Author Archives: Ivan Pepelnjak
Author Archives: Ivan Pepelnjak
One of my readers asked for my opinion about this question…
… and I promised something longer than 280 characters.
Jeff Tantsura left me tantalizing hint after reading the BGP Labeled Unicast on Cisco IOS blog post:
Read carefully “Relationship between SAFI-4 and SAFI-1 Routes” section in RFC 8277
The start of that section doesn’t look promising (and it gets worse):
It is possible that a BGP speaker will receive both a SAFI-11 route for prefix P and a SAFI-42 route for prefix P. Different implementations treat this situation in different ways.
Now for the details:
Jeff Tantsura left me tantalizing hint after reading the BGP Labeled Unicast on Cisco IOS blog post:
Read carefully “Relationship between SAFI-4 and SAFI-1 Routes” section in RFC 8277
The start of that section doesn’t look promising (and it gets worse):
It is possible that a BGP speaker will receive both a SAFI-11 route for prefix P and a SAFI-42 route for prefix P. Different implementations treat this situation in different ways.
Now for the details:
netsim-tools release 1.2.0 adds full-blown MPLS and MPLS/VPN support:
It’s never been easier to build full-blown MPLS/VPN labs ;)… if you’re OK with using Cisco IOS or Arista EOS. Please feel free to submit a PR to add support for other platforms.
You might want to start with the VRF tutorial to see how simple it is to define VRFs, and follow the installation guide to set up your lab – if you’re semi-fluent in Linux (and don’t care about data plane quirks), the easiest option would be to run Arista cEOS.
netlab release 1.2.0 adds full-blown MPLS and MPLS/VPN support:
It’s never been easier to build full-blown MPLS/VPN labs ;)… if you’re OK with using Cisco IOS or Arista EOS. Please feel free to submit a PR to add support for other platforms.
You might want to start with the VRF tutorial to see how simple it is to define VRFs, and follow the installation guide to set up your lab – if you’re semi-fluent in Linux, the easiest option would be to run Arista cEOS.
Every now and then someone tells me how much better the global Internet would be if only we were using recursive layers (RINA) and hierarchical addresses. I always answer “that’s a business problem, not a technical one, and you cannot solve business problems by throwing technology at them”, but of course that has never persuaded anyone who hasn’t been running a large-enough business for long enough.
Geoff Huston is doing a much better job in the March 2022 ISP Column – read the Higher Levels of Address Aggregation, and if you still need more technical details, there’s 30+ pages of RFC 4984.
Every now and then someone tells me how much better the global Internet would be if only we were using recursive layers (RINA) and hierarchical addresses. I always answer “that’s a business problem, not a technical one, and you cannot solve business problems by throwing technology at them”, but of course that has never persuaded anyone who hasn’t been running a large-enough business for long enough.
Geoff Huston is doing a much better job in the March 2022 ISP Column – read the Higher Levels of Address Aggregation, and if you still need more technical details, there’s 30+ pages of RFC 4984.
You MUST read the next masterpiece coming from Ethan Banks: Career Advice I’d Give To 20, 30 and 40-Something Year Old Me. I found this bit particularly relevant:
Your life is at least half over. Stop wasting time doing things other people think is important.
If only Ethan would have told me that wisdom ten years ago.
You MUST read the next masterpiece coming from Ethan Banks: Career Advice I’d Give To 20, 30 and 40-Something Year Old Me. I found this bit particularly relevant:
Your life is at least half over. Stop wasting time doing things other people think are important.
If only Ethan would have told me that wisdom ten years ago.
The previous videos in the How Networks Really Work webinar described some interesting details of data-link layer addresses and network layer addresses. Now for the final bit: how do we map an adjacent network address into a per-interface data link layer address?
If you answered ARP (or ND if you happen to be of IPv6 persuasion) you’re absolutely right… but is that the only way? Watch the Combining Data-Link- and Network Addresses video to find out.
The previous videos in the How Networks Really Work webinar described some interesting details of data-link layer addresses and network layer addresses. Now for the final bit: how do we map an adjacent network address into a per-interface data link layer address?
If you answered ARP (or ND if you happen to be of IPv6 persuasion) you’re absolutely right… but is that the only way? Watch the Combining Data-Link- and Network Addresses video to find out.
Henk Smit made the following claim in one of his comments:
I think BGP-MPLS-VPNs are over-complicated. And you don’t get enough return for that extra complexity.
TL&DR: He’s right (and I just violated Betteridge’s law of headlines)
The history of how we got to the current morass might be interesting for engineers who want to look behind the curtain, so here we go…
Henk Smit made the following claim in one of his comments:
I think BGP-MPLS-VPNs are over-complicated. And you don’t get enough return for that extra complexity.
TL&DR: He’s right (and I just violated Betteridge’s law of headlines)
The history of how we got to the current morass might be interesting for engineers who want to look behind the curtain, so here we go…
A reader sent me the following intriguing question:
I’m trying to understand the ARP behavior with SVI interface configured with anycast gateways of leaf switches, and with distributed anycast gateways configured across the leaf nodes in VXLAN scenario.
Without going into too many details, the core dilemma is: will the ARP request get flooded, and will we get multiple ARP replies. As always, the correct answer is “it depends” 🤷♂️
A reader sent me the following intriguing question:
I’m trying to understand the ARP behavior with SVI interface configured with anycast gateways of leaf switches, and with distributed anycast gateways configured across the leaf nodes in VXLAN scenario.
Without going into too many details, the core dilemma is: will the ARP request get flooded, and will we get multiple ARP replies. As always, the correct answer is “it depends” 🤷♂️
A week ago I described how Cisco IOS implemented BGP Labeled Unicast. In this blog post we’ll focus on Arista EOS using the same lab as before:
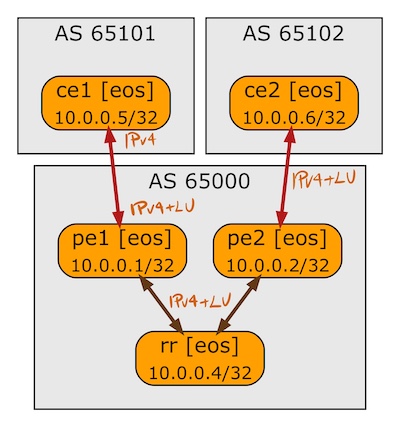
BGP sessions in the BGP-LU lab
A week ago I described how Cisco IOS implemented BGP Labeled Unicast. In this blog post we’ll focus on Arista EOS using the same lab as before:
BGP sessions in the BGP-LU lab
Syed Khalid Ali left the following question on an old blog post describing the use of IBGP and EBGP in an enterprise network:
From an enterprise customer perspective, should I run iBGP or iBGP+IGP (OSPF/ISIS/EIGRP) or IGP while doing mutual redistribution on the edge routers. I was hoping if you could share some thoughtful insight on when to select one over the another?
We covered tons of relevant details in the January 2022 Design Clinic, here’s the CliffNotes version. Keep in mind that the road to hell (and broken designs) is paved with great recipes and best practices, and that I’m presenting a black-and-white picture because I don’t feel like transcribing the discussion we had into an oversized blog post. People wrote books on this topic; I’m pretty sure you can search for Russ White and find a few of them.
Finally, there’s no good substitute for understanding how things work (which brings me to another webinar ;).
Syed Khalid Ali left the following question on an old blog post describing the use of IBGP and EBGP in an enterprise network:
From an enterprise customer perspective, should I run iBGP, iBGP+IGP (OSPF/ISIS/EIGRP), or IGP with mutual redistribution on the edge routers? I was hoping you could share some thoughtful insight on when to select one over the other.
We covered many relevant details in the January 2022 Design Clinic; here’s the CliffNotes version. Remember that the road to hell (and broken designs) is paved with great recipes and best practices and that I’m presenting a black-and-white picture because I don’t feel like transcribing our discussion into an oversized blog post. People wrote books on this topic; search for “Russ White books” to find a few.
Finally, there’s no good substitute for understanding how things work (which brings me to another webinar ;).
Iwan Rahabok’s open-source VMware Operations Guide is now also available in Markdown-on-GitHub format. Networking engineers support vSphere/NSX infrastructure might be particularly interested in the Network Metrics chapter.