Stuff The Internet Says On Scalability For December 16th, 2016
Hey, it's HighScalability time:
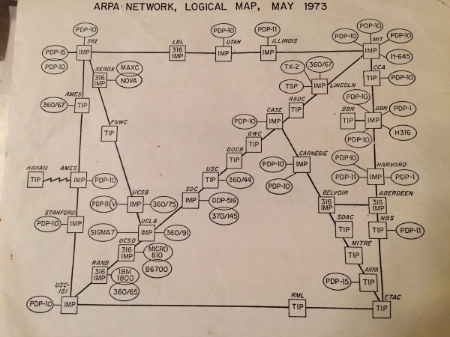
This is the entire internet. In 1973! David Newbury found the map going through his dad's old papers.
- 2.5 billion+: smartphones on earth; $36,000: loss making a VR game; $1 million: spent playing Game of War; 2000 terabytes: saved downloading Font Awesome's fonts per day; 14TB: new hard drives; 19: Systems We Love talks; 4,600Mbps: new 802.11ad Wi-Fi standard;
- Quotable Quotes:
- Thomas Friedman: [John] Doerr immediately volunteered to start a fund that would support creation of applications for this device by third-party developers, but Jobs wasn’t interested at the time. He didn’t want outsiders messing with his elegant phone.
- Fastly: For every problem in computer networking there is a closed-box solution that offers the correct abstraction at the wrong cost.
-
ben stopford: The Data Dichotomy. Data systems are about exposing data. Services are about hiding it.
-
Ernie: just as Amazon invaded the CDN ecosystem with CloudFront and S3, CDNs are going to invade the cloud compute space of AWS.
- The Attention Merchants: When not chronicling death in its many forms, Continue reading
Ask High Scalability: How to build anonymous blockchain communication?
This question came in over the Internets. If you have any ideas please consider sharing them if you have the time...
I am building a 2 way subscription model I am working on a blockchain project where in I have to built a information/data portal where in I will have 2 types of users data providers and data recievers such that there should be anonimity between both of these.
Please guide me how can I leverage blockchain (I think Etherium would be useful in this context but not sure) so that data providers of my system can send messages to data receivers anonymously and vice versa data receivers can request for data through my system to data providers.
I believe, it work if we can create a system where in if a user has data, it will send description to the server, The system will host this description about data without giving the data provider details.
Simultaneously server will store info which user has the data. When data receiver user logs in to system and wants and sees the description of data and wants to analyze that data, it will send request to server for that data. This request is Continue reading
A Scalable Alternative to RESTful Communication: Mimicking Google’s Search Autocomplete with a Single MigratoryData Server

This is a guest post by Mihai Rotaru, CTO of MigratoryData.
Using the RESTful HTTP request-response approach can become very inefficient for websites requiring real-time communication. We propose a new approach and exemplify it with a well-known feature that requires real-time communication, and which is included by most websites: search box autocomplete.
Google, which is one of the most demanding web search environments, seems to handle about 40,000 searches per second according to an estimation made by Internet Live Stats. Supposing that for each search, a number of 6 autocomplete requests are made, we show that MigratoryData can handle this load using a single 1U server.
More precisely, we show that a single MigratoryData server running on a 1U machine can handle 240,000 autocomplete requests per second from 1 million concurrent users with a mean round-trip latency of 11.82 milliseconds.
The Current Approach and Its Limitations
Stuff The Internet Says On Scalability For December 9th, 2016
Hey, it's HighScalability time:

Here's a 1 TB hard drive in 1937. Twenty workers operated the largest vertical letter file in the world. 4000 SqFt. 3000 drawers, 10 feet long. (from @BrianRoemmele)
- 98%~ savings in green house gases using Gmail versus local servers; 2x: time spent on-line compared to 5 years ago; 125 million: most hours of video streamed by Netflix in one day; 707.5 trillion: value of trade in one region of Eve Online; $1 billion: YouTube's advertisement pay-out to the music industry; 1 billion: Step Functions predecessor state machines run per week in AWS retail; 15.6 million: jobs added over last 81 months;
- Quotable Quotes:
- Gerry Sussman~ in the 80s and 90s, engineers built complex systems by combining simple and well-understood parts. The goal of SICP was to provide the abstraction language for reasoning about such systems...programming today is more like science. You grab this piece of library and you poke at it. You write programs that poke it and see what it does. And you say, ‘Can I tweak it to do the thing Continue reading
Sponsored Post: Loupe, New York Times, ScaleArc, Aerospike, Scalyr, Gusto, VividCortex, MemSQL, InMemory.Net, Zohocorp

Who's Hiring?
- The New York Times is looking for a Software Engineer for its Delivery/Site Reliability Engineering team. You will also be a part of a team responsible for building the tools that ensure that the various systems at The New York Times continue to operate in a reliable and efficient manner. Some of the tech we use: Go, Ruby, Bash, AWS, GCP, Terraform, Packer, Docker, Kubernetes, Vault, Consul, Jenkins, Drone. Please send resumes to: [email protected]
- IT Security Engineering. At Gusto we are on a mission to create a world where work empowers a better life. As Gusto's IT Security Engineer you'll shape the future of IT security and compliance. We're looking for a strong IT technical lead to manage security audits and write and implement controls. You'll also focus on our employee, network, and endpoint posture. As Gusto's first IT Security Engineer, you will be able to build the security organization with direct impact to protecting PII and ePHI. Read more and apply here.
Fun and Informative Events
- Your event here!
Cool Products and Services
- A note for .NET developers: You know the pain of troubleshooting errors with limited time, limited information, and limited tools. Log management, exception tracking, Continue reading
The Tech that Turns Each of Us Into a Walled Garden

How we treat each other is based on empathy. Empathy is based on shared experience. What happens when we have nothing in common?
Systems are now being constructed so we’ll never see certain kinds of information. Each of us live in our own algorithmically created Skinner Box /silo/walled garden, fed only information AIs think will be simultaneously most rewarding to you and their creators (Facebook, Google, etc).
We are always being manipulated, granted, but how we are being manipulated has taken a sharp technology driven change and we should be aware of it. This is different. Scary different. And the technology behind it all is absolutely fascinating.
Divided We Are Exploitable
Stuff The Internet Says On Scalability For December 2nd, 2016
Hey, it's HighScalability time:

A phrase you've probably heard a lot this week: AWS announces...
- 18 minutes: latency to Mars; 100TB: biggest dynamodb table; 55M: visits to Kaiser were virtual; $2 Billion: yearly Uber losses; 91%: Apple's take of smartphone profits; 825: AI patents held by IBM; $8: hourly cost of a spot welding in the auto industry; 70%: Walmart website traffic was mobile; $3 billion: online black friday sales; 80%: IT jobs replaceable by automation; $7500: cost of the one terabit per second DDoS attack on Dyn;
- Quotable Quotes:
- @BotmetricHQ: #AWS is deploying tens of thousands of servers every day, enough to power #Amazon in 2005 when it was a $8.5B Enterprise. #reInvent
- bcantrill: From my perspective, if this rumor is true, it's a relief. Solaris died the moment that they made the source proprietary -- a decision so incredibly stupid that it still makes my head hurt six years later.
- Dropbox: it can take up to 180 milliseconds for data traveling by undersea cables at nearly the speed of Continue reading
How to Make Your Database 200x Faster Without Having to Pay More?

This is a guest repost Barzan Mozafari, an assistant professor at University of Michigan and an advisor to a new startup, snappydata.io, that recently launched an open source OLTP + OLAP Database built on Spark.
Almost everyone these days is complaining about performance in one way or another. It’s not uncommon for database administrators and programmers to constantly find themselves in a situation where their servers are maxed out, or their queries are taking forever. This frustration is way too common for all of us. The solutions are varied. The most typical one is squinting at the query and blaming the programmer for not being smarter with their query. Maybe they could have used the right index or materialized view or just re-write their query in a better way. Other times, you might have to spin up a few more nodes if your company is using a cloud service. In other cases, when your servers are overloaded with too many slow queries, you might set different priorities for different queries so that at least the more urgent one (e.g., CEO queries) finish faster. When the DB does not support priority queues, your admin might even cancel your Continue reading
Stuff The Internet Says On Scalability For November 25th, 2016
Hey, it's HighScalability time:

Margaret Hamilton was honored with the Presidential Medal of Freedom for writing Apollo guidance software. Oddly, she's absent from best programmers of all time lists.
- 98 seconds: before camera infected with malware; zeptosecond: smallest fragment of time ever measured; 50%: Google Cloud cheaper than AWS; 50%: of the world is on-line;
- Quotable Quotes:
- @skamille: Sometimes I think that human societies just weren't meant to scale to billions of people sharing arbitrary information
- @joshk0: At @GetArbor we use #kubernetes to host a 30K QPS ad-tech serving platform. Maybe smaller than Pokemon Go but nothing to sneeze at.
- HFT Guy: 2016 should be remembered as the year Google became a better choice than AWS. If 50% cheaper is not a solid argument, I don’t know what is.
- Glenn Marcus: Hybrid [Progressive Web App] development takes 260% more effort man hours than Native development.
- Bruce Schneier: I want to suggest another way of thinking about it in that everything is now a computer: This is not a phone. It’s a computer that makes phone calls. A refrigerator is Continue reading
IT Hare: Ultimate DB Heresy: Single Modifying DB Connection. Part I. Performanc

Sergey Ignatchenko continues his excellent book series with a new chapter on databases. This is a guest repost.
The idea of single-write-connection is used extensively in the post, as it's defined elsewhere I asked Sergey for a definition so the article would make a little more sense...
As for single-write-connection - I mean that there is just one app (named "DB Server" in the article) having a single DB connection to the database which is allowed to issue modifying statements (UPDATEs/INSERTs/DELETEs). This allows to achieve several important simplifications - first of all, all fundamentally non-testable concurrency issues (such as missing SELECT FOR UPDATE and deadlocks) are eliminated entirely, second - the whole thing becomes deterministic (which is a significant help to figure out bugs - even simple text logging has been seen to make the system quite debuggable, including post-mortem), and last but not least - this monopoly on updates can be used in quite creative ways to improve performance (in particular, to keep always-coherent app-level cache which can be like 100x-1000x more efficient than going to DB).
After we finished with all the preliminaries, we can now get to the interesting part – implementing our transactional DB and Continue reading
Sponsored Post: Loupe, New York Times, ScaleArc, Aerospike, Scalyr, Gusto, VividCortex, MemSQL, InMemory.Net, Zohocorp
Who's Hiring?
- The New York Times is looking for a Software Engineer for its Delivery/Site Reliability Engineering team. You will also be a part of a team responsible for building the tools that ensure that the various systems at The New York Times continue to operate in a reliable and efficient manner. Some of the tech we use: Go, Ruby, Bash, AWS, GCP, Terraform, Packer, Docker, Kubernetes, Vault, Consul, Jenkins, Drone. Please send resumes to: [email protected]
- IT Security Engineering. At Gusto we are on a mission to create a world where work empowers a better life. As Gusto's IT Security Engineer you'll shape the future of IT security and compliance. We're looking for a strong IT technical lead to manage security audits and write and implement controls. You'll also focus on our employee, network, and endpoint posture. As Gusto's first IT Security Engineer, you will be able to build the security organization with direct impact to protecting PII and ePHI. Read more and apply here.
Fun and Informative Events
- Your event here!
Cool Products and Services
- A note for .NET developers: You know the pain of troubleshooting errors with limited time, limited information, and limited tools. Log management, exception tracking, Continue reading
Stuff The Internet Says On Scalability For November 18th, 2016
Hey, it's HighScalability time:

Now you don't have to shrink yourself to see inside a computer. Here's a fully functional 16-bit computer that's over 26 square feet huge! Bighex machine.
- 50%: drop in latency and CPU load after adopting PHP7 at Tumblr; 4,425: satellites for Skynet; 13%: brain connectome shared by identical twins; 20: weird & wonderful datasets for machine learning; 200 Gb/sec: InfiniBand data rate; 15 TB: data generated nightly by Large Synoptic Survey Telescope; 17.24%: top comments that were also first comments on reddit; $120 million: estimated cost of developing Kubernetes; 3-4k: proteins involved in the intracellular communication network;
- Quotable Quotes:
- Westworld: Survival is just another loop.
- Leo Laporte: All bits should be treated equally.
- Paul Horner: Honestly, people are definitely dumber. They just keep passing stuff around. Nobody fact-checks anything anymore
- @WSJ: "A conscious effort by a nation-state to attempt to achieve a specific effect" NSA chief on WikiLeaks
- encoderer: For the saas business I run, Cronitor, aws costs have consistently stayed around 10% total MRR. I think there are a lot Continue reading
The Story of Batching to Streaming Analytics at Optimizely
Our mission at Optimizely is to help decision makers turn data into action. This requires us to move data with speed and reliability. We track billions of user events, such as page views, clicks and custom events, on a daily basis. To provide our customers with immediate access to key business insights about their users has always been our top most priority. Because of this, we are constantly innovating on our data ingestion pipeline.
In this article we will introduce how we transformed our data ingestion pipeline from batching to streaming to provide our customers with real-time session metrics.
Motivations
Unification. Previously, we maintained two data stores for different use cases - HBase is used for computing Experimentation metrics, whereas Druid is used for calculating Personalization results. These two systems were developed with distinctive requirements in mind:
|
Experimentation |
Personalization |
|
Instant event ingestion |
Delayed event ingestion ok |
|
Query latency in seconds |
Query latency in subseconds |
|
Visitor level metrics |
Session level metrics |
As our business requirements evolve, however, things quickly became difficult to scale. Maintaining a Druid + HBase Lambda architecture (see below) to satisfy these business needs became a technical burden for the engineering team. We need a solution that Continue reading
How Urban Airship Scaled to 2.5 Billion Notifications During the U.S. Election

This is a guest post by Urban Airship. Contributors: Adam Lowry, Sean Moran, Mike Herrick, Lisa Orr, Todd Johnson, Christine Ciandrini, Ashish Warty, Nick Adlard, Mele Sax-Barnett, Niall Kelly, Graham Forest, and Gavin McQuillan
Urban Airship is trusted by thousands of businesses looking to grow with mobile. Urban Airship is a seven year old SaaS company and has a freemium business model so you can try it for free. For more information, visit www.urbanairship.com. Urban Airship now averages more than one billion push notifications delivered daily. This post highlights Urban Airship notification usage for the 2016 U.S. election, exploring the architecture of the system--the Core Delivery Pipeline--that delivers billions of real-time notifications for news publishers.
2016 U.S. Election
In the 24 hours surrounding Election Day, Urban Airship delivered 2.5 billion notifications—its highest daily volume ever. This is equivalent to 8 notification per person in the United States or 1 notification for every active smartphone in the world. While Urban Airship powers more than 45,000 apps across every industry vertical, analysis of the election usage data shows that more than 400 media apps were responsible for 60% of this record volume, sending 1.5 billion notifications Continue reading
Stuff The Internet Says On Scalability For November 11th, 2016
Hey, it's HighScalability time:

- 9 teraflops: PC GPU performance for VR rendering; 1.75 million requests per second: DDoS attack from cameras; 5GB/mo: average data consumption in the US; ~59.2GB: size of Wikipedia corpus; 50%: slower LTE within the last year; 5.4 million: entries in Microsoft Concept Graph; 20 microseconds: average round-trip latencies between 250,000 machines using direct FPGA-to-FPGA messages (Microsoft); 1.09 billion: Facebook daily active mobile users; 300 minutes: soaring time for an AI controlled glider; 82ms: latency streaming game play on Azure;
- Quotable Quotes:
- AORTA: Apple’s service revenue is now consistently greater than iPad and Mac revenue streams making it the number two revenue stream behind the gargantuan iPhone bucket.
- @GeertHub: Apple R&D budget: $10 billion NASA science budget: $5 billion One explored Pluto, the other made a new keyboard.
- Steve Jobs: tie all of our products together, so we further lock customers into our ecosystem
- @moxie: I think these types of posts are also the inevitable result of people overestimating our organizational capacity based Continue reading
Sponsored Post: Loupe, New York Times, ScaleArc, Aerospike, Scalyr, Gusto, VividCortex, MemSQL, InMemory.Net, Zohocorp
Who's Hiring?
- The New York Times is looking for a Software Engineer for its Delivery/Site Reliability Engineering team. You will also be a part of a team responsible for building the tools that ensure that the various systems at The New York Times continue to operate in a reliable and efficient manner. Some of the tech we use: Go, Ruby, Bash, AWS, GCP, Terraform, Packer, Docker, Kubernetes, Vault, Consul, Jenkins, Drone. Please send resumes to: [email protected]
- IT Security Engineering. At Gusto we are on a mission to create a world where work empowers a better life. As Gusto's IT Security Engineer you'll shape the future of IT security and compliance. We're looking for a strong IT technical lead to manage security audits and write and implement controls. You'll also focus on our employee, network, and endpoint posture. As Gusto's first IT Security Engineer, you will be able to build the security organization with direct impact to protecting PII and ePHI. Read more and apply here.
Fun and Informative Events
- Your event here!
Cool Products and Services
- A note for .NET developers: You know the pain of troubleshooting errors with limited time, limited information, and limited tools. Log management, exception tracking, Continue reading
The QuickBooks Platform

This is a guest post by Siddharth Ram – Chief Architect, Small Business. [email protected].
The QuickBooks ecosystem is the largest small business SaaS product. The QuickBooks Platform supports bookkeeping, payroll and payment solutions for small businesses, their customers and accountants worldwide. Since QuickBooks is also a compliance & tax filing platform, consistency in reporting is extremely important.. Financial reporting requires flexibility in queries – a given report may have dozens of different dimensions that can be tweaked. Collaboration requires multiple edits by employees, Accountants and Business owners at the same time, leading to potential conflicts. All this leads to solving interesting scaling problems at Intuit.
Solving for scalability requires thinking on multiple time horizons and axes. Scaling is not just about scaling software – it is also about people scalability, process scalability and culture scalability. All these axes are actively worked on at Intuit. Our goal with employees is to create an atmosphere that allows them to do the best work of their lives.
Background
Future Tidal Wave of Mobile Video
In this article I will examine the growing trends of Internet Mobile video and how consumer behaviour is rapidly adopting to a world of ‘always on content’ and discuss the impact on the underlying infrastructure.Gone Fishin’
Well, not exactly Fishin', but I'll be on a month long vacation starting today. I won't be posting (much) new content, so we'll all have a break. Disappointing, I know. Please use this time for quiet contemplation and other inappropriate activities. See you on down the road...

Datanet: a New CRDT Database that Let’s You Do Bad Bad Things to Distributed Data
We've had databases targeting consistency. These are your typical RDBMSs. We've had databases targeting availability. These are your typical NoSQL databases.
If you're using your CAP decoder ring you know what's next...what databases do we have that target making concurrency a first class feature? That promise to thrive and continue to function when network partitions occur?
No many, but we have a brand new concurrency oriented database: Datanet - a P2P replication system that utilizes CRDT algorithms to allow multiple concurrent actors to modify data and then automatically & sensibly resolve modification conflicts.
Datanet is the creation of Russell Sullivan. Russell spent over three years hidden away in his mad scientist layer researching, thinking, coding, refining, and testing Datanet. You may remember Russell. He has been involved with several articles on HighScalability and he wrote AlchemyDB, a NoSQL database, which was acquired by Aerospike.
So Russell has a feel for what's next. When he built AlchemyDB he was way ahead of the pack and now he thinks practical, programmer friendly CRDTs are what's next. Why?
Concurrency and data locality. To quote Russell:
Datanet lets you ship data to the spot where the action is happening. When the action happens it Continue reading