Author Archives: Dmitriy Kalugin-Balashov
Author Archives: Dmitriy Kalugin-Balashov
In this article, I want to share with you how I solved a very interesting problem of synchronizing data between IoT devices and a cloud application.
I’ll start by outlining the general idea and the goals of my project. Then I’ll describe my implementation in greater detail. This is going to be a more technically advanced part, where I’ll be talking about the Contiki OS, databases, protocols and the like. In the end, I’ll summarize the technologies I used to implement the whole system.
So, let’s talk about the general idea first.
Here’s a scheme illustrating the final state of the whole system:

I have a user who can connect to IoT devices via a cloud service or directly (that is over Wi-Fi).
Also, I have an application server somewhere in the cloud and the cloud itself somewhere on the Internet. This cloud can be anything — for example, an AWS or Azure instance or it could be a dedicated server, it could be anything :)
The application server is connected to IoT devices over some protocol. I need this connection to exchange data between the application server and the IoT devices.
The IoT devices are connected to each other in Continue reading
As the Russian rouble exchange rate slumped two years ago, it drove us to think of cutting hardware and hosting costs for the Mail.Ru email service. To find ways of saving money, let’s first take a look at what emails consist of.
Indexes and bodies account for only 15% of the storage size, whereas 85% is taken up by files. So, files (that is attachments) are worth exploring in more detail in terms of optimization. At that time, we didn’t have file deduplication in place, but we estimated that it could shrink the total storage size by 36% since many users receive the same messages, such as price lists from online stores or newsletters from social networks containing images and so on. In this article, I’m going to describe how we implemented a deduplication system under the supervision of Albert Galimov.
Hey guys!
In this article, I’d like to tell you a story of implementing the anti-spam system for Mail.Ru Group’s email service and share our experience of using the Tarantool database within this project: what tasks Tarantool serves, what limitations and integration issues we faced, what pitfalls we fell into and how we finally arrived to a revelation.
Let me start with a short backtrace. We started introducing anti-spam for the email service roughly ten years ago. Our first filtering solution was Kaspersky Anti-Spam together with RBL (Real-time blackhole list — a realtime list of IP addresses that have something to do with spam mailouts). This allowed us to decrease the flow of spam messages, but due to the system’s inertia, we couldn’t suppress spam mailouts quickly enough (i.e. in the real time). The other requirement that wasn’t met was speed: users should have received verified email messages with a minimal delay, but the integrated solution was not fast enough to catch up with the spammers. Spam senders are very fast at changing their behavior model and the outlook of their spam content when they find out that spam messages are not delivered. So, we couldn’t put up Continue reading

In this article, I’m going to pay specific attention to information processing via Tarantool queues. My colleagues have recently published several articles in Russian on the benefits of queues (Queue processing infrastructure on My World social network and Push messages in REST API by the example of Target Mail.Ru system). Today I’d like to add some info on queues describing the way we solved our tasks and telling more about our work with Tarantool Queue in Python and asyncio.
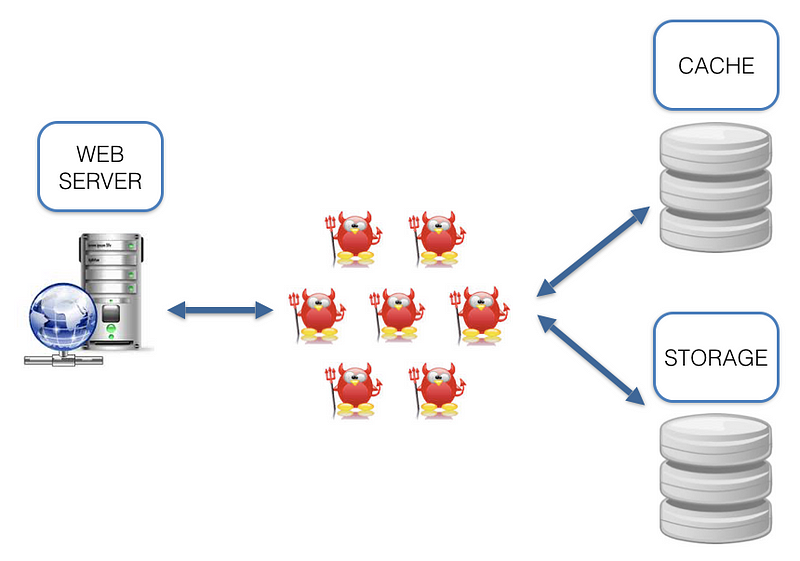
Are you familiar with this architecture? A bunch of daemons are dancing between a web-server, cache and storage.
What are the cons of such architecture? While working with it we come across a number of questions: which language (-s) should we use? Which I/O framework to choose? How to synchronize cache and storage? Lots of infrastructure issues. And why should we solve the infrastructure issues when we need to solve a task? Sure, we can say that we like some X and Y technologies and treat these cons as ideological. But we can’t ignore the fact that the data is located some distance away from the code (see the picture above), which adds latency that could decrease RPS.
The main idea of this article is to describe an alternative, built on nginx as a web-server, load balancer and Tarantool as app server, cache, storage.
The main purpose of this work is to show results of benchmarking some of the leading in-memory NoSQL databases with a tool named YCSB.
We selected three popular in-memory database management systems: Redis (standalone and in-cloud named Azure Redis Cache), Tarantool and CouchBase and one cache system Memcached. Memcached is not a database management system and does not have persistence. But we decided to take it, because it is also widely used as a fast storage system. Our “firing field” was a group of four virtual machines in Microsoft Azure Cloud. Virtual machines are located close to each other, meaning they are in one datacenter. This is necessary to reduce the impact of network overhead in latency measurements. Images of these VMs can be downloaded by links: one, two, three and four (login: nosql, password: qwerty). A pair of VMs named nosql-1 and nosql-2 is useful for benchmarking Tarantool and CouchBase and another pair of VMs named nosql-3 and nosql-4 is good for Redis, Azure Redis Cache and Memcached. Databases and tests are installed and configured on these images.
Our virtual machines were the basic A3 instances with 4 cores, 7 GB RAM and 120 GB disk Continue reading