Cassandra NoSQL Data Model Design

We at Instaclustr recently published a blog post on the most common data modelling mistakes that we see with Cassandra. This post was very popular and led me to think about what advice we could provide on how to approach designing your Cassandra data model so as to come up with a quality design that avoids the traps.
There are a number of good articles around that with rules and patterns to fit your data model into: 6 Step Guide to Apache Cassandra Data Modelling and Data Modelling Recommended Practices.
However, we haven’t found a step by step guide to analysing your data to determine how to fit in these rules and patterns. This white paper is a quick attempt at filling that gap.
Phase 1: Understand the data
This phase has two distinct steps that are both designed to gain a good understanding of the data that you are modelling and the access patterns required.
Define the data domain
The first step is to get a good understanding of your data domain. As someone very familiar with relation data modelling, I tend to sketch (or at least think) ER diagrams to understand the entities, their keys and relationships. However, Continue reading
Stuff The Internet Says On Scalability For November 10th, 2017
Hey, it's HighScalability time:

Ah, the good old days. This is how the FBI stored finger prints in 1944. (Alex Wellerstein). How much data? Estimates range from 30GB to 2TB.
If you like this sort of Stuff then please support me on Patreon. Also, there's my new book, Explain the Cloud Like I'm 10, for complete cloud newbies.
- 1 million: times we touch our phones per year; 13 million: lines of Javascript @ Facebook; 256K: RAM needed for TensorFlow on a microcontroller; 2,502%: increase in the sale of ransomware on the dark web; 800 million: monthly Instagram users; 40%: VMs in Azure run Linux; 40%: improved GCP network latency from new SDN stack; 50%: fat content of a woolly mammoth;
- Quotable Quotes:
- Sean Parker: And that means that we [Facebook] need to sort of give you a little dopamine hit every once in a while, because someone liked or commented on a photo or a post or whatever. And that's going to get you to contribute more content, and that's going to get you ... more likes and comments
- David Gerard: I spent yesterday afternoon on Twitter Continue reading
Sponsored Post: Loupe, Etleap, Aerospike, Stream, Scalyr, VividCortex, Domino Data Lab, MemSQL, Zohocorp

Who's Hiring?
- Need excellent people? Advertise your job here!
Fun and Informative Events
- On-demand Webinar. Fast & Frictionless - The Decision Engine for Seamless Digital Business. In this session, guest speakers Michele Goetz, Principal Analyst at Forrester Research and Matthias Baumhof, VP Worldwide Engineering at ThreatMetrix, discuss: How risk-based authentication leveraging digital identities is key to empowering customer transactions; How real-time customer trust decisions can reduce fraud and improve customer satisfaction; How a high performance Hybrid Memory Architecture (HMA) database helps continuously evaluate across a multitude of factors to drive decisioning at the lowest operational cost. View now.
- Advertise your event here!
Cool Products and Services
- .NET developers dealing with Errors in Production: You know the pain of troubleshooting errors with limited time, limited information, and limited tools. Managers want to know what’s wrong right away, users don’t want to provide log data, and you spend more time gathering information than you do fixing the problem. To fix all that, Loupe was built specifically as a .NET logging and monitoring solution. Loupe notifies you about any errors and tells you all the information you need to fix them. It tracks performance metrics, identifies which errors cause Continue reading
Birth of the NearCloud: Serverless + CRDTs @ Edge is the New Next Thing
Kuhiro 10X Faster than Amazon Lambda
This is a guest post by Russell Sullivan, founder and CTO of Kuhirō.
Serverless is an emerging Infrastructure-as-a-Service solution poised to become an Internet-wide ubiquitous compute platform. In 2014 Amazon Lambda started the Serverless wave and a few years later Serverless has extended to the CDN-Edge and beyond the last mile to mobile, IoT, & storage.
This post examines recent innovations in Serverless at the CDN Edge (SAE). SAE is a sea change, it’s a really big deal, it marks the beginning of moving business logic from a single Cloud-region out to the edges of the Internet, which may eventually penetrate as far as servers running inside cell phone towers. When 5G arrives SAE will be only a few milliseconds away from billions of devices, the Internet will be transformed into a global-scale real-time compute-platform.
The journey of being a founder and then selling a NOSQL company, along the way architecting three different NOSQL data-stores, led me to realize that computation is currently confined to either the data-center or the device: the vast space between the two is largely untapped. So I teamed up with some Continue reading
Stuff The Internet Says On Scalability For November 3rd, 2017
Hey, it's HighScalability time:
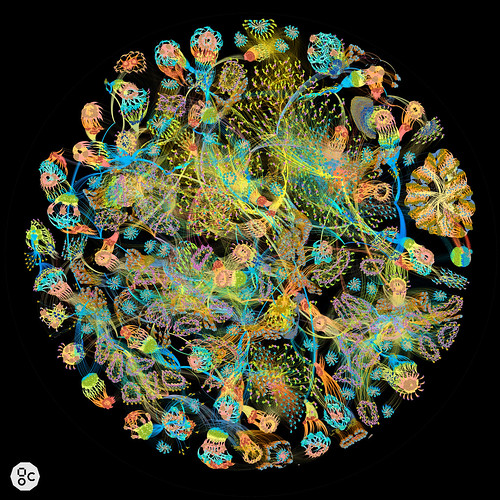
Luscious visualization of a neural network as a large directed graph. It's a full layout of the ResNet-50 training graph, a neural network with ~3 million nodes, and ~10 million edges, using Gephi for the graph layout, to output a 25000x25000 pixel image. (mattfyles)
If you like this sort of Stuff then please support me on Patreon. And take a look at Explain the Cloud Like I'm 10, my new book for complete cloud newbies. Thanks for your support! It means a lot to me.
- 96.4%: adversarial algorithm fools Google's image recognition; 70%+: GOOG and FB influence over internet traffic; 99%: bird reduction on farms using tuned laser guns; 52.45%: people playing my indie game have pirated it; 371,642: open-source projects depend on React; 6: words needed to ID you in email: 2x: node.js speed increase with Turbofan; 3: students who discovered 'Dieselgate'; 215KWh: energy consumed per bitcoin xaction, enough for a car to travel 1,000 miles; 33%: increase in Alphabet's quarterly profits; $1 billion: Amazon's ad business; 1 pixel: all it takes to Continue reading
Stuff The Internet Says On Scalability For October 27th, 2017
Hey, it's HighScalability time:
How a mutex works pic.twitter.com/TwFLAVs2yd
— ☠️??Cody??☠️ (@valarauca1) October 21, 2017
Perfect! Now, imagine a little dog snuck under Big Dog's cone of shame and covered the food with its own cone of shame, and it won't leave. That's deadlock. Imagine a stream of little dogs sneaking under Big Dog's cone so Big Dog nevers gets a bite. That's livelock.
- $100 billion: projected 2021 combined app store spend; 11 TB: SSD; 16: billion dollar disasters in the US this year; 8: meter long 3D printed bridge; 43%: employees who worry about losing their job due to their age; 125 TFLOPS: new AWS EC2 P3 instances; 7%: global Internet traffic flowing over QUIC; 50%: improvement in new in-package DRAM cache-management scheme; 43%: CockroachDB speed improvement executing parallel SQL statements; 325 billion: hours spent in Android apps in Q3; 4.5 million: C++ programmers; 3 trillion: ops per second in Pixel's Image Processing Unit; 80%: drop in Facebook referrals; 1,300 years: longest running business in the world; 40: age when tech Continue reading
Sponsored Post: Loupe, Etleap, Aerospike, Stream, Scalyr, VividCortex, Domino Data Lab, MemSQL, InMemory.Net, Zohocorp
Who's Hiring?
- Need excellent people? Advertise your job here!
Fun and Informative Events
- On-demand Webinar. Fast & Frictionless - The Decision Engine for Seamless Digital Business. In this session, guest speakers Michele Goetz, Principal Analyst at Forrester Research and Matthias Baumhof, VP Worldwide Engineering at ThreatMetrix, discuss: How risk-based authentication leveraging digital identities is key to empowering customer transactions; How real-time customer trust decisions can reduce fraud and improve customer satisfaction; How a high performance Hybrid Memory Architecture (HMA) database helps continuously evaluate across a multitude of factors to drive decisioning at the lowest operational cost. View now.
- Advertise your event here!
Cool Products and Services
- .NET developers dealing with Errors in Production: You know the pain of troubleshooting errors with limited time, limited information, and limited tools. Managers want to know what’s wrong right away, users don’t want to provide log data, and you spend more time gathering information than you do fixing the problem. To fix all that, Loupe was built specifically as a .NET logging and monitoring solution. Loupe notifies you about any errors and tells you all the information you need to fix them. It tracks performance metrics, identifies which errors cause Continue reading
One model at a time: Integrating and running Deep Learning models in production at EyeEm

This is a guest by Michele Palmia, now @EyeEm, good times @IBM, @UniPd and @UCC.
We’ve now been running computer vision models in production at EyeEm for more than three years - on literally billions of images. As an engineer involved in building the infrastructure behind it from scratch, I both enjoyed and suffered the many technical challenges this task raised. This journey has also taught me a lot about managing processes and relationships with different teams, tasks of an especially challenging nature in a dynamic startup environment.
What follows is an attempt to consolidate the computer vision pipeline history at EyeEm, some of the challenges we had to face, some of the learning we’ve gained, and a glimpse into its future.
Index the world’s photos
New Book: Explain the Cloud Like I’m 10
What is the cloud? Why is it called a cloud? How does the cloud work? What does it mean when something is 'in the cloud'?
I wrote a new book: Explain the Cloud Like I'm 10, answering those questions for the complete beginner. It makes the perfect gift for Halloween. And Thanksgiving. And Christmas. Oh, and birthdays too!
The irony is, if you read HighScalability, you're not the target audience :-) Explain the Cloud Like I'm 10 is for people who hear about the cloud everyday and have wondered what it is.
Talking with people outside the tech bubble I've found the cloud is still a mystery. I think that's because almost every explanation of the cloud I could find was a rewording of the same unhelpful technobabble.
In Explain the Cloud Like I'm 10 I've used a lot of pictures and a lot of examples. I go slow and easy. I try really hard to build up an intuitive understanding of what the cloud is and how it works.
If you know of anyone who might benefit from a book like this, I'd appreciate it if you'd pass it on.
thanks!

Stuff The Internet Says On Scalability For October 20th, 2017
Hey, it's HighScalability time:

Cassini's last image of Saturn, stitched together from 11 color composites, each a stack of three images taken in red, green, and blue channels. (Jason Major)
If you like this sort of Stuff then please support me on Patreon.
- 21 billion: max bitcoins ever; #2: Alibaba's cloud?; 1M MWh: Amazon Wind Farm Texas with 100 Turbines is live; $1000: cost to track someone with mobile ads; 20%: ebook sales of total; 17: qubit chip; 30%: Uber deep learning speedup using RDMA;
- Quoteable Quotes:
-
Tim O'Reilly: So what makes a real unicorn of this amazing kind? 1. It seems unbelievable at first. 2. It changes the way the world works. 3. It results in an ecosystem of new services, jobs, business models, and industries.
-
@rajivpant: AlphaGo has already beaten two of the world's best players. But the new AlphaGo Zero began with a blank Go board and no data apart from the rules, and then played itself. Within 72 hours it was good enough to beat the original AlphaGo by 100 games to zero!
-
-
ButterCMS Architecture: a Mission-Critical API Serving Millions of Requests per Month

This is a guest post by Jake Lumetta, co-founder and CEO of ButterCMS.
ButterCMS lets developers add a content management system to any website in minutes. Our business requires us to deliver near-100% uptime for our API, but after multiple outages that nearly crippled our business, we became obsessed with eliminating single points of failure. In this post, I’ll discuss how we use Fastly’s edge cloud platform and other strategies to make sure we keep our customers’ websites up and running.
At its core, ButterCMS offers:
-
A dashboard for content editors
-
A JSON API for fetching content
-
SDK’s for integrating ButterCMS into native code
ButterCMS Tech Stack
Stuff The Internet Says On Scalability For October 13th, 2017
Hey, it's HighScalability time:

Tech is transforming how food is being grown. Lots of opportunity for local nerdy production. Greenhouses even look like dartacenters! (This Tiny Country Feeds the World)
If you like this sort of Stuff then please support me on Patreon.
- 320 trillion: ops/second in Nvidia driverless-car computer; .25%: Lambda invocations impacted by cold starts; $30,000: monthly take hijacking computers to mine cryptocurrency; 400 gbps: Ethernet standard to be ratified this year; 2.1 million: MySQL 8.0 query/second; 100,000: Kiva robots owned by Amazon; 50,000: greenhouses in Egypt's new farm city; 100 petabytes: new hard drives ordered by Backblaze; 20 million: max Bitcoin users per month; 662 million: unused vacation days in US; 92 billion: Pornhub views per year; 1,000: new Facebook hires to review ads; 12 milion: Tinder matches per day; $1 billion: Google training grants;
- Quotable Quotes:
- @toddmotto: Space X sends a rocket up into space. Lands back on its feet back on earth 7minutes later. I can't even run an npm install in that time.
- nappy-doo: Years ago, I started at Google, and was in Charlie's Continue reading
Sponsored Post: Loupe, Etleap, Aerospike, Stream, Scalyr, VividCortex, Domino Data Lab, MemSQL, InMemory.Net, Zohocorp
Who's Hiring?
- Need excellent people? Advertise your job here!
Fun and Informative Events
- October 10 Live Webinar. Fast & Frictionless - The Decision Engine for Seamless Digital Business. Join us for a live webinar on Tuesday, October 10 at 11:00 am Pacific Time featuring guest speakers Michele Goetz, Principal Analyst at Forrester Research, and Matthias Baumhof, VP Worldwide Engineering at ThreatMetrix®. A positive customer experience is required for successful enterprise digital transformation. Digital businesses depend on speed and efficiency to drive operational decisions. Making faster, accurate, and real-time customer trust decisions removes friction and delivers superior business outcomes. In this session, you’ll learn: How risk-based authentication leveraging digital identities is key to empowering customer transactions; How real-time customer trust decisions can reduce fraud and improve customer satisfaction; How a high performance Hybrid Memory Architecture (HMA) database helps continuously evaluate across a multitude of factors to drive decisioning at the lowest operational cost. Register now.
- Advertise your event here!
Cool Products and Services
- .NET developers dealing with Errors in Production: You know the pain of troubleshooting errors with limited time, limited information, and limited tools. Managers want to know what’s wrong right away, users don’t want to provide Continue reading
What will programming look like in the future?
Maybe programming will look something like the above video. Humans and AIs working together to produce software better than either can separately.
The computer as a creative agent, working in tandem with a human partner, to produce software, in a beautiful act of co-creation.
The alternative vision—The Coming Software Apocalypse—is a dead end. Better requirements and better tools have already been tried and found wanting. Requirements are a trap. They don't work. Requirements are no less complex and undiscoverable than code. Tools are another trap. Tools are just code that encode an inflexible solution to a problem that's already been solved.
Admittedly, I'm cheating. I have no idea how any of this will work, but here are the seeds of how it has already started:
- Jeff Dean On Large-Scale Deep Learning At Google
- Machine Learning Driven Programming: A New Programming For A New World
Here's what we do know: neither tools or requirements are a silver bullet, they are a method of incrementally improving software quality. Software production quantity is not increased at all.
What we need is a manufacturing process that puts software production on an exponential curve. The only conceivable tool we have at Continue reading
Stuff The Internet Says On Scalability For October 6th, 2017
Hey, it's HighScalability time:

LiDAR sees an enchanted world. (Luminar)
If you like this sort of Stuff then please support me on Patreon.
- 14TB: Western Digital Hard Drive; 3B: Yahoo's perfidy; ~80%: companies traded on U.S. stock market 1950-2009 were gone by 2009; 21%: conversion increase with AI-enabled site personalisation; $1 billion: US Air Force jets off the cloud; 1 billion: iOS devices in use; 1000x: new DeepMind WaveNet model produces 20 seconds of higher quality audio in 1 second; 96: vCPUs on new GCE machine type, with 624GB of memory;
- Quotable Quotes:
- fusiongyro: The amount of incipient complexity in programming has been growing, not going down. What's more complex, "hello, world" to the console in Python, or "hello world" in a browser with the best and newest web stack? Mobility and microservices create lots of new edge cases and complexity—do non-programmers seem particularly well-equipped to handle edge cases to you? The problem has never really been the syntax—if it were, non-programmers would have made great strides with Applescript and SQL, and we'd all be building PowerBuilder libraries for a living. The problem is Continue reading
Ripple: The Most (Demonstrably) Scalable Blockchain

Ripple’s XRP Ledger is a blockchain-based payment network that transfers funds between any type of currency within a few seconds with average transaction costs of a fraction of a penny. The core of this peer-to-peer network is an open source C++ application called rippled. Ripple’s goal is to supplant the world’s existing legacy payment networks. As such, scalability is a continuous goal. This document describes how the rippled team has integrated performance engineering into its development processes, and how this has contributed to throughput gains of over 1000%.
Performance engineering practices deliver benefits in addition to measurable performance gains. These include the ability to report on the capabilities of the software so that users can feel confident that their needs will be met by the system. Performance engineering informs capacity planning and optimal configuration of environments to support the application. Many performance problems are caught and addressed before customers notice them. As process automation improves, each change to the software can be quickly assessed for improvement or regression. This methodology also makes better use of developer time by helping choose the most effective tasks for improving performance. Any software project serious about supporting global scale should integrate performance engineering Continue reading
Stuff The Internet Says On Scalability For September 29th, 2017
Hey, it's HighScalability time:
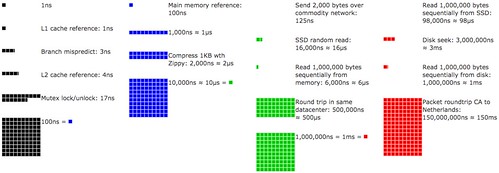
Latency Numbers Every Programmer Should Know plotted over time. Click on and move the slider to see changes. There were a lot more blocks in 1990.
If you like this sort of Stuff then please support me on Patreon.
- 1040: undergrads enrolled in Stanford's machine learning class; 39: minutes to travel from New York to Shanghai on Elon's rocket ride; $625,000: in stolen electronic-grade polysilicon; 160: terabits of data per second for Microsoft's new Trans-Atlantic Subsea Cable; 8K: people in Microsoft's AI group; 110%: increase in ICS/SCADA attacks from 2016 to 2017; 2 million: advertisers on Instagram; ~70%: savings using new Spot instance checkpointing; 10,000: nuts a year stored by a fox squirrel; $22.1 billion: IaaS market in 2016;
- Quotable Quotes:
- @patio11: Wife: "Hold hands when crossing the street." *2 year old grabs own hands* "OK Mommy." Me: "Oh you're going to be so good at programming."
- Charlie Demerjian: Intel’s “new” 8th Gen CPUs are a stopgap OEM placation to cover for a failed process, but they do bring some advances. As SemiAccurate sees it, Intel took .023 steps forward with Continue reading
Aligning Your Team around Microservices When There’s No Precise Definition

This is a guest post by Roger Jin, Software Architect at ButterCMS and co-author of Microservices for Startups.
For a profession that stresses the importance of naming things well, we've done ourselves a disservice with microservices. The problem is that that there is nothing inherently "micro" about microservices. Some can be small, but size is relative and there's no standard of unit of measure across organizations. A "small" service at one company might be one million lines of code while far less at another.
Some argue that microservices aren’t a new thing at all and rather a rebranding of Service Oriented Architectures, while others advocate for viewing microservices as an implementation of SOA similar to how Scrum is an implementation of Agile.
How do you align your team when no precise definitions of microservices exist? The most important thing when talking about microservices on a team is to ensure that you are grounded in a common starting point.
But ambiguous definitions don’t help with this. It would be like trying to put Agile into practice without context for what you are trying to achieve, or an understanding of precise methodologies like Scrum.
Finding common ground
Sponsored Post: Loupe, Etleap, Aerospike, Stream, Scalyr, VividCortex, Domino Data Lab, MemSQL, InMemory.Net, Zohocorp
Who's Hiring?
- Advertise your job here!
Fun and Informative Events
- October 10 Live Webinar. Fast & Frictionless - The Decision Engine for Seamless Digital Business. Join us for a live webinar on Tuesday, October 10 at 11:00 am Pacific Time featuring guest speakers Michele Goetz, Principal Analyst at Forrester Research, and Matthias Baumhof, VP Worldwide Engineering at ThreatMetrix®. A positive customer experience is required for successful enterprise digital transformation. Digital businesses depend on speed and efficiency to drive operational decisions. Making faster, accurate, and real-time customer trust decisions removes friction and delivers superior business outcomes. In this session, you’ll learn: How risk-based authentication leveraging digital identities is key to empowering customer transactions; How real-time customer trust decisions can reduce fraud and improve customer satisfaction; How a high performance Hybrid Memory Architecture (HMA) database helps continuously evaluate across a multitude of factors to drive decisioning at the lowest operational cost. Register now.
- Advertise your event here!
Cool Products and Services
- .NET developers dealing with Errors in Production: You know the pain of troubleshooting errors with limited time, limited information, and limited tools. Managers want to know what’s wrong right away, users don’t want to provide log data, and Continue reading
Adcash – 1 Trillion HTTP Requests Per Month
This is a guest post by Arnaud Granal, CTO at Adcash.
Adcash is a worldwide advertising platform. It belongs to a category called DSP (demand-side platform). A DSP is a platform where anyone can buy traffic from many different adnetworks.
The advertising ecosystem is very fragmented behind the two leaders (Google and Facebook) and DSPs help to solve this fragmentation problem.
If you want to run a campaign across 50 adnetworks, then you can imagine the hassle to do it on each adnetwork (different targetings, minimum to spend, quality issues, etc). What we do, is consolidate the ad inventory of the internet in one place and expose it through a self-service unified interface.
We are a technology provider; if you want to buy native advertisement, if you want to buy popups, if you want to buy banners, then it is your choice. The platform is free to use, we take a % on the success.
A platform like Adcash has to run on a very lean budget, you do not earn big money, you get micro-cents per transaction. It is not unusual to earn less than 0.0001 USD per impression.
Oh, by the way, we have 100 ms Continue reading