Technology Short Take #57
Welcome to Technology Short Take #57. I hope you find something useful here!
Networking
- Tor Anderson has an article on using IPv6 for network boot using UEFI and iPXE.
- Larry Smith Jr. has a great blog series going called “Hey, I can DevOps my Network too!” He started out with an intro post just to set the stage for the series, then had a post on the prep work required to get ready to proceed with the series. In part 2 Larry walks through the node definitions in Vagrant, and in part 3 he reviews the
Vagrantfileand turns up the environment. Parts 4 and 5 walk through auto-configured OSPF and manually-configured OSPF, respectively. I’m looking forward to more posts in this series! - Sometimes I see blog posts that tout themselves as a “deep dive” but aren’t really that deep or detailed. However, this OVN L3 deep dive by Gal Sagie really is a deep dive—he goes into a pretty fair amount of detail on how OVN’s L3 implementation works. Good stuff if you’re interested in getting more details on how OVN is implementing new features like L3.
- Kirk Byers has a helpful article that provides some Continue reading
Using SSH Multiplexing
In this post, I’m going to discuss how to configure and use SSH multiplexing. This is yet another aspect of Secure Shell (SSH), the “Swiss Army knife” for administering and managing Linux (and other UNIX-like) workloads.
Generally speaking, multiplexing is the ability to carry multiple signals over a single connection (see this Wikipedia article for a more in-depth discussion). Similarly, SSH multiplexing is the ability to carry multiple SSH sessions over a single TCP connection. This Wikibook article goes into more detail on SSH multiplexing; in particular, I would call your attention to the table under the “Advantages of Multiplexing” to better understand the idea of multiple SSH sessions with a single TCP connection.
One of the primary advantages of using SSH multiplexing is that it speeds up certain operations that rely on or occur over SSH. For example, let’s say that you’re using SSH to regularly execute a command on a remote host. Without multiplexing, every time that command is executed your SSH client must establish a new TCP connection and a new SSH session with the remote host. With multiplexing, you can configure SSH to establish a single TCP connection that is kept alive for a specific period Continue reading
A Use Case for an SSH Bastion Host
In this post, I’m going to explore one specific use case for using an SSH bastion host. I described this configuration and how to set it up in a previous post; in this post, though, I’d like to focus on one practical use case.
This use case is actually one I depicted graphically in my earlier post:

This diagram could represent a couple different examples. For example, perhaps this is an AWS VPC. Security best practices suggest that you should limit access from the Internet to your instances as much as possible; unless an instance needs to accept traffic from the Internet, don’t assign a public IP address (or an Elastic IP address). However, without a publicly-accessible IP address, how does one connect to and manage the instance? You can’t SSH to it without a publicly-accessible IP address—unless you use an SSH bastion host.
Or perhaps this diagram represents an OpenStack private cloud, where users can deploy instances in a private tenant network. In order for those instances to be accessible externally (where “externally” means external to the OpenStack cloud), the tenant must assign each instance a floating IP address. Security may not be as much of a concern Continue reading
An Introduction to Terraform
In this post, I’m going to provide a quick introduction to Terraform, a tool that is used to provision and configure infrastructure. Terraform allows you to define infrastructure configurations and then have those configurations implemented/created by Terraform automatically. In this respect, you could compare Terraform to similar solutions like OpenStack Heat, AWS CloudFormation, and others.
Before I continue, though, allow me to first address this question: why Terraform?
Why Terraform?
This is a fair question, and one that you should be asking. After all, if Terraform is considered similar to OpenStack Heat or AWS CloudFormation, then why use Terraform instead of one of the comparable solutions? I believe there are a couple (related) reasons why you might consider Terraform over a similar solution:
-
Within a single Terraform definition, you can orchestrate across multiple cloud services. For example, you could create instances with a cloud provider (AWS, DigitalOcean, etc.), create DNS records with a DNS provider, and register key/value entries in Consul. Heat and CloudFormation are, quite naturally, designed to work almost exclusively with OpenStack and AWS, respectively. (Astute readers will know that Heat supports CloudFormation templates, but you get the idea.) Therefore, one reason to use Terraform Continue reading
Bootstrapping Cloud Instances into Ansible
A while ago, I wrote an article about bootstrapping servers into Ansible—in other words, how to prepare servers to be managed via Ansible. In order for a server to be managed via Ansible, you usually must first create a user account for Ansible, populate the appropriate SSH keys, and grant the new Ansible user sudo permissions. The process I described in my earlier blog post works great for manually-built servers (physical or virtual), but I recently needed to revisit this process for cloud instances. Was it possible to use the process I’d found to bootstrap cloud instances into Ansible?
Cloud instances are a slightly different beast than manually-built servers primarily because password authentication isn’t an option—generally speaking, you’re required to use SSH keys when working with cloud instances. Ansible is SSH-based, as you probably already know, so this shouldn’t be an issue, but it was still something I hadn’t tested or verified. After a bit of testing, I found the bootstrap process I described in my earlier post can be easily adapted for cloud instances.
For reference, here’s the command I use when bootstrapping manually-built servers into Ansible:
ansible-playbook bootstrap.yml -k -K --extra-vars
"hosts=newhost.domain.com user=admin"
Using an SSH Bastion Host
Secure Shell, or SSH, is something of a “Swiss Army knife” when it comes to administering and managing Linux (and other UNIX-like) workloads. In this post, I’m going to explore a very specific use of SSH: the SSH bastion host. In this sort of arrangement, SSH traffic to servers that are not directly accessible via SSH is instead directed through a bastion host, which proxies the connection between the SSH client and the remote servers.
At first, it may sound like the use of an SSH bastion host is a pretty specialized use case. In reality, though, I believe this is a design pattern that can actually be useful in a variety of situations. I plan to explore the use cases for an SSH bastion host in a future blog post.
This diagram illustrates the concept of using an SSH bastion host to provide access to Linux instances running inside some sort of cloud network (like an OpenStack Neutron tenant network or an AWS VPC):
Let’s take a closer look at the nuts and bolts of actually setting up an SSH bastion host.
First, you’ll want to ensure you have public key authentication properly configured, both on the bastion host Continue reading
Technology Short Take #56
Welcome to Technology Short Take #56! In this post, I’ve collected a few links on various data center technologies, news, events, and trends. I hope you find something useful here.
Networking
- Open Virtual Network (OVN) is really ramping up and getting lots of attention, which I personally think is absolutely well-deserved. Russell Bryant has a couple great articles on OVN—how to test OVN’s “EZ Bake” release with DevStack as well as an article on implementing OpenStack security groups using OVN ACLs (which in turn leverage the integration between Open vSwitch and the Linux kernel’s conntrack module). Gal Sagie has a write-up on integration between Kuryr and OVN (Kuryr is another topic that is really interesting).
- Here’s an article on using PHP to query NSX API via REST (specifically, working with syslog settings on NSX Manager).
- Speaking of Gal Sagie and OVN, Gal has a post describing a concept for something called “Topology Service Injection” and some proposals for implementing this in OVN. (Gal and Liran Schour from IBM are slated to do a talk on this at the OVS conference this week.)
- One new networking feature added to OpenStack in the Kilo release was Neutron subnet pools. Carl Continue reading
A Handy GUI Tool for Working with APIs
In this post I’m going to share with you an OS X graphical application I found that makes it easier to work with RESTful APIs. The topic of RESTful APIs has come up here before (see this post on using cURL to interact with RESTful APIs), and RESTful APIs have been a key part of a number of other posts (like my recent post on using jq to work with JSON). Unlike these previous posts—which were kind of geeky and focused on the command line—this time around I’m going to show you an application called Paw, which provides a graphic interface for working with APIs.
Before I start talking about Paw, allow me to first explain why I’m talking about working with APIs using this application. I firmly believe that the future of “infrastructure engineers”—that is, folks who today are focused on managing servers, hypervisors, VM, storage, networks, and firewalls—lies in becoming the “full-stack engineer,” someone who has knowledge and skills across multiple areas, including automation/orchestration. In order to gain those skills in automation/orchestration, it’s pretty likely that you’re going to end up having to work with APIs. Hence, why I’m talking about this stuff, and why Continue reading
BusyCal and Textual
I wanted to call out a couple of software packages whose vendors I’ve worked with recently that I felt had really good customer service. The software packages are BusyCal (from BusyCal, LLC) and Textual (from Codeux Software, LLC).
As many of you know, the Mac App Store (MAS) recently suffered an issue due to an expired security certificate, and this caused many MAS apps to have to be re-downloaded or, in limited cases, to stop working (I’m looking at you, Tweetbot 1.6.2). This incident just underscored an uncomfortable feeling I’ve had for a while about using MAS apps (for a variety of reasons that I won’t discuss here because that isn’t the focus of this post). I’d already started focusing on purchasing new software licenses outside of the MAS, but I still had (and have) a number of MAS apps on my Macs.
As a result of this security certificate snafu, I started looking for ways to migrate from MAS apps to non-MAS apps, and BusyCal (a OS X Calendar replacement) and Textual (an IRC client) were two apps that I really wanted to continue to use but were MAS apps. The alternatives were dismal, at best.
A Handy CLI Tool for Working with JSON
While I was at Kubecon this past week, one of the presenters showed off a handy CLI tool for working with JSON. It’s called jq, and in this post I’m going to show you a few ways to use jq. For the source of JSON output, I’ll use the OpenStack APIs.
If you’re not familiar with JSON, I suggest having a look at this non-programmer’s introduction to JSON. Also, refer to this article on using cURL to interact with a RESTful API for a bit more background on some of the commands I’m going to use in this post.
Let’s start by getting an authorization token for OpenStack, using the following curl command:
curl -d '{"auth":{"passwordCredentials":
{"username": "admin","password": "secret"},
"tenantName": "customer-A"}}'
-H "Content-Type: application/json"
http://192.168.100.100:5000/v2.0/tokens
This will return a pretty fair amount of JSON in the response, and it presents the first opportunity to use jq. Let’s say you only wanted the authorization token, and not all the other output. Simply add the following jq command to the end of your curl request:
curl -d '{"auth":{"passwordCredentials":
{"username": "admin","password": "secret"},
"tenantName": "customer-A"}}'
-H "Content-Type: application/json"
http://192.168.100.100:5000/v2.0/tokens |
Continue readingKubecon Liveblog: Opening Keynote
This is a liveblog of the opening keynote at the inaugural Kubernetes conference, Kubecon, taking place this week at the Palace Hotel in San Francisco. Brendan Burns, Senior Staff Software Engineer at Google, is delivering the opening keynote. Burns is a co-founder of the Kubernetes project.
Burns starts out with a quick review of a bit of Kubernetes history, and reviews the broad diversity of submitters that are participating in the development of Kubernetes. He doesn’t spend much time there, though, and quickly transitions into a “where are we going?” discussion.
He says that Kubernetes wasn’t really about containers, or scheduling; it was really about making reliable, scalable, agile distributed systems a CS101 exercise. Kubernetes is really about making it easier to build distributed systems, to scale distributed systems, to update distributed systems, and to make distributed systems more reliable. Burns demonstrates how Kubernetes makes this easier by showing a recorded demo of scaling Nginx web servers up to handle 1 million requests per second, and then updating the Nginx application while still under load.
After the demo completes, Burns takes a few minutes to break down the architecture behind the demonstration. “Loadbots,” managed by a Kubernetes replication controller, Continue reading
Changing Passwords with cloud-init
Generally speaking, when launching instances in a cloud environment (such as AWS or an OpenStack-based cloud), the preferred/default way of accessing that instance is via SSH using an injected SSH key pair. There are times, though, when—for whatever reason—this approach won’t work. (I’ll describe one such situation below.) In such instances, it’s possible to configure cloud-init, the same tool used to inject SSH keys, to change passwords for user accounts. Here’s how.
Please note that this is a total hack. (Do NOT use this for any sort of production workload!) That being said, sometimes things like this are necessary to complete preliminary evaluations of a new technology, new product, or new architecture. In my case, I had a demo environment (using DevStack) that I needed to get up and running, and the instances would not have any external connectivity. This meant I was limited to console access only—hence, SSH keys are useless. The only means of access would be via password login through the console. So, I found this snippet of cloud-init code:
#cloud-config
chpasswd:
list: |
user1:password1
user2:password2
user3:password3
expire: False
For this particular use case, I needed to change the default user on the Ubuntu Continue reading
Calling All Switchers
Are you a switcher? That is, are you someone who has transitioned from one IT discipline to an entirely new IT discipline? Perhaps you were a storage gal for a long time, and now you’ve successfully transitioned into a networking career. Maybe you used to be a Windows admin, and now Linux is your thing. Or perhaps you were a networking guy, and now you’re coding like a madman. If this sounds like you, please read on!
If this describes you—or describes something you’re in the middle of doing—I’d love to talk to you. Please hit me on Twitter (I’m @scott_lowe), or drop me an e-mail (use [email protected], substituting the correct values). I promise it won’t take much of your time, and we can do this via whatever medium makes the most sense: e-mail, telephone, Skype, instant messaging, IRC…you let me know. I’m particularly interested in talking to folks to have made a really dramatic transition, not just moving from being a server administrator to being a virtualization administrator (let’s face it, those two roles are fairly similar).
Thanks, and I look forward to hearing from you soon!
A Quick Look at Carina
Today at the OpenStack Summit in Tokyo, Rackspace announced Carina, a new containers-as-a-service offering that is currently in beta. I took a few minutes to sign up for Carina today and work with it for a little while, and here is a quick introduction.
First, if you’re at all unfamiliar with Docker and/or Docker Swarm, have a look at some of these articles off my site. They’ll help provide some baseline knowledge:
A Quick Introduction to Docker
Running a Small Docker Swarm Cluster
I point out these articles because Carina essentially implements hosted Docker Swarm clusters. You can use the Carina CLI tool (as I will in this article) to create one or more clusters, each of which will expose a Docker API endpoint (just like your own homegrown Docker Swarm cluster) against which you can run the Docker client.
Let’s take a quick look. These instructions assume that you’ve already created an account and downloaded the CLI tool from GitHub. I’m assuming you’re running Linux or OS X; the commands for Windows would be quite different than what I’ll show below.
First, you’ll need to set some environmental variables. I prefer to do this in a file that Continue reading
OpenStack Summit 2015 Day 2 Keynote
Mark Collier, COO of the OpenStack Foundation, takes the stage to kick things off. He starts with a story about meeting new people, learning new things, and sharing OpenStack stories, and encourages attendees to participate in all of these things while they are here at the Summit.
Mark then transitions into a discussion of Liberty (the latest release), and revisits Jonathan Bryce’s discussion of the new organizational model (“the Big Tent”). He specifically calls out Astara and Kuryr as new projects in the Big Tent model. Out of curiosity, he looked at development activity for all the various projects to see which project was the “most active”. It turns out that Neutron was the most active project across all of the various OpenStack projects. According to the user survey last year, 68% were running Neutron. In the most recent user survey, that number climbed to 89%—meaning the vast majority of OpenStack clouds in production are now running Neutron.
So why is networking (and Neutron) so hot right now? Mark believes that this is due to the increasing maturity of software-defined networking and network virtualization. Mark shows data from Crehan Research that states SDN is growing twice as fast as server Continue reading
OpenStack Summit 2015 Day 1 Keynote
This is a liveblog of the Day 1 keynote at the OpenStack Summit here in Tokyo, Japan. As is quite often the case at conferences like this, the wireless network is strained to its limits, so I may not be able to publish this liveblog until well after the keynote ends (possibly even later in the day).
After a brief introduction by one of the leaders of the OpenStack Japan User Group (I couldn’t catch his name), Jonathan Bryce takes the stage. Jonathan takes a few minutes to welcome the attendees, thank the conference sponsors, and go over some logistics (different hotels, meals, getting help, etc.). Jonathan announces the first individual certification for OpenStack—the Certified OpenStack Administrator. The certification test will be available starting in 2016. Not many details are given; I assume that more details will be released in the coming days and weeks.
Jonathan also takes a moment to talk about Liberty, the 12th release of OpenStack. Based on the features added, he feels that manageability, scalability, and extensibility were the key themes for Liberty. This leads Jonathan into a discussion of users and developers, sometimes (not beneficially) separated by sales and product management. Jonathan feels that Continue reading
Technology Short Take #55
Welcome to Technology Short Take #55! Here’s hoping I’ve managed to find something of value and interest to you in this latest collection of links and articles from around the web on networking, storage, virtualization, security, and other data center-related technologies. Enjoy!
Networking
- I recently came across Kuryr, an OpenStack project aimed at connecting Docker’s libnetwork efforts to OpenStack Neutron. The end result, as I understand it, would be to allow any Neutron plugin to be able to provide container networking functionality to Docker via libnetwork. This makes sense to me, although I think that network virtualization products are still going to need to integrate directly with libnetwork so that they can be used in environments outside of OpenStack. If you’re interested in getting more information on Kuryr, check out Gal Sagie’s post here or read this follow-up post on using Kuryr and OVN (Open Virtual Network) together.
- Drew Conry-Murray has a post up on the Packet Pushers blog talking about the benefits and challenges of a single OS; specifically, the benefits and challenges pertaining to Arista and EOS. Lots of companies like to tout the “single OS” banner, but there can be value in having specialized OSes custom-built Continue reading
Adding an Interface to an OpenStack Instance After Creation
In this post I’ll share a few commands I found for adding a network interface to an OpenStack instance after launching the instance. You could, of course, simply launch the instance with multiple network interfaces from the very beginning, but these commands are handy in case you messed up or in case the requirements for the instance changed after it was launched. Please note there’s nothing revolutionary or ground-breaking in the commands listed here; I’m simply trying to help share information in the event others will find it useful.
I tested these commands using OpenStack “Juno” with VMware NSX providing the networking functionality for Neutron, but (as you can tell if you check the articles in the “References” section) this functionality has been around for a while. These commands should work with any supported Neutron plug-in.
First, create the Neutron network port:
neutron port-create <Neutron network name>
If you want to attach a security group to the port (probably a good idea), then modify the command to look like this:
neutron port-create --security-group <Security group name>
<Neutron network name>
Note that you can add multiple --security-group parameters to the command in order to specify multiple security groups on the Continue reading
Prayer Time at Tokyo Summit
This is something I’ve had the pleasure of organizing at VMworld over the last couple of years, and I’d like to start doing it at the OpenStack Summits as well. So, next week in Tokyo, I’d like to offer Christians attending the Summit the opportunity to gather together for a brief time of prayer before the day’s activities get started.
If you’re interested in attending, here are the details.
What: A brief time of prayer
Where: The pool outside the Grand Prince Hotel New Takanawa (the pool outside the red building on this map of the Summit campus)
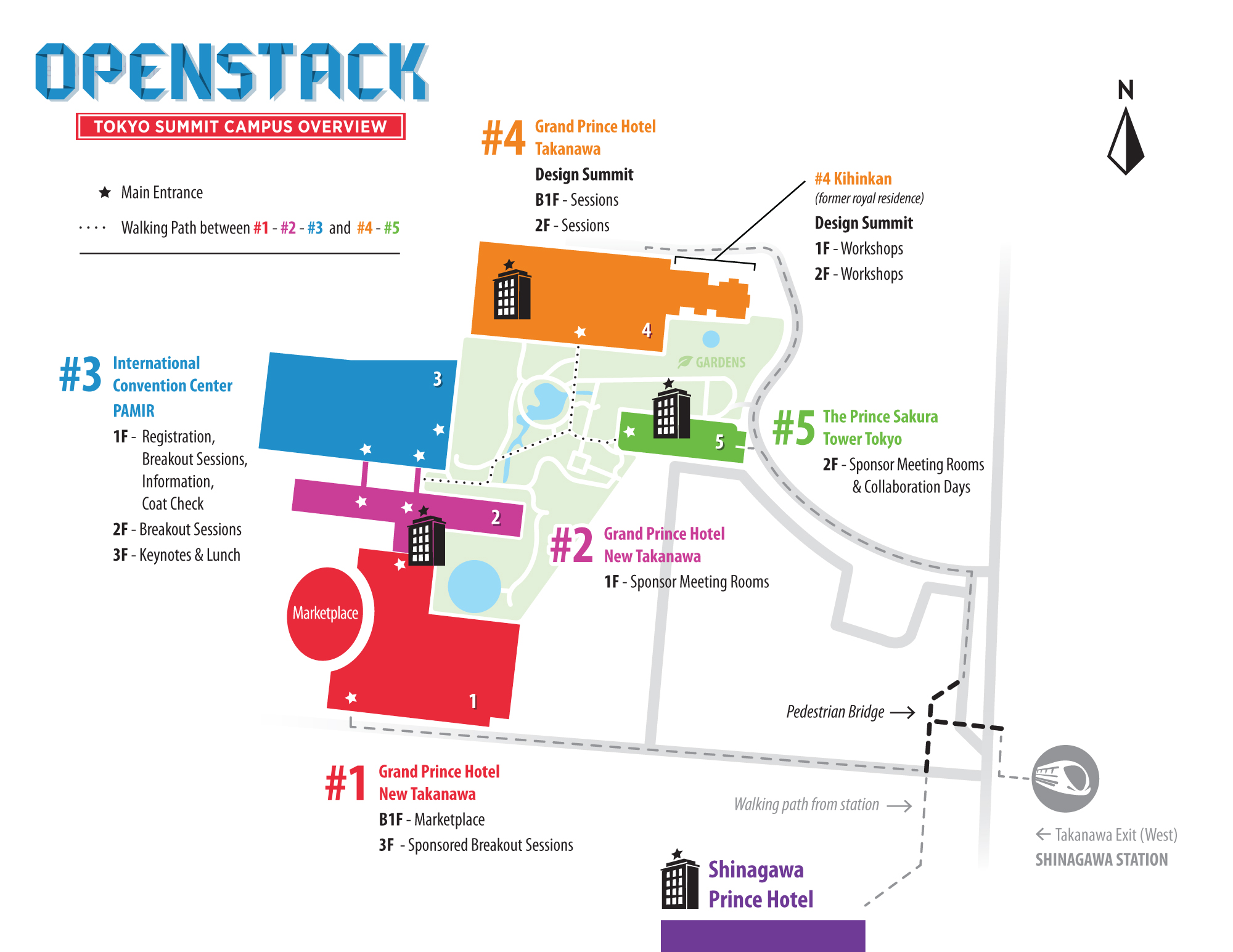{kind=link}
When: Tuesday, October 27 through Thursday, October 29, at 8:00 am each day (this should give you time to grab some breakfast before the keynotes and sessions start at 9:00 am)
Who: All courteous attendees are welcome, but please note that this will be a distinctly Christian-focused and Christ-centric activity. This is not to exclude anyone, but rather to focus on like-minded individuals. (I encourage believers of other faiths/religions to organize equivalent activities.)
Why: To spend a few minutes in prayer over the day, the Summit, and the other attendees gathered there
You don’t need to RSVP to let me know Continue reading
Spousetivities in Tokyo
Regular readers of this site know that my wife, Crystal, organizes spouse activities (aka “Spousetivities”, like the combination of “spouse” and “activities”) at conferences. This year she’s adding activities in Tokyo, Japan, in conjunction with the Fall OpenStack Summit!
Here’s a quick look at what is planned:
- Tokyo city tour w/ tea ceremony (very cool!)
- Tour of Tokyo Tower, Meiji Jingu, and Odaiba
- A visit to Mt. Fuji and Hakone
- Nikko tour
More details on these activities is available on the Spousetivities site.
The activities are funded in part by VMware NSX and Blue Box (their sponsorship helps reduce the cost of activities for participants). If you have a loved one (spouse, domestic partner, family member, friend, whatever!) traveling with you to Tokyo, head on over to the registration page to get them signed up for some great activities while you’re at the Summit.