Worth Reading: Scripting Good Practices in Python
Just in case you decide to build a simple Python project over the summer: read scripting good practices in Python by Brett Cannon and tell your AI friend to adhere to them ;)
Worth Reading: More VXLAN and EVPN Labs
Ali Bahadır Coşkun continued his EVPN/VXLAN journey. Using the free netlab-powered EVPN/VXLAN labs, he finished the basic EVPN/VXLAN lab (adding EVPN control plane to VXLAN underlay), and then completed the whole VXLAN/IRB/anycast saga.
Want to do something similar? The free EVPN/VXLAN lab exercises include six VXLAN labs, almost a dozen EVPN labs, and a few EVPN designs. I might add a lab or two during the summer break.
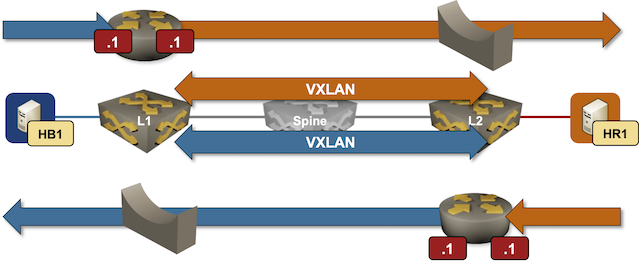
Worth Checking: EVPN Centralized Anycast Gateway
Daniel Blažek couldn’t resist testing Arista EOS centralized anycast gateway functionality (on top of IPv6 underlay to make it even more fun) and published working device configurations in a GitHub repo.
His repository includes a containerlab topology definition, so you can start the lab directly from the repository.
Getting Started with netlab @ Cisco DevNet
Cisco DevNet channel has published an hour-long Getting Started with netlab interview with Suresh Vina, resulting in netlab.tools documentation having more weekly visits than ipspace.net blog for the first time. Thanks a million ;))
If you’re new to netlab, I hope you’ll enjoy the video. If you have any follow-up questions, don’t hesitate to start a discussion.
Time for Another Summer Break?
I can confirm that an old saying is true: the older you are, the faster years pass. Can’t believe it’s time for another summer break. I hope you’ll manage to get away from work, turn off the Internet, and enjoy a few days in your favorite spot with your loved ones!
I also promise I won’t be annoying you with boring stuff like EVPN next hops or pointers to AI myth-busters (I have to admit it: I was cleaning my Inbox this week). However, I probably won’t be able to resist publishing a few lightweight netlab-related blog posts, or links to interesting content.
Worth Reading: Appearing Productive in The Workplace
The Appearing Productive in The Workplace article I stumbled upon is yet another masterful description of how AI slop, used by Expert Beginners, wastes everyone’s time and energy. Try to have fun reading it, even though it may be way too close to the mark.
Anycast-Only Gateways in EVPN Asymmetric IRB
In the previous blog post, I described how ARP works in an EVPN asymmetric IRB environment where the PE devices share an anycast MAC/IP address in addition to a unicast MAC/IP address. Today, let’s see how well things work if the PE devices have only the anycast MAC/IP address:
Packet forwarding in an EVPN asymmetric IRB design using only anycast gateways
Worth Reading: My Network is Talking Back Thanks to SuzieQ MCP
Claudia de Luna published a step-by-step description of how you can use SuzieQ data with an AI agent.
That’s definitely interesting, but I found the list of MCP resources at the end of her blog post even more valuable; that’s a keeper even if you never looked at SuzieQ (in which case you REALLY SHOULD).
Worth Reading: AI Enthusiasts Against AI Skeptics
Charity Majors wrote an excellent article describing AI enthusiasts in a race against time and AI skeptics in a race against entropy. Fair warning: its very first sentence triggered an acute case of PTSD:
I recently attended a talk where one of the presenters made some pretty…astonishing claims about what they had achieved by the pure, uncut power of vibe coding.
I’ve seen way too many presentations making “astonishing claims” about the unlimited unicorn-driven powers of OpenFlow, SDN, OpenDaylight, or Ansible.
Worth Reading: Extending a VLAN with Static VXLAN
Ali Bahadır Coşkun wrote a nice article describing how he mastered extending a VLAN with static VXLAN with the help of free netlab-powered VXLAN labs.
The same set of lab exercises includes six VXLAN labs, almost a dozen EVPN labs, and a few EVPN designs. I might add a lab or two during the summer break.
ARP with Anycast Gateways in EVPN Asymmetric IRB
In previous blog posts, I described the ARP issues in EVPN environments, starting with centralized routing, and then asymmetric IRB with unicast (per-leaf-switch) first-hop gateways. Of course, no self-respecting vendor would tell you to do that; anycast gateways are all the rage these days.
As always, anycast gateways could mean different things, depending on which vendor documentation you read ;)
- Active-active VRRP (one device is the active VRRP gateway, but all devices listen to the VRRP MAC address).
- Shared MAC+IP address beside device-specific unicast MAC and IP addresses.
- Shared MAC+IP address with no PE-specific IP address.
Worth Reading: Leading Intelligent Networks
Chris Grundemann wrote an interesting article arguing that you should structure your network operations around teams, not heroes.
Even if you feel you’re perfectly OK with your network being held together by exhausted heroes (and duct tape), it could be a bit harder to deploy network automation in an always-busy hero culture. However, the choice, as they say, is yours.
SR-MPLS with OSPFv2
I started my part of the Segment Routing workshop @ ITNOG10 exploring SR-MPLS with IS-IS (simple SR-MPLS, dual-stack SR-MPLS, SR-MPLS over unnumbered IPv4 interfaces). Next step: let’s change the routing protocol to OSPF while using the same network topology:

AI in Networking with Andrew Yourtchenko
I always wanted to find someone who is more positive about AI than I am, while having solid “can deliver working stuff at scale” credentials. Andrew Yourtchenko definitely fits the bill. I first met him (online) when he was still an engineer in Cisco TAC, and when we finally met in person, he was busy automating the deployment of Cisco Live networking infrastructure. He was also instrumental in bringing us closer to ubiquitous IPv6 deployment with Happy Eyeballs.
Using netlab to Configure Live Devices
Leo Fleskes sent me an interesting question after reading my Generate Partial Device Configurations with netlab blog post:
What is stopping us from eventually, given enough usage and coverage, using netlab to configure devices in the live network?
In theory, nothing. In practice, you might hit a few hurdles:
Goodbye, Leaf-and-Spine Networks?
A friend of mine sent me links to a new paper published by AWS engineers, and an associated LinkedIn post which claims:
We got lean, resilient, massive aggregation fabrics that provide 33% better throughput with 69% fewer routers, savings 27% of costs, cutting power usage by 40%, and reducing CO2 emissions.
The obvious question one should ask after reading the hyperventilated Radical Network Redesign blog post is thus: is this the end of leaf-and-spine networks? Of course not. Let’s go into the details.
Worth Reading: Genie Tarpit
Following a link in Martin Fowler’s Fragments, I stumbled upon Genie Tarpit by Kent Beck – a perfect summary of my experiences with AI coding (code reviews are OK, new code less so). He also provided a good reason for that behavior:
The “plausible deniability” task orientation of the genie leaves it claiming success even though the code doesn’t work at all.
And the proposed solution?
You probably saw this one coming—nobody knows.
netlab 26.06: OSPFv3 on FortiOS, MPLS/VPN on SR Linux
netlab release 26.06 adds OSPFv3 support on FortiOS (by @a-v-popov) and MPLS/VPN support on SR Linux. We also ensured the installation scripts work on Ubuntu 26.04 (everything else was OK) and updated the installed Vagrant version to 2.4.9 (we’re not using new Vagrant features; you don’t have to upgrade it in an existing installation).
Other than that, we added a few improvements and squashed a number of bugs.
Upgrading or Starting from Scratch?
- To upgrade your netlab installation, execute
pip3 install --upgrade networklab. - New to netlab? Start with the Getting Started document and the installation guide.
- Need help? Open a discussion or an issue in netlab GitHub repository.
Lab: Implementing VRF-Lite with VXLAN
Did you know that you can implement a VRF-Lite design with VXLAN? All you need are devices that can run VRF routing protocols over VXLAN-backed VLAN segments.
Compared to the “traditional” VRF-Lite design, in which you need a set of VLANs on every link and every device running the routing protocol for every VRF, the VXLAN-based design needs just IP routing on the core switches, resulting in a design that’s pretty close to what we were building with DMVPN (without IPsec and NHRP complications).
Using netlab to Argue with Vendor TAC
A happy netlab user sent me an unexpected use case: they successfully used its multi-vendor capabilities to argue with a vendor TAC. Here’s the gist of the story (edited/anonymized for obvious reasons):
They deployed a configuration change that resulted in an unexpected outage. The outage partially disrupted the data center network, so they didn’t have the luxury of collecting data and reproducing the issue, as they had to roll back the change as expeditiously as possible.