Author Archives: Ivan Pepelnjak
Author Archives: Ivan Pepelnjak
In the multi-pod EVPN design, I described a simple way to merge two EVPN fabrics into a single end-to-end fabric. Here are a few highlights of that design:
In that design, the WAN edge routers have to support EVPN (at least in the control plane) and carry all EVPN routes for both fabrics. Today, we’ll change the design to use simpler WAN edge routers that support only IP forwarding.
Daniel Dib asked a sad question on LinkedIn:
Where did all the great documentation go?
In more detail:
There was a time when documentation answered almost all questions:
- What is the thing?
- What does the thing do?
- Why would you use the thing?
- How do you configure the thing?
I’ve seen the same thing happening in training, and here’s my cynical TL&DR answer: because the managers of the documentation/training departments don’t understand the true value of what they’re producing and thus cannot justify a decent budget to make it happen.
A few days ago, I described how you can use the new config.inline functionality to apply additional configuration commands to individual devices in a netlab-powered lab.
However, sometimes you have to apply the same set of commands to several devices. Although you could use device groups to do that, netlab release 25.09 offers a much better mechanism: you can embed custom configuration templates in the lab topology file.
netlab release 25.10 includes:
You’ll find more details in the release notes.
An engineer reading my multi-pod EVPN article asked an interesting question:
How do you handle troubleshooting when VTEPs cannot reach each other across pods?
The ancient Romans already knew the rough answer: divide and conquer.
In this particular case, the “divide” part starts with a simple realization: VXLAN/EVPN is just another application running on top of IP.
TL&DR: You shouldn’t see any immediate impact of this change, but I’ll eventually clean up old stuff, so you might want to check the URLs if you use RSS/Atom feeds to get the list of ipSpace.net blog posts or podcast episodes. The (hopefully) final URLs are listed on this page.
Executive Summary: I cleaned up the whole ipSpace.net RSS/Atom feeds system. The script that generated the content for various feeds has been replaced with static Hugo-generated RSS/Atom feeds. I added redirects for all the old stuff I could find (including ioshints.blogspot.com), but I could have missed something. The only defunct feed is the free content feed (which hasn’t changed in a while, anyway), as it required scanning the documents database. You can use this page to find the (ever-increasing) free content.
And now for the real story ;)
When I first met David Gee, he worked for a large system integrator. A few years later, he moved to a networking vendor, worked for a few of them, then for a software vendor, and finally decided to start his own system integration business.
Obviously, I wanted to know what drove him to make those changes, what lessons he learned working in various parts of the networking industry, and what (looking back with perfect hindsight) he would have changed.
Here’s an interesting data point in case you ever wondered why things are getting slower, even though the CPU performance is supposedly increasing. Albert Siersema sent me a link to a confusing implementation of spaghetti networking.
It looks like they’re trying to solve the how do I connect two containers (network namespaces) without having the privilege to create a vEth pair challenge with plenty of chewing gum and duct tape tap interfaces 🤦♂️
In this challenge lab, you’ll configure a BIRD daemon running in a container as a BGP route reflector in a transit autonomous system. You should be familiar with the configuration concepts if you completed the IBGP lab exercises, but will probably struggle with BIRD configuration if you’re not familiar with it.

Click here to start the lab in your browser using GitHub Codespaces (or set up your own lab infrastructure). After starting the lab environment, change the directory to challenge/01-bird-rr, build the BIRD container with netlab clab build bird if needed, and execute netlab up.
For years, netlab has had custom configuration templates that can be used to deploy custom configurations onto lab devices. The custom configuration templates can be Jinja2 templates, and you can create different templates (for the same functionality) for different platforms. However, using that functionality if you need an extra command or two makes approximately as much sense as using a Kubernetes cluster to deploy a BusyBox container.
netlab release 25.09 solves that problem with the files plugin and the inline config functionality.
In the EVPN Designs: Layer-3 Inter-AS Option A, I described the simplest multi-site design in which the WAN edge routers exchange IP routes in individual VRFs, resulting in two isolated layer-2 fabrics connected with a layer-3 link.
Today, let’s explore a design that will excite the True Believers in end-to-end layer-2 networks: two EVPN fabrics connected with an EBGP session to form a unified, larger EVPN fabric. We’ll use the same “physical” topology as the previous example; the only modification is that the WA-WB link is now part of the underlay IP network.
After I published the updated netlab topology graphs article, Samuel K. Lam quickly made a comment along the lines of now we know how the graph representing the following topology was made, adding a nice ASCII art that illustrated the point I was trying to make much better than my graphs:

ASCII art representing the BGP leak lab
Let’s see how close we can get to that ideal topology diagram with GraphViz and D2 graphs.
I’m too old to be fighting with windmills, but sometimes I have to get a rant off my chest. This one was triggered by the latest episode of the hilarious1 “DHCPv6 on Android” soap opera
In a 720-degree turnaround, Android 11 supports DHCPv6, but only for prefix delegation purposes. Yes, you got it right, in a year or two, every phone might want to have a dedicated /64 prefix assigned to it on WiFi segments2.
Want more details? Well, there’s a high-level overview published on the Android Developers blog and a corresponding message sent to the v6ops mailing list. Let’s see how much sense that makes.
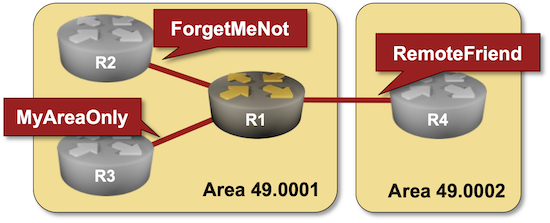
Like OSPF and BGP, IS-IS contains a simple mechanism to authenticate routing traffic – IS-IS packets can include a cleartext password or an MD5- or SHA hash. Unlike OSPF, IS-IS can also authenticate:
Want to know more? Check out the Protect IS-IS Routing Data with MD5 Authentication lab exercise.
Click here to start the lab in your browser using GitHub Codespaces (or set up your own lab infrastructure). After starting the lab environment, change the directory to feature/3-md5 and execute netlab up.

I made most of the Ansible for Networking Engineers webinar public; you can watch those videos without an ipSpace.net account.
Want to spend more time watching free ipSpace.net videos? The complete list is here.
Someone approached me after my NOG.HR netlab presentation and said: “wouldn’t it be great if we could just start the lab from an example topology published on GitHub?”
It took me almost a year to get it done, but the functionality finally made it into the 25.09 release:
Is it possible to deploy Precision Time Protocol across a country-wide WAN network and reach nanosecond-level synchronization between cities? It’s definitely not trivial and only works over dedicated infrastructure; for more details, watch the PTP in WANs (video) presentation Oliver Ettlin had at SwiNOG 40.
Last week, I explained how to generate network topology graphs (using GraphViz or D2 graphing engines) from a netlab lab topology. Let’s see how we can make them look nicer (or at least more informative). We’ll work with a simple leaf-and-spine topology with four nodes1:
defaults.device: frr
provider: clab
nodes: [ s1, s2, l1, l2 ]
links: [ s1-l1, s1-l2, s2-l1, s2-l2 ]
This is the graph generated by netlab create followed by dot graph.dot -T png -o graph.png:
When I was writing a blog post, I needed a link to the netlab lab topology documentation, so I searched for “netlab lab topology” (I know I’m lazy, but it felt quicker than navigating the sidebar menu).
The AI overview I got was way too verbose, but it nailed the Key Concepts and How It Works well enough that I could just use them in the netlab README.md file. Maybe this AI thing is becoming useful after all ;)
I wrote about the optimal BGP path selection with BGP additional paths in 2021, and I probably mentioned (in one of the 360 BGP-related blog posts) that you need it to implement IBGP load balancing in networks using BGP route reflectors. If you want to try that out, check out the IBGP Load Balancing with BGP Additional Paths lab exercise.

Click here to start the lab in your browser using GitHub Codespaces (or set up your own lab infrastructure). After starting the lab environment, change the directory to lb/4-ibgp-add-path and execute netlab up.