Author Archives: Ivan Pepelnjak
Author Archives: Ivan Pepelnjak
Shipping netlab release 1.9.0 included running 36 hours of integration tests, including fifteen VXLAN/EVPN tests covering:
All tests included one or two devices under test and one or more FRR containers1 running EVPN/VXLAN with the devices under test. The results were phenomenal; apart from a few exceptions, everything Just Worked™️.
I love bashing SRv6, so it’s only fair to post a (technical) counterview, this time coming as a comment from Henk Smit.
There are several benefits of SRv6 that I’ve heard of.
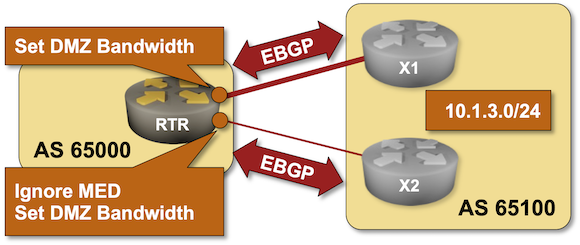
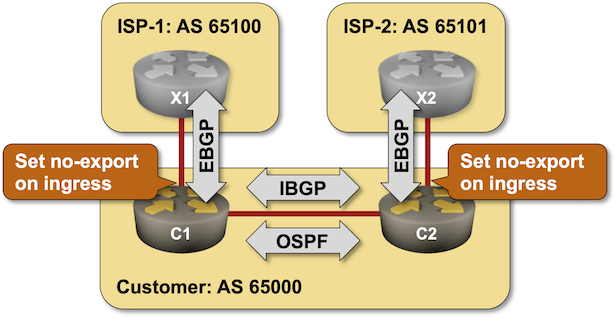
The very first BGP Communities RFC included an interesting idea: let’s tag paths we don’t want to propagate to other autonomous systems. For example, the prefixes received from one upstream ISP should not be propagated to another upstream ISP (sadly, things don’t work that way in reality).
Want to try out that concept? Start the Using No-Export Community to Filter Transit Routes lab in GitHub Codespaces.
After reading the Layer-3-Only EVPN: Behind the Scenes blog post, one might come to an obvious conclusion: the per-VRF EVPN transit VNI must match across all PE devices forwarding traffic for that VRF.
Interestingly, at least some EVPN implementations handle multiple VNIs per VRF without a hitch; I ran my tests in a lab where three switches used unique per-switch VNI for a common VRF.
Ever since Pawel Foremski talked about BGP Pipe @ RIPE88 meeting, I wanted to kick its tires in netlab. BGP Pipe is a Go executable that runs under Linux (but also FreeBSD or MacOS), so I could add a Linux VM (or container) to a netlab topology and install the software after the lab has been started. However, I wanted to have the BGP neighbor configured on the other side of the link (on the device talking with the BGP Pipe daemon).
I could solve the problem in a few ways:
netlab release 1.9.0 brings tons of new routing features:
Other new goodies include:
As I was doing the final integration tests for netlab release 1.9.0, I stumbled upon a fascinating BGP configuration quirk: where do you configure the allowas-in parameter and why?
BGP runs over TCP, and all parameters related to the TCP session are configured for a BGP neighbor (IPv4 or IPv6 address). That includes the source interface, local AS number (it’s advertised in the per-session OPEN message that negotiates the address families), MD5 password (it uses MD5 checksum of TCP packets), GTSM (it uses the IP TTL field), or EBGP multihop (it increases the IP TTL field).
Urs Baumann brought me a nice surprise last weekend. He opened a GitHub issue saying, “MPLS works on Arista cEOS containers in release 4.31.2F” and asking whether we could enable netlab to configure MPLS on cEOS containers.
After a few configuration tweaks and a batch of integration tests later, I had the results: everything worked. You can use MPLS on Arista cEOS with netlab release 1.9.0 (right now @ 1.9.0-dev2), and I’ll be able to create MPLS labs running in GitHub Codespaces in the not-too-distant future.
In the previous blog post, I described how to build a lab to explore the layer-3-only EVPN design and asked you to do that and figure out what’s going on behind the scenes. If you didn’t find time for that, let’s do it together in this blog post. To keep it reasonably short, we’ll focus on the EVPN control plane and leave the exploration of the data-plane data structures for another blog post.
The most important thing to understand when analyzing a layer-3-only EVPN/VXLAN network is that the data plane looks like a VRF-lite design: each VRF uses a hidden VLAN (implemented with VXLAN) as the transport VLAN between the PE devices.
Wes made an interesting comment to the Migrating a Data Center Fabric to VXLAN blog post:
The benefit of VXLAN is mostly scalability, so if your enterprise network is not scaling… just don’t. The migration path from VLANs is to just keep using VLANs. The (vendor-driven) networking industry has a huge blind spot about this.
Paraphrasing the famous Dinesh Dutt’s Autocon1 remark: I couldn’t disagree with you more.
A few weeks ago, Roman Dodin mentioned layer-3-only EVPNs: a layer-3 VPN design with no stretched VLANs in which EVPN is used to transport VRF IP prefixes.
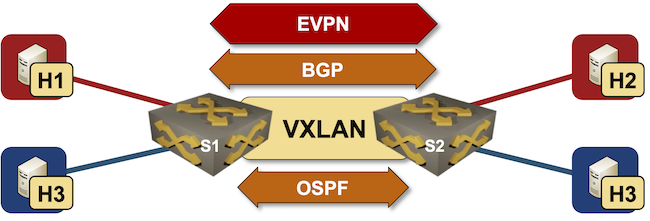
The reality is a bit muddier (in the VXLAN world) as we still need transit VLANs and router MAC addresses; the best way to explore what’s going on behind the scenes is to build a simple lab.
Darko Petrovic made an excellent remark on one of my LinkedIn posts:
The majority of the networks running now in the Enterprise are on traditional VLANs, and the migration paths are limited. Really limited. How will a business transition from traditional to whatever is next?
The only sane choice I found so far in the data center environment (and I know it has been embraced by many organizations facing that conundrum) is to build a parallel fabric (preferably when the organization is doing a server refresh) and connect the new fabric with the old one with a layer-3 link (in the ideal world) or an MLAG link bundle.
Vincent Bernat documented a quirk I hope you’ll never see outside of a CCIE lab: combining BGP confederations with AS-override can generate endless AS paths.
I agree entirely with his conclusions (avoid both features). However, I still think that replacing an AS within the confederation part of an AS path (which should belong to a single well-managed AS) is not exactly the most brilliant idea I’ve seen.
I never mastered the fine art of polite diplomatic sarcasm. Brad Casemore is a virtuoso – you’ll love his take on Google’s Quarterly Results: Investors Begin Questioning Efficacy of GenAI Investments.
Did you know you can use netlab to generate reports describing your lab topology, IP addressing, BGP details, or OSPF areas? The magic command (netlab report) was introduced in August 2023, followed by netlab show reports to display the available reports a few months later.
You can generate the reports in text, Markdown, or HTML format. The desired format is selected with the report name suffix. For example, the bgp-asn.md report will create Markdown text.
Let’s see how that works.
Daniel Dib asked an interesting question on LinkedIn when considering an RT5-only EVPN design:
I’m curious what EVPN provides if all you need is L3. For example, you could run pure L3 BGP fabric if you don’t need VRFs or a limited amount of them. If many VRFs are needed, there is MPLS/VPN, SR-MPLS, and SRv6.
I received a similar question numerous times in my previous life as a consultant. It’s usually caused by vendor marketing polluting PowerPoint slide decks with acronyms without explaining the fundamentals1. Let’s fix that.
Dmytro Shypovalov wrote a fantastic article explaining the basics of MPLS-based Segment Routing. It’s pretty much equivalent to everything I ever wrote about SR-MPLS but in a much nicer package. Definitely a must-read.
Ben asked an interesting question:
Do you think, realistically in 2024, netlab would suffice to prepare the CCIE lab exam? Particulary for the SP flavor, since netlab supports a lot of routing protocols. Thanks!
TL&DR: No.
netlab would be a great tool to streamline your CCIE preparation studies. You could:
Here’s another AI rant to spice your summer: AI Is Still a Delusion, including an excellent example of how the latest LLMs flunk simple logical reasoning. I particularly liked this one-line summary:
The real danger today is not that computers are smarter than us but that we think computers are smarter than us and consequently trust them to make decisions they should not be trusted to make.
It might be worth remembering that quote when an AI-powered management appliance messes up your network because of a false positive ;)
The first BGP load balancing lab exercise described the basics of EBGP equal-cost load balancing. Now for the fun part: what if you want to spread traffic across multiple links in an unequal ratio? There’s a nerd knob for that: the BGP Link Bandwidth extended community that you can test-drive in this lab exercise.