Strategy: Taming Linux Scheduler Jitter Using CPU Isolation and Thread Affinity

When nanoseconds matter you have to pay attention to OS scheduling details. Mark Price, who works in the rarified high performance environment of high finance, shows how in his excellent article on Reducing system jitter.
For a tuning example he uses the famous Disrupter inter-thread messaging library. The goal is to keep the OS continuously feeding CPUs work from high priority threads. His baseline test shows the fastest message is sent in 76 nanoseconds, 1 in 100 messages took longer than 2 milliseconds, and the longest delay was 11 milliseconds.
The next section of the article shows in loving detail how to bring those latencies lower and more consistent, a job many people will need to do in practice. You'll want to read the article for a full explanation, including how to use perf_events and HdrHistogram. It's really great at showing the process, but in short:
- Turning off power save mode on the CPU reduced brought the max latency from 11 msec down to 8 msec.
- Guaranteeing threads will always have CPU resources using CPU isolation and thread affinity brought the maximum latency down to 14 microseconds.
Related Articles
Sponsored Post: iStreamPlanet, Close.io, Instrumental, Location Labs, Enova, Surge, Redis Labs, Jut.io, VoltDB, Datadog, SignalFx, InMemory.Net, VividCortex, MemSQL, Scalyr, AiScaler, AppDynamics, ManageEngine, Site24x7

Who's Hiring?
- As a Networking & Systems Software Engineer at iStreamPlanet you’ll be driving the design and implementation of a high-throughput video distribution system. Our cloud-based approach to video streaming requires terabytes of high-definition video routed throughout the world. You will work in a highly-collaborative, agile environment that thrives on success and eats big challenges for lunch. Please apply here.
- As a Scalable Storage Software Engineer at iStreamPlanet you’ll be driving the design and implementation of numerous storage systems including software services, analytics and video archival. Our cloud-based approach to world-wide video streaming requires performant, scalable, and reliable storage and processing of data. You will work on small, collaborative teams to solve big problems, where you can see the impact of your work on the business. Please apply here.
- Close.io is a *profitable* fast-growing SaaS startup looking for a Lead DevOps/Infrastructure engineer to join our ~10 person team in Palo Alto or *remotely*. Come help us improve API performance, tune our databases, tighten up security, setup autoscaling, make deployments faster and safer, scale our MongoDB/Elasticsearch/MySQL/Redis data stores, setup centralized logging, instrument our app with metric collection, set up better monitoring, etc. Learn more and apply here.
- Location Labs is Continue reading
How Facebook Tells Your Friends You’re Safe in a Disaster in Under Five Minutes
In a disaster there’s a raw and immediate need to know your loved ones are safe. I felt this way during 9/11. I know I’ll feel this way during the next wild fire in our area. And I vividly remember feeling this way during the 1989 Loma Prieta earthquake.
Most earthquakes pass beneath notice. Not this one and everyone knew it. After ceiling tiles stopped falling like snowflakes in the computer lab, we convinced ourselves the building would not collapse, and all thoughts turned to the safety of loved ones. As it must have for everyone else. Making an outgoing call was nearly impossible, all the phone lines were busy as calls poured into the Bay Area from all over the nation. Information was stuck. Many tense hours were spent in ignorance as the TV showed a constant stream of death and destruction.
It’s over a quarter of a century later, can we do any better?
Facebook can. Through a product called Safety Check, which connects friends and loved ones during a disaster. When a disaster hits Safety Check prompts people in the area to indicate if they are OK or not. Then Facebook closes the worry loop by Continue reading
Stuff The Internet Says On Scalability For September 25th, 2015
Hey, it's HighScalability time:

How long would you have lasted? Loved The Martian. Can't wait for the game, movie, and little potato action figures. Me, I would have died on the first level.
- 60 miles: new record distance for quantum teleportation; 160: size of minimum viable Mars colony; $3 trillion: assets managed by hedge funds; 5.6 million: fingerprints stolen in cyber attack; 400 million: Instagram monthly active users; 27%: increase in conversion rate from mobile pages that are 1 second faster; 12BN: daily Telegram messages; 1800 B.C: oldest beer recipe; 800: meetings booked per day at Facebook; 65: # of neurons it takes to walk with 6 legs
- Quotable Quotes:
- @bigdata: assembling billions of pieces of evidence: Not even the people who write algorithms really know how they work
- @zarawesome: "This is the most baller power move a billionaire will pull in this country until Richard Branson finally explodes the moon."
- @mtnygard: An individual microservice fits in your head, but the interrelationships among them exceeds any human's ability. Automate your awareness.
- Ben Thompson~ The mistake that lots of BuzzFeed imitators have made is to imitate Continue reading
How will new memory technologies impact in-memory databases?

This is a guest post by Yiftach Shoolman, Co-founder & CTO of redislabs. Will 3D XPoint change everything? Not as much as you might hope...
Recently, investors, analysts, partners and customers have asked me how the announcement from Intel and Micron about their new 3D XPoint memory technology will affect the in-memory databases market. In these discussions, a common question was “Who needs an in-memory database if all the non in-memory databases will achieve similar performance with 3D XPoint technology?” Well, I think that's a valid question so I've decided to take a moment to describe how we think this technology will influence our market.
First, a little background...
The motivation of Intel and Micron is clear -- DRAM is expensive and hasn’t changed much during the last few years (as shown below). In addition, there are currently only three major makers of DRAM on the planet (Samsung Electronics, Micron and SK Hynix), which means that the competition between them is not as cutthroat as it used to be between four and five major manufacturers several years ago.
DRAM Price Trends
Uber Goes Unconventional: Using Driver Phones as a Backup Datacenter
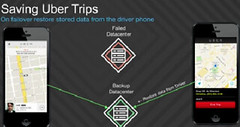
In How Uber Scales Their Real-Time Market Platform one of the most intriguing hints was how Uber handles datacenter failovers using driver phones as an external distributed storage system for recovery.
Now we know a lot more about how that system works from Uber's Nikunj Aggarwal and Joshua Corbin, who gave a very interesting talk at the @Scale conference: How Uber Uses your Phone as a Backup Datacenter.
Rather than use a traditional backend replication scheme where databases sync state between datacenters to achieve a measure of k-safety, Uber did something different, what they do is store enough state on driver phones so that if a datacenter failover occurs trip information can not be lost on the failover.
Why choose this approach? The traditional approach would be much simpler. I think it is to make sure the customer always has a good customer experience and losing trip information for an active trip would make for a horrible customer experience.
By building their syncing strategy around the phone, even thought it's complicated and takes a lot work, Uber is able to preserve trip data and make for a seamless customer experience even on datacenter failures. And making the customer Continue reading
Stuff The Internet Says On Scalability For September 18th, 2015
Hey, it's HighScalability time:

- terabits: Facebook's network capacity; 56.2 Gbps: largest extortion DDoS attack seen by Akamai; 220: minutes spent usings apps per day; $33 billion: 2015 in-app purchases; 2334: web servers running in containers on a Raspberry Pi 2; 121: startups valued over $1 billion
- Quotable Quotes:
- A Beautiful Question: Finding Nature's Deep Design: Two obsessions are the hallmarks of Nature’s artistic style: Symmetry—a love of harmony, balance, and proportion Economy—satisfaction in producing an abundance of effects from very limited means
- @Carnage4Life: ad blocking Apple has done to Google what Google did to MSFT. Added a feature they can't compete with without breaking their biz model
- @shellen: FWIW - Dreamforce is a localized weather system that strikes downtown SF every year causing widespread panic & bad slacks.
- @KentBeck: first you learn the value of abstraction, then you learn the cost of abstraction, then you're ready to engineer
- @doctorow: Arab-looking man of Syrian descent found in garage building what looks like a bomb
- @kixxauth: Idempotency is not something you take a pill for. -- ZeroMQ
- Continue reading
5 Lessons and 8 Industry Changes Over 5 Years as Etsy CTO

Endings are often a time for reflection and from reflection often comes wisdom. That is the case for Kellan Elliott-McCrea, who recently announced he was leaving his job after five successful years as the CTO of Etsy. Kellan wrote a rather remarkable going away post: Five years, building a culture, and handing it off, brimming with both insight and thoughtful commentary.
This post is just a short gloss of the major points. He goes into more depth on each point, so please read his post.
The Five Lessons:
- Nothing we “know” about software development should be assumed to be true.
- Technology is the product of the culture that builds it.
- Software development should be thought of as a cycle of continual learning and improvement rather a progression from start to finish, or a search for correctness.
- You build a culture of learning by optimizing globally not locally.
- If you want to build for the long term, the only guarantee is change.
The Eight Industry Changes:
- Five years ago, continuous deployment was still a heretical idea.
- Five years ago, it was crazy to discuss that monitoring, testing, debugging, QA, staged releases, game days, user research, and prototypes Continue reading
Sponsored Post: Microsoft, Instrumental, Location Labs, Enova, Librato, Surge, Redis Labs, Jut.io, VoltDB, Datadog, SignalFx, InMemory.Net, VividCortex, MemSQL, Scalyr, AiScaler, AppDynamics, ManageEngine, Site24x7
Who's Hiring?
- Microsoft’s Visual Studio Online team is building the next generation of software development tools in the cloud out in Durham, North Carolina. Come help us build innovative workflows around Git and continuous deployment, help solve the Git scale problem or help us build a best-in-class web experience. Learn more and apply.
- Are you someone who can efficiently spin up and maintain large production Linux deployments? Can you troubleshoot systems in the middle of the night as well as design them so that you don't have to wake up? If so, and you want to work with some of the best in the business, you will probably love the Infrastructure Group at Location Labs. Please apply here.
- As a Lead Software Engineer at Enova you’ll be one of Enova’s heavy hitters, overseeing technical components of major projects. We’re going to ask you to build a bridge, and you’ll get it built, no matter what. You’ll balance technical requirements with business needs, while advocating for a high quality codebase when working with full business teams. You’re fluent in ‘technical’ language and ‘business’ language, because you’re the engineer everyone counts on to understand how it works now, how it Continue reading
How Uber Scales Their Real-time Market Platform

Reportedly Uber has grown an astonishing 38 times bigger in just four years. Now, for what I think is the first time, Matt Ranney, Chief Systems Architect at Uber, in a very interesting and detailed talk--Scaling Uber's Real-time Market Platform---tells us a lot about how Uber’s software works.
If you are interested in Surge pricing, that’s not covered in the talk. We do learn about Uber’s dispatch system, how they implement geospatial indexing, how they scale their system, how they implement high availability, and how they handle failure, including the surprising way they handle datacenter failures using driver phones as an external distributed storage system for recovery.
The overall impression of the talk is one of very rapid growth. Many of the architectural choices they’ve made are a consequence of growing so fast and trying to empower recently assembled teams to move as quickly as possible. A lot of technology has been used on the backend because their major goal has been for teams to get the engineering velocity as high as possible.
After a understandably chaotic (and very successful) start it seems Uber has learned a lot about their business and what they really need to Continue reading
Stuff The Internet Says On Scalability For September 11th, 2015
Hey, it's HighScalability time:

- $100 million: amount Popcorn could have made from criminal business offers; 3.2-gigapixel: World’s Most Powerful Digital Camera; $17.3 trillion: US GDP in 2014; 700 million: Facebook time series database data points added per minute; 300PB: Facebook data stored in Hive; 5,000: Airbnb EC2 instances.
- Quotable Quotes:
- @jimmydivvy: NASA: Decade long flight across the solar system. Arrives within 72 seconds of predicted. No errors. Me: undefined is not a function
- Packet Pushers~ Everyone has IOPS now. We are heading towards invisible consumption being the big deal going forward.
- Randy Medlin: Gonna drop $1000+ on a giant iPad, $100 on a stylus, then whine endlessly about $4.99 drawing apps.
- Anonymous: Circuit Breaker + Real-time Monitoring + Recovery = Resiliency
- Astrid Atkinson: I used to get paged awake at two in the morning. You go from zero to Google is down. That’s a lot to wake up to.
- Todd Waters~ In 1979, 200MB weighed 30 lbs and took up the space of a washing machine
- Todd Waters~ CERN spends more compute Continue reading
Trade Stimulators and the Very Old Idea of Increasing User Engagement

Very early in my web career I was introduced to the almost mystical holy grail of web (and now app) properties: increasing user engagement.
The reason is simple. The more time people spend with your property the more stuff you can sell them. The more stuff you can sell the more value you have. Your time is money. So we design for addiction.
Famously Facebook, through the ties that bind, is the engagement leader with U.S. adults spending a stunning average of 42.1 minutes per day on Facebook. Cha-ching.
Immense resources are spent trying to make websites and apps sticky. Psychological tricks and gamification strategies are deployed with abandon to get you not to leave a website or to keep playing an app.
It turns out this is a very old idea. Casinos are designed to keep you gambling, for example. And though I’d never really thought about it before, I shouldn’t have been surprised to learn retail stores of yore used devices called trade stimulators to keep customers hanging around and spending money.
Never heard of trade stimulators? I hadn’t either until, while watching American Pickers, one of my favorite shows, they talked about this whole Continue reading
Want IoT? Here’s How a Major US Utility Collects Power Data from Over 5.5 Million Meters
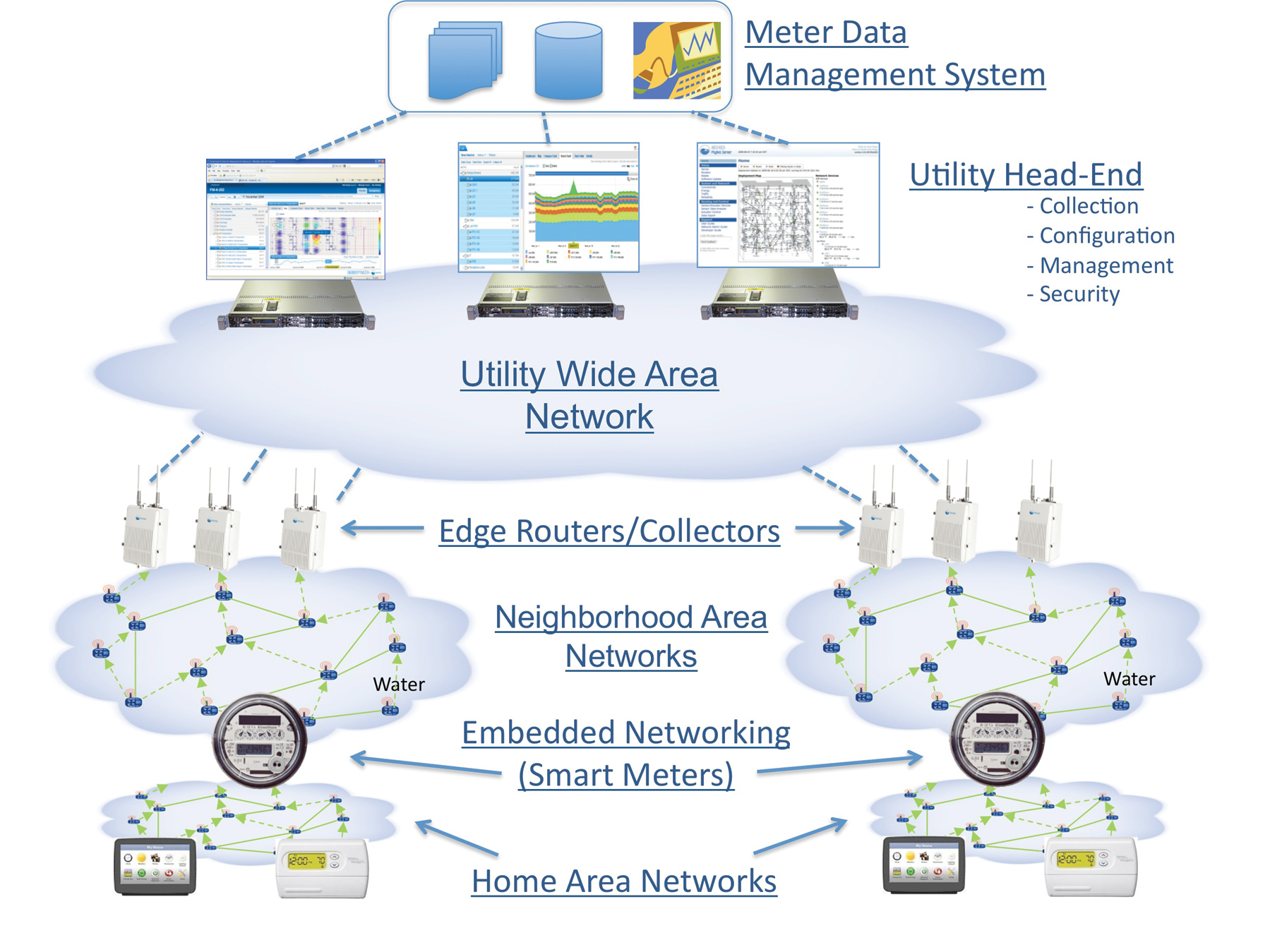
I serendipitously found this fascinating reply by Richard Farley, your friendly neighborhood meter reader, in a local email list giving a rare first-hand account of how the Advanced Metering Infrastructure works in California. This is real Internet of Things territory. So if it doesn't have a typical post structure that is why. He generously allowed it to be reposted with a few redactions. When you see “A Major US Utility”, please replace it with the most likely California power company.
Old mechanical meters had bearings that over time wore out and caused friction that threw off readings. That friction would cause the analog gauge to spin slower than it should, resulting in lower readings than actual usage -- hence "free power". It's like a clock falling behind over time as the gears wear down.
For A Major US Utility "estimated billing" happens when your meter, for whatever reason, was not able to be read. The algorithms approved by the CPUC and are almost always favorable to the consumer. A Major US Utility hates to have to do estimated billing because they almost always have to underestimate based on the algorithms and CPUC rules. Not 100% sure about this, but if they Continue reading
Stuff The Internet Says On Scalability For September 4th, 2015
Hey, it's HighScalability time:
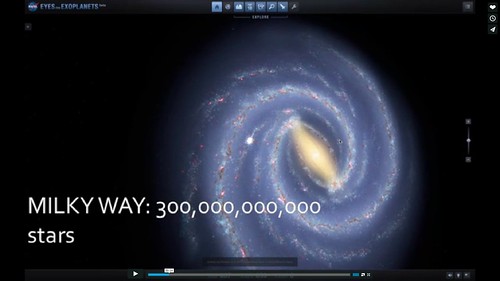
An astonishing 300 billion stars in our galaxy have planets. Take a look in the Eyes on Exoplanets app.
- 1 billion: people who used Facebook in a single day; 2.8 million: sq. ft. in new Apple campus (with drone pics); 1.1 trillion: Apache Kafka messages per day; 2,000 years: age of termite mounds in Central Africa; 30: # of times better the human brain is better than the best supercomputers; 4 billion: requests it took to trigger an underflow bug.
- Quotable Quotes:
- Sara Seager: If an Earth 2.0 exists, we have the capability to find and identify it by the 2020s.
- Android Dick: But you’re my friend, and I’ll remember my friends, and I’ll be good to you. So don’t worry, even if I evolve into Terminator, I’ll still be nice to you. I’ll keep you warm and safe in my people zoo, where I can watch you for ol’ times sake.
- @viktorklang: "If the conversation is typically “scale out” versus “scale up” if we’re coordination-free, we get to choose “scale out” while “scaling up.”
- Amir Najmi: At Google, data scientists are just Continue reading
How Agari Uses Airbnb’s Airflow as a Smarter Cron

This is a guest repost by Siddharth Anand, Data Architect at Agari, on Airbnb's open source project Airflow, a workflow scheduler for data pipelines. Some think Airflow has a superior approach.
Workflow schedulers are systems that are responsbile for the periodic execution of workflows in a reliable and scalable manner. Workflow schedulers are pervasive - for instance, any company that has a data warehouse, a specialized database typically used for reporting, uses a workflow scheduler to coordinate nightly data loads into the data warehouse. Of more interest to companies like Agari is the use of workflow schedulers to reliably execute complex and business-critical "big" data science workloads! Agari, an email security company that tackles the problem of phishing, is increasingly leveraging data science, machine learning, and big data practices typically seen in data-driven companies like LinkedIn, Google, and Facebook in order to meet the demands of burgeoning data and dynamicism around modeling.
In a previous post, I described how we leverage AWS to build a scalable data pipeline at Agari. In this post, I discuss our need for a workflow scheduler in order to improve the reliablity of our data pipelines, providing the previous post's pipeline Continue reading
Building Globally Distributed, Mission Critical Applications: Lessons From the Trenches Part 2

This is Part 2 of a guest post by Kris Beevers, founder and CEO, NSONE, a purveyor of a next-gen intelligent DNS and traffic management platform. Here's Part 1.
Integration and functional testing is crucial
Unit testing is hammered home in every modern software development class. It’s good practice. Whether you’re doing test-driven development or just banging out code, without unit tests you can’t be sure a piece of code will do what it’s supposed to unless you test it carefully, and ensure those tests keep passing as your code evolves.
In a distributed application, your systems will break even if you have the world’s best unit testing coverage. Unit testing is not enough.
You need to test the interactions between your subsystems. What if a particular piece of configuration data changes – how does that impact Subsystem A’s communication with Subsystem B? What if you changed a message format – do all the subsystems generating and handling those messages continue to talk with each other? Does a particular kind of request that depends on results from four different backend subsystems still result in a correct response after your latest code changes?
Unit tests don’t answer these questions, Continue reading
Sponsored Post: Microsoft , Librato, Surge, Redis Labs, Jut.io, VoltDB, Datadog, MongoDB, SignalFx, InMemory.Net, Couchbase, VividCortex, MemSQL, Scalyr, AiScaler, AppDynamics, ManageEngine, Site24x7
Who's Hiring?
- Microsoft’s Visual Studio Online team is building the next generation of software development tools in the cloud out in Durham, North Carolina. Come help us build innovative workflows around Git and continuous deployment, help solve the Git scale problem or help us build a best-in-class web experience. Learn more and apply.
- VoltDB's in-memory SQL database combines streaming analytics with transaction processing in a single, horizontal scale-out platform. Customers use VoltDB to build applications that process streaming data the instant it arrives to make immediate, per-event, context-aware decisions. If you want to join our ground-breaking engineering team and make a real impact, apply here.
- At Scalyr, we're analyzing multi-gigabyte server logs in a fraction of a second. That requires serious innovation in every part of the technology stack, from frontend to backend. Help us push the envelope on low-latency browser applications, high-speed data processing, and reliable distributed systems. Help extract meaningful data from live servers and present it to users in meaningful ways. At Scalyr, you’ll learn new things, and invent a few of your own. Learn more and apply.
- UI Engineer– AppDynamics, founded in 2008 and lead by proven innovators, Continue reading
Building Globally Distributed, Mission Critical Applications: Lessons From the Trenches Part 1
This is Part 1 of a guest post by Kris Beevers, founder and CEO, NSONE, a purveyor of a next-gen intelligent DNS and traffic management platform.
Every tech company thinks about it: the unavoidable – in fact, enviable – challenge of scaling its applications and systems as the business grows. How can you think about scaling from the beginning, and put your company on good footing, without optimizing prematurely? What are some of the key challenges worth thinking about now, before they bite you later on? When you’re building mission critical technology, these are fundamental questions. And when you’re building a distributed infrastructure, whether for reliability or performance or both, they’re hard questions to answer.
Putting the right architecture and processes in place will enable your systems and company to withstand the common hiccups distributed, high traffic applications face. This enables you to stay ahead of scaling constraints, manage inevitable network and system failures, stay calm and debug production issues in real-time, and grow your company and product successfully.
Who is this guy?
I’ve been building globally distributed, large scale applications for a long time. Way back in the first dot-com boom, I bailed on college classes for Continue reading
Stuff The Internet Says On Scalability For August 28th, 2015x
Hey, it's HighScalability time:

The oldest known fossil of a flowering plant. 130 million years old. What digital will last so long?
- 32.6: Ashley Madison password cracks per hour; 1 million: cores in the Human Brain Project's silicon brain; 54,000: tennis balls used at Wimbledon; 4 kB: size of first web page; 1.2 million: million messages per second Apache Samza performance on a single node; 27%: higher conversion for sites loading one second faster;
- Quotable Quotes:
- @adrianco: Apple first read about Mesos on http://highscalability.com and for a year have run Siri on the worlds biggest cluster
- @Besvinick: Interesting recurring sentiment from recent grads: We lived most of our college lives on Snapchat—now we don't have any "tangible" memories.
- Robin Hobb: For most moments of our lives, we have forgotten almost all of the world around us, except for what currently claims our interest.
- @Carnage4Life: I'd like to thank all the Amazon employees who cried at their desks to make this possible ?? ?????
- Jim Handy: The single most interesting thing I learned at the 2015 Flash Memory Summit was that 3D NAND doesn’t have a natural limit, after Continue reading
7 Strategies for 10x Transformative Change
 Peter Thiel, VC, PayPal co-founder, early Facebook investor, and most importantly, the supposed inspiration for Silicon Valley's intriguing Peter Gregory character, argues in his book Zero to One that a successful business needs to make a product that is 10 times better than its closest competitor.
Peter Thiel, VC, PayPal co-founder, early Facebook investor, and most importantly, the supposed inspiration for Silicon Valley's intriguing Peter Gregory character, argues in his book Zero to One that a successful business needs to make a product that is 10 times better than its closest competitor.
The title Zero to One refers to the idea of progress as either horizontal/extensive or vertical/intensive. For a more detailed explanation take a look at Peter Thiel's CS183: Startup - Class 1 Notes Essay.
Horizontal/extensive progress refers to copying things that work. Observe, imitate, and repeat. The one word summary for the concept is "globalization.” For more on this PAYPAL MAFIA: Reid Hoffman & Peter Thiel's Master Class in China is an interesting watch.
Vertical/intensive progress means doing something genuinely new, that is going from zero to one, as apposed to going from one to N, which is merely globalization. This is the creative spark. The hero's journey of over coming obstacles on the way to becoming the Master of the Universe you were always meant to be.
We see this pattern with Google a lot. Google often hits scaling challenges long before anyone else and because they have a systematizing culture they Continue reading