Sponsored Post: Cassandra Summit, Gusto, LaunchDarkly, Awake Networks, Kinsta, Aerospike, InMemory.Net, VividCortex, MemSQL, Scalyr, AiScaler, AppDynamics, ManageEngine, Site24x7

Who's Hiring?
-
IT Security Engineering. At Gusto we are on a mission to create a world where work empowers a better life. As Gusto's IT Security Engineer you'll shape the future of IT security and compliance. We're looking for a strong IT technical lead to manage security audits and write and implement controls. You'll also focus on our employee, network, and endpoint posture. As Gusto's first IT Security Engineer, you will be able to build the security organization with direct impact to protecting PII and ePHI. Read more and apply here.
-
Awake Networks is an early stage network security and analytics startup that processes, analyzes, and stores billions of events at network speed. We help security teams respond to intrusions with super-human efficiency and provide macroscopic and microscopic insight into the networks they defend. We're looking for folks that are excited about building systems that handle scale in a constrained environment. We have many open-ended problems to solve around stream-processing, distributed systems, machine learning, query processing, data modeling, and much more! Please check out our jobs page to learn more.
- Software Engineer (DevOps). You are one of those rare engineers who loves to tinker with distributed systems at high Continue reading
Stuff The Internet Says On Scalability For July 1st, 2016
Hey, it's HighScalability time:
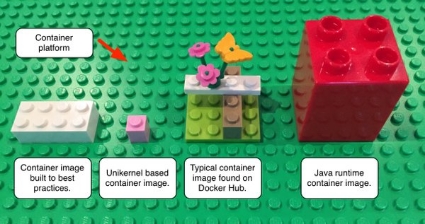
If you can't explain it with Legos then you don't really understand it.
- 700 trillion: more pixels in Google's Satellite Map; 9,000km: length of new undersea internet cable from Oregon to Japan; 60 terabits per second: that undersea internet cable again; 12%: global average connection speed increase; 76%: WeChat users who spend more than 100RMB ($15) per month; 5 liters: per day pay in beer for Pyramid workers; 680: number of rubber bands it takes to explode a watermelon; 1,000: new Amazon services this year; $15 billion: amount Uber has raised; 7 million: # of feather on on each bird in Piper; 5.8 million: square-feet in Tesla Gigafactory; 2x: full-duplex chip could double phone-network data capacity;
- Quotable Quotes:
- @hyc_symas: A shame everyone is implementing on top of HTTP today. Contemporary "protocol design" is a sick joke.
- @f3ew: Wehkamp lost dev and accept environments 5 days before launch. Shit happens. 48 hours to recovery. #devopsdays
- Greg Linden: Ultimately, [serverless computing] this is a good thing, making compute more efficient by allowing more overlapping workloads Continue reading
Scaling Hotjar’s Architecture: 9 Lessons Learned
 Hotjar offers free website analytics so they have a challenging mission: handle hundreds of millions of requests per day from mostly free users. Marc von Brockdorff, Co-Founder & Director of Engineering at Hotjar, summarized the lessons they've learned in: 9 Lessons Learned Scaling Hotjar's Tech Architecture To Handle 21,875,000 Requests Per Hour.
Hotjar offers free website analytics so they have a challenging mission: handle hundreds of millions of requests per day from mostly free users. Marc von Brockdorff, Co-Founder & Director of Engineering at Hotjar, summarized the lessons they've learned in: 9 Lessons Learned Scaling Hotjar's Tech Architecture To Handle 21,875,000 Requests Per Hour.
In response to the criticism their architecture looks like a hot mess, Erik Näslund, Chief Architect at Hotjar, gives the highlights of their architecture:
- We use nginx + lua for the really hot code paths where python doesn't quite cut it. No language is perfect and you might have to break out of your comfort zone and use something different every now and then.
- Redis, Memcached, Postgres, Elasticsearch and S3 are all suitable for different kinds of data storage and we eventually needed them all to be able to query and store data in a cost effective way. We didn't start out using 5 different data-stores though...it's something that we "grew into".
- Each application server is a (majestic) monolith. Micro-services are one way of architecting things, monoliths are another - I'm still waiting to be convinced that one way is superior to the other when it comes Continue reading
How Facebook Live Streams to 800,000 Simultaneous Viewers
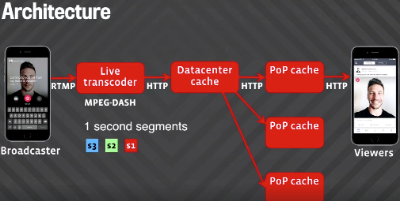
Fewer companies know how to build world spanning distributed services than there are countries with nuclear weapons. Facebook is one of those companies and Facebook Live, Facebook’s new live video streaming product, is one one of those services.
Facebook CEO Mark Zuckerberg:
The big decision we made was to shift a lot of our video efforts to focus on Live, because it is this emerging new format; not the kind of videos that have been online for the past five or ten years...We’re entering this new golden age of video. I wouldn’t be surprised if you fast-forward five years and most of the content that people see on Facebook and are sharing on a day-to-day basis is video.
If you are in the advertising business what could better than a supply of advertising ready content that is never ending, always expanding, and freely generated? It’s the same economics Google exploited when it started slapping ads on an exponentially growing web.
An example of Facebook’s streaming prowess is a 45 minute video of two people exploding a watermelon with rubber bands. It reached a peak of over 800,000 simultaneous viewers who also racked up over 300,000 comments. That’s Continue reading
Stuff The Internet Says On Scalability For June 24th, 2016
Hey, it's HighScalability time:
A complete and accurate demonstration of the internals of a software system.
- 79: podcasts for developers; 100 million: daily voice calls made on WhatsApp; 2,000; cars Tesla builds each week; 2078 lbs: weight it takes to burst an exercise ball; 500 million: Instagram users; > 100M: hours watched per day on Netflix; 400 PPM: Antarctica’s CO2 Level; 2.5 PB: New Relic SSD storage;
- Quotable Quotes:
- Alan Kay: The Internet was done so well that most people think of it as a natural resource like the Pacific Ocean, rather than something that was man-made. When was the last time a technology with a scale like that was so error-free? The Web, in comparison, is a joke. The Web was done by amateurs.
- @jaykreps: Actually, yes: distributed systems are hard, but getting 100+ engineers to work productively on one app is harder.
- @adrianco: All in 2016: Serverless Architecture: AWS Lambda, Codeless Architecture: Mendix, Architectureless Architecture: SaaS
- @AhmetAlpBalkan: "That's MS SQL Server running on Ubuntu on Docker Swarm on Docker Datacenter on @Azure" @markrussinovich #dockercon
- Erik Continue reading
The Technology Behind Apple Photos and the Future of Deep Learning and Privacy

There’s a war between two visions of how the ubiquitous AI assisted future will be rendered: on the cloud or on the device. And as with any great drama it helps the story along if we have two archetypal antagonists. On the cloud side we have Google. On the device side we have Apple. Who will win? Both? Neither? Or do we all win?
If you would have asked me a week ago I would have said the cloud would win. Definitely. If you read an article like Jeff Dean On Large-Scale Deep Learning At Google you can’t help but be amazed at what Google is accomplishing. Impressive. Wide ranging. Smart. Systematic. Dominant.
Apple has been largely absent from the trend of sprinkling deep learning fairy dust on their products. This should not be all that surprising. Apple moves at their own pace. Apple doesn’t reach for early adopters, they release a technology when it’s a win for the mass consumer market.
There’s an idea because Apple is so secretive they might have hidden away vast deep learning chops we don’t even know about yet. We, of course, have no way of knowing.
What may prove more true is that Continue reading
Stuff The Internet Says On Scalability For June 17th, 2016
Hey, it's HighScalability time:
- 4281: # of unread articles in my HackerNews feed; 23%: of all corporate cash is held by Microsoft, Apple, Google; 400 million: number of new servers needed by 2020; ~25,740TB: storage Backblaze adds per month; 3 bits: IBM stores per memory cell; 488 million: faked comments by China per year; 90%: revenue Spotify makes fron 30% of users; 780 million: miles of Tesla driving data; 4 days: median time to binge watch a season on Netlix; $33: cost of Nike Air Max; $50 billion: amount Apple has paid out to app developers; $270 million: amount Line makes from selling stickers; 4,600: # of trees Apple will plant aorund the Spaceship; 200 million: Google photos users; $1.8 billion: Series F round for Snapchat; 3x: capacity of the roadway with driverless cars; 138%: growth in Alibaba's cloud;
- Quotable Quotes:
- @swardley: By this time next year, AMZN should be comfortably worth Continue reading
The Image Optimization Technology that Serves Millions of Requests Per Day

This article will touch upon how Kraken.io built and scaled an image optimization platform which serves millions of requests per day, with the goal of maintaining high performance at all times while keeping costs as low as possible. We present our infrastructure as it is in its current state at the time of writing, and touch upon some of the interesting things we learned in order to get it here.
Let’s make an image optimizer
You want to start saving money on your CDN bills and generally speed up your websites by pushing less bytes over the wire to your user’s browser. Chances are that over 60% of your traffic are images alone.
Using ImageMagick (you did read ImageTragick, right?) you can slash down the quality of a JPEG file with a simple command:
$ convert -quality 70 original.jpg optimized.jpg
$ ls -la
-rw-r--r-- 1 matylla staff 5897 May 16 14:24 original.jpg
-rw-r--r-- 1 matylla staff 2995 May 16 14:25 optimized.jpg
Congratulations. You’ve just brought down the size of that JPEG by ~50% by butchering it’s quality. The image now looks like Minecraft. It can’t look like that - it sells your products Continue reading
Sponsored Post: Gusto, Awake Networks, Spotify, Telenor Digital, Kinsta, Aerospike, InMemory.Net, VividCortex, MemSQL, Scalyr, AiScaler, AppDynamics, ManageEngine, Site24x7
Who's Hiring?
-
IT Security Engineering. At Gusto we are on a mission to create a world where work empowers a better life. As Gusto's IT Security Engineer you'll shape the future of IT security and compliance. We're looking for a strong IT technical lead to manage security audits and write and implement controls. You'll also focus on our employee, network, and endpoint posture. As Gusto's first IT Security Engineer, you will be able to build the security organization with direct impact to protecting PII and ePHI. Read more and apply here.
-
Awake Networks is an early stage network security and analytics startup that processes, analyzes, and stores billions of events at network speed. We help security teams respond to intrusions with super-human efficiency and provide macroscopic and microscopic insight into the networks they defend. We're looking for folks that are excited about applying modern bleeding edge techniques to build systems that handle scale in a constrained environment. We have many open-ended problems to solve around stream-processing, distributed systems, machine learning, query processing, data modeling, and much more! Please check out our jobs page to learn more.
-
Site Reliability Engineer Manager. We at Spotify are looking for an engineering leader (Chapter Continue reading
Sponsored Post: Spotify, Telenor Digital, Kinsta, Aerospike, InMemory.Net, VividCortex, MemSQL, Scalyr, AiScaler, AppDynamics, ManageEngine, Site24x7
Who's Hiring?
-
Site Reliability Engineer Manager. We at Spotify are looking for an engineering leader (Chapter Lead) to manage the NYC part of the Site Reliability Engineering team. This team works with the infrastructure that powers the music service used by millions of users, built by hundreds of engineers. We create tools, develop infrastructure, and teach good practices to help Spotify engineers move faster. As a Chapter Lead your primary responsibility is to the people on your team: ensuring that the members are growing as engineers, doing valuable work, performing well, and generally having a great time at Spotify. Read more and apply here
-
Site Reliability Engineer. Spotify SREs design, code, and operate tools and systems to reduce the amount of time and effort necessary for our engineers to scale the world’s best music streaming product to 40 million users. We are strong believers in engineering teams taking operational responsibility for their products and work hard to support them in this. We work closely with engineers to advocate sensible, scalable, systems design and share responsibility with them in diagnosing, resolving, and preventing production issues. Read more and apply here
-
Backend Engineer. We at Spotify are looking for senior backend engineers Continue reading
Performance and Scaling in Enterprise Systems
This is a guest post from Vlad Mihalcea the author of the High-Performance Java Persistence book, on the notion of performance and scalability in enterprise systems.
An enterprise application needs to store and retrieve as much data and as fast as possible. In application performance management, the two most important metrics are response time and throughput.
The lower the response time, the more responsive an application becomes. Response time is, therefore, the measure of performance. Scaling is about maintaining low response times while increasing system load, so throughput is the measure of scalability.
Response time and throughput
Stuff The Internet Says On Scalability For May 6th, 2016
Hey, it's HighScalability time:
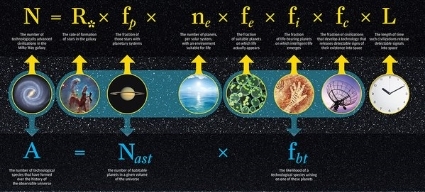
Who wants in on the over? We are not alone if the probability a habitable zone planet develops a technological species is larger than 10-24.
- 100,000+: bare metal servers run by Twitter; 10 billion: Snapchat videos delivered daily; $2.57 billion: AWS fourth quarter revenues; 40 light years: potentially habitable planets; 1700: seed banks around the world; 560x: throughput after SSD optimization; 12: data science algorithms; $2.8 billion: new value of Pivotal’s Cloud Foundry;
- Quotable Quotes:
- @skap5: Pied Piper's product is its stock and anything that makes its price go up! #SiliconValley
- Seth Godin: It pays to have big dreams but low overhead.
- Craig Venter~ Our knowledge of the genome hasn't changed a lot since 2003, but it's about to start changing rapidly. One of the key things for understanding the genome is to get very large numbers of genomes so we can understand out of the 6.2 billion or so letters of genetic code the less than 3% that we have different amongst the entire human population. We Continue reading
Gone Fishin’
Well, not exactly Fishin', but I'll be on a month long vacation starting today. I won't be posting (much) new content, so we'll all have a break. Disappointing, I know. Please use this time for quiet contemplation and other inappropriate activities. See you on down the road...

Stuff The Internet Says On Scalability For April 29th, 2016
Hey, it's HighScalability time:

The Universe in one image (Pablo Budassi). Imagine an ancient being leaning over, desperately scrying to figure out what they have wrought.
-
50 minutes: Facebook daily average use; 1.65 billion: Facebook Monthly active users; 25PB: size of Internet archive; 7 years: speedup of encryption adoption from the Snowden revelations; 10 million: strands of DNA Microsoft is buying to store data; 300TB: open data from CERN; 2PB: data from PanSTARRS' imaging survey; 100 billion: words translated by Google per day; 204 million: Weather Channel views in March on Facebook;
- Quotable Quotes:
- @antevens: -> Describe your perfect date. ......<- YYYY-MM-DD HH:MM:SS.XXXXXX
- @ValaAfshar: 1995: top 15 Internet companies worth $17 billion. 2015: top 15 Internet companies worth $2.4 trillion.
- @BenedictEvans: The move to mobile took away Facebook's monopoly of social, but gave it much greater scale, engagement & revenue potential.
- Sundar Pichai: We will move from mobile first to an AI first world.
- Chris Sacca~ We [Google] literally could feel a scale that had never been felt before on Continue reading
How Walmart Canada’s responsive redesign boosted conversions by 20%: a case Study
With conversion optimization on the rise, it is a great idea to look into case studies which help you learn and adopt them to your personal needs positively. To find the material on conversion optimization you need from case studies, here are some few pointers:
- Find out which case studies reflect your situation currently in business and your future aspirations.
- Find out why a certain aspect of a case study worked and how to adopt it to specifically address your website’s needs.
- Ensure you keep the references of your case study in order to go back to them when you need them.
Find out which case studies reflect your situation currently in business and your future aspirations.
Find out why a certain aspect of a case study worked and how to adopt it to specifically address your website’s needs.
Ensure you keep the references of your case study in order to go back to them when you need them.
Find out which case studies reflect your situation currently in business and your future aspirations.Find out why a certain aspect of a case study worked and how to adopt it to specifically address your website’s needs.Ensure you keep the Continue reading
The Platform Advantage of Amazon, Facebook, and Google

Where’s the magic? [Amazon] The databasing and streaming and syncing infrastructure we build on is pretty slick, but that’s not the secret. The management tools are nifty, too; but that’s not it either. It’s the tribal knowledge: How to build Cloud infrastructure that works in a fallible, messy, unstable world.
Tim Bray, Senior Principal Engineer at Amazon, in Cloud Eventing
Ben Thompson makes the case in Apple's Organizational Crossroads and in a recent episode of Exponent that Apple has a services problem. With the reaching of peak iPhone Apple naturally wants to turn to services as a way to expand revenues. The problem is Apple has a mixed history of delivering services at scale and Ben suggests that the strength of Apple, its functional organization, is a weakness when it comes to making services. The same skill set you need to create great devices is not the same skill set you need to create great services. He suggests: “Apple’s services need to be separated from the devices that are core to the company, and the managers of those services need to be held accountable via dollars and cents.”
If Apple has this problem they are not the only Continue reading
Sponsored Post: Aerospike, TrueSight Pulse, Redis Labs, InMemory.Net, VividCortex, MemSQL, Scalyr, AiScaler, AppDynamics, ManageEngine, Site24x7
Who's Hiring?
- Software Engineer (DevOps). You are one of those rare engineers who loves to tinker with distributed systems at high scale. You know how to build these from scratch, and how to take a system that has reached a scalability limit and break through that barrier to new heights. You are a hands on doer, a code doctor, who loves to get something done the right way. You love designing clean APIs, data models, code structures and system architectures, but retain the humility to learn from others who see things differently. Apply to AppDynamics
- Software Engineer (C++). You will be responsible for building everything from proof-of-concepts and usability prototypes to deployment- quality code. You should have at least 1+ years of experience developing C++ libraries and APIs, and be comfortable with daily code submissions, delivering projects in short time frames, multi-tasking, handling interrupts, and collaborating with team members. Apply to AppDynamics
Fun and Informative Events
- Discover the secrets of scalability in IT. The cream of the Amsterdam and Berlin tech scene are coming together during TechSummit, hosted by LeaseWeb for a great day of tech talk. Find out how to build systems that will cope with constant change and Continue reading
The Joy of Deploying Apache Storm on Docker Swarm

This is a guest repost from Baqend Tech on deploying and redeploying an Apache Storm cluster on top of Docker Swarm instead of deploying on VMs. It's an interesting topic because of the experience Wolfram Wingerath called it "a real joy", which is not a phrase you hear often in tech. Curious, I asked what made using containers such a good experience over using VMs? Here's his reply:
Being pretty new to Docker and Docker Swarm, I'm sure there are many good and bad sides I am not aware of, yet. From my point of view, however, the thing that makes deployment (and operation in general) on top of Docker way more fun than on VMs or even on bare metal is that Docker abstracts from heterogeneity and many issues. Once you have Docker running, you can start something like a MongoDB or a Redis server with a single-line statement. If you have a Docker Swarm cluster, you can do the same, but Docker takes care of distributing the thing you just started to some server in your cluster. Docker even takes care of downloading the correct image in case you don't have it on your machine right now. You also Continue reading
Stuff The Internet Says On Scalability For April 22nd, 2016
Hey, it's HighScalability time:
A perfect 10. Really stuck that landing. Nadia Comaneci approves.
- $1B: Supercell’s Clash Royale projected annual haul; 3x: Messenger and WhatsApp send more messages than SMS; 20%: of big companies pay zero corporate taxes; Tens of TB's RAM: Netflix's Container Runtime; 1 Million: People use Facebook over Tor; $10.0 billion: Microsoft raining money in the cloud;
- Quotable Quotes:
- @nehanarkhede: @LinkedIn's use of @apachekafka:1.4 trillion msg/day, 1400 brokers. Powers database replication, change capture etc
- @kenkeiter~ Full-duplex on a *single antenna* -- this is huge. (single chip, too -- that's the other huge part, obviously)
- John Langford: In the next few years, I expect machine learning to solve no important world issues.
- Dan Rayburn: By My Estimate, Apple’s Internal CDN Now Delivers 75% Of Their Own Content
- @BenedictEvans: If Google sees the device as dumb glass, Apple sees the cloud as dumb pipes & dumb storage. Both views could lead to weakness
- @JordanRinke: We need less hackathons, more apprenticeships. Less bootcamps, more classes. Less rockstars, more mentors. Develop people instead of product
- @alicegoldfuss: Nagios screaming / Continue reading
How Twitter Handles 3,000 Images Per Second
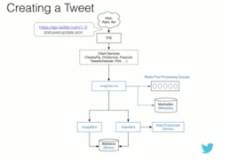
Today Twitter is creating and persisting 3,000 (200 GB) images per second. Even better, in 2015 Twitter was able to save $6 million due to improved media storage policies.
It was not always so. Twitter in 2012 was primarily text based. A Hogwarts without all the cool moving pictures hanging on the wall. It’s now 2016 and Twitter has moved into to a media rich future. Twitter has made the transition through the development of a new Media Platform capable of supporting photos with previews, multi-photos, gifs, vines, and inline video.
Henna Kermani, a Software Development Engineer at Twitter, tells the story of the Media Platform in an interesting talk she gave at Mobile @Scale London: 3,000 images per second. The talk focuses primarily on the image pipeline, but she says most of the details also apply to the other forms of media as well.
Some of the most interesting lessons from the talk:
-
Doing the simplest thing that can possibly work can really screw you. The simple method of uploading a tweet with an image as an all or nothing operation was a form of lock-in. It didn’t scale well, especially on poor networks, which made it Continue reading