Author Archives: lindsay
Author Archives: lindsay
I came across a situation where a software upgrade failed for some members in a Juniper QFX Virtual Chassis. There is a known issue with upgrades with a certain configuration + version combination, but I thought it didn’t apply to me. Turns out that the key was the host OS version, not the Junos VM version. Your host and guest versions can be out of sync with Juniper QFX 5K devices, and this can lead to confusing behavior, especially in a virtual chassis where host OS versions might vary.
When upgrading an old Juniper QFX5100, you might see these messages when running the upgrade:
1
2
Error: jinstall-vjunos fails post-install
Error: jinstall-vjunos-14.1X53-D34-domestic-signed fails post-install
In my case, I saw it for some nodes in a Virtual Chassis. Some worked, some failed. KB31923 says that this error is due to this configuration:
1
2
3
# show system internet-options
tcp-drop-synfin-set;
no-tcp-reset drop-tcp-with-syn-only;
Easy enough to change:
1
2
3
4
5
6
7
8
9
10
# delete system internet-options
{master:0}[edit]
root# show |compare
[edit system]
internet-options {
tcp-drop-synfin-set;
no-tcp-reset drop-tcp-with-syn-only;
{master:0}[edit]
root# commit
Juniper routing instances are very useful when you need separate routing tables on the one device, for example to separate customers. Junos lets you configure SNMP polling of routing instances, so customers can poll “their” interfaces using 'instance_name'@'community'. All very useful. But it wasn’t obvious to me how to poll the default table via an interface in a routing instance. The trick is to just use @'community'. Here’s an example.
To demo this I have a simple network. I’m using a Virtual QFX plus Vagrant setup, based on the Vagrantfiles in this repo. I’m running one vqfx10k, connected to one server. The key here is that the server has two connections to the vqfx. One interface is in the default instance, one is in a “Customer” routing instance:
Here’s the routing-instance config:
1
2
3
4
5
6
7
8
vagrant@vqfx> show configuration routing-instances
Customer {
instance-type virtual-router;
interface xe-0/0/1.0;
}
{master:0}
vagrant@vqfx>
And here’s my SNMP configuration:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
vagrant@vqfx> show Continue reading
Juniper routing instances are very useful when you need separate routing tables on the one device, for example to separate customers. Junos lets you configure SNMP polling of routing instances, so customers can poll “their” interfaces using 'instance_name'@'community'. All very useful. But it wasn’t obvious to me how to poll the default table via an interface in a routing instance. The trick is to just use @'community'. Here’s an example.
To demo this I have a simple network. I’m using a Virtual QFX plus Vagrant setup, based on the Vagrantfiles in this repo. I’m running one vqfx10k, connected to one server. The key here is that the server has two connections to the vqfx. One interface is in the default instance, one is in a “Customer” routing instance:
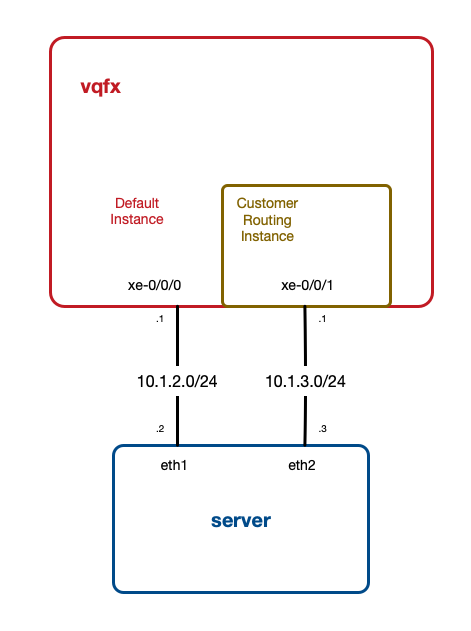
Here’s the routing-instance config:
1
2
3
4
5
6
7
8
vagrant@vqfx> show configuration routing-instances
Customer {
instance-type virtual-router;
interface xe-0/0/1.0;
}
{master:0}
vagrant@vqfx>
And here’s my SNMP configuration:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
vagrant@vqfx> Continue reading
I have started a new role as a Network Engineer with Valve Corporation. My period of unemployment was short-lived, and I am gainfully employed once more.
Did I think about going to work for another vendor? Yes, I did. I thought a lot about what I want to do, and what type of company I want to work for. Small/medium/large, vendor/customer, Product Manager vs Engineer, etc.
For now, I decided I want to solve business problems using whichever tools are appropriate, rather than building and selling a single product. I didn’t want to work for a company that just consumes technology though. I want to work somewhere that has interesting problems, and will do whatever is needed to solve those problems - build/buy/cobble together.
Valve is big enough to offer the right level of challenge, but also small enough that I can make a difference. I’m not lost in the machine, but I am working on a global network.
Valve is also quite a different company. Check out the Employee Handbook to get a sense of Continue reading
I have started a new role as a Network Engineer with Valve Corporation. My period of unemployment was short-lived, and I am gainfully employed once more.
Did I think about going to work for another vendor? Yes, I did. I thought a lot about what I want to do, and what type of company I want to work for. Small/medium/large, vendor/customer, Product Manager vs Engineer, etc.
For now, I decided I want to solve business problems using whichever tools are appropriate, rather than building and selling a single product. I didn’t want to work for a company that just consumes technology though. I want to work somewhere that has interesting problems, and will do whatever is needed to solve those problems - build/buy/cobble together.
Valve is big enough to offer the right level of challenge, but also small enough that I can make a difference. I’m not lost in the machine, but I am working on a global network.
Valve is also quite a different company. Check out the Employee Handbook to get a sense of Continue reading
This blog is now hosted via Netlify, rather than GitHub Pages. It is still built using Jekyll, but I updated the theme to Mediumish.
I looked at switching to Hugo for site generation, but I hit several bugs trying to do the import, and theme setup was a pain. So I stuck with Jekyll, because it’s doing what I need. Using Netlify gives me a few more options around build and deploy, and moves away from Cloudflare.
All URLs and RSS feed should remain the same. Let me know if you see any issues.
This blog is now hosted via Netlify, rather than GitHub Pages. It is still built using Jekyll, but I updated the theme to Mediumish.
I looked at switching to Hugo for site generation, but I hit several bugs trying to do the import, and theme setup was a pain. So I stuck with Jekyll, because it’s doing what I need. Using Netlify gives me a few more options around build and deploy, and moves away from Cloudflare.
All URLs and RSS feed should remain the same. Let me know if you see any issues.
I’ve given in to the Sunk Cost Fallacy once more: I’ve renewed my CCIE. There was a lot of foot dragging this time around, and I only had four months to spare. But it’s done, for another year. Here’s some quick notes on my prep, and thoughts on the exam.
I decided to sit the CCIE R&S Written Exam to renew. This was the easiest route for me. I don’t use Cisco products on a day to day basis, so certifying with a different track would be very hard for me.
The version hasn’t changed since the last time I sat it. It’s still 400-100, v5.1. The only difference is that the “Evolving Technologies” section has been tweaked a little. Think Automation toolsets, Cloud concepts, etc.
I used the study guide I purchased last time from “CCIE in 8 Weeks”. I also re-subscribed to their online practice exams. I meant to only subscribe for 3 months, but…I couldn’t get motivated to do this exam. I ended up paying for another 3 months access, before I finally knuckled down and did the study while I was on vacation. I flicked through my old CCIE flashcards a few times too.
I’ve given in to the Sunk Cost Fallacy once more: I’ve renewed my CCIE. There was a lot of foot dragging this time around, and I only had four months to spare. But it’s done, for another year. Here’s some quick notes on my prep, and thoughts on the exam.
I decided to sit the CCIE R&S Written Exam to renew. This was the easiest route for me. I don’t use Cisco products on a day to day basis, so certifying with a different track would be very hard for me.
The version hasn’t changed since the last time I sat it. It’s still 400-100, v5.1. The only difference is that the “Evolving Technologies” section has been tweaked a little. Think Automation toolsets, Cloud concepts, etc.
I used the study guide I purchased last time from “CCIE in 8 Weeks”. I also re-subscribed to their online practice exams. I meant to only subscribe for 3 months, but…I couldn’t get motivated to do this exam. I ended up paying for another 3 months access, before I finally knuckled down and did the study while I was on vacation. I flicked through my old CCIE flashcards a few times too.
I’ve given in to the Sunk Cost Fallacy once more: I’ve renewed my CCIE. There was a lot of foot dragging this time around, and I only had four months to spare. But it’s done, for another year. Here’s some quick notes on my prep, and thoughts on the exam.
I decided to sit the CCIE R&S Written Exam to renew. This was the easiest route for me. I don’t use Cisco products on a day to day basis, so certifying with a different track would be very hard for me.
The version hasn’t changed since the last time I sat it. It’s still 400-100, v5.1. The only difference is that the “Evolving Technologies” section has been tweaked a little. Think Automation toolsets, Cloud concepts, etc.
I used the study guide I purchased last time from “CCIE in 8 Weeks”. I also re-subscribed to their online practice exams. I meant to only subscribe for 3 months, but…I couldn’t get motivated to do this exam. I ended up paying for another 3 months access, before I finally knuckled down and did the study while I was on vacation. I flicked through my old CCIE flashcards a few times too.
I’ve given in to the Sunk Cost Fallacy once more: I’ve renewed my CCIE. There was a lot of foot dragging this time around, and I only had four months to spare. But it’s done, for another year. Here’s some quick notes on my prep, and thoughts on the exam.
I decided to sit the CCIE R&S Written Exam to renew. This was the easiest route for me. I don’t use Cisco products on a day to day basis, so certifying with a different track would be very hard for me.
The version hasn’t changed since the last time I sat it. It’s still 400-100, v5.1. The only difference is that the “Evolving Technologies” section has been tweaked a little. Think Automation toolsets, Cloud concepts, etc.
I used the study guide I purchased last time from “CCIE in 8 Weeks”. I also re-subscribed to their online practice exams. I meant to only subscribe for 3 months, but…I couldn’t get motivated to do this exam. I ended up paying for another 3 months access, before I finally knuckled down and did the study while I was on vacation. I flicked through my old CCIE flashcards a few times too.
Using network CLI for automation has always been fragile. But it keeps surprising me with the way it breaks. This time, it was a combination of Ansible, Arista, replace: config and terminal length used as a config command.
I often hang out in the NTC Slack channel. A user reported they were having a problem with Ansible and EOS. Basic changes worked, but when they used eos_config with the replace: config option, it just timed out. We knew basic authentication & connectivity was fine, it had to be something else.
But it made no sense, because these modules are widely used. What’s going on?
Some commands produce more than one screen’s worth of output - for example, show run can be hundreds of lines long. Most screens don’t have hundreds of lines, so pagination is used. The network Continue reading
Using network CLI for automation has always been fragile. But it keeps surprising me with the way it breaks. This time, it was a combination of Ansible, Arista, replace: config and terminal length used as a config command.
I often hang out in the NTC Slack channel. A user reported they were having a problem with Ansible and EOS. Basic changes worked, but when they used eos_config with the replace: config option, it just timed out. We knew basic authentication & connectivity was fine, it had to be something else.
But it made no sense, because these modules are widely used. What’s going on?
Some commands produce more than one screen’s worth of output - for example, show run can be hundreds of lines long. Most screens don’t have hundreds of lines, so pagination is used. The network Continue reading
Using network CLI for automation has always been fragile. But it keeps surprising me with the way it breaks. This time, it was a combination of Ansible, Arista, replace: config and terminal length used as a config command.
I often hang out in the NTC Slack channel. A user reported they were having a problem with Ansible and EOS. Basic changes worked, but when they used eos_config with the replace: config option, it just timed out. We knew basic authentication & connectivity was fine, it had to be something else.
But it made no sense, because these modules are widely used. What’s going on?
Some commands produce more than one screen’s worth of output - for example, show run can be hundreds of lines long. Most screens don’t have hundreds of lines, so pagination is used. The network Continue reading
We are now Lawful Permanent Residents of the United States - aka Green Card Holders. It took a few years to get to this point. Here’s our timeline, why we did it, what it means for us, and what next.
I first moved to the US on an L-1B visa. This is an intra-company transfer visa, that let me move to the US to continue working for Brocade.
Total Continue reading
We are now Lawful Permanent Residents of the United States - aka Green Card Holders. It took a few years to get to this point. Here’s our timeline, why we did it, what it means for us, and what next.
I first moved to the US on an L-1B visa. This is an intra-company transfer visa, that let me move to the US to continue working for Brocade.
Total Continue reading
We are now Lawful Permanent Residents of the United States - aka Green Card Holders. It took a few years to get to this point. Here’s our timeline, why we did it, what it means for us, and what next.
I first moved to the US on an L-1B visa. This is an intra-company transfer visa, that let me move to the US to continue working for Brocade.
Total Continue reading
I use a Privacy Filter on my laptop screen when traveling. I’m doing a bit of time on planes these days, and it makes a big difference. Most of my code is Open Source, but other content is proprietary. High chance of competitors being on the same plane as me, so better to make it harder for others to see.
The only problem with these screens is that if you frequently take it off like I do, the adhesive strips collect dust, and stop sticking after a while. Recently someone asked me how to get them replaced.
3M does not sell replacement strips…but they do something even better: they give them away for free. Pretty cool ah?
Just go here, fill in the details, and they’ll send you some more. How good is that?
I use a Privacy Filter on my laptop screen when traveling. I’m doing a bit of time on planes these days, and it makes a big difference. Most of my code is Open Source, but other content is proprietary. High chance of competitors being on the same plane as me, so better to make it harder for others to see.
The only problem with these screens is that if you frequently take it off like I do, the adhesive strips collect dust, and stop sticking after a while. Recently someone asked me how to get them replaced.
3M does not sell replacement strips…but they do something even better: they give them away for free. Pretty cool ah?
Just go here, fill in the details, and they’ll send you some more. How good is that?
I use a Privacy Filter on my laptop screen when traveling. I’m doing a bit of time on planes these days, and it makes a big difference. Most of my code is Open Source, but other content is proprietary. High chance of competitors being on the same plane as me, so better to make it harder for others to see.
The only problem with these screens is that if you frequently take it off like I do, the adhesive strips collect dust, and stop sticking after a while. Recently someone asked me how to get them replaced.
3M does not sell replacement strips…but they do something even better: they give them away for free. Pretty cool ah?
Just go here, fill in the details, and they’ll send you some more. How good is that?