Stuff The Internet Says On Scalability For August 19th, 2016
Hey, it's HighScalability time:

- 4: SpaceX rocket landings at sea; 32TB: 3D Vertical NAND Flash; 10x: compute power for deep learning as the best of today’s GPUs; 87%: of vehicles could go electric without any range problems; 06%: visitors that post comments on NPR; 235k: terrorism related Twitter accounts closed; 40%: AMD improvement in instructions per clock for Zen; 15%: apps are slower is summer because of humidity;
- Quotable Quotes:
- @netik: There is no Internet of Things. There are only many unpatched, vulnerable small computers on the Internet.
- @Pinboard: The Programmers’ Credo: we do these things not because they are easy, but because we thought they were going to be easy
- Aphyr: This advantage is not shared by sequential consistency, or its multi-object cousin, serializability. This much, I knew–but Herlihy & Wing go on to mention, almost offhand, that strict serializability is also nonlocal!
- @PHP_CEO: I’VE HAD AN IDEA / WE’LL TAKE ALL THE BAD CODE / BUNDLE IT TOGETHER / AND SELL IT TO VCS Continue reading
Sponsored Post: Zohocorp, Exoscale, Host Color, Cassandra Summit, Scalyr, Gusto, LaunchDarkly, Aerospike, VividCortex, MemSQL, AiScaler, InMemory.Net

Who's Hiring?
-
IT Security Engineering. At Gusto we are on a mission to create a world where work empowers a better life. As Gusto's IT Security Engineer you'll shape the future of IT security and compliance. We're looking for a strong IT technical lead to manage security audits and write and implement controls. You'll also focus on our employee, network, and endpoint posture. As Gusto's first IT Security Engineer, you will be able to build the security organization with direct impact to protecting PII and ePHI. Read more and apply here.
Fun and Informative Events
- Join database experts from companies like Apple, ING, Instagram, Netflix, and many more to hear about how Apache Cassandra changes how they build, deploy, and scale at Cassandra Summit 2016. This September in San Jose, California is your chance to network, get certified, and trained on the leading NoSQL, distributed database with an exclusive 20% off with promo code - Academy20. Learn more at CassandraSummit.org
-
NoSQL Databases & Docker Containers: From Development to Deployment. What is Docker and why is it important to Developers, Admins and DevOps when they are using a NoSQL database? Find out in this on-demand webinar by Alvin Richards, Continue reading
How PayPal Scaled to Billions of Transactions Daily Using Just 8VMs

How did Paypal take a billion hits a day system that might traditionally run on a 100s of VMs and shrink it down to run on 8 VMs, stay responsive even at 90% CPU, at transaction densities Paypal has never seen before, with jobs that take 1/10th the time, while reducing costs and allowing for much better organizational growth without growing the compute infrastructure accordingly?
PayPal moved to an Actor model based on Akka. PayPal told their story here: squbs: A New, Reactive Way for PayPal to Build Applications. They open source squbs and you can find it here: squbs on GitHub.
The stateful service model still doesn't get enough consideration when projects are choosing a way of doing things. To learn more about stateful services there's an article, Making The Case For Building Scalable Stateful Services In The Modern Era, based on an great talk given by Caitie McCaffrey. And if that doesn't convince you here's WhatsApp, who used Erlang, an Akka competitor, to achieve incredible throughput: The WhatsApp Architecture Facebook Bought For $19 Billion.
I refer to the above articles because the PayPal article is short on architectural details. It's more about the factors the led the selection of Akka and the Continue reading
Stuff The Internet Says On Scalability For August 12th, 2016
Hey, it's HighScalability time:
The big middle finger to the Olympic Committee. They pulled this video of the incredibly beautiful Olympic cauldron at Rio.
- 25 years ago: the first website went online; $236M: Pokemon Go revenue in 5 weeks in 3 countriesSeveral thousand: work on Apple maps; 2500 Nimitz Carriers: weight of iPhone if implemented using tube transistors; $50 trillion: cost of iPhone in 1950, economic output of the world in your hand; 1000x: faster phase-change RAM; 15lbs: Americans heavier than 20 years ago; 2 years: for hacking the IRS; 3.6PB: hypothetical storage pod based on 60 TB SSD; 330,000: cash registers hacked; 162%: increased love for electric cars in China;
- Quotable Quotes:
- @carllerche: it is hard to imagine how a node app could get closer to the metal with only 20MM LOC between the app and the hardware.
- David Heinemeier Hansson (RoR)~ Lots and lots of huge systems that are running the gosh darn Internet are built by remote people operating asynchronously. You don't think that's good enough for your little Continue reading
10 Gameday Failure Testing Scenarios from Obama for America

I have dozens if not hundreds of half finished articles and snippets of ideas in the haunted house that is my Google Docs. Walking the house around midnight, with the lights turned off course, I stumbled upon one ghost that has been haunting me since 2012. It is time to perform the ritual of exorcism by just publishing something.
You may or may not remember Obama for America, which in 2012 had a staff of 120 people that built and maintained the infrastructure that helped get out the vote for Obama.
Harper Reed and Dylan Richard headed up the effort. Around that time they were getting a lot of press. One of the things that interested me was how they held Gameday test events, where they would simulate failure modes in their testing environments. Google calls these DiRT (Disaster Recovery Testing event) exercises.
So I asked Harper and Dylan what these exercises actually were and they were kind enough to reply. And I apparently forgot all about it. My apologies. Better late than never? Yah, let's go with that.
Here are some of the failure testing scenarios carried out by the Obama for America team:
- Flush memcache
- Continue reading
Stuff The Internet Says On Scalability For August 5th, 2016
Hey, it's HighScalability time:

What does a 107 football field long battery building Gigafactory look like? A lot like a giant Costco. (tour)
- 60 billion: Facebook messages per day; 3x: Facebook messages compared to global SMS traffic; $15: min wage increases job growth; 85,000: real world QPS for Twitter's search; 2017: when MRAM finally arrives; $60M: Bitcoin heist, bigger than any bank robbery; 710m: Internet users in China;
- Quotable Quotes:
- @cmeik: When @eric_brewer told me that Go was good for building distributed systems, I couldn't help but think about this.
- David Rosenthal: We can see the end of the era of data and computation abundance. Dealing with an era of constrained resources will be very different.In particular, enthusiasm for blockchain technology as A Solution To Everything will need to be tempered by its voracious demand for energy.
- Dr Werner Vogels: What we’ve seen is a revolution where complete applications are being stripped of all their servers, and only code is being run. Quite a few companies are ripping out big pieces of Continue reading
Is build back? The Fall of the General Purpose CPU
There's a meme out there that hardware is dead. Maybe not. Hardware is becoming more specialized as the general purpose CPU can't keep up. The tick-tock cycle created by Moore's law meant designers had a choice: build or buy. Make your own hardware to deep inspect 1gps of network traffic (for example) and release later or use an off-the-shelf CPU and release sooner.
Now in the anarchy of a Moore's lawless it looks like build is back. Jeff Dean is giving a talk at #scaledmlconf where he talks about this trend at Google.
CPU@jackclarkSF: Jeff Dean says Google can run its full Inception' v3 image model on a phone at about 6fps. And specialized ASICs are coming.
And Mo Patel captured this slide from the talk:


Sponsored Post: Exoscale, Host Color, Cassandra Summit, Scalyr, Gusto, LaunchDarkly, Aerospike, VividCortex, MemSQL, AiScaler, InMemory.Net
Who's Hiring?
-
IT Security Engineering. At Gusto we are on a mission to create a world where work empowers a better life. As Gusto's IT Security Engineer you'll shape the future of IT security and compliance. We're looking for a strong IT technical lead to manage security audits and write and implement controls. You'll also focus on our employee, network, and endpoint posture. As Gusto's first IT Security Engineer, you will be able to build the security organization with direct impact to protecting PII and ePHI. Read more and apply here.
Fun and Informative Events
- Join database experts from companies like Apple, ING, Instagram, Netflix, and many more to hear about how Apache Cassandra changes how they build, deploy, and scale at Cassandra Summit 2016. This September in San Jose, California is your chance to network, get certified, and trained on the leading NoSQL, distributed database with an exclusive 20% off with promo code - Academy20. Learn more at CassandraSummit.org
-
NoSQL Databases & Docker Containers: From Development to Deployment. What is Docker and why is it important to Developers, Admins and DevOps when they are using a NoSQL database? Find out in this on-demand webinar by Alvin Richards, Continue reading
How to Setup a Highly Available Multi-AZ Cassandra Cluster on AWS EC2

This is a guest post by Alessandro Pieri, Software Architect at Stream. Try out this 5 minute interactive tutorial to learn more about Stream’s API.
Originally built by Facebook in 2009, Apache Cassandra is a free and open-source distributed database designed to handle large amounts of data across a large number of servers. At Stream, we use Cassandra as the primary data store for our feeds. Cassandra stands out because it’s able to:
-
Shard data automatically
-
Handle partial outages without data loss or downtime
-
Scales close to linearly
If you’re already using Cassandra, your cluster is likely configured to handle the loss of 1 or 2 nodes. However, what happens when a full availability zone goes down?
In this article you will learn how to setup Cassandra to survive a full availability zone outage. Afterwards, we will analyze how moving from a single to a multi availability zone cluster impacts availability, cost, and performance.
Recap 1: What Are Availability Zones?
Stuff The Internet Says On Scalability For July 29th, 2016
Hey, it's HighScalability time:

- 40.4 million: iPhones sold this quarter; 7: number of times Facebook has avoided the IRS; 104: new exoplanets; 100: new brain regions found; 2x: HTTPS adoption;
- Quotable Quotes:
- @mat: Apple is doomed: "the nearly $8 billion in profits this quarter is more than twice what Facebook made in 2015"
- Bruce Schneier: The truth is that technology magnifies power in general, but the rates of adoption are different. The unorganized, the distributed, the marginal, the dissidents, the powerless, the criminal: they can make use of new technologies faster. And when those groups discovered the Internet, suddenly they had power. But when the already powerful big institutions finally figured out how to harness the Internet for their needs, they had more power to magnify. That’s the difference: the distributed were more nimble and were quicker to make use of their new power, while the institutional were slower but were able to use their power more effectively.
- @mjasay: What AWS does for AMZN: $2.89B in revenue Continue reading
Economics May Drive Serverless

We've been following an increasing ephemerality curve to get more and more utilization out of our big brawny boxes. VMs, VMs in the cloud, containers, containers in the cloud, and now serverless, which looks to be our first native cloud infrastructure.
Serverless is said to be about functions, but you really need a zip file of code to do much of anything useful, which is basically a container.
So serverless isn't so much about packaging as it is about not standing up your own chunky persistent services. Those services, like storage, like the database, etc, have moved to the environment.
Your code orchestrates the dance and implements specific behaviours. Serverless is nothing if not a framework writ large.
Serverless also intensifies the developer friendly disintermediation of infrastructure that the cloud started.
Upload your code and charge it on your credit card. All the developer has to worry about their function. Oh, and linking everything together (events, DNS, credentials, backups, etc) through a Byzantine patch panel of a UI; uploading each of your zillions of "functions" on every change; managing versions so you can separate out test, development, and production. But hey, nothing is perfect.
What may drive serverless more Continue reading
Stuff The Internet Says On Scalability For July 22nd, 2016
Hey, it's HighScalability time:

- 40%: energy Google saves in datacenters using machine learning; 2.3: times more energy knights in armor spend than when walking; 1000x: energy efficiency of 3D carbon nanotubes over silicon chips; 176,000: searchable documents from the Founding Fathers of the US; 93 petaflops: China’s Sunway TaihuLight; $800m: Azure's quarterly revenue; 500 Terabits per square inch: density when storing a bit with an atom; 2 billion: Uber rides; 46 months: jail time for accessing a database;
- Quotable Quotes:
- Lenin: There are decades where nothing happens; and there are weeks where decades happen.
- Nitsan Wakart: I have it from reliable sources that incorrectly measuring latency can lead to losing ones job, loved ones, will to live and control of bowel movements.
- Margaret Hamilton~ part of the culture on the Apollo program “was to learn from everyone and everything, including from that which one would least expect.”
- @DShankar: Basically @elonmusk plans to compete with -all vehicle manufacturers (cars/trucks/buses) -all ridesharing companies -all Continue reading
Building Highly Scalable V6 Only Cloud Hosting

This is a guest repost by Donatas Abraitis, Lead Systems Engineer at at Hostinger International.
This article is about how we built the new high scalable cloud hosting solution using IPv6-only communication between commodity servers, what problems we faced with IPv6 protocol and how we tackled them for handling more than ten millions active users.
Why did we decide to run IPv6-only network?
At Hostinger we care much about innovation technologies, thus we decided to run a new project named Awex that is based on this protocol. If we can, so why not start since today? Only frontend (user facing) services are running in dual-stack environment, everything else is IPv6-only for west-east traffic.
Architecture
Sponsored Post: Cassandra Summit, Scalyr, Gusto, LaunchDarkly, Awake Networks, Aerospike, VividCortex, MemSQL, AiScaler, InMemory.Net
Who's Hiring?
-
IT Security Engineering. At Gusto we are on a mission to create a world where work empowers a better life. As Gusto's IT Security Engineer you'll shape the future of IT security and compliance. We're looking for a strong IT technical lead to manage security audits and write and implement controls. You'll also focus on our employee, network, and endpoint posture. As Gusto's first IT Security Engineer, you will be able to build the security organization with direct impact to protecting PII and ePHI. Read more and apply here.
-
Awake Networks is an early stage network security and analytics startup that processes, analyzes, and stores billions of events at network speed. We help security teams respond to intrusions with super-human efficiency and provide macroscopic and microscopic insight into the networks they defend. We're looking for folks that are excited about building systems that handle scale in a constrained environment. We have many open-ended problems to solve around stream-processing, distributed systems, machine learning, query processing, data modeling, and much more! Please check out our jobs page to learn more.
Fun and Informative Events
- Join database experts from companies like Apple, ING, Instagram, Netflix, and many more to hear Continue reading
How Does Google do Planet-Scale Engineering for a Planet-Scale Infrastructure?
How does Google keep all its services up and running? They almost never seem to fail. If you've ever wondered we get a wonderful peek behind the curtain in a talk given at GCP NEXT 2016 by Melissa Binde, Director, Storage SRE at Google: How Google Does Planet-Scale Engineering for Planet-Scale Infrastructure.
Melissa's talk is short, but it's packed with wisdom and delivered in a no nonsense style that makes you think if your service is down Melissa is definitely the kind of person you want on the case.
Oh, just what is SRE? It stands for Site Reliability Engineering, but a definition is more elusive. It's like the kind of answers you get when you ask for a definition of the Tao. It's more a process than a thing, as is made clear by Ben Sloss 24x7 VP, Google, who defines SRE as:
what happens when a software engineer is tasked with what used to be called operations.
Let that bounce around your head for awhile.
Above and beyond all else one thing is clear: SREs are the custodian of production. SREs are the custodian of customer experience, for both google.com and GCP.
Some Continue reading
Stuff The Internet Says On Scalability For July 15th, 2016
Hey, it's HighScalability time:

- <2%: percent of total U.S. electricity consumption used by data centers; $4.99: hourly wage of Amazon Turkers; 8,072: cores in Cassandra cluster; .5: new reward for slaving away in the Bitcoin mines; 11: source code for the original Apollo guidance computer; 10 inverse femtobarns: number of collisions recorded by the Large Hadron Collider; 34 bps: using MEMO to send molecular messages through the air; 200 MB: record for storage in DNA; 10,000+: 3D printed parts are used in a Rolls-Royce Phantom; $43.6bn: IaaS revenue to triple by 2020;
- Quotable Quotes:
- @PokemonGoApp: To ensure all Trainers can experience #PokemonGo, we continue to add new resources to accommodate everyone. Thank you for your patience.
- @balajis: Pokemon Go is a classic overnight success, 10 years in the making. Ingress database, Google Maps, the Pokemon brand…
- @avantgame: The math of Pokemon Go is pretty amazing. 21 million players in ONE week, playing 43 minutes on average a day.
- @icecrime: Does Pokemon Go have generics?
- Continue reading
Why Amazon Retail Went to a Service Oriented Architecture

When Lee Atchison arrived at Amazon, Amazon was in the process of moving from a large monolithic application to a Service Oriented Architecture.
Lee talks about this evolution in an interesting interview on Software Engineering Daily: Scalable Architecture with Lee Atchison, about Lee's new book: Architecting for Scale: High Availability for Your Growing Applications.
This is a topic Adrian Cockcroft has talked a lot about in relation to his work at Netflix, but it's a powerful experience to hear Lee talk about how Amazon made the transition with us having the understanding of what Amazon would later become.
Amazon was running into the problems of success. Not so much from a scaling to handle the requests perspective, but they were suffering from the problem of scaling the number of engineers working in the same code base.
At the time their philosophy was based on the Two Pizza team. A small group owns a particular piece of functionality. The problem is it doesn’t work to have hundreds of pizza teams working on the same code base. It became very difficult to innovate and add new features. It even became hard to build the application, pass the test suites, and Continue reading
Vertical Scaling Works for Bits and Bites
This is just to delicious a parallel to pass up.
Here we have Google building a new four story datacenter Scaling Up: Google Building Four-Story Data Centers:

And here we have a new vertical farm from AeroFarms:

Both have racks of consumables. One is a rack of bits, the other is a rack of bites. Both used to sprawl horizontally across huge swaths of land and now are building up. Both designs are driven by economic efficiency, extracting the most value per square foot. Both are expanding to meet increased demand. It's a strange sort of convergence.
Stuff The Internet Says On Scalability For July 8th, 2016
Hey, it's HighScalability time:

- $3B: damages awarded to HP from Oracle; 37%: when to stop looking through your search period; 70%: observed Annualized Failure Rate (AFR) in production datacenters for some models of SSDs;
- Quotable Quotes:
- spacerodent: After Christmas there was this huge excess capacity and that is when I first learned of the EC2 project. It was my belief EC2 came out of a need to utilize those extra Gurupa servers during the off season:)
- bcantrill: That said, I think Sun's problem was pretty simple: we thought we were a hardware company long after it should have been clear that we were a systems company. As a result, we made overpriced, underperforming (and, it kills me to say, unreliable) hardware. And because we were hardware-fixated, we did not understand the economic disruptive force of either Intel or open source until it was too late.
- @cmeik: I am not convinced the blockchain and CRDTs *work.*
- daly: Managers make decisions. Only go to management with your Continue reading
Machine Learning Driven Programming: A New Programming for a New World
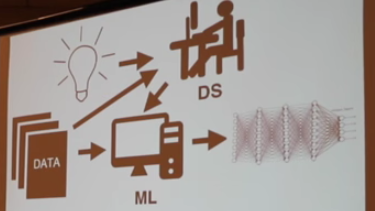
If Google were created from scratch today, much of it would be learned, not coded. Around 10% of Google's 25,000 developers are proficient in ML; it should be 100% -- Jeff Dean
Like the weather, everybody complains about programming, but nobody does anything about it. That’s changing and like an unexpected storm the change comes from an unexpected direction: Machine Learning / Deep Learning.
I know, you are tired of hearing about Deep Learning. Who isn’t by now? But programming has been stuck in a rut for a very long time and it's time we do something about it.
Lots of silly little programming wars continue to be fought that decide nothing. Functions vs objects; this language vs that language; this public cloud vs that public cloud vs this private cloud vs that ‘fill in the blank’; REST vs unrest; this byte level encoding vs some different one; this framework vs that framework; this methodology vs that methodology; bare metal vs containers vs VMs vs unikernels; monoliths vs microservices vs nanoservices; eventually consistent vs transactional; mutable vs immutable; DevOps vs NoOps vs SysOps; scale-up vs scale-out; centralized vs decentralized; single threaded vs massively parallel; sync vs async. And so Continue reading