Stuff The Internet Says On Scalability For July 27th, 2018
Hey, it's HighScalability time:

Startup opportunity? Space Garbage Collection service. 18,000+ known Near-Earth Objects. (NASA)
Do you like this sort of Stuff? Please lend me your support on Patreon. It would mean a great deal to me. And if you know anyone looking for a simple book that uses lots of pictures and lots of examples to explain the cloud, then please recommend my new book: Explain the Cloud Like I'm 10. They'll love you even more.
- 143 billion: daily words Google Translated; 73%: less face-to-face interaction in open offices; 10 billion: Uber trips; 131M: data breach by Exactis; $123 billion: Facebook value loss is 4 Twitters and 7 snapchats; $9.1B: spent on digital gaming across all platforms; 20-km: width of lake on mars; 1 billion: Google Drive users; $32.7 billion: Alphabet revenues; $110bn: Microsoft total revenue; $1.9 million: buy the Brady Bunch house; 5.623 trillion: Amazon Sable requests handle on prime day; 91%: Facebook's advertising revenue on mobile; $18 billion: deep learning market by 2024;
- Quotable Quotes:
- Ryan Cash: The App Store has changed the Continue reading
Google’s New Book: The Site Reliability Workbook

Google has released a new book: The Site Reliability Workbook — Practical Ways to Implement SRE.
It's the second book in their SRE series. How is it different than the previous Site Reliability Engineering book?
David Rensin, a SRE at Google, says:
It's a whole new book. It's designed to sit next to the original on the bookshelf and for folks to bounce between them -- moving between principle and practice.
And from the preface:
The purpose of this second SRE book is (a) to add more implementation detail to the principles outlined in the first volume, and (b) to dispel the idea that SRE is implementable only at “Google scale” or in “Google culture.”
The Site Reliability Workbook weighs in at a hefty 508 pages and roughly follows the structure of the first book. It's organized into three different parts: Foundations, Practices, and Processes. There are three appendices: Example SLO Document, Example Error Budget Policy, and Results of Postmortem Analysis.
The table of content is quite detailed, but here are the chapter titles:
- How SRE Relates to DevOps.
- Implementing SLOs.
- SLO Engineering Case Studies.
- Monitoring.
- Alerting on SLOs.
- Eliminating Toil.
- Simplicity.
- On-Call.
- Incident Response.
- Postmortem Continue reading
Stuff The Internet Says On Scalability For July 20th, 2018
Hey, it's HighScalability time:

World History Timeline from 3000BC to 2000AD. Yet we still program with text—in files.
{kind=link}
Do you like this sort of Stuff? Please lend me your support on Patreon. It would mean a great deal to me. And if you know anyone looking for a simple book that uses lots of pictures and lots of examples to explain the cloud, then please recommend my new book: Explain the Cloud Like I'm 10. They'll love you even more.
- $150 billion: Bezos Prime; 49%: Amazon's share of US e-commerce; 1,000 terabytes: image size to represent one cubic millimeter of brain tissue; 7x: 4 year reduction in cost of computing power; 25x: faster code using SIMD; 4TB: RAM in GCE “ultramem” instance type; 4 months: half-life of an ICO; 80%: cost savings moving from AWS to DO; 130,000: square feet in biggest vertical farm; 14x: price increase for Google Maps;
- Quotable Quotes:
- Chappell: In [CPU] architectures, we believe that aggressive specialization is a part of the answer to what happens next. That’s mapping applications to the specific architectural choices. And you already see that Continue reading
Stuff The Internet Says On Scalability For July 13th, 2018
Hey, it's HighScalability time:
Steve Blank tells the Secret History of Silicon Valley. What a long, strange trip it is.
Do you like this sort of Stuff? Please lend me your support on Patreon. It would mean a great deal to me. And if you know anyone looking for a simple book that uses lots of pictures and lots of examples to explain the cloud, then please recommend my new book: Explain the Cloud Like I'm 10. They'll love you even more.
- $27 billion: CapEx invested by leading cloud vendors in first quarter of 2018; $40 billion: App store revenue in 10 years; $57.5 billion: venture investment first half of 2018; 1 billion: Utah voting system per day hack attempts; 67%: did not deploy a serverless app last year; $1.8 billion: made by Pokeman GO; $13 billion: Netflix's new content budget;
- Quotable Quotes:
- @davidbrunelle: The best developers and engineering leaders I've personally worked with do *not* have a notable presence on GitHub or public bodies of speaking or writing work. I worry that a lot of folks confuse celebrity and visibility with talent and ability.
- Bernard Continue reading
Sponsored Post: Datadog, InMemory.Net, Triplebyte, Etleap, Scalyr, MemSQL

Who's Hiring?
- Triplebyte lets exceptional software engineers skip screening steps at hundreds of top tech companies like Apple, Dropbox, Mixpanel, and Instacart. Make your job search O(1), not O(n). Apply here.
- Need excellent people? Advertise your job here!
Fun and Informative Events
- Advertise your event here!
Cool Products and Services
- Datadog is a cloud-scale monitoring platform that combines infrastructure metrics, distributed traces, and logs all in one place. With out-of-the-box dashboards and seamless integrations with over 200 technologies, Datadog provides end-to-end visibility into the health and performance of modern applications at scale. Build your own rich dashboards, set alerts to identify anomalies, and collaborate with your team to troubleshoot and fix issues fast. Start a free trial and try it yourself.
- InMemory.Net provides a Dot Net native in memory database for analysing large amounts of data. It runs natively on .Net, and provides a native .Net, COM & ODBC apis for integration. It also has an easy to use language for importing data, and supports standard SQL for querying data. http://InMemory.Net
- For heads of IT/Engineering responsible for building an analytics infrastructure, Etleap is an ETL solution for creating perfect data Continue reading
Stuff The Internet Says On Scalability For July 6th, 2018
Hey, it's HighScalability time:
Could RAINB (Redundant Array of Independent Neanderthal ‘minibrains’) replace TPUs as the future AI core?
Do you like this sort of Stuff? Please lend me your support on Patreon. It would mean a great deal to me. And if you know anyone looking for a simple book that uses lots of pictures and lots of examples to explain the cloud, then please recommend my new book: Explain the Cloud Like I'm 10. They'll love you even more.
- $100m: Fortnite iOS revenue in 90 days; $2.5 Billion: SUSE Linux acquisition; 500,000: different orgs on Slack; 6.1%: chance of breaking change in each library; 10: years of the Apple app store; 2021: Japan goes exascale;
- Quoteable Quotes:
- jedberg: > Yes, that's how Amazon creates lock-in.
That is the cynical way to look at it. It also creates value because it lets you do more with what you already have. - Paul Ingles: We didn’t change our organisation because we wanted to use Kubernetes, we used Kubernetes because we wanted to change our organisation.
- ThousandEyes: The Internet is made up of thousands of autonomous networks that Continue reading
- jedberg: > Yes, that's how Amazon creates lock-in.
In Defense of Humanity—How Complex Systems Failed in Westworld **spoilers**

The Westworld season finale made an interesting claim: humans are so simple and predictable they can be encoded by a 10,247-line algorithm. Small enough to fit in the pages of a thin virtual book.
Perhaps my brain was already driven into a meta-fugal state by a torturous, Escher-like, time shifting plot line, but I did observe myself thinking—that could be true. Or is that a thought Ford programmed into my control unit?
To the armies of algorithms perpetually watching over us, the world is a Skinner box. Make the best box, make the most money. And Facebook, Netflix, Amazon, Google, etc. make a lot of money specifically on our predictability.
Even our offline behaviour is predictable. Look at patterns of human mobility. We stay in a groove. We follow regular routines. Our actions are not as spontaneous and unpredictable as we'd surmise.
Predictive policing is a thing. Our self-control is limited. We aren't good with choice. We're predictably irrational. We seldom learn from mistakes. We seldom change.
Not looking good for team human.
It's not hard to see how those annoyingly smug androids—with their perfect bodies and lives lived in a terrarium—could come to Continue reading
Stuff The Internet Says On Scalability For June 29th, 2018
Hey, it's HighScalability time:

Rockets. They're big. You won't believe how really really big they are. (Corridor Crew)
Do you like this sort of Stuff? Please lend me your support on Patreon. It would mean a great deal to me. And if you know anyone looking for a simple book that uses lots of pictures and lots of examples to explain the cloud, then please recommend my new book: Explain the Cloud Like I'm 10. They'll love you even more.
- 200TB: GitLab Git data; $100 Billion: Instagram; ~250k: Walmart peak events per second; 10x: data from upgraded Large Hadron Collider; .3mm: smallest computer; 9.9 million: spam or automated accounts identified by Twitter per week; 1 million: facial image training set; 1/3: industrial robots installed in China; 24%: never backup; 7 billion: BuzzFeed monthly page views;
- Quotable Quotes:
-
@jason: would love to do a https://www.founder.university/ for Immigrants -- but we might need to do it in Canada or Mexico, so that, umm.... potential immigrants can actually attend! #america
-
Stuff The Internet Says On Scalability For June 22nd, 2018
Hey, it's HighScalability time:

4th of July may never be the same. China creates stunning non-polluting drone swarm firework displays. Each drone is rated with a game mechanic and gets special privileges based on performance (just kidding). (TicToc)
Do you like this sort of Stuff? Please lend me your support on Patreon. It would mean a great deal to me. And if you know anyone looking for a simple book that uses lots of pictures and lots of examples to explain the cloud, then please recommend my new book: Explain the Cloud Like I'm 10. They'll love you even more.
-
$40 million: Netflix monthly spend on cloud services; 5%: retention increase can increase profits 25%; 50+%: Facebook's IPv6 traffic from the U.S, for mobile it’s over 75 percent; 1 billion: monthly Facebook, err, Instagram users; 409 million: websites use NGINX; 847 Tbps: global average IP traffic in 2021; 200 million: Netflix subscribers by 2020; $30bn: market for artificial-intelligence chips by 2022;
-
Quotable Quotes:
-
@evacide: Just yelled “Encryption of data in transit is not the same as encryption of data at rest!” at Continue reading
-
Sponsored Post: Datadog, InMemory.Net, Triplebyte, Etleap, Scalyr, MemSQL
Who's Hiring?
- Triplebyte lets exceptional software engineers skip screening steps at hundreds of top tech companies like Apple, Dropbox, Mixpanel, and Instacart. Make your job search O(1), not O(n). Apply here.
- Need excellent people? Advertise your job here!
Fun and Informative Events
- Advertise your event here!
Cool Products and Services
- Datadog is a cloud-scale monitoring platform that combines infrastructure metrics, distributed traces, and logs all in one place. With out-of-the-box dashboards and seamless integrations with over 200 technologies, Datadog provides end-to-end visibility into the health and performance of modern applications at scale. Build your own rich dashboards, set alerts to identify anomalies, and collaborate with your team to troubleshoot and fix issues fast. Start a free trial and try it yourself.
- InMemory.Net provides a Dot Net native in memory database for analysing large amounts of data. It runs natively on .Net, and provides a native .Net, COM & ODBC apis for integration. It also has an easy to use language for importing data, and supports standard SQL for querying data. http://InMemory.Net
- For heads of IT/Engineering responsible for building an analytics infrastructure, Etleap is an ETL solution for creating perfect data Continue reading
How Ably Efficiently Implemented Consistent Hashing
This is a guest post by Srushtika Neelakantam, Developer Advovate for Ably Realtime, a realtime data delivery platform.
Ably’s realtime platform is distributed across more than 14 physical data centres and 100s of nodes. In order for us to ensure both load and data are distributed evenly and consistently across all our nodes, we use consistent hashing algorithms.
In this article, we’ll understand what consistent hashing is all about and why it is an essential tool in scalable distributed system architectures. Further, we’ll look at data structures that can be used to implement this algorithm efficiently at scale. At the end, we’ll also have a look at a working example for the same.
Hashing revisited
Remember the good old naïve Hashing approach that you learnt in college? Using a hash function, we ensured that resources required by computer programs could be stored in memory in an efficient manner, ensuring that in-memory data structures are loaded evenly. We also ensured that this resource storing strategy also made information retrieval more efficient and thus made programs run faster.
The classic hashing approach used a hash function to generate a pseudo-random number, which is then divided by the size of the memory Continue reading
Stuff The Internet Says On Scalability For June 15th, 2018
Hey, it's HighScalability time:

Scaling fake ratings. A 5 star 10,000 phone Chinese click farm. (English Russia)
Do you like this sort of Stuff? Please lend me your support on Patreon. It would mean a great deal to me. And if you know anyone looking for a simple book that uses lots of pictures and lots of examples to explain the cloud, then please recommend my new book: Explain the Cloud Like I'm 10. They'll love you even more.
- 1.6x: better deep learning cluster scheduling on k8s; 100,000: Large-scale Diverse Driving Video Database; 3rd: reddit popularity in the US; 50%: increase in Neural Information Processing System papers, AI bubble? 420 tons: leafy greens from robot farms; 75%: average unused storage on EBS volumes; 12TB: RAM on new Azure M-series VM; 10%: premium on Google's single-tenant nodes; $7.5B: Microsoft's cost of courting developers; 100th: flip-flop invention anniversary; 1 million: playlist dataset from Spotify; 38GB torrent: Stackoverflow public database; 85%: teens use YouTube; 20%-25%: costs savings using Aurora; 80%: machine learning Ph.D.s work at Google or Facebook; 18: years of Continue reading
Open Source Database HA Resources from Severalnines

Severalnines has spent the last several years writing blogs and crafting content to help make your open source database solutions highly available. We are fans of highscalability.com and wanted to post some links to our top resources to help readers learn more how to make MySQL, MongoDB, MariaDB, Percona and PostgreSQL databases scalable.
Top HA Resources for MySQL & MariaDB
Stuff The Internet Says On Scalability For June 8th, 2018
Hey, it's HighScalability time:

Slovenia. A gorgeous place to break your leg. Highly recommended.
Do you like this sort of Stuff? Please lend me your support on Patreon. It would mean a great deal to me. And if you know anyone looking for a simple book that uses lots of pictures and lots of examples to explain the cloud, then please recommend my new book: Explain the Cloud Like I'm 10. They'll love you even more.
- 294: slides in Internet trends 2018 deck; 110 TB: Hubble Space Telescope data; $124 million: daily App store purchases; 10 billion: monthly Siri requests; 1000 billion: yearly photos taken on iOS; one exabyte: Backblaze storage by year end; 837 million: spam taken down by Facebook in Q1; 86%: of passwords are terrible; 10 Million: US patents; 72: Transceiver Radar Chip; C: most energy efficient language; $138 Billion: global games market; $50 billion: 2017 Angry Birds revenue; 50 million: cesium atomic clock time source; 1.3 Million: vCPU grid on AWS at $30,000 per hour; $296 million: Fortnite April revenue; 4000: Siri requests per second;
- Quotable Quotes:
- @adriancolyer: Microsoft's ServiceFabric Continue reading
Gone Fishin’
Well, not exactly Fishin', but I'll be on a month long vacation starting today. I won't be posting new content, so we'll all have a break. Disappointing, I know. Please use this time for quiet contemplation and other inappropriate activities. Se vidiva kmalu!

If you really need a quick fix there's always all the back catalog of Stuff the Internet Says. Odds are there's a lot you didn't read yet.
Stuff The Internet Says On Scalability For April 27th, 2018
Hey, it's HighScalability time:

Did ancient Egyptians invent Wi-Fi? @sherifhanna
Do you like this sort of Stuff? Please lend me your support on Patreon. It would mean a great deal to me. And if you know anyone looking for a simple book that uses lots of pictures and lots of examples to explain the cloud, then please recommend my new book: Explain the Cloud Like I'm 10. They'll love you even more.
- $17,500: price to give up Google search; 51.8,31.2,18.79: % using AWS, Azure, Google for IoT; 400: items per second shipped by peak Amazon; 43%: music revenues came from streaming; 800%: boost in downloads from apps featured by the Apple App Store; 45: average age of startup founder;
- Quotable Quotes:
-
Broad Band: By the mid-twentieth century, computing was so much considered a woman’s job that when computing machines came along, evolving alongside and largely independently from their human counterparts, mathematicians would guesstimate their horsepower by invoking “girl-years,” and describe units of machine labor as equivalent to one “kilogirl.”
-
thegayngler: Most engineers would not hire themselves. That has been apparent to me for awhile now. Continue reading
-
Update: What will programming look like in the future?
Update: Ólafur Arnalds built a robotic music system to accompany him on the piano. He calls his system of two semi generative, self playing pianos—STRATUS. You can hear his most recent song re:member. There's more explanation in The Player Pianos pt. II and a short Facebook live session. His software reacts to his playing in real-time. Then he has to react to the robots because he's not sure what they're going to do. He's improvising like a jazz band would do, but it's with robots. It's his own little orchestra. The result is beautiful. The result is also unexpected. Ólafur makes the fascinating point that usually your own improvisation is limited by your own muscle memory. But with the randomness of the robots you are forced to respond in different ways. He says you get a "pure unrestricted creativity." And it's fun he says with a big smile on his face.
Maybe programming will look something like the above video. Humans and AIs working together to produce software better than either can separately.
The computer as a creative agent, working in tandem with a human partner, to produce software, in a beautiful act of Continue reading
Google: Addressing Cascading Failures

Like the Spanish Inquisition, nobody expects cascading failures. Here's how Google handles them.
This excerpt is a particularly interesting and comprehensive chapter—Chapter 22 - Addressing Cascading Failures—from Google's awesome book on Site Reliability Engineering. Worth reading if it hasn't been on your radar. And it's free!
If at first you don't succeed, back off exponentially."
Why do people always forget that you need to add a little jitter?"
A cascading failure is a failure that grows over time as a result of positive feedback.107 It can occur when a portion of an overall system fails, increasing the probability that other portions of the system fail. For example, a single replica for a service can fail due to overload, increasing load on remaining replicas and increasing their probability of failing, causing a domino effect that takes down all the replicas for a service.
We’ll use the Shakespeare search service discussed in Shakespeare: A Sample Service as an example throughout this chapter. Its production configuration might look something like Figure 22-1.
 Figure 22-1. Example production configuration for the Shakespeare search service
Figure 22-1. Example production configuration for the Shakespeare search service
Causes of Cascading Failures and Designing to Avoid Them
Sponsored Post: Datadog, InMemory.Net, Triplebyte, Etleap, Scalyr, MemSQL
Who's Hiring?
- Triplebyte lets exceptional software engineers skip screening steps at hundreds of top tech companies like Apple, Dropbox, Mixpanel, and Instacart. Make your job search O(1), not O(n). Apply here.
- Need excellent people? Advertise your job here!
Fun and Informative Events
- Advertise your event here!
Cool Products and Services
- Datadog is a cloud-scale monitoring platform that combines infrastructure metrics, distributed traces, and logs all in one place. With out-of-the-box dashboards and seamless integrations with over 200 technologies, Datadog provides end-to-end visibility into the health and performance of modern applications at scale. Build your own rich dashboards, set alerts to identify anomalies, and collaborate with your team to troubleshoot and fix issues fast. Start a free trial and try it yourself.
- InMemory.Net provides a Dot Net native in memory database for analysing large amounts of data. It runs natively on .Net, and provides a native .Net, COM & ODBC apis for integration. It also has an easy to use language for importing data, and supports standard SQL for querying data. http://InMemory.Net
- For heads of IT/Engineering responsible for building an analytics infrastructure, Etleap is an ETL solution for creating perfect data Continue reading
Strategy: Use TensorFlow.js in the Browser to Reduce Server Costs
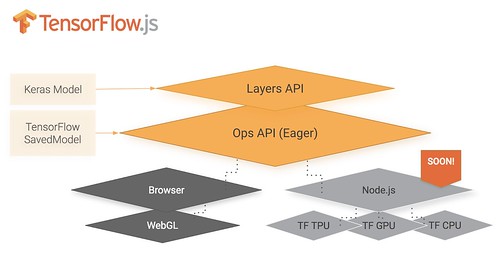
One of the strategies Jacob Richter describes (How we built a big data platform on AWS for 100 users for under $2 a month) in his relentless drive to lower AWS costs is moving ML from the server to the client.
Moving work to the client is a time honored way of saving on server side costs. Not long ago it might have seemed like moving ML to the browser would be an insane thing to do. What was crazy yesterday often becomes standard practice today, especially when it works, especially when it saves money:
Our post-processing machine learning models are mostly K-means clustering models to identify outliers. As a further step to reduce our costs, we are now running those models on the client side using TensorFlow.js instead of using an autoscaling EC2 container. While this was only a small change using the same code, it resulted in a proportionally massive cost reduction.
To learn more Alexis Perrier has a good article on Tensorflow with Javascript Brings Deep Learning to the Browser:
Tensorflow.js has four layers: The WebGL API for GPU-supported numerical operations, the web browser for user interactions, and two APIs: Continue reading