Author Archives: Jakub Sitnicki
Author Archives: Jakub Sitnicki
Have you noticed how simple questions sometimes lead to complex answers? Today we will tackle one such question. Category: our favorite - Linux networking.
If I navigate to https://blog.cloudflare.com/, my browser will connect to a remote TCP address, might be 104.16.132.229:443 in this case, from the local IP address assigned to my Linux machine, and a randomly chosen local TCP port, say 192.0.2.42:54321. What happens if I then decide to head to a different site? Is it possible to establish another TCP connection from the same local IP address and port?
To find the answer let's do a bit of learning by discovering. We have prepared eight quiz questions. Each will let you discover one aspect of the rules that govern local address sharing between TCP sockets under Linux. Fair warning, it might get a bit mind-boggling.
Questions are split into two groups by test scenario:
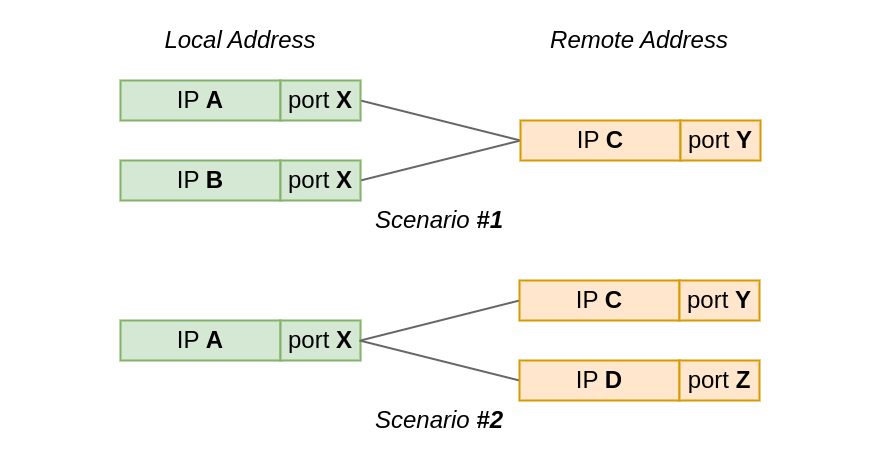
In the first test scenario, two sockets connect from the same local port to the same remote IP and port. However, the local IP is different for each socket.
While, in the second scenario, the local Continue reading
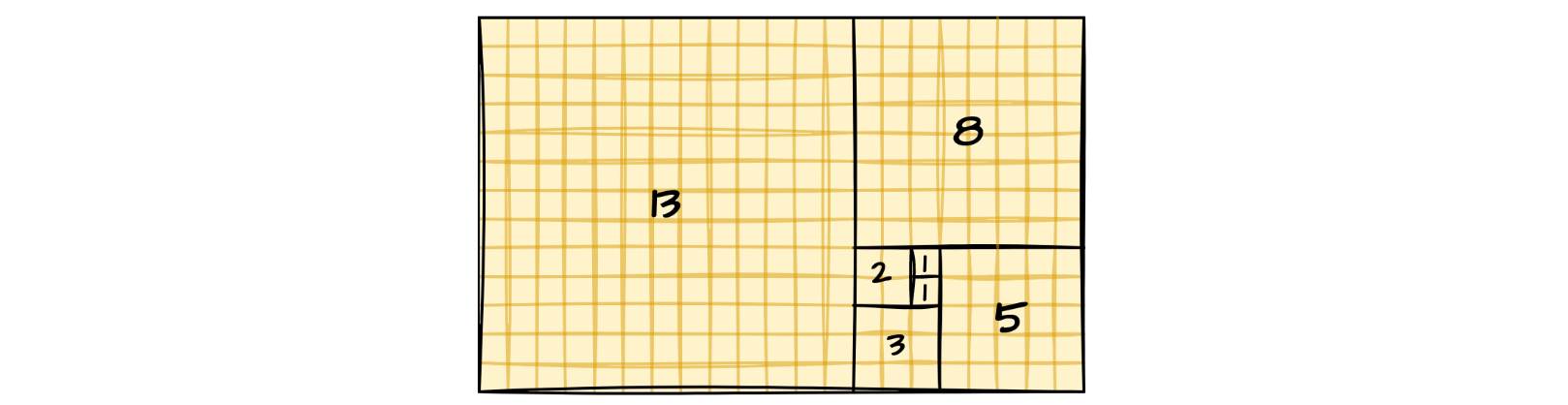
Early on when we learn to program, we get introduced to the concept of recursion. And that it is handy for computing, among other things, sequences defined in terms of recurrences. Such as the famous Fibonnaci numbers - Fn = Fn-1 + Fn-2.
Later on, perhaps when diving into multithreaded programming, we come to terms with the fact that the stack space for call frames is finite. And that there is an “okay” way and a “cool” way to calculate the Fibonacci numbers using recursion:
// fib_okay.c
#include <stdint.h>
uint64_t fib(uint64_t n)
{
if (n == 0 || n == 1)
return 1;
return fib(n - 1) + fib(n - 2);
}
Listing 1. An okay Fibonacci number generator implementation
// fib_cool.c
#include <stdint.h>
static uint64_t fib_tail(uint64_t n, uint64_t a, uint64_t b)
{
if (n == 0)
return a;
if (n == 1)
return b;
return fib_tail(n - 1, b, a + b);
}
uint64_t fib(uint64_t n)
{
return fib_tail(n, 1, 1);
}
Listing 2. A better version of the same
If we take a look at the machine code the compiler produces, the “cool” variant translates to a nice and tight sequence of instructions:
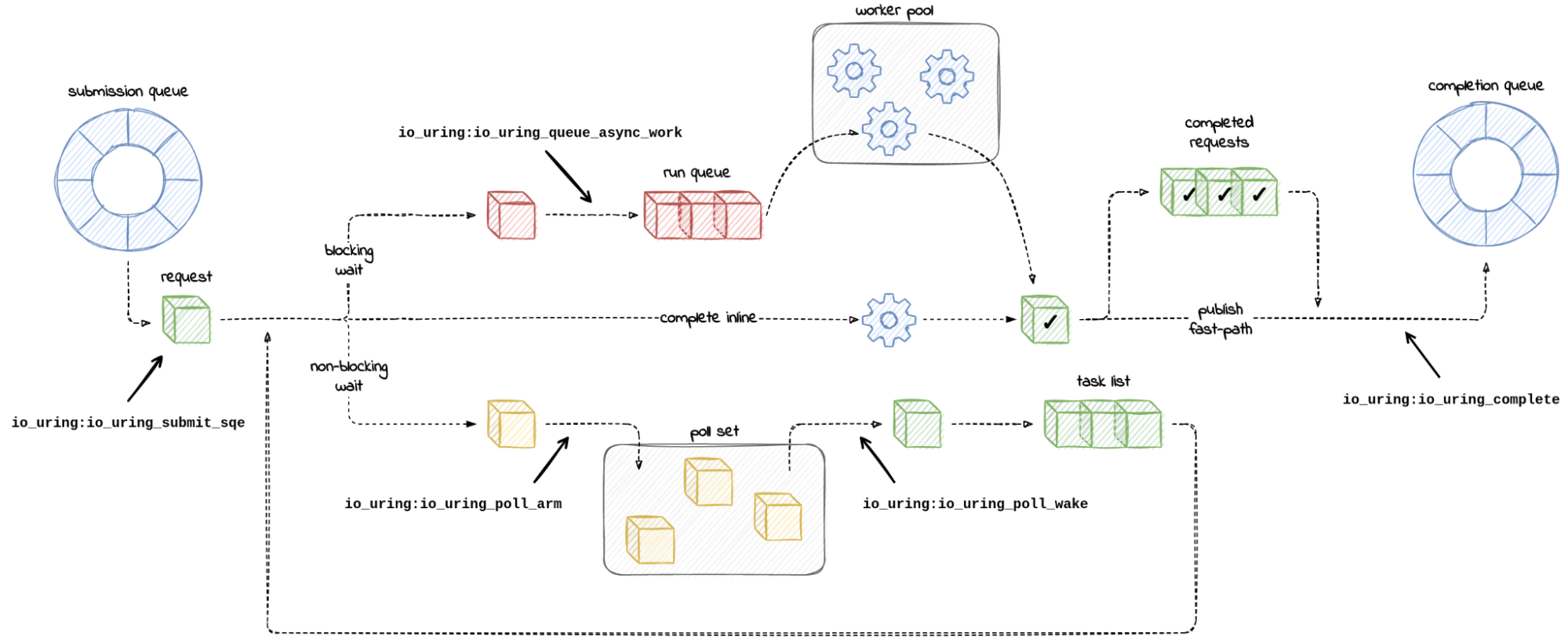
Chances are you might have heard of io_uring. It first appeared in Linux 5.1, back in 2019, and was advertised as the new API for asynchronous I/O. Its goal was to be an alternative to the deemed-to-be-broken-beyond-repair AIO, the “old” asynchronous I/O API.
Calling io_uring just an asynchronous I/O API doesn’t do it justice, though. Underneath the API calls, io_uring is a full-blown runtime for processing I/O requests. One that spawns threads, sets up work queues, and dispatches requests for processing. All this happens “in the background” so that the user space process doesn’t have to, but can, block while waiting for its I/O requests to complete.
A runtime that spawns threads and manages the worker pool for the developer makes life easier, but using it in a project begs the questions:
1. How many threads will be created for my workload by default?
2. How can I monitor and control the thread pool size?
I could not find the answers to these questions in either the Efficient I/O with io_uring article, or the Lord of the io_uring guide – two well-known pieces of available documentation.
And while a recent enough io_uring man page touches on the Continue reading
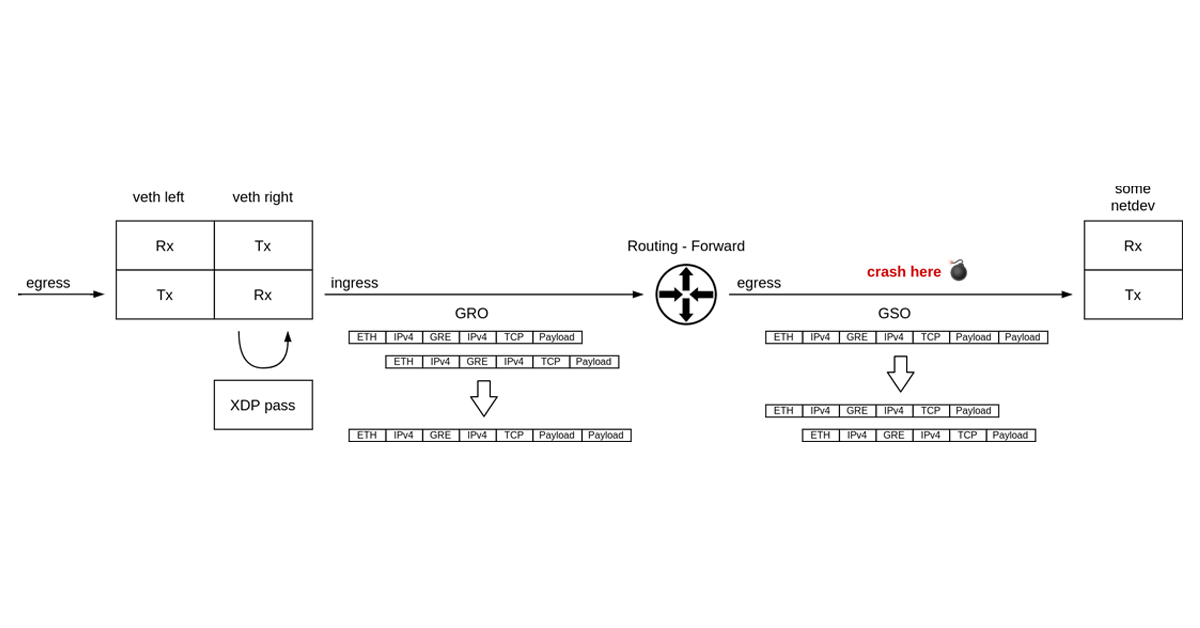
“Once you eliminate the impossible, whatever remains, no matter how improbable, must be the truth.” — Sherlock Holmes
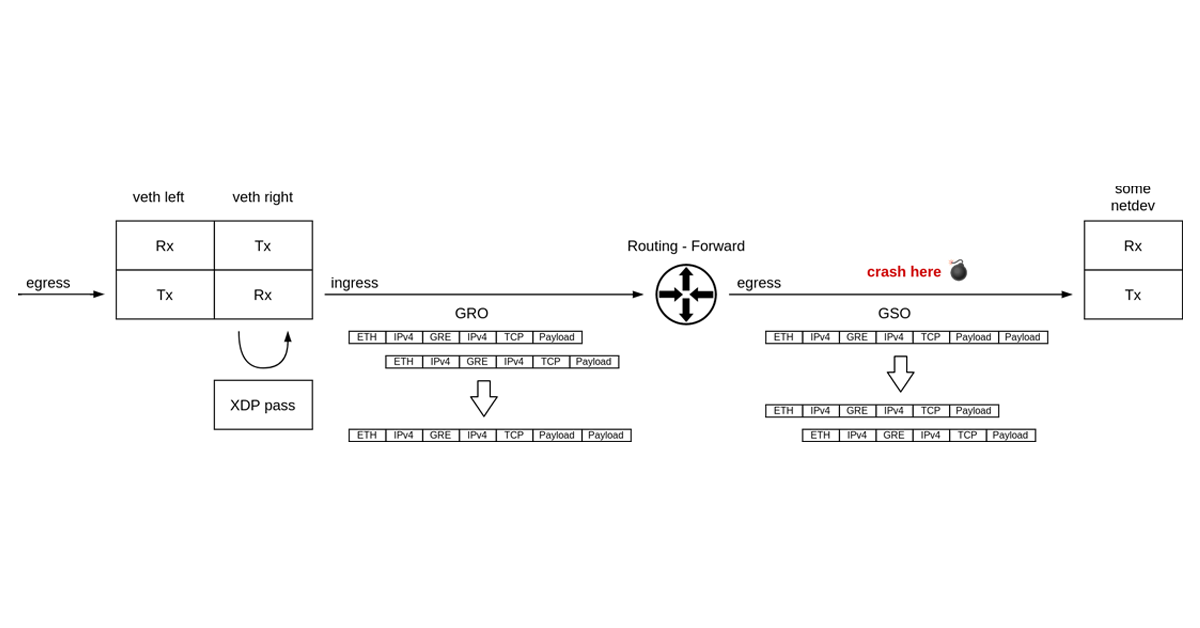
It’s not every day that you get to debug what may well be a packet of death. It was certainly the first time for me.
What do I mean by “a packet of death”? A software bug where the network stack crashes in reaction to a single received network packet, taking down the whole operating system with it. Like in the well known case of Windows ping of death.
Challenge accepted.
Around a year ago we started seeing kernel crashes in the Linux ipv4 stack. Servers were crashing sporadically, but we learned the hard way to never ignore cases like that — when possible we always trace crashes. We also couldn’t tie it to a particular kernel version, which could indicate a regression which hopefully could be tracked down to a single faulty change in the Linux kernel.
The crashed servers were leaving behind only a crash report, affectionately known as a “kernel oops”. Let’s take a look at it and go over what information we have there.

Parts of the oops, like offsets into Continue reading

We have been working with conntrack, the connection tracking layer in the Linux kernel, for years. And yet, despite the collected know-how, questions about its inner workings occasionally come up. When they do, it is hard to resist the temptation to go digging for answers.
One such question popped up while writing the previous blog post on conntrack:
“Why are there no entries in the conntrack table for SYN packets dropped by the firewall?”
Ready for a deep dive into the network stack? Let’s find out.

We already know from last time that conntrack is in charge of tracking incoming and outgoing network traffic. By running conntrack -L we can inspect existing network flows, or as conntrack calls them, connections.
So if we spin up a toy VM, connect to it over SSH, and inspect the contents of the conntrack table, we will see…
$ vagrant init fedora/33-cloud-base
$ vagrant up
…
$ vagrant ssh
Last login: Sun Jan 31 15:08:02 2021 from 192.168.122.1
[vagrant@ct-vm ~]$ sudo conntrack -L
conntrack v1.4.5 (conntrack-tools): 0 flow entries have been shown.
… nothing!
Even though the conntrack kernel Continue reading
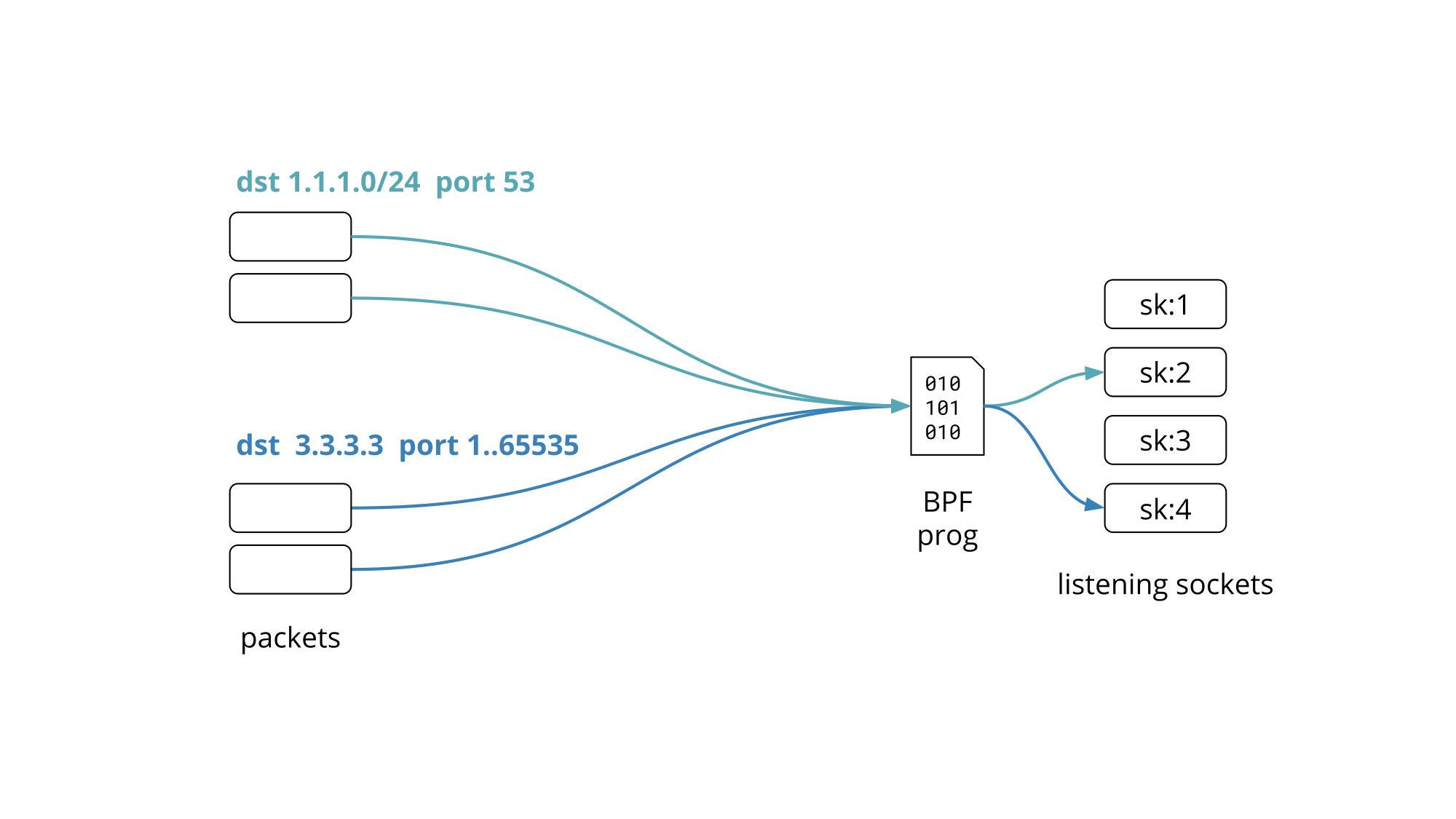
We recently gave a presentation on Programming socket lookup with BPF at the Linux Plumbers Conference 2019 in Lisbon, Portugal. This blog post is a recap of the problem statement and proposed solution we presented.

Our edge servers are crowded. We run more than a dozen public facing services, leaving aside the all internal ones that do the work behind the scenes.
Quick Quiz #1: How many can you name? We blogged about them! Jump to answer.
These services are exposed on more than a million Anycast public IPv4 addresses partitioned into 100+ network prefixes.
To keep things uniform every Cloudflare edge server runs all services and responds to every Anycast address. This allows us to make efficient use of the hardware by load-balancing traffic between all machines. We have shared the details of Cloudflare edge architecture on the blog before.
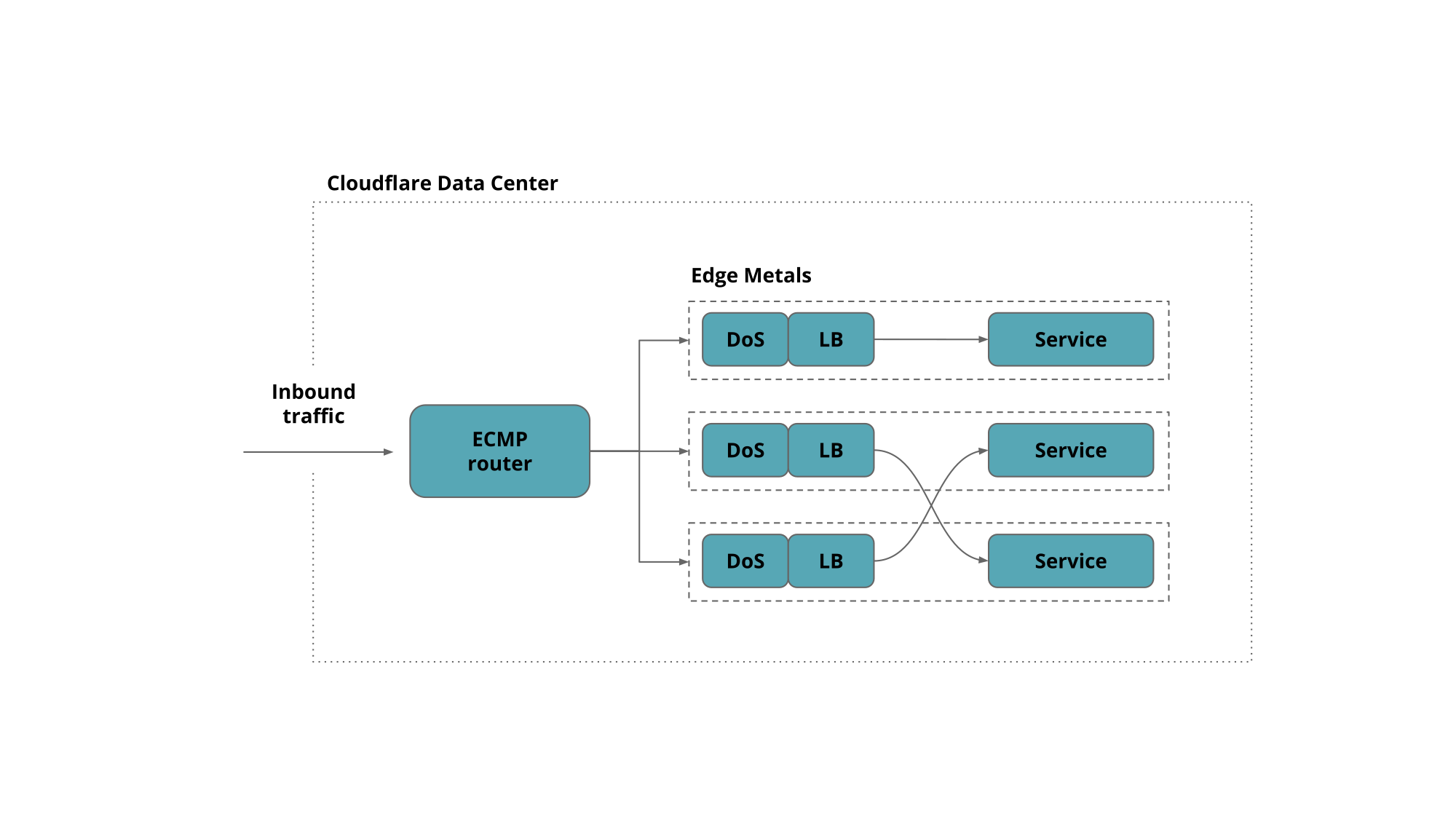
Granted not all services work on all the addresses but rather on a subset of them, covering one or several network prefixes.
So how do you set up your network services to listen on hundreds of IP addresses without driving the network stack over the edge?
Cloudflare engineers have had to ask themselves this question Continue reading
It is unlikely we can tell you anything new about the extended Berkeley Packet Filter, eBPF for short, if you've read all the great man pages, docs, guides, and some of our blogs out there.
But we can tell you a war story, and who doesn't like those? This one is about how eBPF lost its ability to count for a while1.
They say in our Austin, Texas office that all good stories start with "y'all ain't gonna believe this… tale." This one though, starts with a post to Linux netdev mailing list from Marek Majkowski after what I heard was a long night:
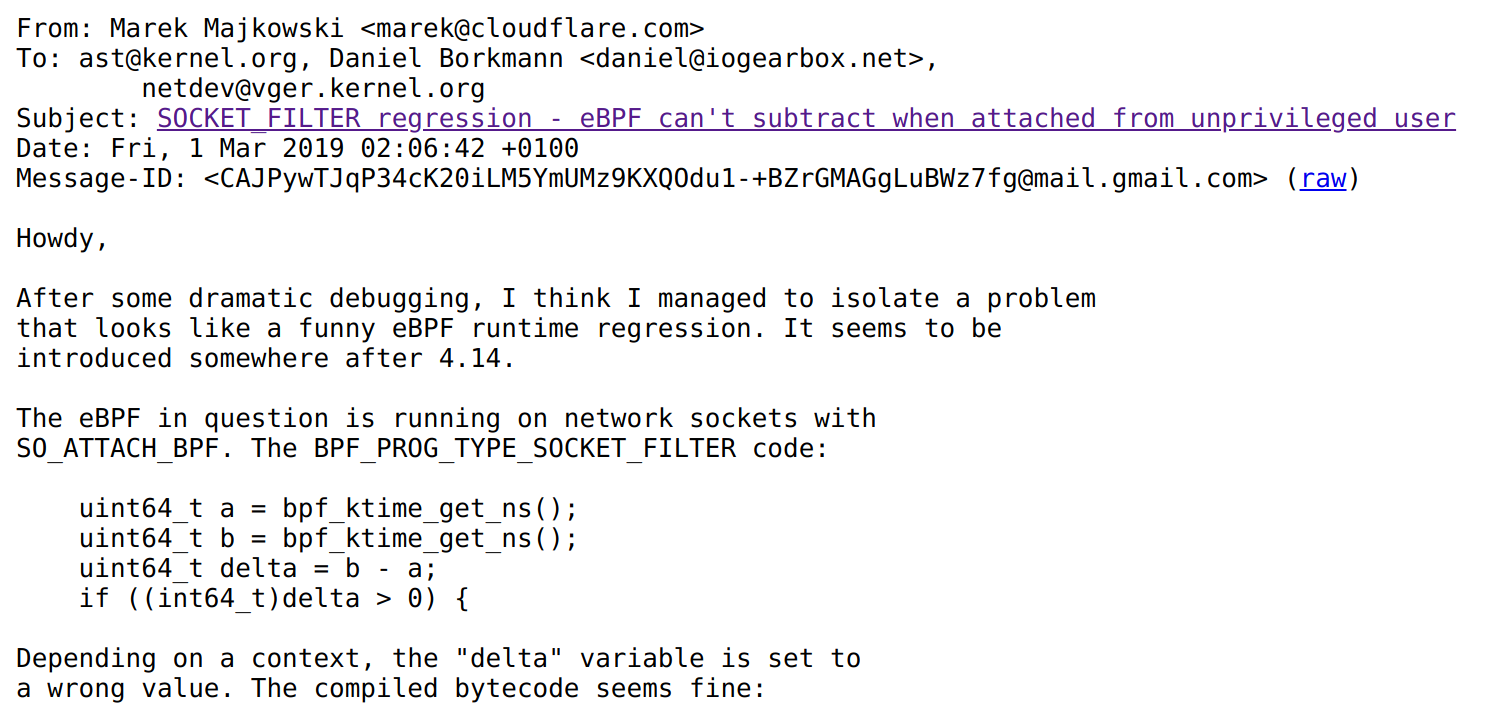
Marek's findings were quite shocking - if you subtract two 64-bit timestamps in eBPF, the result is garbage. But only when running as an unprivileged user. From root all works fine. Huh.
If you've seen Marek's presentation from the Netdev 0x13 conference, you know that we are using BPF socket filters as one of the defenses against simple, volumetric DoS attacks. So potentially getting your packet count wrong could be a Bad Thing™, and affect legitimate traffic.
Let's try to reproduce this bug with Continue reading
{kind=link}