Cloudflare Acquires Linc


Cloudflare has always been about democratizing the Internet. For us, that means bringing the most powerful tools used by the largest of enterprises to the smallest development shops. Sometimes that looks like putting our global network to work defending against large-scale attacks. Other times it looks like giving Internet users simple and reliable privacy services like 1.1.1.1. Last week, it looked like Cloudflare Pages — a fast, secure and free way to build and host your JAMstack sites.
We see a huge opportunity with Cloudflare Pages. It goes beyond making it as easy as possible to deploy static sites, and extending that same ease of use to building full dynamic applications. By creating a seamless integration between Pages and Cloudflare Workers, we will be able to host the frontend and backend together, at the edge of the Internet and close to your users. The Linc team is joining Cloudflare to help us do just that.
Today, we’re excited to announce the acquisition of Linc, an automation platform to help front-end developers collaborate and build powerful applications. Linc has done amazing work with Frontend Application Bundles (FABs), making dynamic backends more accessible to frontend developers. Their Continue reading
Beat – An Acoustics Inspired DDoS Attack
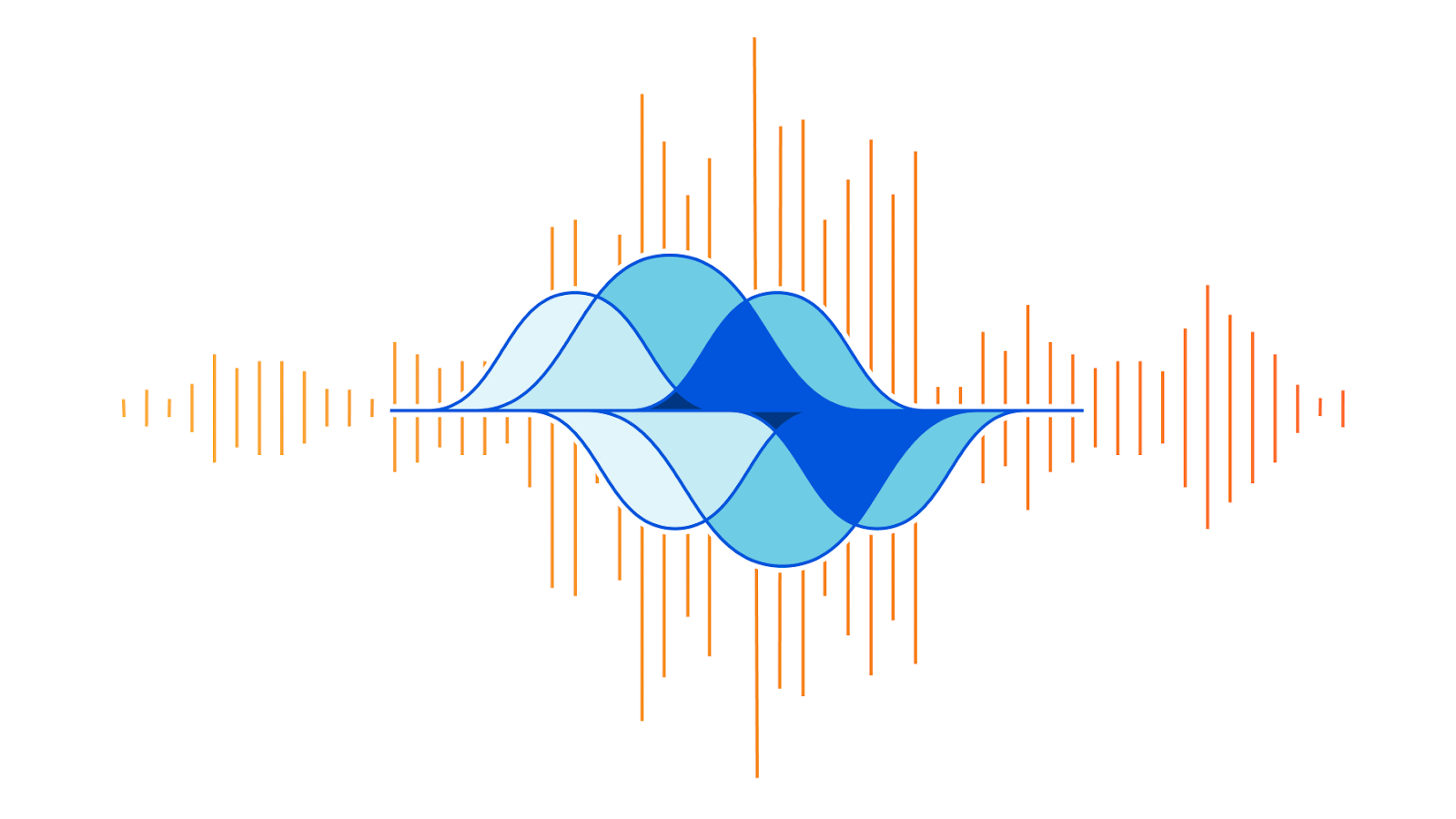
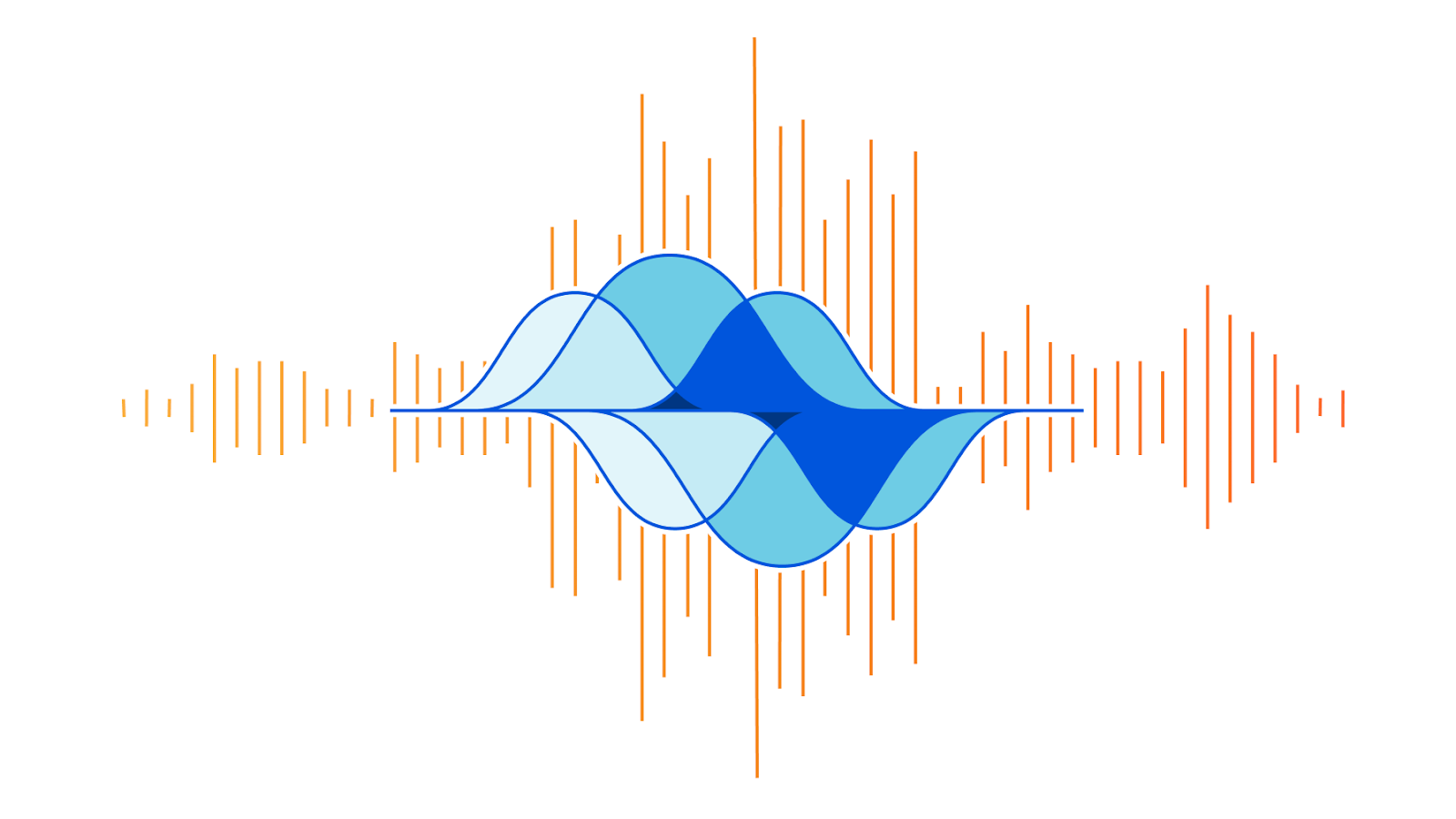
On the week of Black Friday, Cloudflare automatically detected and mitigated a unique ACK DDoS attack, which we’ve codenamed “Beat”, that targeted a Magic Transit customer. Usually, when attacks make headlines, it’s because of their size. However, in this case, it’s not the size that is unique but the method that appears to have been borrowed from the world of acoustics.
Acoustic inspired attack
As can be seen in the graph below, the attack’s packet rate follows a wave-shaped pattern for over 8 hours. It seems as though the attacker was inspired by an acoustics concept called beat. In acoustics, a beat is a term that is used to describe an interference of two different wave frequencies. It is the superposition of the two waves. When the two waves are nearly 180 degrees out of phase, they create the beating phenomenon. When the two waves merge they amplify the sound and when they are out of sync they cancel one another, creating the beating effect.
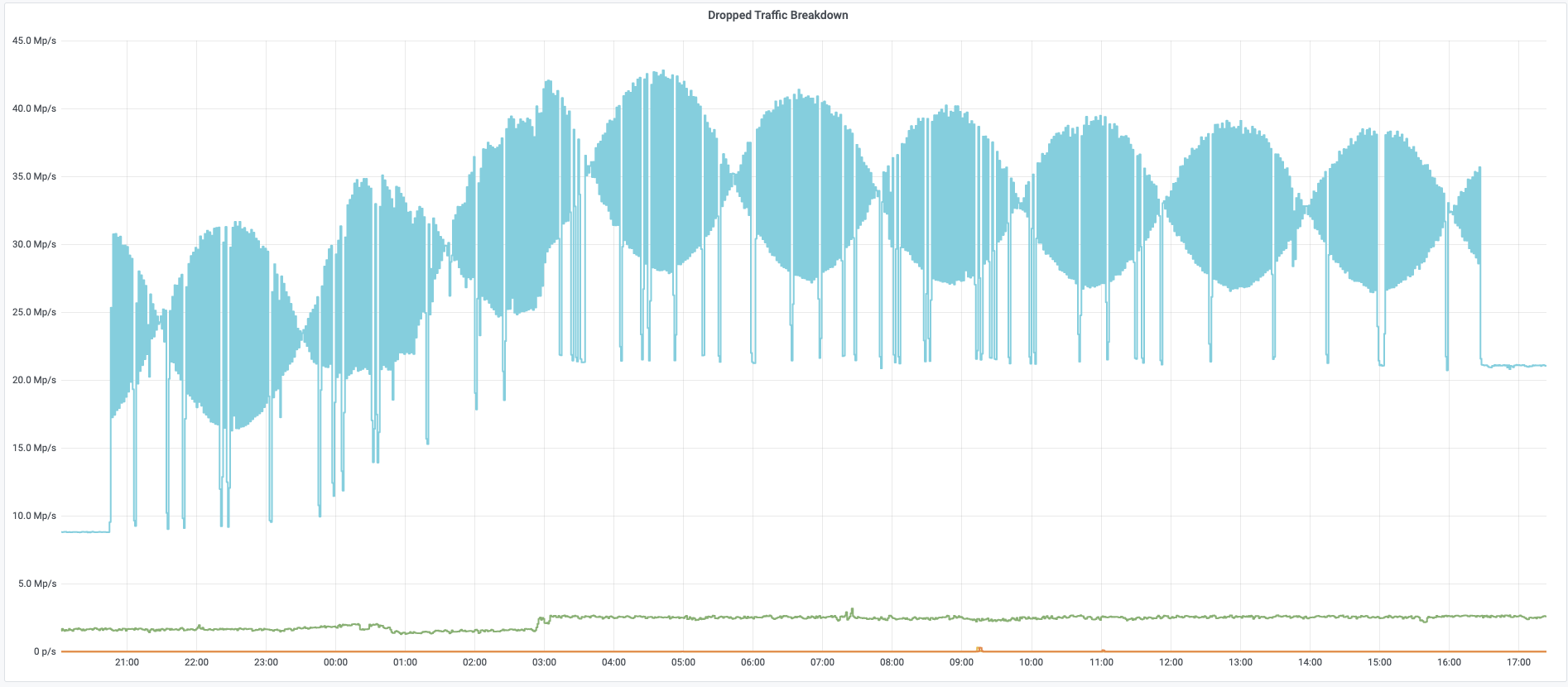
Acedemo.org has a nice tool where you can create your own beat wave. As you can see in the screenshot below, the two waves in blue and red are out Continue reading
Configure identity-based policies in Cloudflare Gateway

During Zero Trust Week in October, we released HTTP filtering in Cloudflare Gateway, which expands protection beyond DNS threats to those at the HTTP layer as well. With this feature, Cloudflare WARP proxies all Internet traffic from an enrolled device to a data center in our network. Once there, Cloudflare Gateway enforces organization-wide rules to prevent data loss and protect team members.
However, rules are not one-size-fits-all. Corporate policies can vary between groups or even single users. For example, we heard from customers who want to stop users from uploading files to cloud storage services except for a specific department that works with partners. Beyond filtering, security teams asked for the ability to audit logs on a user-specific basis. If a user account was compromised, they needed to know what happened during that incident.
We’re excited to announce the ability for administrators to create policies based on a user’s identity and correlate that identity to activity in the Gateway HTTP logs. Your team can reuse the same identity provider integration configured in Cloudflare Access and start building policies tailored to your organization today.
Fine-grained rule enforcement
Until today, organizations could protect their users' Internet-bound traffic by configuring DNS and HTTP Continue reading
Computing Euclidean distance on 144 dimensions
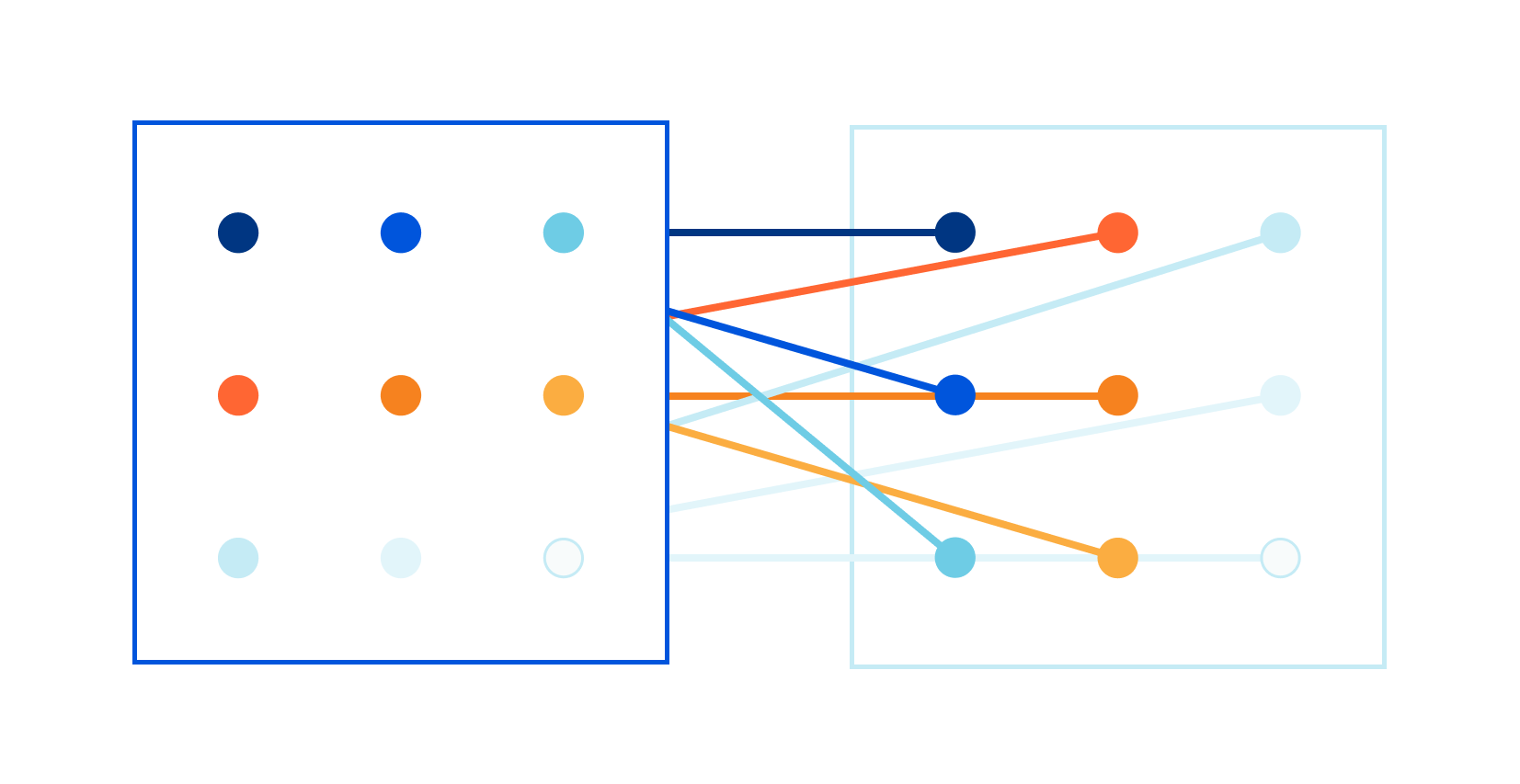
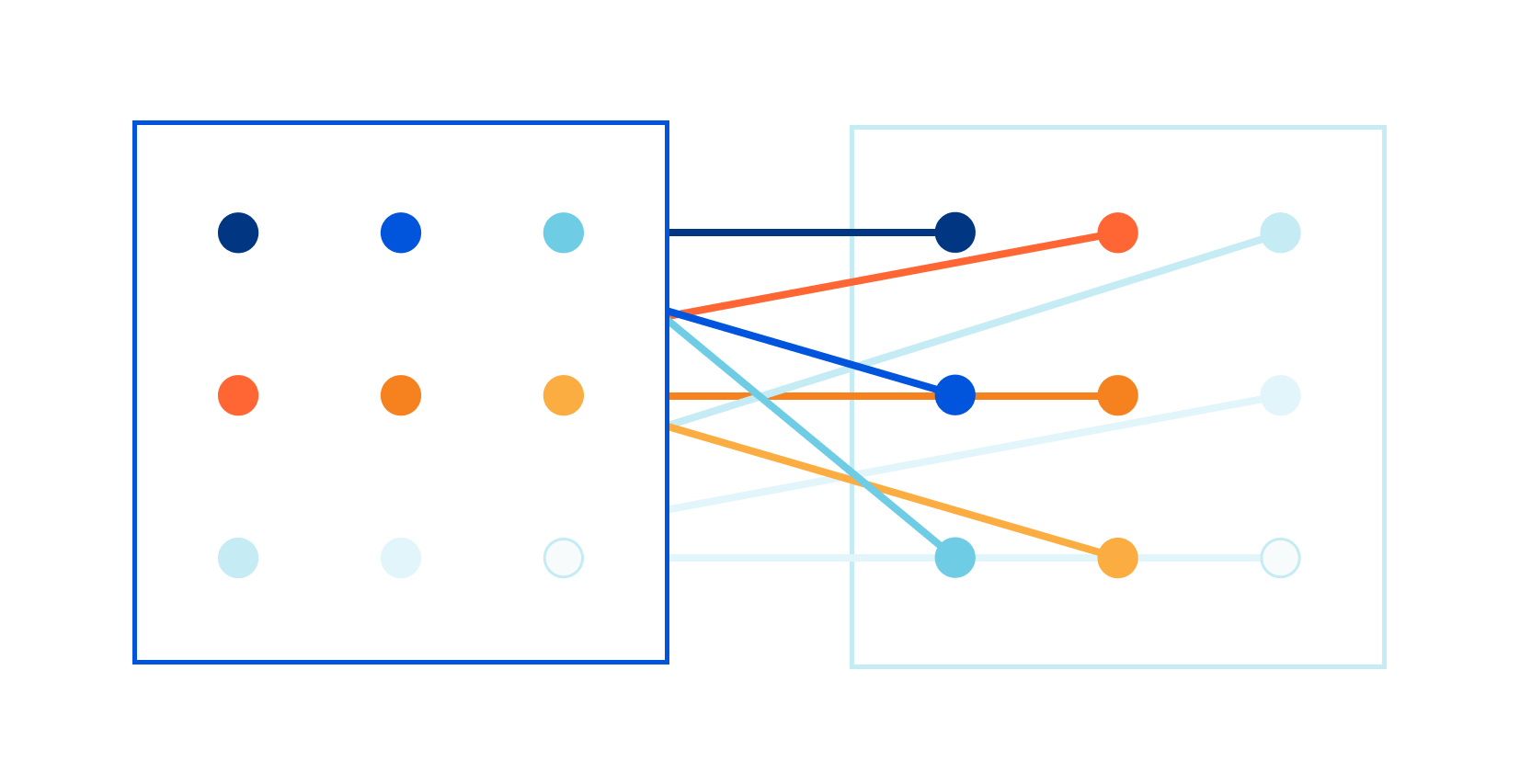
Late last year I read a blog post about our CSAM image scanning tool. I remember thinking: this is so cool! Image processing is always hard, and deploying a real image identification system at Cloudflare is no small achievement!
Some time later, I was chatting with Kornel: "We have all the pieces in the image processing pipeline, but we are struggling with the performance of one component." Scaling to Cloudflare needs ain't easy!
The problem was in the speed of the matching algorithm itself. Let me elaborate. As John explained in his blog post, the image matching algorithm creates a fuzzy hash from a processed image. The hash is exactly 144 bytes long. For example, it might look like this:
00e308346a494a188e1043333147267a 653a16b94c33417c12b433095c318012
5612442030d14a4ce82c623f4e224733 1dd84436734e4a5d6e25332e507a8218
6e3b89174e30372d
The hash is designed to be used in a fuzzy matching algorithm that can find "nearby", related images. The specific algorithm is well defined, but making it fast is left to the programmer — and at Cloudflare we need the matching to be done super fast. We want to match thousands of hashes per second, of images passing through our network, against a database of millions of known images. To make this work, Continue reading
A quirk in the SUNBURST DGA algorithm


On Wednesday, December 16, the RedDrip Team from QiAnXin Technology released their discoveries (tweet, github) regarding the random subdomains associated with the SUNBURST malware which was present in the SolarWinds Orion compromise. In studying queries performed by the malware, Cloudflare has uncovered additional details about how the Domain Generation Algorithm (DGA) encodes data and exfiltrates the compromised hostname to the command and control servers.
Background
The RedDrip team discovered that the DNS queries are created by combining the previously reverse-engineered unique guid (based on hashing of hostname and MAC address) with a payload that is a custom base 32 encoding of the hostname. The article they published includes screenshots of decompiled or reimplemented C# functions that are included in the compromised DLL. This background primer summarizes their work so far (which is published in Chinese).
RedDrip discovered that the DGA subdomain portion of the query is split into three parts:
<encoded_guid> + <byte> + <encoded_hostname>
An example malicious domain is:
7cbtailjomqle1pjvr2d32i2voe60ce2.appsync-api.us-east-1.avsvmcloud.com
Where the domain is split into the three parts as
| Encoded guid Continue reading |
|---|
Introducing Cloudflare Pages: the best way to build JAMstack websites


Across multiple cultures around the world, this time of year is a time of celebration and sharing of gifts with the people we care the most about. In that spirit, we thought we'd take this time to give back to the developer community that has been so supportive of Cloudflare for the last 10 years.
Today, we’re excited to announce Cloudflare Pages: a fast, secure and free way to build and host your JAMstack sites.
Today, the path from an idea to a website is paved with good intentions
Websites are the way we express ourselves on the web. It doesn’t matter if you’re a hobbyist with a blog, or the largest of corporations with millions of customers — if you want to reach people outside the confines of 140 280 characters, the web is the place to be.
As a frontend developer, it’s your responsibility to bring this expression to life. And make no mistake — with so many frontend frameworks, tooling, and static site generators at your disposal — it’s a great time to be in your line of work.
That is, of course, right up until the point when you’re ready to show your work off Continue reading
Trend data on the SolarWinds Orion compromise


On Sunday, December 13, FireEye released a report on a sophisticated supply chain attack leveraging SolarWinds' Orion IT monitoring software. The malware was distributed as part of regular updates to Orion and had a valid digital signature.
One of the notable features of the malware is the way it hides its network traffic using a multi-staged approach. First, the malware determines its command and control (C2) server using a domain generation algorithm (DGA) to construct and resolve a subdomain of avsvmcloud[.]com.
These algorithmically generated strings are added as a subdomain of one of the following domain names to create a new fully-qualified domain name to resolve:
.appsync-api[.]eu-west-1[.]avsvmcloud[.]com
.appsync-api[.]us-west-2[.]avsvmcloud[.]com
.appsync-api[.]us-east-1[.]avsvmcloud[.]com
.appsync-api[.]us-east-2[.]avsvmcloud[.]com
An example of such a domain name might look like: hig4gcdkgjkrt24v6isue7ax09nksd[.]appsync-api[.]eu-west-1[.]avsvmcloud[.]com
The DNS query response to a subdomain of one of the above will return a CNAME record that points to another C2 domain, which is used for data exfiltration. The following subdomains were identified as the C2 domains used for data exfiltration:
freescanonline[.]com
deftsecurity[.]com
thedoccloud[.]com
websitetheme[.]com
highdatabase[.]com
incomeupdate[.]com
databasegalore[.]com
panhardware[.]com
zupertech[.]com
virtualdataserver[.]com
Continue reading
Improving Cloudflare’s products and services, one feature request at a time

I started at Cloudflare in April 2018. I was excited to join an innovative company that operates with integrity and takes customer needs into account when planning product roadmaps. After 2.5 years at Cloudflare, this excitement has only grown, as it has become even clearer that our customers’ feedback is essential to our business. At an all-hands meeting this November, Michelle Zatlyn, our co-founder and COO, said that “every time we see things and approach problems from the lens of a customer, we make better decisions.” One of the ways we make these decisions is through Customer Success Managers funneling our customers’ feedback to our product and engineering teams.
As a Strategic Customer Success Manager, I meet regularly with my customers to better understand their experience with Cloudflare and work cross-functionally with our internal teams to continually improve it. One thing my customers often mention to me, regardless of industry or size, is their appreciation that their feedback is not only heard but understood and actioned. We are an engineering-driven company that remains agile enough to Continue reading
Privacy and Compliance Reading List


Privacy matters. Privacy and Compliance are at the heart of Cloudflare's products and solutions. We are committed to providing built-in data protection and privacy throughout our global network and for every product in our portfolio. This is why we have dedicated a whole week to highlight important aspects of how we are working to make sure privacy will stay at the core of all we do as a business.
In case you missed any of the blog posts this week addressing the topics of Privacy and Compliance, you’ll find a summary below.
Welcome to Privacy & Compliance Week: Reflecting Values at Cloudflare’s Core
We started the week with this introduction by Matthew Prince. The blog post summarizes the early decisions that the founding team made to make sure customer data is kept private, that we do not sell or rent this data to third parties, and why trust is the foundation of our business. > Read the full blog post.
Introducing the Cloudflare Data Localization Suite
Cloudflare’s network is private and compliant by design. Preserving end-user privacy is core to our mission of helping to build a better Internet; we’ve never sold personal data about customers or end-users of our Continue reading
Supporting Jurisdictional Restrictions for Durable Objects
Over the past week, you’ve heard how Cloudflare is making it easy for our customers to control where their data is stored and protected.
We’re not the only ones building these data controls. Around the world, companies are working to figure out where and how to store customer data in a way that is compliant with data localization obligations. For developers, this means new deployment models and new headaches — wrangling infrastructure in multiple regions, partitioning user data based on location, and staying on top of the latest rules from regulators.
Durable Objects, currently in limited beta, already make it easy for customers to manage state on Cloudflare Workers without worrying about provisioning infrastructure. Today, we’re announcing Jurisdictional Restrictions for Durable Objects, which ensure that a Durable Object only stores and processes data in a given geographical region. Jurisdictional Restrictions make it easy for developers to build serverless, stateful applications that not only comply with today’s regulations, but can handle new and updated policies as new regulations are added.
How Jurisdictional Restrictions Work
When creating a Durable Object, developers generate a unique ID that lets a Cloudflare Worker communicate with the Object.
Let’s say I want to create a Durable Continue reading
Encrypting your WAF Payloads with Hybrid Public Key Encryption (HPKE)

The Cloudflare Web Application Firewall (WAF) blocks more than 72B malicious requests per day from reaching our customers’ applications. Typically, our users can easily confirm these requests were not legitimate by checking the URL, the query parameters, or other metadata that Cloudflare provides as part of the security event log in the dashboard.
Sometimes investigating a WAF event requires a bit more research and a trial and error approach, as the WAF may have matched against a field that is not logged by default.
Not logging all parts of a request is intentional: HTTP headers and payloads often contain sensitive data, including personally identifiable information, which we consider a toxic asset. Request headers may contain cookies and POST payloads may contain username and password pairs submitted during a login attempt among other sensitive data.
We recognize that providing clear visibility in any security event is a core feature of a firewall, as this allows users to better fine tune their rules. To accomplish this, while ensuring end-user privacy, we built encrypted WAF matched payload logging. This feature will log only the specific component of the request the WAF has deemed malicious — and it is encrypted using a customer-provided key Continue reading
How to Build a Global Network that Complies with Local Law
We’ve spent a lot of time over the course of this week talking about Cloudflare engineers building technical solutions to improve privacy, increase control over data, and thereby, help our customers address regulatory challenges. But not all challenges can be solved with engineering. We sometimes have to build policies and procedures that anticipate our customers’ concerns. That has been an approach we’ve used to address government and other legal requests for data throughout the years.
Governments around the world have long had an interest in getting access to online records. Sometimes law enforcement is looking for evidence relevant to criminal investigations. Sometimes intelligence agencies are looking to learn more about what foreign governments or actors are doing. And online service providers of all kinds often serve as an access point for those electronic records.
For service providers like Cloudflare, though, those requests can be fraught. The work that law enforcement and other government authorities do is important. At the same time, the data that law enforcement and other government authorities are seeking does not belong to us. By using our services, our customers have put us in a position of trust over that data. Maintaining that trust is fundamental to Continue reading
Securing the post-quantum world
Quantum computing is inevitable; cryptography prepares for the future
Quantum computing began in the early 1980s. It operates on principles of quantum physics rather than the limitations of circuits and electricity, which is why it is capable of processing highly complex mathematical problems so efficiently. Quantum computing could one day achieve things that classical computing simply cannot.
The evolution of quantum computers has been slow. Still, work is accelerating, thanks to the efforts of academic institutions such as Oxford, MIT, and the University of Waterloo, as well as companies like IBM, Microsoft, Google, and Honeywell. IBM has held a leadership role in this innovation push and has named optimization the most likely application for consumers and organizations alike. Honeywell expects to release what it calls the “world’s most powerful quantum computer” for applications like fraud detection, optimization for trading strategies, security, machine learning, and chemistry and materials science.
In 2019, the Google Quantum Artificial Intelligence (AI) team announced that their 53-qubit (analogous to bits in classical computing) machine had achieved “quantum supremacy.” This was the first time a quantum computer was able to solve a problem faster than any classical computer in existence. This was considered a significant milestone.
Announcing Workplace Records for Cloudflare for Teams

We wanted to close out Privacy & Compliance Week by talking about something universal and certain: taxes. Businesses worldwide pay employment taxes based on where their employees do work. For most businesses and in normal times, where employees do work has been relatively easy to determine: it's where they come into the office. But 2020 has made everything more complicated, even taxes.
As businesses worldwide have shifted to remote work, employees have been working from "home" — wherever that may be. Some employees have taken this opportunity to venture further from where they usually are, sometimes crossing state and national borders.

In a lot of ways, it's gone better than expected. We're proud of helping provide technology solutions like Cloudflare for Teams that allow employees to work from anywhere and ensure they still have a fast, secure connection to their corporate resources. But increasingly we've been hearing from the heads of the finance, legal, and HR departments of our customers with a concern: "If I don't know where my employees are, I have no idea where I need to pay taxes."
Today we're announcing the beta of a new feature for Cloudflare for Teams to help solve this problem: Continue reading
Cloudflare Certifications


At Cloudflare, we prioritize initiatives that improve the security and privacy of our products and services. The security organization believes trust and transparency are foundational principles that are ingrained in what we build, the policies we set, and the data we protect. Many of our enterprise customers have stringent regulatory compliance obligations and require their cloud service providers like ourselves to provide assurance that we meet and exceed industry security standards. In the last couple of years, we’ve decided to invest in ways to make the evaluation of our security posture easier. We did so not only by obtaining recognized security certifications and reports in an aggressive timeline, but we also built a team that partners with our customers to provide transparency into our security and privacy practices.
Security Certifications & Reports
We understand the importance of providing transparency into our security processes, controls, and how our customers can continuously rely on them to operate effectively. Cloudflare complies with and supports the following standards:

SOC-2 Type II / SOC 3 (Service Organizations Controls) - Cloudflare maintains SOC reports that include the security, confidentiality, and availability trust principles. The SOC-2 report provides assurance that our products and underlying infrastructure are secure Continue reading
Cloudflare’s privacy-first Web Analytics is now available for everyone


In September, we announced that we’re building a new, free Web Analytics product for the whole web. Today, I’m excited to announce that anyone can now sign up to use our new Web Analytics — even without changing your DNS settings. In other words, Cloudflare Web Analytics can now be deployed by adding an HTML snippet (in the same way many other popular web analytics tools are) making it easier than ever to use privacy-first tools to understand visitor behavior.
Why does the web need another analytics service?
Popular analytics vendors have business models driven by ad revenue. Using them implies a bargain: they track visitor behavior and create buyer profiles to retarget your visitors with ads; in exchange, you get free analytics.
At Cloudflare, our mission is to help build a better Internet, and part of that is to deliver essential web analytics to everyone with a website, without compromising user privacy. For free. We’ve never been interested in tracking users or selling advertising. We don’t want to know what you do on the Internet — it’s not our business.
Our customers have long relied on Cloudflare’s Analytics because we’re accurate, fast, and privacy-first. In September we released a Continue reading
Deprecating the __cfduid cookie


Cloudflare is deprecating the __cfduid cookie. Starting on 10 May 2021, we will stop adding a “Set-Cookie” header on all HTTP responses. The last __cfduid cookies will expire 30 days after that.
We never used the __cfduid cookie for any purpose other than providing critical performance and security services on behalf of our customers. Although, we must admit, calling it something with “uid” in it really made it sound like it was some sort of user ID. It wasn't. Cloudflare never tracks end users across sites or sells their personal data. However, we didn't want there to be any questions about our cookie use, and we don’t want any customer to think they need a cookie banner because of what we do.
So why did we use the __cfduid cookie before, and why can we remove it now?
The primary use of the cookie is for detecting bots on the web. Malicious bots may disrupt a service that has been explicitly requested by an end user (through DDoS attacks) or compromise the security of a user's account (e.g. through brute force password cracking or credential stuffing, among others). We use many signals to build machine learning models that can Continue reading
Improving DNS Privacy with Oblivious DoH in 1.1.1.1


Today we are announcing support for a new proposed DNS standard — co-authored by engineers from Cloudflare, Apple, and Fastly — that separates IP addresses from queries, so that no single entity can see both at the same time. Even better, we’ve made source code available, so anyone can try out ODoH, or run their own ODoH service!
But first, a bit of context. The Domain Name System (DNS) is the foundation of a human-usable Internet. It maps usable domain names, such as cloudflare.com, to IP addresses and other information needed to connect to that domain. A quick primer about the importance and issues with DNS can be read in a previous blog post. For this post, it’s enough to know that, in the initial design and still dominant usage of DNS, queries are sent in cleartext. This means anyone on the network path between your device and the DNS resolver can see both the query that contains the hostname (or website) you want, as well as the IP address that identifies your device.
To safeguard DNS from onlookers and third parties, the IETF standardized DNS encryption with DNS over HTTPS (DoH) and DNS over TLS (DoT). Both protocols Continue reading
OPAQUE: The Best Passwords Never Leave your Device
Passwords are a problem. They are a problem for reasons that are familiar to most readers. For us at Cloudflare, the problem lies much deeper and broader. Most readers will immediately acknowledge that passwords are hard to remember and manage, especially as password requirements grow increasingly complex. Luckily there are great software packages and browser add-ons to help manage passwords. Unfortunately, the greater underlying problem is beyond the reaches of software to solve.
The fundamental password problem is simple to explain, but hard to solve: A password that leaves your possession is guaranteed to sacrifice security, no matter its complexity or how hard it may be to guess. Passwords are insecure by their very existence.
You might say, “but passwords are always stored in encrypted format!” That would be great. More accurately, they are likely stored as a salted hash, as explained below. Even worse is that there is no way to verify the way that passwords are stored, and so we can assume that on some servers passwords are stored in cleartext. The truth is that even responsibly stored passwords can be leaked and broken, albeit (and thankfully) with enormous effort. An increasingly pressing problem stems from the Continue reading
Good-bye ESNI, hello ECH!
Most communication on the modern Internet is encrypted to ensure that its content is intelligible only to the endpoints, i.e., client and server. Encryption, however, requires a key and so the endpoints must agree on an encryption key without revealing the key to would-be attackers. The most widely used cryptographic protocol for this task, called key exchange, is the Transport Layer Security (TLS) handshake.
In this post we'll dive into Encrypted Client Hello (ECH), a new extension for TLS that promises to significantly enhance the privacy of this critical Internet protocol. Today, a number of privacy-sensitive parameters of the TLS connection are negotiated in the clear. This leaves a trove of metadata available to network observers, including the endpoints' identities, how they use the connection, and so on.
ECH encrypts the full handshake so that this metadata is kept secret. Crucially, this closes a long-standing privacy leak by protecting the Server Name Indication (SNI) from eavesdroppers on the network. Encrypting the SNI secret is important because it is the clearest signal of which server a given client is communicating with. However, and perhaps more significantly, ECH also lays the groundwork for adding future security features and performance Continue reading