Author Archives: networkop on networkop
Author Archives: networkop on networkop
Any network device, be it a transit router or a host, usually has multiple IP addresses assigned to its interfaces. One of the first things we learn as network engineers is how to determine which IP address is used for the locally-sourced traffic. However, the default scenario can be changed in a couple of different ways and this post is a brief documentation of the available options.
Whenever a local application decides to connect to a remote network endpoint, it creates a network socket, providing a minimal amount of details required to build and send a network packet. Most often, this information includes a destination IP and port number as you can see from the following abbreviated output:
$ strace -e trace=network curl http://example.com
socket(AF_INET, SOCK_STREAM, IPPROTO_TCP) = 6
setsockopt(6, SOL_TCP, TCP_NODELAY, [1], 4) = 0
setsockopt(6, SOL_SOCKET, SO_KEEPALIVE, [1], 4) = 0
setsockopt(6, SOL_TCP, TCP_KEEPIDLE, [60], 4) = 0
setsockopt(6, SOL_TCP, TCP_KEEPINTVL, [60], 4) = 0
connect(6, {sa_family=AF_INET, sin_port=htons(80), sin_addr=inet_addr("93.184.216.34")}, 16)
While this output does not show the DNS resolution part (due to getaddrinfo() not being a syscall), we can see that the only user-specific input information provided by an application ( Continue reading
In the previous post, I mentioned that CUE can help you work with both “industry-standard” semi-structured APIs and fully structured APIs where data is modelled using OpenAPI or JSON schema. However, there was an elephant in the room that I conveniently ignored but without which no conversation about network automation would be complete. With this post, I plan to rectify my previous omission and explain how you can use CUE to work with YANG-based APIs. More specifically, I’ll focus on OpenConfig and gNMI and show how CUE can be used to write YANG-based configuration data, validate it and send it to a remote device.
Working with YANG-based APIs is not much different from what I’ve described in the two previous blog posts [1] and [2]. We’re still dealing with structured data that gets assembled based on the rules defined in a set of YANG models and sent over the wire using one of the supported protocols (Netconf, Restconf or gNMI). One of the biggest differences, though, is that data generation gets done in one of the general-purpose programming languages (e.g. Python, Go), since doing it in Ansible is not feasible due to the Continue reading
What I’ve covered in the previous blog post about CUE and Ansible were isolated use cases, disconnected islands in the sea of network automation. The idea behind that was to simplify the introduction of CUE into existing network automation workflows. However, this does not mean CUE is limited to those use cases and, in fact, CUE is most powerful when it’s used end-to-end — both to generate device configurations and to orchestrate interactions with external systems. In this post, I’m going to demonstrate how to use CUE for advanced network automation workflows involving fetching information from an external device inventory management system, using it to build complex hierarchical configuration values and, finally, generating and pushing intended configurations to remote network devices.
CUE was designed to be a simple, scalable and robust configuration language. This is why it includes type checking, schema and constraints validation as first-class constructs. There are some design decisions, like the lack of inheritance or value overrides, that may take new users by surprise, however over time it becomes clear that they make the language simpler and more readable. One of the most interesting features of CUE, though, is that all code Continue reading
Hardly any conversation about network automation that happens these days can avoid the topic of automation frameworks. Amongst the few that are still actively developed, Ansible is by far the most popular choice. Ansible ecosystem has been growing rapidly over the last few years, with modules being contributed by both internal (Redhat) and external (community) developers. Having the backing of one of the largest open-source first companies has allowed Ansible to spread into all areas of infrastructure – from server automation to cloud provisioning. By following the principle of eating your own dog food, Redhat used Ansible in a lot of its own open-source projects, which made it even more popular in the masses. Another important factor in Ansible’s success is the ease of understanding. When it comes to network automation, Ansible’s stateless and agentless architecture very closely follows a standard network operation experience – SSH in, enter commands line-by-line, catch any errors, save and disconnect. But like many complex software projects, Ansible is not without its own challenges, and in this post, I’ll take a look at what they are and how CUE can help overcome them.
Let’s start with an overview of the intermediate Ansible Continue reading
In the past few years, network automation has made its way from a new and fancy way of configuring devices to a well-recognized industry practice. What started as a series of “hello world” examples has evolved into an entire discipline with books, professional certifications and dedicated career paths. It’s safe to say that today, most large-scale networks (>100 devices) are at least deployed (day 0) and sometimes managed (day 1+) using an automated workflow. However, at the heart of these workflows are the same exact principles and tools that were used in the early days. Of course, these tools have evolved and matured but they still have the same scope and limitations. Very often, these limitations are only becoming obvious once we hit a certain scale or complexity, which makes it even more difficult to replace them. The easiest option is to accept and work around them, forcing the square peg down the round hole. In this post, I’d like to propose an alternative approach to what I’d consider “traditional” network automation practices by shifting the focus from “driving the CLI” to the management of data. I believe that this adjustment will enable us to build automation workflows that are Continue reading
In one of his recent posts, Ivan raises a question: “I can’t grasp why Cumulus releases a Vagrant box, but not a Docker container”. Coincidentally, only a few weeks before that I had managed to create a Cumulus Linux container image. Since then, I’ve done a lot of testing and discovered limitations of the pure containerised approach and how to overcome them while still retaining the container user experience. This post is a documentation of my journey from the early days of running Cumulus on Docker to the integration with containerlab and, finally, running Cumulus in microVMs backed by AWS’s Firecracker and Weavework’s Ignite.
One of the main reason for running containerised infrastructure is the famous Docker UX. Containers existed for a very long time but they only became mainstream when docker released their container engine. The simplicity of a typical docker workflow (build, ship, run) made it accessible to a large number of not-so-technical users and was the key to its popularity.
Virtualised infrastructure, including networking operating systems, has mainly been distributed in a VM form-factor, retaining much of the look and feel of the real hardware for the software processes running on top. However it Continue reading
eBPF has a thriving ecosystem with a plethora of educational resources both on the subject of eBPF itself and its various application, including XDP. Where it becomes confusing is when it comes to the choice of libraries and tools to interact with and orchestrate eBPF. Here you have to select between a Python-based BCC framework, C-based libbpf and a range of Go-based libraries from Dropbox, Cilium, Aqua and Calico. Another important area that is often overlooked is the “productionisation” of the eBPF code, i.e. going from manually instrumented examples towards production-grade applications like Cilium. In this post, I’ll document some of my findings in this space, specifically in the context of writing a network (XDP) application with a userspace controller written in Go.
In most cases, an eBPF library is there to help you achieve two things:
Some libraries may also help you attach your eBPF program to a specific Continue reading
When using a personal VPN at home, one of the biggest problems I’ve faced was the inability to access public streaming services. I don’t care about watching Netflix from another country, I just want to be able to use my local internet connection for this kind of traffic while still encrypting everything else. This problem is commonly known in network engineering as “local internet breakout” and is often implemented at remote branch/edge sites to save costs of transporting SaaS traffic (e.g. Office365) over the VPN infrastructure. These “local breakout” solutions often rely on explicit enumeration of all public IP subnets, which is a bit cumbersome, or require “intelligent” (i.e. expensive) DPI functionality. However, it is absolutely possible to build something like this for personal use and this post will demonstrate how to do that.
The problem scope consists of two relatively independent areas:
Traffic routing - how to forward traffic to different outgoing interfaces based on the target domain.
VPN management - how to connect to the best VPN gateway and make sure that connection stays healthy.
Each of one these problem areas is addressed by a separate set of components.
VPN management is solved Continue reading
There comes a time in the life of every Kubernetes cluster when internal resources (pods, deployments) need to be exposed to the outside world. Doing so from a pure IP connectivity perspective is relatively easy as most of the constructs come baked-in (e.g. NodePort-type Services) or can be enabled with an off-the-shelf add-on (e.g. Ingress and LoadBalancer controllers). In this post, we’ll focus on one crucial piece of network connectivity which glues together the dynamically-allocated external IP with a static customer-defined hostname — a DNS. We’ll examine the pros and cons of various ways of implementing external DNS in Kubernetes and introduce a new CoreDNS plugin that can be used for dynamic discovery and resolution of multiple types of external Kubernetes resources.

Let’s start by reviewing various types of “external” Kubernetes resources and the level of networking abstraction they provide starting from the lowest all the way to the highest level.
One of the most fundamental building block of all things external in Kubernetes is the NodePort service. It works by allocating a unique external port for every service instance and setting up kube-proxy to deliver incoming packets from that port to the one of Continue reading
Every Kubernetes cluster is provisioned with a special service that provides a way for internal applications to talk to the API server. However, unlike the rest of the components that get spun up by default, you won’t find the definition of this service in any of the static manifests and this is just one of the many things that make this service unique.
To make sure we’re on the same page, I’m talking about this:
$ kubect get svc kubernetes -n default
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 161m
This service is unique in many ways. First, as you may have noticed, it always occupies the first available IP in the Cluster CIDR, a.k.a. --service-cluster-ip-range.
Second, this service is invincible, i.e. it will always get re-created, even when it’s manually removed:
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 118s
$ kubectl delete svc kubernetes
service "kubernetes" deleted
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 0s
You may notice that it comes up with the Continue reading
Last week I posted a tweet about a Kubernetes networking puzzle. In this post, we’ll go over the details of this puzzle and uncover the true cause and motive of the misbehaving ingress.
Imagine you have a Kubernetes cluster with three namespaces, each with its own namespace-scoped ingress controller. You’ve created an ingress in each namespace that exposes a simple web application. You’ve checked one of them, made sure it works and moved on to other things. However some time later, you get reports that the web app is unavailable. You go to check it again and indeed, the page is not responding, although nothing has changed in the cluster. In fact, you realise that the problem is intermittent - one minute you can access the page, and on the next refresh it’s gone. To make things worse, you realise that similar issues affect the other two ingresses.
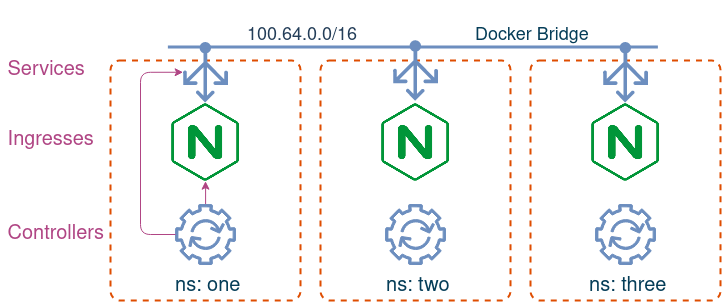
If you feel like you’re capable of solving it on your own, feel free to follow the steps in the walkthrough, otherwise, continue on reading. In either case, make sure you’ve setup a local test environment so that it’s easier to follow along:
Clone the ingress-puzzle repo:
git clone Continue readingCluster API (CAPI) is a relatively new project aimed at deploying Kubernetes clusters using a declarative API (think YAML). The official documentation (a.k.a. the Cluster API book), does a very good job explaining the main concepts and goals of the project. I always find that one of the best ways to explore new technology is to see how it works locally, on my laptop, and Cluster API has a special “Docker” infrastructure provider (CAPD) specifically for that. However, the official documentation for how to setup a docker managed cluster is very poor and fractured. In this post, I’ll try to demonstrate the complete journey to deploy a single CAPI-managed k8s cluster and provide some explanation of what happens behind the scene so that its easier to troubleshoot when things go wrong.
Two things must be pre-installed before we can start building our test clusters:
We’re gonna need run a few scripts from the Cluster API Github repo, so let’s get a copy Continue reading
In September 2019 I had the honour to present at Open Networking Summit in Antwerp. My talk was about meshnet CNI plugin, k8s-topo orchestrator and how to use them for large-scale network simulations in Kubernetes. During the same conference, I attended a talk about Network Service Mesh and its new kernel-based forwarding dataplane which had a lot of similarities with the work that I’ve done for meshnet. Having had a chat with the presenters, we’ve decided that it would be interesting to try and implement a meshnet-like functionality with NSM. In this post, I’ll try to document some of the findings and results of my research.
NSM is a CNCF project aimed at providing service mesh-like capabilities for L2/L3 traffic. In the context of Kubernetes, NSM’s role is to interconnect pods and setup the underlying forwarding, which involves creating new interfaces, allocating IPs and configuring pod’s routing table. The main use cases are cloud-native network functions (e.g. 5G), service function chaining and any containerised applications that may need to talk over non-standard protocols. Similar to traditional service meshes, the intended functionality is achieved by injecting sidecar containers that communicate with a distributed control plane of Continue reading
In the previous two posts, we’ve seen how to build a custom network API with Kubernetes CRDs and push the resulting configuration to network devices. In this post, we’ll apply the final touches by enabling oAuth2 authentication and enforcing separation between different tenants. All of these things are done while the API server processes incoming requests, so it would make sense to have a closer look at how it does that first.
Every incoming request has to go through several stages before it can get accepted and persisted by the API server. Some of these stages are mandatory (e.g. authentication), while some can be added through webhooks. The following diagram comes from another blogpost that covers each one of these stages in detail:

Specifically for NaaS platform, this is how we’ll use the above stages:
In the previous post, we’ve examined the foundation of the Network-as-a-Service platform. A couple of services were used to build the configuration from data models and templates and push it to network devices using Nornir and Napalm. In this post, we’ll focus on the user-facing part of the platform. I’ll show how to expose a part of the device data model via a custom API built on top of Kubernetes and how to tie it together with the rest of the platform components.
There are two main ways to interact with a Kubernetes API: one using a client library, which is how NaaS services communicate with K8s internally, the other way is with a command line tool called kubectl, which is intended to be used by humans. In either case, each API request is expected to contain at least the following fields:
Recently I’ve been pondering the idea of cloud-like method of consumption of traditional (physical) networks. My main premise for this was that users of a network don’t have to wait hours or days for their services to be provisioned when all that’s required is a simple change of an access port. Let me reinforce it by an example. In a typical data center network, the configuration of the core (fabric) is fairly static, while the config at the edge can change constantly as servers get added, moved or reconfigured. Things get even worse when using infrastructure-as-code with CI/CD pipelines to generate and test the configuration since it’s hard to expose only a subset of it all to the end users and it certainly wouldn’t make sense to trigger a pipeline every time a vlan is changed on an edge port.
This is where Network-as-a-Service (NaaS) platform fits in. The idea is that it would expose the required subset of configuration to the end user and will take care of applying it to the devices in a fast and safe way. In this series of blogposts I will describe and demonstrate a prototype of such a platform, implemented on top of Continue reading
Every time when I get bored from my day job I tend to find some small interesting project that I can do that can give me an instant sense of accomplishment and as the result lift my spirits and improve motivation. So this time I remembered when someone once asked me if they could use Terraform to control their physical network devices and I had to explain how this is the wrong tool for the job. Somehow the question got stuck in my head and now it came to fruition in the form of terraform-yang.
This is a small Terraform plugin (provider) that allows users to manipulate interface-level settings of a network device. And I’m not talking about a VM in the cloud that runs network OS of your favourite vendor, this stuff is trivial and doesn’t require anything special from Terraform. I’m talking about Terraform controlling your individual physical network devices over an OpenConfig’s gNMI interface with standard Create/Read/Update/Delete operations exposed all the way to Terraform’s playbooks (or whatever they are called). Network Infrastructure as code nirvana…

Although this may look scary at the beginning, the process of creating your Continue reading
In the previous post I’ve demonstrated how to build virtual network topologies on top of Kubernetes with the help of meshnet-cni plugin. As an example, I’ve shown topologies with 50 cEOS instances and 250 Quagga nodes. In both of these examples virtual network devices were running natively inside Docker containers, meaning they were running as (a set of) processes directly attached to the TCP/IP stack of the network namespace provided by the k8s pod. This works well for the native docker images, however, the overwhelming majority of virtual network devices are still being released as VMs. In addition to that, some of them require more than one VM and some special bootstrapping before they can they can be used for the first time. This means that in order to perform true multi-vendor network simulations, we need to find a way to run VMs inside containers, which, despite the seeming absurdity, is quite a common thing to do.
Kubevirt is a very popular project that provides the ability to run VMs inside k8s. It uses the power of Custom Resource Definitions to extend the native k8s API to allow the definition of VM parameters (libvirt domainxml) same Continue reading
In the previous post I’ve demonstrated a special-purpose CNI plugin for network simulations inside kubernetes called meshnet. I’ve shown how relatively easy it is to build a simple 3-node topology spread across multiple kubernetes nodes. However, when it comes to real-life large-scale topology simulations, using meshnet “as is” becomes problematic due to the following reasons:
That is why I built k8s-topo - an orchestrator for network simulations inside kubernetes. It automates a lot of these manual steps and provides a simple and user-friendly interface to create networks of any size and configuration.
k8s-topo is a Python script that creates network topologies inside k8s based on a simple YAML file. It uses syntax similar to docker-topo with a few modifications to account for the specifics of kubernetes environment. For instance, the following file is all what’s required to create and configure a simple 3-node topology:
etcd_port: 32379
links:
- endpoints: ["host-1:eth1:12.12.12.1/24", "host-2:eth1:12.12.12.2/24"]
- endpoints: ["host-1:eth2:13.13.13.1/24", "host-3:eth1:13.13.13.3/24"]
- endpoints: ["host-2:eth2:23.23. Continue readingBuilding virtualised network topologies has been one of the best ways to learn new technologies and to test new designs before implementing them on a production network. There are plenty of tools that can help build arbitrary network topologies, some with an interactive GUI (e.g. GNS3 or EVE-NG/Unetlab) and some “headless”, with text-based configuration files (e.g. vrnetlab or topology-converter). All of these tools work by spinning up multiple instances of virtual devices and interconnecting them according to a user-defined topology.
Most of these tools were primarily designed to work on a single host. This may work well for a relatively small topology but may become a problem as the number of virtual devices grows. Let’s take Juniper vMX as an example. From the official hardware requirements page, the smallest vMX instance will require:
This does not include the resources consumed by the underlying hypervisor, which can easily eat up another vCPU + 2GB of RAM. It’s easy to imagine how quickly Continue reading