Author Archives: Junho Choi
Author Archives: Junho Choi
Cloudflare launched support for gRPC® during our 2020 Birthday Week. We’ve been humbled by the immense interest in the beta, and we’d like to thank everyone that has applied and tried out gRPC! In this post we’ll do a deep-dive into the technical details on how we implemented support.
gRPC is an open source RPC framework running over HTTP/2. RPC (remote procedure call) is a way for one machine to tell another machine to do something, rather than calling a local function in a library. RPC has been around in the history of distributed computing, with different implementations focusing on different areas, for a long time. What makes gRPC unique are the following characteristics:
In terms of the protocol, gRPC uses HTTP/2 frames extensively: requests and responses look very similar to a normal HTTP/2 request.


Cloudflare recently shipped improved upload speeds across our network for clients using HTTP/2. This post describes our journey from troubleshooting an issue to fixing it and delivering faster upload speeds to the global Internet.
We launched speed.cloudflare.com in May 2020 to give our users insight into how well their networks perform. The test provides download, upload and latency tests. Soon after release, we received reports from a small number of users that sometimes upload speeds were underreported. Our investigation determined that it seemed to happen with end users that had high upload bandwidth available (several hundreds Mbps class cable modem or fiber service). Our speed tests are performed via browser JavaScript, and most browsers use HTTP/2 by default. We found that HTTP/2 upload speeds were sometimes much slower than HTTP/1.1 (assuming all TLS) when the user had high available upload bandwidth.
Upload speed is more important than ever, especially for people using home broadband connections. As many people have been forced to work from home they’re using their broadband connections differently than before. Prior to the pandemic broadband traffic was very asymmetric (you downloaded way more than you uploaded… think listening to music, or streaming a movie), Continue reading
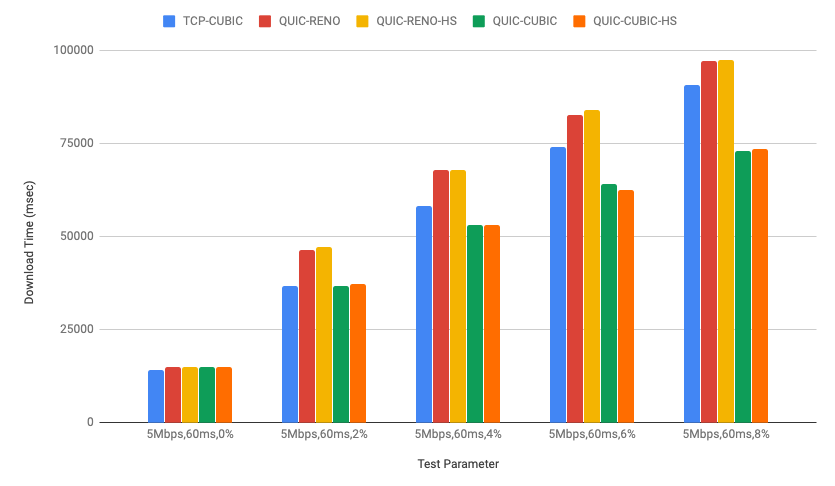
quiche, Cloudflare's IETF QUIC implementation has been running CUBIC congestion control for a while in our production environment as mentioned in Comparing HTTP/3 vs. HTTP/2 Performance). Recently we also added HyStart++ to the congestion control module for further improvements.
In this post, we will talk about QUIC congestion control and loss recovery briefly and CUBIC and HyStart++ in the quiche congestion control module. We will also discuss lab test results and how to visualize those using qlog which was recently added to the quiche library as well.
In the network transport area, congestion control is how to decide how much data the connection can send into the network. It has an important role in networking so as not to overrun the link but also at the same time it needs to play nice with other connections in the same network to ensure that the overall network, the Internet, doesn’t collapse. Basically congestion control is trying to detect the current capacity of the link and tune itself in real time and it’s one of the core algorithms for running the Internet.
QUIC congestion control has been written based on many years of TCP Continue reading
This is a Korean translation of a prior post by Marek Majkowski.
사내에서 DDoS 대응팀은 종종 "패킷 버리는 사람들"이라 불립니다. 다른 팀이 우리 네트워크를 통해 지나가는 트래픽으로 스마트한 일을 하며 신나할 때 우리는 그걸 버리는 여러가지 방법을 찾아가며 즐거워 합니다.

CC BY-SA 2.0 image by Brian Evans
DDoS 공격을 견뎌내기 위해서는 빠르게 패킷을 버릴 수 있는 능력이 매우 중요합니다.
쉽게 들리겠지만 서버에 도달한 패킷을 버리는 것은 여러 단계에서 가능합니다. 각 기법은 장점과 한계점이 있습니다. 이 블로그 글에서는 지금까지 시도해 본 기법들을 모두 정리해 보도록 하겠습니다.
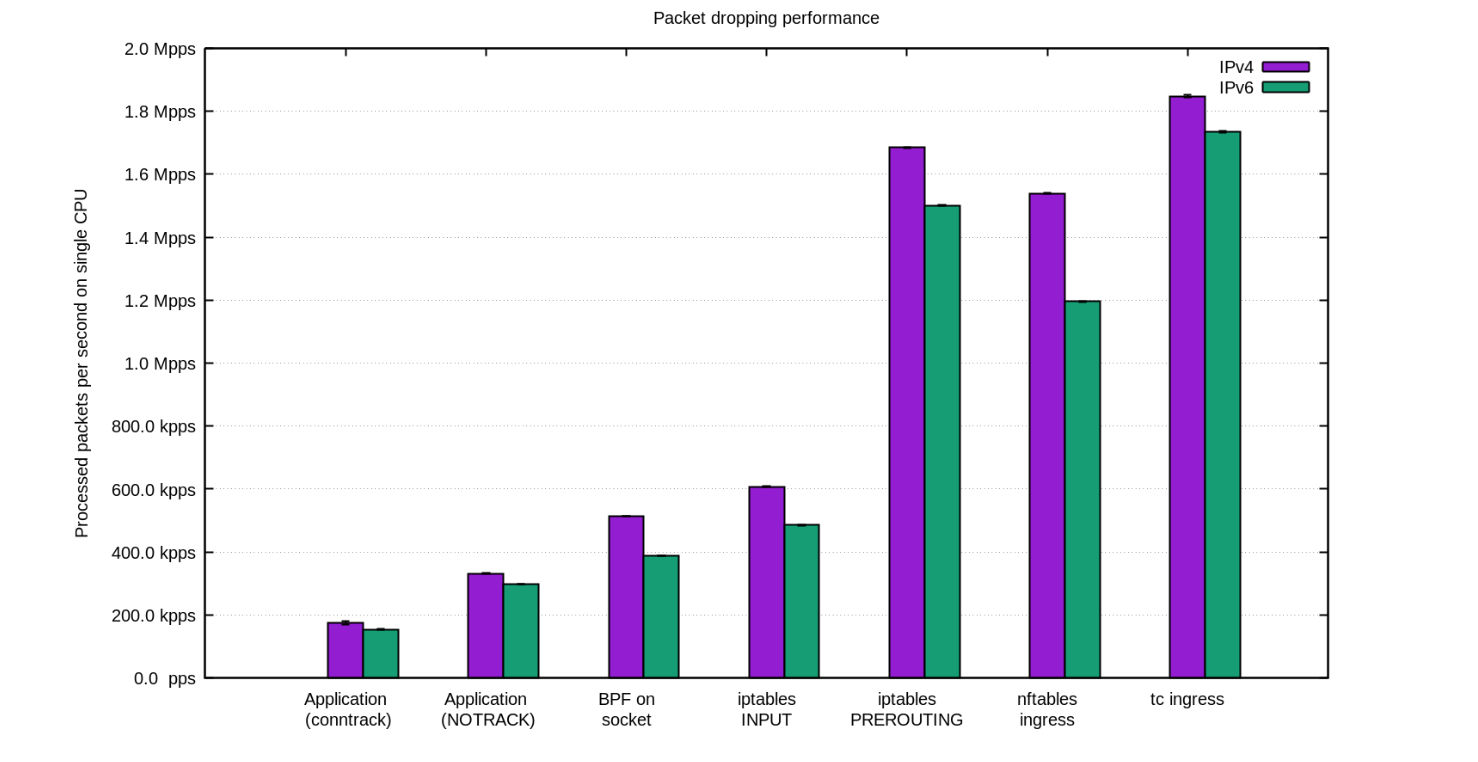
각 기법의 상대적인 성능을 시각화하기 위해서 먼저 숫자를 볼 것입니다. 벤치마크는 합성 테스트이므로 실제 숫자와는 일부 차이가 있을 수 있습니다. 테스트를 위해서는 10Gbps 네트워크 카드가 달린 인텔 서버를 사용할 것입니다. 하드웨어가 아니라 운영체제의 한계를 보여주기 위한 테스트이므로 하드웨어의 상세 사항은 적지 않겠습니다.
테스트 설정은 다음과 같습니다:
테스트는 사용자 공간 어플리케이션의 속도나 패킷 처리 속도를 최대화하려는 것이 아니라 커널의 병목 지점을 알고자 하는 것입니다.
합성 트래픽은 conntrack에 최대한의 부하를 주도록 준비되었습니다 - 임의의 소스 IP와 포트 필드를 사용합니다. tcpdump는 다음과 같이 Continue reading

This is a Korean translation of a prior post by Marek Majkowski.
얼마전 우리는 Spectrum을 발표하였습니다: 어떤 TCP 기반의 프로토콜이라도 DDoS 방어, 로드밸런싱 그리고 컨텐츠 가속을 할 수 있는 새로운 Cloudflare의 기능입니다.

CC BY-SA 2.0 image by Staffan Vilcans
Spectrum을 만들기 시작하고 얼마 되지 않아서 중요한 기술적 난관에 부딛히게 되었습니다: Spectrum은 1부터 65535 사이의 어떤 유효한 TCP 포트라도 접속을 허용해야 합니다. 우리의 리눅스 엣지 서버에서는 "임의의 포트 번호에 인바운드 연결을 허용"은 불가능합니다. 이것은 리눅스만의 제한은 아닙니다: 이것은 대부분 운영 체제의 네트워크 어플리케이션의 기반인 BSD 소켓 API의 특성입니다. 내부적으로 Spectrum을 완성하기 위해서 풀어야 하는 서로 겹치는 문제가 둘 있었습니다:
Cloudflare의 엣지 서버는 거의 동일한 구성을 갖고 있습니다. 초창기에는 루프백 네트워크 인터페이스에 특정한 /32 (그리고 /128) IP 주소를 할당하였습니다[1]. 이것은 수십개의 IP주소만 갖고 있었을 때에는 잘 동작 하였지만 더 성장함에 따라 확대 적용하는 것에는 실패하였습니다.
그때 "AnyIP" 트릭이 등장하였습니다. AnyIP는 단일 주소가 아니라 전체 IP 프리픽스 (서브넷)을 루프백 인터페이스에 할당하도록 해 줍니다. 사실 AnyIP를 많이 사용하고 있습니다: 여러분 컴퓨터에는 루브백 인터페이스에 Continue reading

This is a Korean translation of a prior post by Ignat Korchagin.
Cloudflare에서는 Go를 좋아합니다. Go는 많은 내부 소프트웨어 프로젝트와 거대한 파이프라인 시스템의 일부로도 사용되고 있습니다. 하지만 Go를 한단계 더 끌어 올려서 우리가 선호하는 운영체제인 리눅스의 스크립트 언어로 사용할 수 있을까요?

gopher image CC BY 3.0 Renee French | Tux image CC0 BY OpenClipart-Vectors
간단한 답은: 왜 안되나요? Go는 비교적 쉽게 배울 수 있고 아주 복잡하지도 않고, 코드를 처음부터 작성해야 하는 일을 피하기 위해 재사용 가능한 라이브러리의 거대한 에코시스템이 있습니다. 추가로 다음과 같은 잠재적인 장점이 있습니다:
go build 명령은 대부분의 소규모이며 독립적인 프로젝트에 적합합니다. 더 복잡한 프로젝트는 대부분 별도의 빌드 시스템/스크립트 세트를 채용하고 있습니다. 이런 스크립트도 Go로 작성 가능하지 않을까요?go get 을 사용하면 됩니다. 그리고 이 코드가 여러분의 GOPATH에 설치되므로, 서드파티 라이브러리를 받는 것은 시스템의 별도 운영 권한을 필요로 하지 않습니다(다른 일부 스크립트 언어와 달리). 이것은 대규모의 기업 환경에서 특히 유용합니다.
This is a Korean translation of a prior post.
(이 글은 제 개인 블로그에 게시된 튜토리얼을 다시 올린 것입니다)
Rust에는 흥미로운 기능이 많지만 그중에도 강력한 매크로 시스템이 있습니다. 불행히도 The Book[1]과 여러가지 튜토리얼을 읽고 나서도 서로 다른 요소의 복잡한 리스트를 처리하는 매크로를 구현하려고 하면 저는 여전히 어떻게 만들어야 하는지를 이해하는데 힘들어 하며, 좀 시간이 지나서 머리속에 불이 켜지는 듯한 느낌이 들면 그제서야 이것저것 매크로를 마구 사용하기 시작 합니다. :) (맞아요, 난-매크로를-써요-왜냐하면-함수나-타입-지정이나-생명주기를-쓰고-싶어하지-않아서 처럼과 같은 이유는 아니지만 다른 사람들이 쓰는걸 봤었고 실제로 유용한 곳이라면 말이죠)
CC BY 2.0 image by Conor Lawless
그래서 이 글에서는 제가 생각하는 그런 매크로를 쓰는 데 필요한 원칙을 설명하고자 합니다. 이 글에서는 The Book의 매크로 섹션을 읽어 보았고 기본적인 매크로 정의와 토큰 타입에 대해 익숙하다고 가정하겠습니다.
이 튜토리얼에서는 역폴란드 표기법 (Reverse Polish Notation, RPN)을 예제로 사용합니다. 충분히 간단하기 때문에 흥미롭기도 하고, 학교에서 이미 배워서 익숙할 지도 모르고요. 하지만 컴파일 시간에 정적으로 구현하기 위해서는 재귀적인 매크로를 사용해야 할 것입니다.
역폴란드 표기법(후위 또는 후치 표기법으로 불리기도 합니다)은 모든 연산에 스택을 사용하므로 연산 대상을 스택에 넣고 [이진] 연산자는 연산 대상 두개를 스택에서 가져와서 결과를 평가하고 다시 스택에 넣습니다. 따라서 다음과 같은 식을 생각해 보면:
2 3 + 4 *
이 식은 다음과 같이 해석됩니다:
역자주: 이 글은 Marek Majkowski의 https://blog.cloudflare.com/syn-packet-handling-in-the-wild/ 를 번역한 것입니다.
우리 Cloudflare 에서는 실제 인터넷상의 서버 운영 경험이 많습니다. 하지만 이런 흑마술 마스터하기를 게을리하지도 않습니다. 이 블로그에서는 인터넷 프로토콜의 여러 어두운 부분을 다룬 적이 있습니다: understanding FIN-WAIT-2 나 receive buffer tuning과 같은 것들입니다.

CC BY 2.0 image by Isaí Moreno
사람들이 충분히 신경쓰지 않는 주제가 하나 있는데, 바로 SYN 홍수(SYN floods) 입니다. 우리는 리눅스를 사용하고 있는데 리눅스에서 SYN 패킷 처리는 매우 복잡하다는 것을 알게 되었습니다. 이 글에서는 이에 대해 좀 더 알아 보도록 하겠습니다.
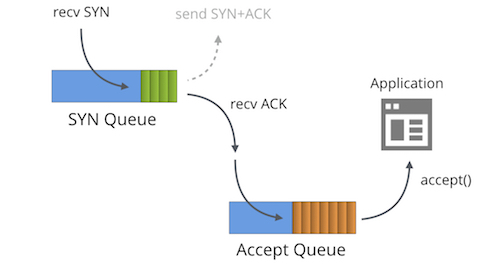
일단 만들어진 소켓에 대해 "LISTENING" TCP 상태에는 두개의 분리된 큐가 존재 합니다:
일반적으로 이 큐에는 여러가지 다른 이름이 붙어 있는데, "reqsk_queue", "ACK backlog", "listen backlog", "TCP backlog" 등이 있습니다만 혼란을 피하기 위해 위의 이름을 사용하도록 하겠습니다.
SYN 큐는 수신 SYN 패킷[1] (구체적으로는 struct inet_request_sock)을 저장합니다. 이는 SYN+ACK 패킷을 보내고 타임아웃시에 재시도하는 역할을 합니다. 리눅스에서 재시도 값은 다음과 같이 설정됩니다:
$ sysctl net.ipv4.tcp_synack_retries
net.ipv4.tcp_synack_retries = 5
문서를 보면 다음과 같습니다:
tcp_synack_retries - 정수
수동 TCP 연결 시도에 대해서 SYNACK를 몇번 다시 보낼지를 지정한다.
이 값은 255 이하이어야 한다. 기본값은 5이며, 1초의 초기 RTO값을 감안하면
마지막 재전송은 31초 Continue reading{kind=link}