Author Archives: Adrian Colyer
Author Archives: Adrian Colyer
TLDR; this is the last edition of The Morning Paper for now. Plus: one strand of research you won’t want to miss!
I was listening to a BBC Radio 4 podcast recently (More or Less: Behind the Stats – Ants and Algorithms) in which the host Tim Harford is interviewing David Sumpter about his recent book, ‘The ten equations that rule the world.’ One of those equations, the ‘reward equation’ models how ants communicate using pheromones, and our own brains keep track of rewards using dopamine.
About 4 and a half minutes into the podcast Tim asks a fascinating question: the reward equation includes a decay or ‘forgetting’ parameter, so what happens if you disrupt established solutions for long enough that their hold is broken? For example, the complete disruption to our established routines that Covid has caused over the last year? The answer for ants, if you disrupt all of the pheromone trails around their nest, is that they converge on a new solution in the environment, but it won’t necessarily look the same as the one they had before the disruption. (If you’re interested in the amazing problem-solving skills of ants and how we Continue reading
An overview of end-to-end entity resolution for big data, Christophides et al., ACM Computing Surveys, Dec. 2020, Article No. 127
The ACM Computing Surveys are always a great way to get a quick orientation in a new subject area, and hot off the press is this survey on the entity resolution (aka record linking) problem. It’s an important part of many modern data workflows, and an area I’ve been wrestling with in one of my own projects.
Entity Resolution (ER) aims to identify different descriptions that refer to the same real-world entity appearing either within or across data sources, when unique entity identifiers are not available.
When ER is applied to records from the same data source it can be used for deduplication, when used to join records across data sources we call it record linking. Doing this well at scale is non-trivial; at its core, the problem requires comparing each entity to every other, i.e. it is quadratic in input size.
An individual record/document for an entity is called an entity description. A set of such descriptions is an entity collection. Two descriptions that correspond to the same real world entity are called matches or Continue reading
Bias in word embeddings, Papakyriakopoulos et al., FAT*’20
There are no (stochastic) parrots in this paper, but it does examine bias in word embeddings, and how that bias carries forward into models that are trained using them. There are definitely some dangers to be aware of here, but also some cause for hope as we also see that bias can be detected, measured, and mitigated.
…we want to provide a complete overview of bias in word embeddings: its detection in the embeddings, its diffusion in algorithms using the embeddings, and its mitigation at the embeddings level and at the level of the algorithm that uses them.
It’s been shown before (‘Man is to computer programmer as woman is to homemaker?’) that word embeddings contain bias. The dominant source of that bias is the input dataset itself, i.e. the text corpus that the embeddings are trained on. Bias in, bias out. David Hume put his finger on the fundamental issue at stake here back in 1737 when he wrote about the unjustified shift in stance from describing what is and is not to all of a sudden talking about what ought or ought not to be. Continue reading
Seeing is believing: a client-centric specification of database isolation, Crooks et al., PODC’17.
Last week we looked at Elle, which detects isolation anomalies by setting things up so that the inner workings of the database, in the form of the direct serialization graph (DSG), can be externally recovered. Today’s paper choice, ‘Seeing is believing’ also deals with the externally observable effects of a database, in this case the return values of read operations, but instead of doing this in order to detect isolation anomalies, Crooks et al. use this perspective to create new definitions of isolation levels.
It’s one of those ideas, that once it’s pointed out to you seems incredibly obvious (a hallmark of a great idea!). Isolation guarantees are a promise that a database makes to its clients. We should therefore define them in terms of effects visible to clients – as part of the specification of the external interface offered by the database. How the database internally fulfils that contract is of no concern to the client, so long as it does. And yet, until Crooks all the definitions, including Adya’s, have been based on implementation concerns!
In theory defining isolation levels Continue reading
Elle: inferring isolation anomalies from experimental observations, Kingsbury & Alvaro, VLDB’20
Is there anything more terrifying, and at the same time more useful, to a database vendor than Kyle Kingsbury’s Jepsen? As the abstract to today’s paper choice wryly puts it, “experience shows that many databases do not provide the isolation guarantees they claim.” Jepsen captures execution histories, and then examines them for evidence of isolation anomalies. General linearizability and serializability checking are NP-complete problems due to extreme state-space explosion with increasing concurrency, and Jepsen’s main checker, Knossos, taps out on the order of hundreds of transactions.
Databases are in for an ‘Ell(e) of a hard time with the new checker in the Jepsen family though, Elle. From the README:
Like a clever lawyer, Elle looks for a sequence of events in a story which couldn’t possibly have happened in that order, and uses that inference to prove the story can’t be consistent.
The paper describes how Elle works behind the scenes, and gives us a taste of Elle in action. Elle is able to check histories of hundreds of thousands of transactions in just tens of seconds. Which means whole new levels of stress for Continue reading
Achieving 100 Gbps intrusion prevention on a single server, Zhao et al., OSDI’20
Papers-we-love is hosting a mini-event this Wednesday (18th) where I’ll be leading a panel discussion including one of the authors of today’s paper choice: Justine Sherry. Please do join us if you can.
We always want more! This stems from a combination of Jevon’s paradox and the interconnectedness of systems – doing more in one area often leads to a need for more elsewhere too. At the end of the day, there are three basic ways we can increase capacity:
Options 1 and 2 are of course the ‘scale out’ options, whereas option 3 is ‘scale up’. With more nodes and more coordination comes more complexity, both in design and operation. So while scale out has seen the majority of attention in the cloud era, it’s good to remind ourselves periodically just what we really can do on a single Continue reading
Virtual consensus in Delos, Balakrishnan et al. (Facebook, Inc.), OSDI’2020
Before we dive into this paper, if you click on the link above and then download and open up the paper pdf you might notice the familiar red/orange splash of USENIX, and appreciate the fully open access. USENIX is a nonprofit organisation committed to making content and research freely available – both conference proceedings and the recorded presentations of their events. Without in-person conferences this year, income is down and events are under threat. If you want to help them, you have options to donate, become a member, or even talk to your organisation about becoming a partner, benefactor, or patron. Every little helps!
Back in 2017 the engineering team at Facebook had a problem. They needed a table store to power core control plane services, which meant strong guarantees on durability, consistency, and availability. They also needed it fast – the goal was to be in production within 6 to 9 months. While ultimately this new system should be able to take advantage of the latest advances in consensus for improved performance, that’s not realistic given a 6-9 month in-production target. So realistically all Continue reading
Helios: hyperscale indexing for the cloud & edge, Potharaju et al., PVLDB’20
Last time out we looked at the motivations for a new reference blueprint for large-scale data processing, as embodied by Helios. Today we’re going to dive into the details of Helios itself. As a reminder:
Helios is a distributed, highly-scalable system used at Microsoft for flexible ingestion, indexing, and aggregation of large streams of real-time data that is designed to plug into relationals engines. The system collects close to a quadrillion events indexing approximately 16 trillion search keys per day from hundreds of thousands of machines across tens of data centres around the world.
As an ingestion and indexing system, Helios separates ingestion and indexing and introduces a novel bottoms-up index construction algorithm. It exposes tables and secondary indices for use by relational query engines through standard access path selection mechanisms during query optimisation. As a reference blueprint, Helios’ main feature is the ability to move computation to the edge.
Helios is designed to ingest, index, and aggregate large streams of real-time data (tens of petabytes a day). For example, the log data generated by Azure Cosmos. It supports key use cases such as finding Continue reading
Helios: hyperscale indexing for the cloud & edge, Potharaju et al., PVLDB’20
On the surface this is a paper about fast data ingestion from high-volume streams, with indexing to support efficient querying. As a production system within Microsoft capturing around a quadrillion events and indexing 16 trillion search keys per day it would be interesting in its own right, but there’s a lot more to it than that. Helios also serves as a reference architecture for how Microsoft envisions its next generation of distributed big-data processing systems being built. These two narratives of reference architecture and ingestion/indexing system are interwoven throughout the paper. I’m going to tackle the paper in two parts, focusing today on the reference architecture, and in the next post on the details of Helios itself. What follows is a discussion of where big data systems might be heading, heavily inspired by the remarks in this paper, but with several of my own thoughts mixed in. If there’s something you disagree with, blame me first!
Cloud-native systems represent by far the largest, most distributed, computing systems in our history. And the established cloud-native architectural principles behind them Continue reading
The case for a learned sorting algorithm, Kristo, Vaidya, et al., SIGMOD’20
We’ve watched machine learning thoroughly pervade the web giants, make serious headway in large consumer companies, and begin its push into the traditional enterprise. ML, then, is rapidly becoming an integral part of how we build applications of all shapes and sizes. But what about systems software? It’s earlier days there, but ‘The case for learned index structures’(Part 1 Part 2), SageDB and others are showing the way.
Today’s paper choice builds on the work done in SageDB, and focuses on a classic computer science problem: sorting. On a 1 billion item dataset, Learned Sort outperforms the next best competitor, RadixSort, by a factor of 1.49x. What really blew me away, is that this result includes the time taken to train the model used!
Suppose you had a model that given a data item from a list, could predict its position in a sorted version of that list. 0.239806? That’s going to be at position 287! If the model had 100% accuracy, it would give us a completed sort just by running over the dataset and putting Continue reading
Orbital edge computing: nanosatellite constellations as a new class of computer system, Denby & Lucia, ASPLOS’20.
Last time out we looked at the real-world deployment of 5G networks and noted the affinity between 5G and edge computing. In true Crocodile Dundee style, Denby and Lucia are entitled to say “that’s not the edge, this is the edge!”. Today’s paper choice has it all: clusters of formation-flying autonomous nanosatellites working in tandem to overcome the physical limitations of space and the limited bandwidth to earth. The authors call this Orbital Edge Computing in contrast to the request-response style of satellite communications introduced with the previous generation of monolithic satellites. Only space system architects don’t call it request-response, they call it a ‘bent-pipe architecture.’
Momentum towards large constellations of nanosatellites requires a reimagining of space systems as distributed, edge-sensing and edge-computing systems.
Satellites used to be large monolithic devices, e.g. the 500kg, $192M Earth Observing-1 (EO-1) satellite. Over the last couple of decades there’s been a big switch to /nanosatellite/ constellations. Nanosatellites are typically 10cm cubes (for the “CubeSat” standard), weigh just a few kilograms, and cost in the thousands of dollars.
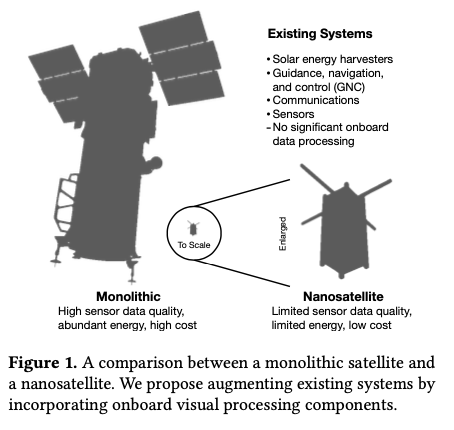
The CubeSat Continue reading
Understanding operational 5G: a first measurement study on its coverage, performance and energy consumption, Xu et al., SIGCOMM’20
We are standing on the eve of the 5G era… 5G, as a monumental shift in cellular communication technology, holds tremendous potential for spurring innovations across many vertical industries, with its promised multi-Gbps speed, sub-10 ms low latency, and massive connectivity.
There are high hopes for 5G, for example unlocking new applications in UHD streaming and VR, and machine-to-machine communication in IoT. The first 5G networks are now deployed and operational. In today’s paper choice, the authors investigate whether 5G as deployed in practice can live up to the hype. The short answer is no. It’s a great analysis that taught me a lot about the realities of 5G, and the challenges ahead if we are to eventually get there.
The study is based on one of the world’s first commercial 5G network deployments (launched in April 2019), a 0.5 x 0.92 km university campus. As is expected to be common during the roll-out and transition phase of 5G, this network adopts the NSA (Non-Standalone Access) deployment model whereby the 5G radio is used for the data Continue reading
Towards an API for the real numbers, Boehm, PLDI’20
Last time out we saw that even in scientific computing applications built by experts, problems with floating point numbers are commonplace. The idiosyncrasies of floating point representations also show up in more everyday applications such as calculators and spreadsheets. Here the user-base is less inclined to be sympathetic:
If arithmetic computations and results are directly exposed to human users who are not floating point experts, floating point approximations tend to be viewed as bugs.
Hans-J. Boehm, author of today’s paper, should know, because he’s been involved in the development of the Android calculator app. That app is subject to “voluminous (public) user feedback”, and in the 2014 floating-point based calculator, bug reports relating to inaccurate results, unnecessary zeroes, and the like.
It’s a classic software development moment. The bug / feature request that looks just like any other ordinary issue on the outside, but takes you from straightforward implementation to research-level problem on the inside! In this case, the realisation that you can’t just use standard IEEE floating point operations anymore.
For calculators, spreadsheets, and many other applications we don’t need the raw performance of hardware floating point operations. But Continue reading
Spying on the floating point behavior of existing, unmodified scientific applications Dinda et al., HPDC’20
It’s common knowledge that the IEEE standard floating point number representations used in modern computers have their quirks, for example not being able to accurately represent numbers such as 1/3, or 0.1. The wikipedia page on floating point numbers describes a number of related accuracy problems including the difficulty of testing for equality. In day-to-day usage, beyond judicious use of ‘within’ for equality testing, I suspect most of us ignore the potential difficulties of floating point arithmetic even if we shouldn’t. You’d like to think that scientific computing applications which heavily depend on floating point operations would do better than that, but the results in today’s paper choice give us reason to doubt.
…despite a superficial similarity, floating point arithmetic is not real number arithmetic, and the intuitive framework one might carry forward from real number arithmetic rarely applies. Furthermore, as hardware and compiler optimisations rapidly evolve, it is challenging even for a knowledgeable developer to keep up. In short, floating point and its implementations present sharp edges for its user, and the edges are getting sharper… recent research has determined that the Continue reading
Static analysis of Java enterprise applications: frameworks and caches, the elephants in the room, Antoniadis et al., PLDI’20
Static analysis is a key component of many quality and security analysis tools. Being static, it has the advantage that analysis results can be produced solely from source code without the need to execute the program. This means for example that it can be applied to analyse source code repositories and pull requests, be used as an additional test in CI pipelines, and even give assistance in your IDE if it’s fast enough.
Enterprise applications have (more than?) their fair share of quality and security issues, and execute in a commercial context where those come with financial and/or reputational risk. So they would definitely benefit from the kinds of reassurances that static analysis can bring. But there’s a problem:
Enterprise applications represent a major failure of applying programming languages research to the real world — a black eye of the research community. Essentially none of the published algorithms or successful research frameworks for program analysis achieve acceptable results for enterprise applications on the main quality axes of static analysis research: completeness, precision, and scalability.
If you try running Continue reading
Watchman: monitoring dependency conflicts for Python library ecosystem Wang et al., ICSE ‘20
There are more than 1.4M Python libraries in the PyPI repository. Figuring out which combinations of those work well together is not always easy. In fact, we have a phrase for navigating the maze of dependencies modern projects seem to accumulate: “dependency hell”. It’s often not the direct dependencies of your project that bite you, but the dependencies of your dependencies, all the way on down to transitive closure. In today’s paper from ICSE ‘20, Wang et al. study the prevalence of dependency conflicts in Python projects and their causes. Having demonstrated (not that many of us would need much convincing) that dependency conflicts are a real problem, they build and evaluate Watchman, a tool to quickly find and report dependency conflicts, and to predict dependency conflicts in the making. Jolly useful it looks too.
If you have a set of versioned dependencies that all work together, you can create a lock file to pin those versions. But if you haven’t yet reached that happy place, or you need to upgrade, add or remove a dependency, you’ll be Continue reading
Aligning superhuman AI with human behavior: chess as a model system, McIlroy-Young et al., KDD’20
It’s been a while, but it’s time to start reading CS papers again! We’ll ease back into it with one or two papers a week for a few weeks, building back up to something like 3 papers a week at steady state.
AI models can learn to perform some tasks to human or even super-human levels, but do they then perform those tasks in a human-like way? And does that even matter so long as the outcomes are good? If we’re going to hand everything over to AI and get out of the way, then maybe not. But where humans are still involved in task performance, supervision, or evaluation, then McIlroy-Young et al. make the case that this difference in approaches really does matter. Human-machine collaboration offers a lot of potential to enhance and augment human performance, but this requires the human and the machine to be ‘on the same page’ to be truly effective (see e.g. ‘Ten challenges for making automation a ‘team player’ in joint human-agent activity‘).
The central challenge in realizing these Continue reading
I hope things have been going well for you during the various stages of covid-19 lockdowns. In the UK where I am things are just starting to ease, although it looks like I’ll still be working remotely for a considerable time to come.
Lockdown so far has been bittersweet for me. Two deaths in my extended family, neither covid related, but both with funerals impacted, and one life-threatening incident in my immediate family (all ok now thank goodness, but it was very stressful at the time!). At the same time it’s been a wonderful opportunity to spend more quality time with my family and I’m grateful for that.
Covid-19, the lack of in-person schooling for children, and fully remote working have interrupted my routines just like they have for many others. I’ve still been studying pretty hard (it’s almost a form of relaxation and retreat for me), but in a different subject area. My current intention is to pick up The Morning Paper again for the new academic term, starting in September. I’ll no doubt have a huge backlog of interesting papers to look at by then – if you’ve encountered any on your travels that you think I Continue reading