like I'm 10. They'll love you even more.

Hey, it's HighScalability time:
This mind blowing creation is from John Williamson. It's the first million integers, represented as binary vectors indicating their prime factors, laid out with UMAP. No, I really have no idea what that means either, but it did make me consider that our universe could be created by an algorithm. What are the wiggly cycles on the periphery? Groups of numbers that share a minimum amount of prime factors, further out groups are numbers that have increasing amounts of shared prime factors. So the primes are at the core, ungrouped as they have no prime factors to use to join groups. Primorials should be furthest out.
Do you like this sort of Stuff? Please lend me your support on Patreon. It would mean a great deal to me. And if you know anyone looking for a simple book that uses lots of pictures and lots of examples to explain the cloud, then please recommend my new book: Explain the Cloud Like I'm 10. They'll love you even more.

This is article was written by Dirceu Pereira Tiegs, Site Reliability Engineer at Auth0, and originally was originally published in Auth0.
Auth0 provides authentication, authorization, and single sign-on services for apps of any type (mobile, web, native) on any stack. Authentication is critical for the vast majority of apps. We designed Auth0 from the beginning so that it could run anywhere: on our cloud, on your cloud, or even on your own private infrastructure.
In this post, we'll talk more about our public SaaS deployments and provide a brief introduction to the infrastructure behind auth0.com and the strategies we use to keep it up and running with high availability.
A lot has changed since then in Auth0. These are some of the highlights:
We went from processing a couple of million logins per month to 1.5+ billion logins per month, serving thousands of customers, including FuboTV, Mozilla, JetPrivilege, and more.
We implemented new features like custom domains, scaled bcrypt operations, vastly improved user search, and much more.
The number of services that compose our product in order to scale our organization and handle the increases in traffic went from under Continue reading
Hey, it's HighScalability time:
Do you like this sort of Stuff? Please lend me your support on Patreon. It would mean a great deal to me. And if you know anyone looking for a simple book that uses lots of pictures and lots of examples to explain the cloud, then please recommend my new book: Explain the Cloud Like I'm 10. They'll love you even more.

Decentralized systems will continue to lose to centralized systems until there's a driver requiring decentralization to deliver a clearly superior consumer experience. Unfortunately, that may not happen for quite some time.
I say unfortunately because ten years ago, even five years ago, I still believed decentralization would win. Why? For all the idealistic technical reasons I laid out long ago in Building Super Scalable Systems: Blade Runner Meets Autonomic Computing In The Ambient Cloud.
While the internet and the web are inherently decentralized, mainstream applications built on top do not have to be. Typically, applications today—Facebook, Salesforce, Google, Spotify, etc.—are all centralized.
That wasn't always the case. In the early days of the internet the internet was protocol driven, decentralized, and often distributed—FTP (1971), Telnet (<1973), FINGER (1971/1977), TCP/IP (1974), UUCP (late 1970s) NNTP (1986), DNS (1983), SMTP (1982), IRC(1988), HTTP(1990), Tor (mid-1990s), Napster(1999), and XMPP(1999).
We do have new decentalized services: Bitcoin(2009), Minecraft(2009), Ethereum(2104), IPFS(2015), Mastadon(2016), and PeerTube(2018). We're still waiting on Pied Piper to deliver the decentralized internet.
On an evolutionary timeline decentralized systems are neanderthals; centralized systems are the humans. Neanderthals came first. Humans may have interbred with neanderthals, humans may have even killed off the neanderthals, but Continue reading
Hey, it's HighScalability time:
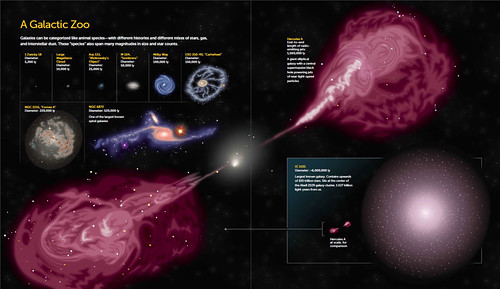
The amazing Zoomable Universe from 10^27 meters—about 93 billion light-years—down to the subatomic realm, at 10^-35 meters.
Do you like this sort of Stuff? Please lend me your support on Patreon. It would mean a great deal to me. And if you know anyone looking for a simple book that uses lots of pictures and lots of examples to explain the cloud, then please recommend my new book: Explain the Cloud Like I'm 10. They'll love you even more.
Decentralized systems will continue to lose to centralized systems until there's a driver requiring decentralization to deliver a clearly superior consumer experience. Unfortunately, that may not happen for quite some time.
I say unfortunately because ten years ago, even five years ago, I still believed decentralization would win. Why? For all the idealistic technical reasons I laid out long ago in Building Super Scalable Systems: Blade Runner Meets Autonomic Computing In The Ambient Cloud.
While the internet and the web are inherently decentralized, mainstream applications built on top do not have to be. Typically, applications today—Facebook, Salesforce, Google, Spotify, etc.—are all centralized.
That wasn't always the case. In the early days of the internet the internet was protocol driven, decentralized, and often distributed—FTP (1971), Telnet (<1973), FINGER (1971/1977), TCP/IP (1974), UUCP (late 1970s) NNTP (1986), DNS (1983), SMTP (1982), IRC(1988), HTTP(1990), Tor (mid-1990s), Napster(1999), and XMPP(1999).
We do have new decentalized services: Bitcoin(2009), Minecraft(2009), Ethereum(2104), IPFS(2015), Mastadon(2016), and PeerTube(2018). We're still waiting on Pied Piper to deliver the decentralized internet.
On an evolutionary timeline decentralized systems are neanderthals; centralized systems are the humans. Neanderthals came first. Humans may have interbred with neanderthals, humans may have even killed off the neanderthals, but Continue reading
Hey, it's HighScalability time (out Thur-Fri, so we're going early):

London Maker Faire 1851—The Great Exhibition—100,000 objects, displayed along more than 10 miles, by over 15,000 contributors.
Do you like this sort of Stuff? Please lend me your support on Patreon. It would mean a great deal to me. And if you know anyone looking for a simple book that uses lots of pictures and lots of examples to explain the cloud, then please recommend my new book: Explain the Cloud Like I'm 10. They'll love you even more.

There are a lot of cool nuggets in Google's New Book: The Site Reliability Workbook. If you haven't put it on your reading list, here's a tantalizing excerpt from CHAPTER 11 Managing Load by Cooper Bethea, Gráinne Sheerin, Jennifer Mace, and Ruth King with Gary Luo and Gary O’Connor.
Niantic launched Pokémon GO in the summer of 2016. It was the first new Pokémon game in years, the first official Pokémon smartphone game, and Niantic’s first project in concert with a major entertainment company. The game was a runaway hit and more popular than anyone expected—that summer you’d regularly see players gathering to duel around landmarks that were Pokémon Gyms in the virtual world.
Pokémon GO’s success greatly exceeded the expectations of the Niantic engineering team. Prior to launch, they load-tested their software stack to process up to 5x their most optimistic traffic estimates. The actual launch requests per second (RPS) rate was nearly 50x that estimate—enough to present a scaling challenge for nearly any software stack. To further complicate the matter, the world of Pokémon GO is highly interactive and globally shared among its users. All players in a given area see the same view of the game Continue reading
Hey, it's HighScalability time:
Everything starts with Doug Engelbart — Jane Metcalfe.
It was the very first time (1968) the world had ever seen a mouse, seen outline processing, seen hypertext, seen mixed text and graphics, seen real-time video conferencing. — Doug Engelbart (Valley of Genius).
ARPA funded the demo at a cost of $1 million. Most importantly? It was the first use of a todo list as an example. A tradition unlike any other.
Do you like this sort of Stuff? Please lend me your support on Patreon. It would mean a great deal to me. And if you know anyone looking for a simple book that uses lots of pictures and lots of examples to explain the cloud, then please recommend my new book: Explain the Cloud Like I'm 10. They'll love you even more.
Hey, it's HighScalability time:

Startup opportunity? Space Garbage Collection service. 18,000+ known Near-Earth Objects. (NASA)
Do you like this sort of Stuff? Please lend me your support on Patreon. It would mean a great deal to me. And if you know anyone looking for a simple book that uses lots of pictures and lots of examples to explain the cloud, then please recommend my new book: Explain the Cloud Like I'm 10. They'll love you even more.

Google has released a new book: The Site Reliability Workbook — Practical Ways to Implement SRE.
It's the second book in their SRE series. How is it different than the previous Site Reliability Engineering book?
David Rensin, a SRE at Google, says:
It's a whole new book. It's designed to sit next to the original on the bookshelf and for folks to bounce between them -- moving between principle and practice.
And from the preface:
The purpose of this second SRE book is (a) to add more implementation detail to the principles outlined in the first volume, and (b) to dispel the idea that SRE is implementable only at “Google scale” or in “Google culture.”
The Site Reliability Workbook weighs in at a hefty 508 pages and roughly follows the structure of the first book. It's organized into three different parts: Foundations, Practices, and Processes. There are three appendices: Example SLO Document, Example Error Budget Policy, and Results of Postmortem Analysis.
The table of content is quite detailed, but here are the chapter titles:
Hey, it's HighScalability time:

Do you like this sort of Stuff? Please lend me your support on Patreon. It would mean a great deal to me. And if you know anyone looking for a simple book that uses lots of pictures and lots of examples to explain the cloud, then please recommend my new book: Explain the Cloud Like I'm 10. They'll love you even more.
Hey, it's HighScalability time:
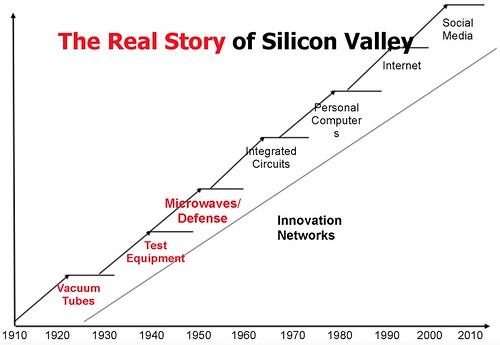
Steve Blank tells the Secret History of Silicon Valley. What a long, strange trip it is.
Do you like this sort of Stuff? Please lend me your support on Patreon. It would mean a great deal to me. And if you know anyone looking for a simple book that uses lots of pictures and lots of examples to explain the cloud, then please recommend my new book: Explain the Cloud Like I'm 10. They'll love you even more.

{kind=link}