Author Archives: Marek Majkowski
Author Archives: Marek Majkowski
I was asked to debug another weird issue on our network. Apparently every now and then a connection going through CloudFlare would time out with 522 HTTP error.
 CC BY 2.0 image by Chris Combe
CC BY 2.0 image by Chris Combe
522 error on CloudFlare indicates a connection issue between our edge server and the origin server. Most often the blame is on the origin server side - the origin server is slow, offline or encountering high packet loss. Less often the problem is on our side.
In the case I was debugging it was neither. The internet connectivity between CloudFlare and origin was perfect. No packet loss, flat latency. So why did we see a 522 error?
The root cause of this issue was pretty complex. Afterred long debugging we identified an important symptom: sometimes, once in thousands of runs, our test program failed to establish a connection between two daemons on the same machine. To be precise, an NGINX instance was trying to establish a TCP connection to our internal acceleration service on localhost. This failed with a timeout error.
Once we knew what to look for we were able to reproduce this with good old netcat. After a couple of dozen of Continue reading
A recent blog post posed the question Why do we use the Linux kernel's TCP stack?. It triggered a very interesting discussion on Hacker News.
I've also thought about this question while working at CloudFlare. My experience mostly comes from working with thousands of production machines here and I can try to answer the question from that perspective.
 CC BY 2.0 image by John Vetterli
CC BY 2.0 image by John Vetterli
Let's start with a broader question - what is the point of running an operating system at all? If you planned on running a single application, having to use a kernel consisting of multiple million lines of code may sound like a burden.
But in fact most of us decide to run some kind of OS and we do that for two reasons. Firstly, the OS layer adds hardware independence and easy to use APIs. With these we can focus on writing the code for any machine - not only the specialized hardware we have at the moment. Secondly, the OS adds a time sharing layer. This allows us to run more than one application at a time. Whether it's a second HTTP server or just a bash session, this ability to share resources Continue reading
Some time ago we discovered that certain very slow downloads were getting abruptly terminated and began investigating whether that was a client (i.e. web browser) or server (i.e. us) problem.
Some users were unable to download a binary file a few megabytes in length. The story was simple—the download connection was abruptly terminated even though the file was in the process of being downloaded. After a brief investigation we confirmed the problem: somewhere in our stack there was a bug.
Describing the problem was simple, reproducing the problem was easy with a single curl command, but fixing it took surprising amount of effort.
 CC BY 2.0 image by jojo nicdao
CC BY 2.0 image by jojo nicdao
In this article I'll describe the symptoms we saw, how we reproduced it and how we fixed it. Hopefully, by sharing our experiences we will save others from the tedious debugging we went through.
Two things caught our attention in the bug report. First, only users on mobile phones were experiencing the problem. Second, the asset causing issues—a binary file—was pretty large, at around 30MB.
After a fruitful session with tcpdump one of our engineers was able to prepare a test case that reproduced the Continue reading
Back in November we wrote a blog post about one latency spike. Today I'd like to share a continuation of that story. As it turns out, the misconfigured rmem setting wasn't the only source of added latency.
It looked like Mr Wolf hadn't finished his job.
After adjusting the previously discussed rmem sysctl we continued monitoring our systems' latency. Among other things we measured ping times to our edge servers. While the worst case improved and we didn't see 1000ms+ pings anymore, the line still wasn't flat. Here's a graph of ping latency between an idling internal machine and a production server. The test was done within the datacenter, the packets never went to the public internet. The Y axis of the chart shows ping times in milliseconds, the X axis is the time of the measurement. Measurements were taken every second for over 6 hours:

As you can see most pings finished below 1ms. But out of 21,600 measurements about 20 had high latency of up to 100ms. Not ideal, is it?
The latency occurred within our datacenter and the packets weren't lost. This suggested a kernel issue again. Linux responds to ICMP pings from its soft Continue reading
Over the last month, we’ve been watching some of the largest distributed denial of service (DDoS) attacks ever seen unfold. As CloudFlare has grown we've brought on line systems capable of absorbing and accurately measuring attacks. Since we don't need to resort to crude techniques to block traffic we can measure and filter attacks with accuracy. Our systems sort bad packets from good, keep websites online and keep track of attack packet rates and bits per second.
The current spate of large attacks are all layer 3 (L3) DDoS. Layer 3 attacks consist of a large volume of packets hitting the target network, and the aim is usually to overwhelm the target network hardware or connectivity.
L3 attacks are dangerous because most of the time the only solution is to acquire large network capacity and buy beefy networking hardware, which is simply not an option for most independent website operators. Or, faced with huge packet rates, some providers simply turn off connections or entirely block IP addresses.
Historically, L3 attacks were the biggest headache for CloudFlare. Over the last two years, we’ve automated almost all of our L3 attack handling and these automatic systems protect Continue reading
We're happy to announce that next week CloudFlare is hosting the Null Security meetup in Singapore. You are invited!

Null is a community for hackers and security enthusiasts. Monthly meetups are organized in a number of Asian cities. Read more at http://null.co.in/.
The lineup for the February meetup:
If you’d like to sign up for the event, you can do so here:
What: Null Singapore - The Open Security Community meetup
When: February 24th: 6:45pm-8:45pm
Where: The Working Capitol, "The Commons" Room, 1 Keong Saik Road, Singapore 089109
CloudFlare is actively hiring in Singapore!
A customer reported an unusual problem with our CloudFlare CDN: our servers were responding to some HTTP requests slowly. Extremely slowly. 30 seconds slowly. This happened very rarely and wasn't easily reproducible. To make things worse all our usual monitoring hadn't caught the problem. At the application layer everything was fine: our NGINX servers were not reporting any long running requests.
Time to send in The Wolf.
He solves problems.
First, we attempted to reproduce what the customer reported—long HTTP responses. Here is a chart of of test HTTP requests time measured against our CDN:
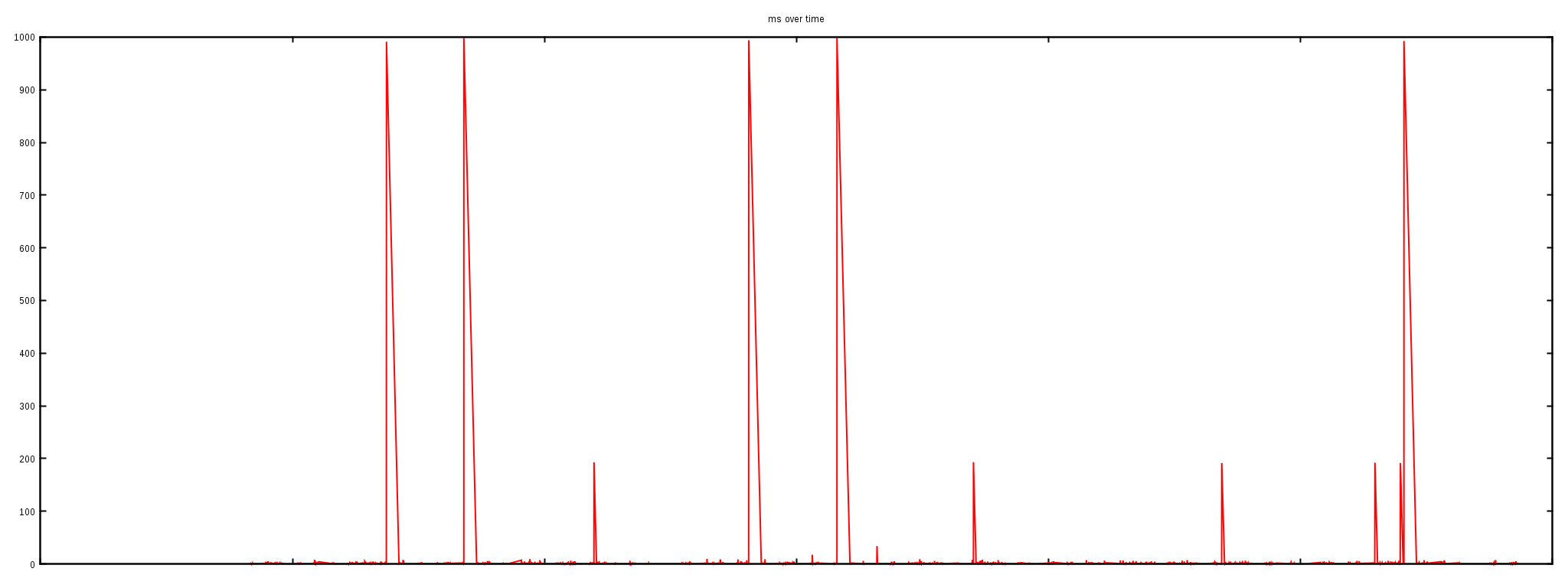
We ran thousands of HTTP queries against one server over a couple of hours. Almost all the requests finished in milliseconds, but, as you can clearly, see 5 requests out of thousands took as long as 1000ms to finish. When debugging network problems the delays of 1s, 30s are very characteristic. They may indicate packet loss since the SYN packets are usually retransmitted at times 1s, 3s, 7s, 15, 31s.
At first we thought the spikes in HTTP load times might indicate some sort of network problem. To be sure we ran ICMP pings against two IPs over many Continue reading
CloudFlare servers are constantly being targeted by DDoS'es. We see everything from attempted DNS reflection attacks to L7 HTTP floods involving large botnets.
Recently an unusual flood caught our attention. A site reliability engineer on call noticed a large number of HTTP requests being issued against one of our customers.

Here is one of the requests:
POST /js/404.js HTTP/1.1
Host: www.victim.com
Connection: keep-alive
Content-Length: 426
Origin: http://attacksite.com
User-Agent: Mozilla/5.0 (Linux; U; Android 4.4.4; zh-cn; MI 4LTE Build/KTU84P) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/42.0.0.0 Mobile Safari/537.36 XiaoMi/MiuiBrowser/2.1.1
Content-Type: application/x-www-form-urlencoded
Accept: */*
Referer: http://attacksite.com/html/part/86.html
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,en-US;q=0.8
id=datadatadasssssssssssssssssssssssssssssssssssssssssssassssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssadatadata
We received millions of similar requests, clearly suggesting a flood. Let's take a deeper look at this request.
First, let's note that the headers look legitimate. We often see floods issued by Python or Ruby scripts, with weird Accept-Language or User-Agent headers. But this one doesn't look like it. This request is a proper request issued by a real browser.
Next, notice the request is a POST and contains an Origin header — it was issued by an Ajax (XHR) cross Continue reading
In two previous posts we've discussed how to receive 1M UDP packets per second and how to reduce the round trip time. We did the experiments on Linux and the performance was very good considering it's a general purpose operating system.
Unfortunately the speed of vanilla Linux kernel networking is not sufficient for more specialized workloads. For example, here at CloudFlare, we are constantly dealing with large packet floods. Vanilla Linux can do only about 1M pps. This is not enough in our environment, especially since the network cards are capable of handling a much higher throughput. Modern 10Gbps NIC's can usually process at least 10M pps.
 CC BY 2.0 image by Tony Webster
CC BY 2.0 image by Tony Webster
It's apparent that the only way to squeeze more packets from our hardware is by working around the Linux kernel networking stack. This is called a "kernel bypass" and in this article we'll dig into various ways of achieving it.
Let's prepare a small experiment to convince you that working around Linux is indeed necessary. Let's see how many packets can be handled by the kernel under perfect conditions. Passing packets to userspace is costly, so instead let's try to drop Continue reading
Good morning!
In a recent blog post we explained how to tweak a simple UDP application to maximize throughput. This time we are going to optimize our UDP application for latency. Fighting with latency is a great excuse to discuss modern features of multiqueue NICs. Some of the techniques covered here are also discussed in the scaling.txt kernel document.
 CC BY-SA 2.0 image by Xiaojun Deng
CC BY-SA 2.0 image by Xiaojun Deng
Our experiment will be setup up as follows:
Last week during a casual conversation I overheard a colleague saying: "The Linux network stack is slow! You can't expect it to do more than 50 thousand packets per second per core!"
That got me thinking. While I agree that 50kpps per core is probably the limit for any practical application, what is the Linux networking stack capable of? Let's rephrase that to make it more fun:
On Linux, how hard is it to write a program that receives 1 million UDP packets per second?
Hopefully, answering this question will be a good lesson about the design of a modern networking stack.
 CC BY-SA 2.0 image by Bob McCaffrey
CC BY-SA 2.0 image by Bob McCaffrey
First, let us assume:
Measuring packets per second (pps) is much more interesting than measuring bytes per second (Bps). You can achieve high Bps by better pipelining and sending longer packets. Improving pps is much harder.
Since we're interested in pps, our experiments will use short UDP messages. To be precise: 32 bytes of UDP payload. That means 74 bytes on the Ethernet layer.
For the experiments we will use two physical servers: "receiver" and "sender".
They both have two six core 2GHz Xeon processors. With hyperthreading (HT) enabled Continue reading
For quite some time we've been grilling our candidates about dirty corners of TCP/IP stack. Every engineer here must prove his/her comprehensive understanding of the full network stack. For example: what are the differences in checksumming algorithms between IPv4 and IPv6 stacks?
I'm joking of course, but in the spirit of the old TCP/IP pub game I want to share some of the amusing TCP/IP quirks I've bumped into over the last few months while working on CloudFlare's automatic attack mitigation systems.

CC BY-SA 2.0 image by Daan Berg
Don't worry if you don't know the correct answer: you may always come up with a funny one!
Some of the questions are fairly obvious, some don't have a direct answer and are supposed to provoke a longer discussion. The goal is to encourage our readers to review the dusty RFCs, get interested in the inner workings of the network stack and generally spread the knowledge about the protocols we rely on so much.
Don't forget to add a comment below if you want to share a response!
You think you know all about TCP/IP? Let's find out.
1) What is the lowest TCP port number?
2) The TCP Continue reading
DNS, one of the oldest technologies running the Internet, keeps evolving. There is a constant stream of new developments, from DNSSEC, through DNS-over-TLS, to a plentiful supply of fresh EDNS extensions.

New DNS Resource Records types are being added all the time. As the Internet evolves, new RR’s gain traction while the usage of some old record types decreases. Did you know you can use DNS to express the location of your server on the planet's surface?
Today, we are announcing that we are deprecating the DNS ANY meta-query. In a few weeks we'll be responding to those queries with rcode 4 / Not Implemented.
“ANY” is one of the special “magic” types in DNS. Instead of being a query for a single type like A , AAAA or MX, ANY retrieves all the available types for a given name. Over the years there have been many arguments over the semantics of ANY with some people arguing it really means ALL. Answers to ANY queries are among the biggest that DNS servers give out. The original reason for adding the ANY to DNS was to aid in debugging and testing Continue reading
Last week, a very small number of our users who are using IP tunnels (primarily tunneling IPv6 over IPv4) were unable to access our services because a networking change broke "path MTU discovery" on our servers. In this article, I'll explain what path MTU discovery is, how we broke it, how we fixed it and the open source code we used.
When a host on the Internet wants to send some data, it must know how to divide the data into packets. And in particular it needs to know the maximum size of packet. The maximum size of a packet a host can send is called Maximum Transmission Unit: MTU.
The longer the MTU, the better for performance, but the worse for reliability, because a lost packet means more data to be retransmitted and because many routers on the Internet can't deliver very long packets.
The fathers of the Internet assumed that this problem would be solved at the IP layer with IP fragmentation. Unfortunately IP fragmentation has serious disadvantages and it's avoided in practice.
To work around fragmentation problems the IP layer contains a "Don't Fragment" bit on every IP packet. Continue reading
