Author Archives: lindsay
Author Archives: lindsay
Been a while since I did a “War Stories” post - here’s one about a routing policy I screwed up recently. Gave me a fright that I’d really messed something up, but in the end it was no big deal, and it taught me something about who uses route collector info.
While looking at bgp.he.net/AS32590 for something unrelated, I saw this:

Investigating more, it tells me this:
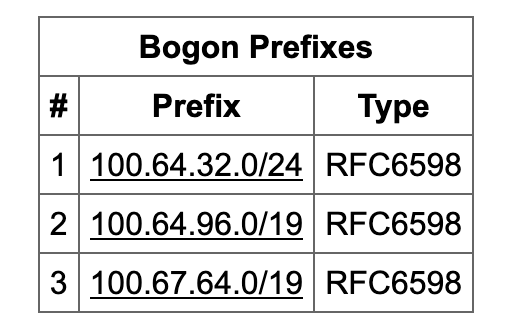
What the hell is going on? We should never be announcing bogon ranges to any peer. I rushed off to check some of our peering sessions, e.g
1
2
3
4
5
6
7
8
lindsayh@rtr> show route advertising-protocol bgp 86.104.125.69
inet.0: 1009955 destinations, 8974886 routes (1008431 active, 2 holddown, 2770 hidden)
Prefix Nexthop MED Lclpref AS path
* 155.133.226.0/24 Self I
* 155.133.229.0/24 Self I
* 155.133.250.0/24 Self I
* 162.254.197.0/24 Self I
We’re just advertising the normal set of prefixes I expect at that site. Defintely not advertising anything unusual to HE. So why do they think we’re advertising bogons?
Hmmm…Cloudflare Radar also says we’re announcing junk. Must Continue reading
I’ve written before about choosing a Juniper version. Juniper has a new release process. Well, two actually - the new official process, and what they’re actually doing…
First the good bits. Juniper started a new release process in 2023. Key points:
I like the new process. It simplifies the versions they have to maintain. We used to say that you should wait for the R3 release, but really there’s no difference between R3 and R2-S3. Now Juniper doesn’t have to maintain the quarterly releases, and all the maintenance and service releases below them. It avoids the confusion that happened when they kept patching -R2, even after releasing R3.
But here’s the thing with a simplified release process: you’ve got no excuses for not delivering. I have no issue with 6-monthly feature releases. But it feels like they’re doing annual releases these days.
Look at the current download page for Continue reading
I recommend always using LACP for external connections. It will make your life easier, even when you only have a single connection. Here’s why we do it.
If you set up a PNI with AS32590, we will strongly recommend the use of LACP, even for a single link. If you have two PNIs with us, they will each be separate single-member LAGs, because they will be on different routers on our side.
It’s only once you have more than 2 links that we start using LACP in the way most people think of it.
It’s not just us. In Google’s Peering Policy, under “Private peering physical connection requirements”, it states
Link aggregation via LACP is required for all links, including single links
Ever wondered why that is? What’s the point in setting up a LAG if I only have one link? What does it give me? More lines of config for no operational enhancement? And I thought we should use L3 everywhere anyway?
I can’t speak for Google, only for the way we operate our network. But I’m pretty sure their reasons are similar to ours. The obvious reason is for future growth, but there are operational benefits too.
The BGP RFCs state that external BGP peers should insert their own AS into the AS PATH advertised to eBGP peers. Some peers strip their AS, generally for commercial gain. Juniper and Cisco have opposite default behaviors for handling this. Make sure you set bgp enforce-first-as on Juniper routers. Caveats apply.
A few years ago I was looking at some traffic reporting anomalies. My IPFIX data said that traffic with next-hop AS <dodgy-AS> was around 3Gb. But my SNMP data showed that a PNI to that peer was doing 8-10Gb.
I first doubted my router, because I had issues with IPFIX in the past on that specific platform. I also wondered about sampling rates. I have high flow rates, and need to set the sampling to be more coarse. But it was a big anomaly.
Slicing & dicing the data different ways, and chatting to colleagues about it, we saw what was going on. IPFIX showed the right volumes when reporting on destination interface. But some prefixes received from the peer did not contain the peer’s AS. We still accepted them.
Huh? Isn’t it normal behavior, to insert your own AS into any prefixes you advertise to Continue reading
Picking the right Junos version is important. If you’re not familiar with Juniper, finding and downloading the right software package is confusing. Here’s some guidance on picking the right version.
It’s useful to understand Junos version numbering, and the upgrade policy. Then check the Suggested Releases page to see what they recommend, check if that makes sense, and figure out how to get from here to there.
These days Juniper publishes a new release train every quarter. Versioning is simple “<year>.<quarter>.R<release number>”. So 21.4R1 is released in the 4th quarter of 2021. New releases add new features and support new hardware. Configs may break
They then publish “service releases” on top of that, for example 21.4R1-S1 and 21.4R1-S2. These are supposed to only be bugfixes, but complacency breeds contempt. So sometimes they throw in throw in breaking changes that may render your existing config non-bootable, because why the hell not? Continue reading
Juniper has a new enhanced four-post rack mount kit “JNP-4PST-RMK-1U-E” for their 1RU datacenter devices. It works with devices like the QFX5120 and PTX10001-36MR. It is much improved over the legacy rack mount kit. It are not as good as some competitors, but it is backwards compatible. It makes switch installation quicker and safer.
Juniper has used the same 4-post kit for their 1RU datacenter switches and routers for many years. The same kit works on QFX5100, QFX5110 and QFX5120-48Y switches. The MX204 uses a slight variation, but is almost identical. Oddly, the QFX5120-32C uses something completely different. Devices are secured to the front and rear posts. 2-post mounting is unwise for modern deep devices with heavy PSUs. You can still get away with 2-post mounting for lighter, shallower access switches. Modern servers and deep switches/routers need 4-post mounting, or some sort of shelf.
The current kit “EX-4PST-RMK” has 2 parts per side:

One piece screws in to each side of the switch. Note that there are 8 holes per side, but Juniper supplies a total of 12 very small screws. As you can imagine, installing 12 very small screws per switch is no fun Continue reading
The Juniper EX3400 switch series is a decent access switch. But a Product Manager chose to save $0.50 on COGS by choosing a 2GB disk. That’s just not enough space to handle normal Junos upgrades. This has wasted untold engineer hours on busywork. I hope that person (A) got a bonus, and (B) is never allowed to under-spec hardware again.
Here’s some tips I’ve learnt for manual and automated upgrades for EX3400s.
Search for “Juniper EX3400 disk space” and you’ll find plenty of people complaining about this, and some suggestions. Juniper KB31198 looks like a good place to start. But it starts with request system storage cleanup and request system snapshot delete snap*.
Those might work if you’re upgrading from 15.1X -> 18.2. Maybe if you’re lucky it will be enough for upgrades within the 18.4 train. But it almost certainly won’t work if you’re going from 18.4.x -> 20.2.x.
There have been PRs that are supposed to fix this, and they might help around the edges, but they don’t help a lot.
With certain version combinations, you could get away with copying the new verson to /mfs, and Continue reading
I’ve written before about the default ARP policer on Juniper MX. It can create some odd failure conditions when you’re connected to noisy networks such as large Internet Exchanges. Junos OS Evolved, as used on platforms like the PTX10003 has low default values for ARP and ICMPv6 ND DDoS protections. It will cause the same problems, but is easier to diagnose and mitigate.
Platforms like MX, QFX, PTX have Control Plane DDoS protections built in. These will automatically rate-limit various traffic types that hit the CPU. This is generally a Good Thing. Certain packet types get punted from the ASIC to the CPU, but the CPU can’t handle anywhere near the traffic levels that the forwarding ASIC can. Send enough special packets to a router, choke the CPU, and you might be able to knock things offline. So having default policies to rate-limit traffic makes sense.
Juniper might have “One Junos” but we know it’s not that simple. Behavior varies between platforms. Check these default values for some DDoS protections for different platforms:
| Protocol | MX | QFX | PTX |
|---|---|---|---|
| ARP | 20,000 | 500 | 500 |
| NDPv6 | 20,000 | N/A | 500 |
| ICMP | 20,000 | N/A | 500 |
| BGP | 20,000 | 3,000 | 5,000 |
Note Continue reading
Juniper Routing Engines with VM Host need an i40e NVM firmware upgrade. The procedure is a pain in the ass, and documentation is not great. But you can’t avoid the upgrade any more. New Junos versions need the firmware upgrade, and replacement REs will ship with it already installed. Here’s some tips on doing the upgrade.
Newer Juniper Routing Engines use a Linux-based hypervisor, and Junos (still BSD-based) runs as a guest VM. This is mostly transparent for day to day operations. When you do a Junos upgrade, it will upgrade the underlying hypervisor if required.
Upcoming Junos versions ship with a new version of Wind River Linux that needs i40e firmware version 6.01. Older versions used v4.26. You need the new i40e firmware installed first, before you can install the latest Junos versions. You can’t put this upgrade off forever. Sooner or later you’ll want to ugprade to a Junos version that only supports the new firmware. Or you’ll get a replacement RE delivered with new firmware, and you can’t downgrade it.
For the last couple of years, Juniper has been shipping Junos versions that will work with both old & new firmware versions. You Continue reading
Juniper routers consider a directly configured IP as a “local” route, except when you use /32 mask. Then it is a “direct” route. This caused me some confusion when creating a policy to redistribute loopback IP addresses into BGP.
A router learns routes from a variety of sources - networks configured on the box, those learned from IS-IS, rumors of prefixes from BGP or RIP, etc. You can see the full list here.
When routes are learned from different sources, Junos uses “Route Preference Values” to decide which route source to prefer. (Cisco refers to this as Administrative Distance). If routes are otherwise identical, the route with the lowest preference will be installed into the FIB.
If you’re looking at the route table, you can narrow down displayed routes to look at a specific type, e.g. show route protocol direct to see locally connected networks:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
vagrant@vqfx> show route protocol direct
inet.0: 7 destinations, 7 routes (7 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, Continue reading
Juniper routers consider a directly configured IP as a “local” route, except when you use /32 mask. Then it is a “direct” route. This caused me some confusion when creating a policy to redistribute loopback IP addresses into BGP.
A router learns routes from a variety of sources - networks configured on the box, those learned from IS-IS, rumors of prefixes from BGP or RIP, etc. You can see the full list here.
When routes are learned from different sources, Junos uses “Route Preference Values” to decide which route source to prefer. (Cisco refers to this as Administrative Distance). If routes are otherwise identical, the route with the lowest preference will be installed into the FIB.
If you’re looking at the route table, you can narrow down displayed routes to look at a specific type, e.g. show route protocol direct to see locally connected networks:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
vagrant@vqfx> show route protocol direct
inet.0: 7 destinations, 7 routes (7 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, Continue reading
Juniper devices have a default ARP policer that drops ARP requests and responses over 150kbps. By default, this is an aggregate policer that applies to all interfaces. This can lead to unexpected behavior when high levels of ARP on one interface lead to BGP session drops on another interface. You can’t change the default policer limits, but you can create a new policer, with higher limits.
I was investigating a problem reported by one of our Transit providers. Once a day or so, our IPv4 BGP session with them would flap. The interface itself was stable, and the IPv6 session remained up. One particular site was seeing this more than others. The sites used different platforms, but were running the same code version.
The curious thing was the logs - we saw log messages saying that we had a notification message saying NOTIFICATION received from 192.0.2.188 (External AS 64498): code 4 (Hold Timer Expired Error). The syslog included this hold timer 30s, hold timer remain 0s, last sent 2s. So our router thought it was sending regular KEEPALIVE messages, but the remote end thought it had missed too many.
Looking Continue reading
Juniper devices have a default ARP policer that drops ARP requests and responses over 150kbps. By default, this is an aggregate policer that applies to all interfaces. This can lead to unexpected behavior when high levels of ARP on one interface lead to BGP session drops on another interface. You can’t change the default policer limits, but you can create a new policer, with higher limits.
I was investigating a problem reported by one of our Transit providers. Once a day or so, our IPv4 BGP session with them would flap. The interface itself was stable, and the IPv6 session remained up. One particular site was seeing this more than others. The sites used different platforms, but were running the same code version.
The curious thing was the logs - we saw log messages saying that we had a notification message saying NOTIFICATION received from 192.0.2.188 (External AS 64498): code 4 (Hold Timer Expired Error). The syslog included this hold timer 30s, hold timer remain 0s, last sent 2s. So our router thought it was sending regular KEEPALIVE messages, but the remote end thought it had missed too many.
Looking Continue reading
Juniper SRX 300 Series firewalls may stop forwarding traffic in some situations. The firewall says it is forwarding the traffic, but it doesn’t work. Monitoring traffic looks OK, ARP entries are present, but traffic never gets to the destination, until you clear ARP. Turns out the problem comes from using LACP with fast timers and active mode. Luckily the fix is simple.
Here’s the situation we saw: Our NMS reported a Juniper SRX320 offline. All other devices at the site were still working, but the firewall was unreachable. Traffic from the firewall to the NMS goes via the firewall’s default gateway. Firewall A in this diagram was unreachable, but Firewall B was fine.
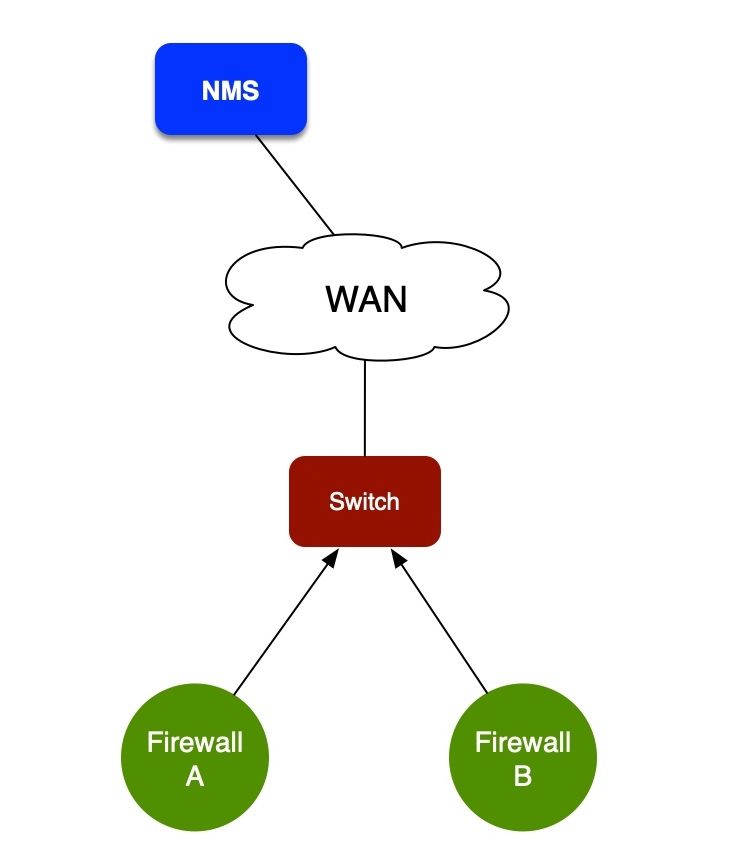
OK, what’s happening? Why is my firewall unreachable?
Try to ping Firewall A, no response. From the default gateway, we can see an ARP entry for the firewall, but no response to ping. We can log in to Firewall B, and we see an ARP entry for Firewall A. Crucially: we can ping Firewall A from Firewall B. Hmmm. That’s strange. Why can we ping it from one locally connected device but not another?
From Firewall B, we SSH across Continue reading
Juniper SRX 300 Series firewalls may stop forwarding traffic in some situations. The firewall says it is forwarding the traffic, but it doesn’t work. Monitoring traffic looks OK, ARP entries are present, but traffic never gets to the destination, until you clear ARP. Turns out the problem comes from using LACP with fast timers and active mode. Luckily the fix is simple.
Here’s the situation we saw: Our NMS reported a Juniper SRX320 offline. All other devices at the site were still working, but the firewall was unreachable. Traffic from the firewall to the NMS goes via the firewall’s default gateway. Firewall A in this diagram was unreachable, but Firewall B was fine.
OK, what’s happening? Why is my firewall unreachable?
Try to ping Firewall A, no response. From the default gateway, we can see an ARP entry for the firewall, but no response to ping. We can log in to Firewall B, and we see an ARP entry for Firewall A. Crucially: we can ping Firewall A from Firewall B. Hmmm. That’s strange. Why can we ping it from one locally connected device but not another?
From Firewall B, we SSH across Continue reading
IPFIX is problematic on the Juniper QFX10K switches. Documentation is sparse, and doesn’t have a complete configuration. Behavior changes between versions in undocumented ways. Here’s a couple of things I noticed when upgrading from Junos 17.3 to 17.4. These also apply if you are running 18.4 code. I hit more problems with 18.4, and ended up rolling back to 17.4.
Here’s a graph showing total reported throughput for a QFX10K I upgraded:
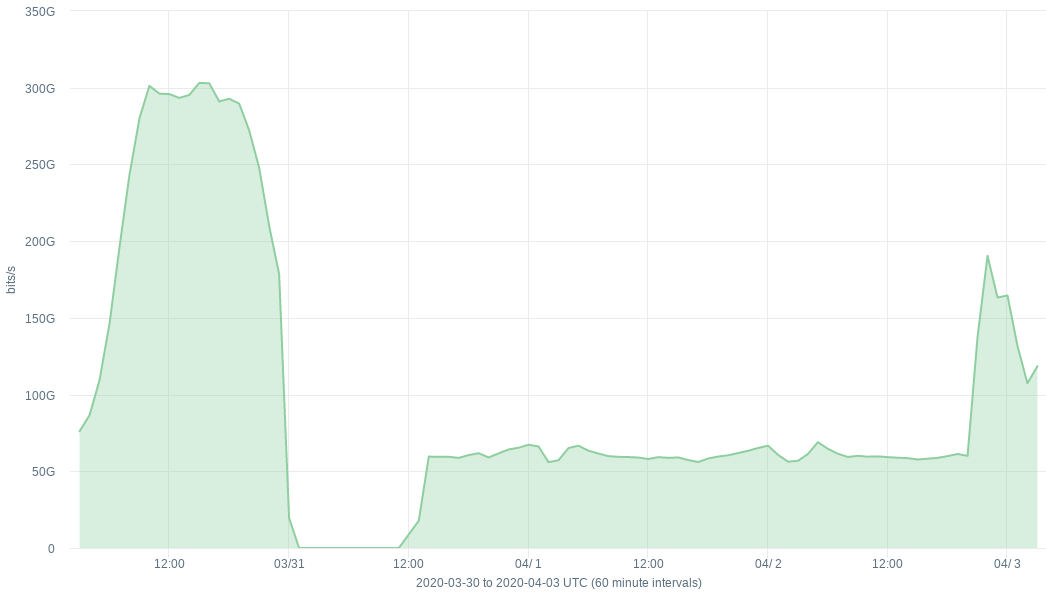
There’s a few things going on there. First the reported traffic drops to zero after I upgraded. Then it starts coming up, after I fixed the first problem. But then after that the reported traffic is flat, and lower than it should be. Then it starts coming up again after I made the second fix.
The first configuration change I needed to add was this: set chassis fpc 0 sampling-instance sample-border, where sample-border is the name of the sampling instance I have configured under forwarding-options. This was not required with 17.3. If you don’t do it with 17.4, you won’t get any data.
Some Juniper platforms implement Continue reading
IPFIX is problematic on the Juniper QFX10K switches. Documentation is sparse, and doesn’t have a complete configuration. Behavior changes between versions in undocumented ways. Here’s a couple of things I noticed when upgrading from Junos 17.3 to 17.4. These also apply if you are running 18.4 code. I hit more problems with 18.4, and ended up rolling back to 17.4.
Here’s a graph showing total reported throughput for a QFX10K I upgraded:
There’s a few things going on there. First the reported traffic drops to zero after I upgraded. Then it starts coming up, after I fixed the first problem. But then after that the reported traffic is flat, and lower than it should be. Then it starts coming up again after I made the second fix.
The first configuration change I needed to add was this: set chassis fpc 0 sampling-instance sample-border, where sample-border is the name of the sampling instance I have configured under forwarding-options. This was not required with 17.3. If you don’t do it with 17.4, you won’t get any data.
Some Juniper platforms implement Continue reading
Juniper changed the way they do temperature management on MX240 and MX480 chassis devices, somewhere between 15.1 and 17.3. The net result is that your chassis might run hotter after you upgrade, which can lead to the system shutting down some optics. Probably not what you want. Luckily there’s a few hidden commands you can use to change this behavior
Post upgrade, you might see higher temperatures reported by show chassis fpc. This system was reporting temperatures in the low 30s, now it reports 50:
1
2
3
4
5
6
7
8
9
lindsayh@MX240> show chassis fpc
Temp CPU Utilization (%) CPU Utilization (%) Memory Utilization (%)
Slot State (C) Total Interrupt 1min 5min 15min DRAM (MB) Heap Buffer
0 Empty
1 Online 50 22 1 22 22 22 2048 38 21
2 Empty
{master}
lindsayh@MX240>
On its own, that’s OK, until you start seeing log messages like this:
1
FPC 1 temperature over 50 degrees C; non-high-temperature tolerant optics will be disabled in 58 seconds if condition persists
Yeah that’s not good, especially when it carries out the threat, and Continue reading
Juniper changed the way they do temperature management on MX240 and MX480 chassis devices, somewhere between 15.1 and 17.3. The net result is that your chassis might run hotter after you upgrade, which can lead to the system shutting down some optics. Probably not what you want. Luckily there’s a few hidden commands you can use to change this behavior
Post upgrade, you might see higher temperatures reported by show chassis fpc. This system was reporting temperatures in the low 30s, now it reports 50:
1
2
3
4
5
6
7
8
9
lindsayh@MX240> show chassis fpc
Temp CPU Utilization (%) CPU Utilization (%) Memory Utilization (%)
Slot State (C) Total Interrupt 1min 5min 15min DRAM (MB) Heap Buffer
0 Empty
1 Online 50 22 1 22 22 22 2048 38 21
2 Empty
{master}
lindsayh@MX240>
On its own, that’s OK, until you start seeing log messages like this:
1
FPC 1 temperature over 50 degrees C; non-high-temperature tolerant optics will be disabled in 58 seconds if condition persists
Yeah that’s not good, especially when it carries out the threat, and Continue reading
I came across a situation where a software upgrade failed for some members in a Juniper QFX Virtual Chassis. There is a known issue with upgrades with a certain configuration + version combination, but I thought it didn’t apply to me. Turns out that the key was the host OS version, not the Junos VM version. Your host and guest versions can be out of sync with Juniper QFX 5K devices, and this can lead to confusing behavior, especially in a virtual chassis where host OS versions might vary.
When upgrading an old Juniper QFX5100, you might see these messages when running the upgrade:
1
2
Error: jinstall-vjunos fails post-install
Error: jinstall-vjunos-14.1X53-D34-domestic-signed fails post-install
In my case, I saw it for some nodes in a Virtual Chassis. Some worked, some failed. KB31923 says that this error is due to this configuration:
1
2
3
# show system internet-options
tcp-drop-synfin-set;
no-tcp-reset drop-tcp-with-syn-only;
Easy enough to change:
1
2
3
4
5
6
7
8
9
10
# delete system internet-options
{master:0}[edit]
root# show |compare
[edit system]
internet-options {
tcp-drop-synfin-set;
no-tcp-reset drop-tcp-with-syn-only;
{master:0}[edit]
root# commit