Author Archives: Marek Majkowski
Author Archives: Marek Majkowski


Modern DDR3 SDRAM. Source: BY-SA/4.0 by Kjerish
During my recent visit to the Computer History Museum in Mountain View, I found myself staring at some ancient magnetic core memory.

Source: BY-SA/3.0 by Konstantin Lanzet
I promptly concluded I had absolutely no idea on how these things could ever work. I wondered if the rings rotate (they don't), and why each ring has three wires woven through it (and I still don’t understand exactly how these work). More importantly, I realized I have very little understanding on how the modern computer memory - dynamic RAM - works!
Source: Ulrich Drepper's series about memory
I was particularly interested in one of the consequences of how dynamic RAM works. You see, each bit of data is stored by the charge (or lack of it) on a tiny capacitor within the RAM chip. But these capacitors gradually lose their charge over time. To avoid losing the stored data, they must regularly get refreshed to restore the charge (if present) to its original level. This refresh process involves reading the value of every bit and then writing it back. During this "refresh" time, the memory is busy and it can't perform normal operations Continue reading
It's been a while since we last wrote about Layer 3/4 DDoS attacks on this blog. This is a good news - we've been quietly handling the daily onslaught of DDoS attacks. Since our last write-up, a handful of interesting L3/4 attacks have happened. Let's review them.
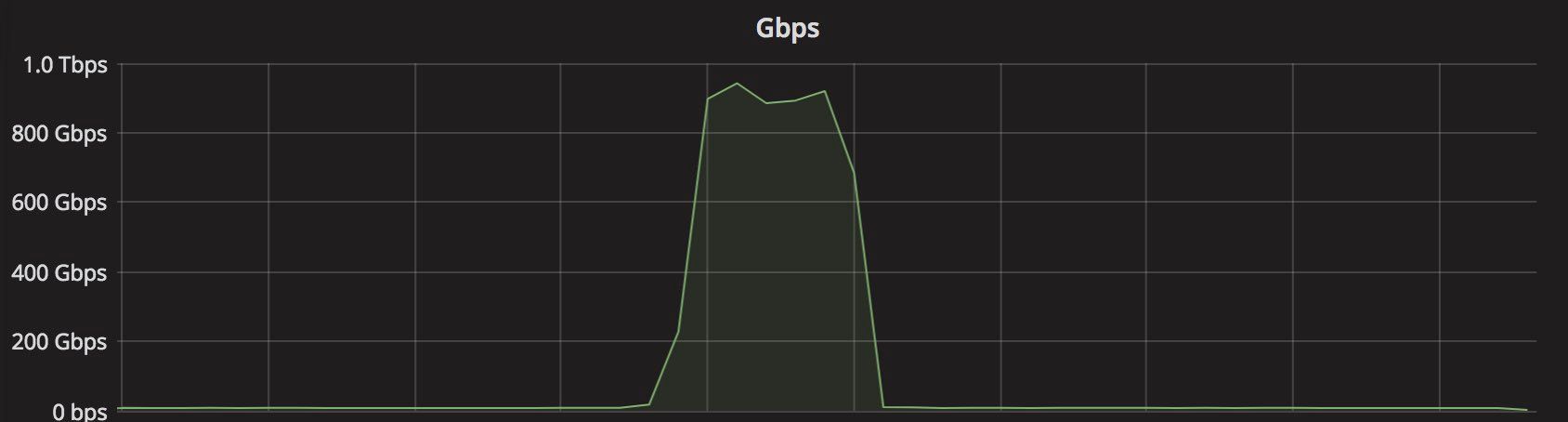
In April, John tweeted about a gigantic 942Gbps SYN flood:
It was a notable event for a couple of reasons.
First, it was really large. Previously, we've seen only amplification / reflection attacks at terabit scale. In those cases, the attacker doesn't actually have too much capacity. They need to bounce the traffic off other servers to generate a substantial load. This is different from typical "direct" style attacks, like SYN floods. In the SYN flood mentioned by John, all 942Gbps were coming directly from attacker-controlled machines.
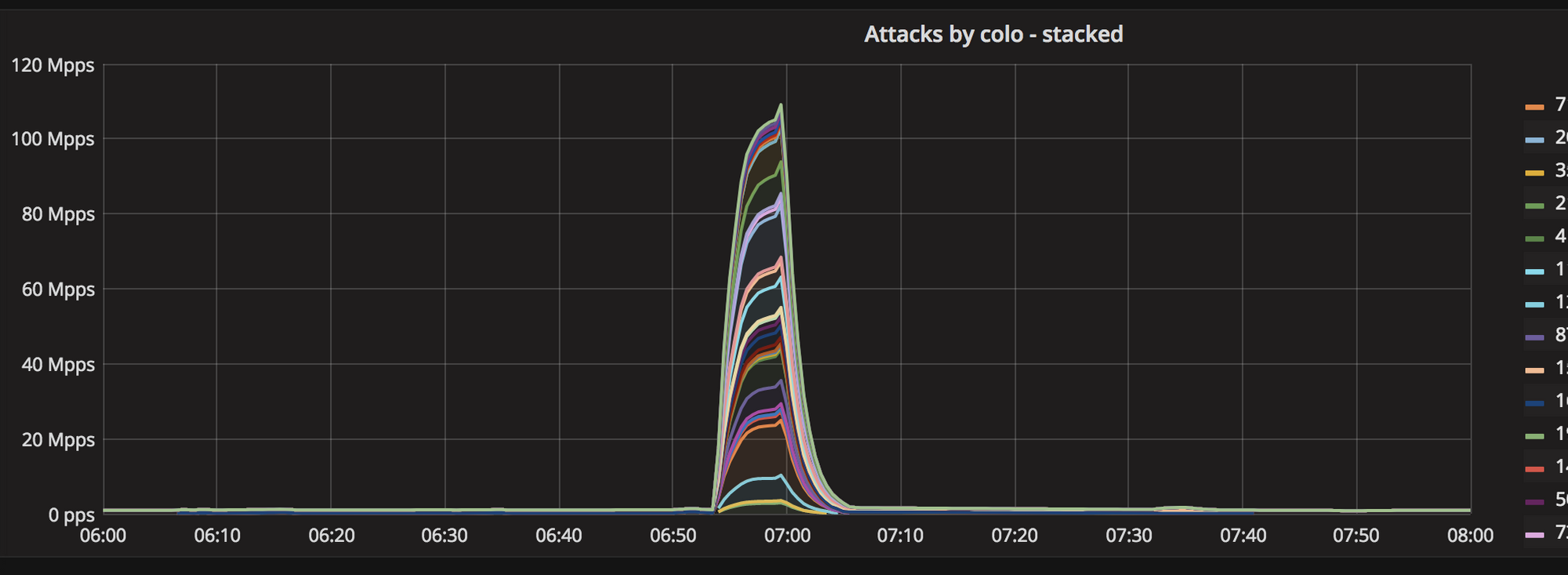
Secondly, this attack was truly distributed. Normal SYN floods come from a small number of geographical locations. This one, was all over the globe, hitting all Cloudflare data centers:
Thirdly, the attack seem to be partially spoofed. While our analysis was not conclusive, we saw random, spoofed source IP addresses in the largest internet exchanges. The above Hilbert curve shows the source IP Continue reading
Back in 2015 we deployed ECMP routing - Equal Cost Multi Path - within our datacenters. This technology allowed us to spread traffic heading to a single IP address across multiple physical servers.
You can think about it as a third layer of load balancing.

When deploying ECMP we hit a problem with Path MTU discovery. The ICMP packets destined to our Anycast IP's were being dropped. You can read more about that (and the solution) in the 2015 blog post Path MTU Discovery in practice.
To solve the problem we created a small piece of software, called pmtud (https://github.com/cloudflare/pmtud). Since deploying pmtud, our ECMP setup has been working smoothly.
During that initial ECMP rollout things were broken. To keep services running until pmtud was done, we deployed a quick hack. We reduced the MTU of IPv6 traffic to the minimal possible value: 1280 bytes.
This was done as a tag on a default route. This is Continue reading
Internally our DDoS mitigation team is sometimes called "the packet droppers". When other teams build exciting products to do smart things with the traffic that passes through our network, we take joy in discovering novel ways of discarding it.

CC BY-SA 2.0 image by Brian Evans
Being able to quickly discard packets is very important to withstand DDoS attacks.
Dropping packets hitting our servers, as simple as it sounds, can be done on multiple layers. Each technique has its advantages and limitations. In this blog post we'll review all the techniques we tried thus far.
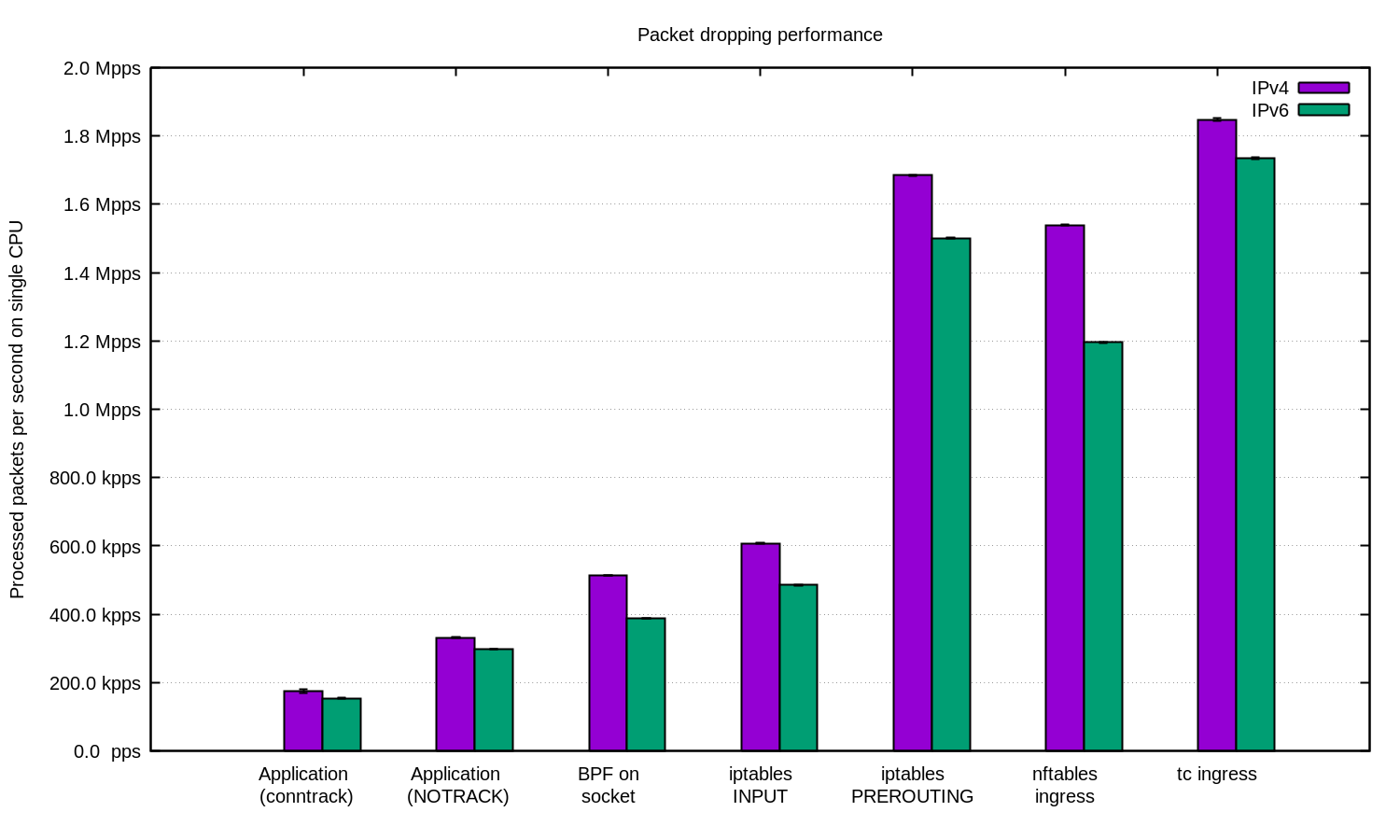
To illustrate the relative performance of the methods we'll show some numbers. The benchmarks are synthetic, so take the numbers with a grain of salt. We'll use one of our Intel servers, with a 10Gbps network card. The hardware details aren't too important, since the tests are prepared to show the operating system, not hardware, limitations.
Our testing setup is prepared as follows:
We transmit a large number of tiny UDP packets, reaching 14Mpps (millions packets per second).
This traffic is directed towards a single CPU on a target server.
We measure the number of packets handled by the kernel on that Continue reading
On May 31, 2018 we had a 17 minute outage on our 1.1.1.1 resolver service; this was our doing and not the result of an attack.
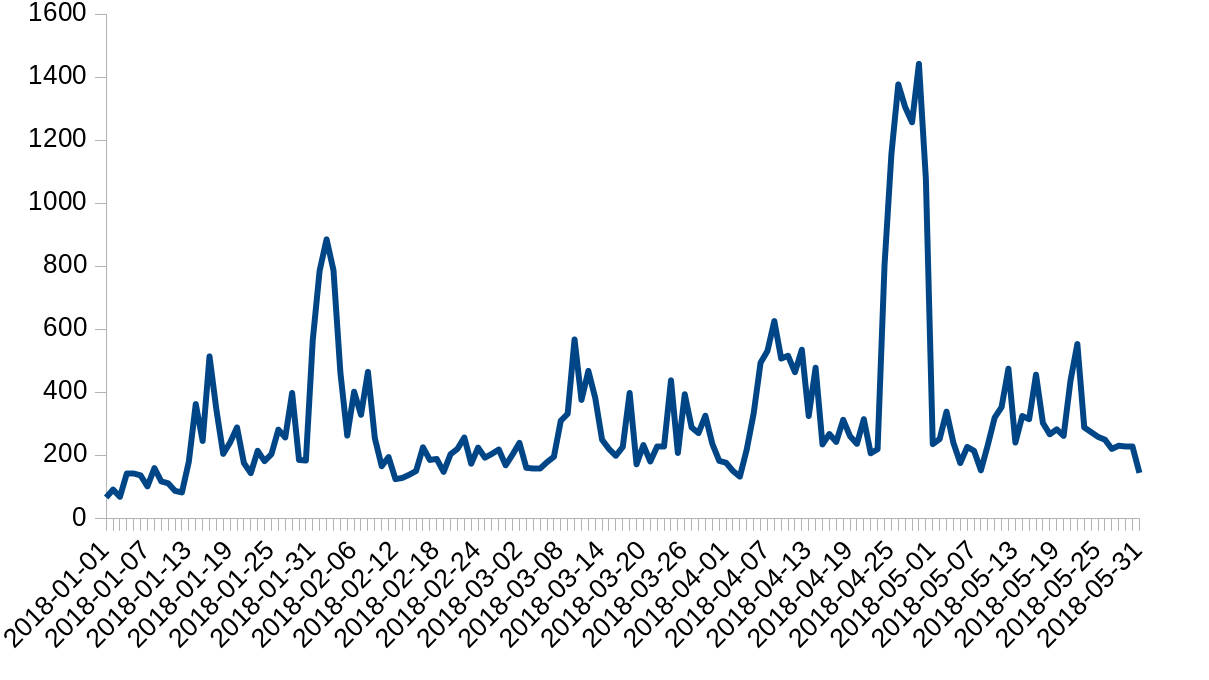
Cloudflare is protected from attacks by the Gatebot DDoS mitigation pipeline. Gatebot performs hundreds of mitigations a day, shielding our infrastructure and our customers from L3/L4 and L7 attacks. Here is a chart of a count of daily Gatebot actions this year:
In the past, we have blogged about our systems:
Today, things didn't go as planned.
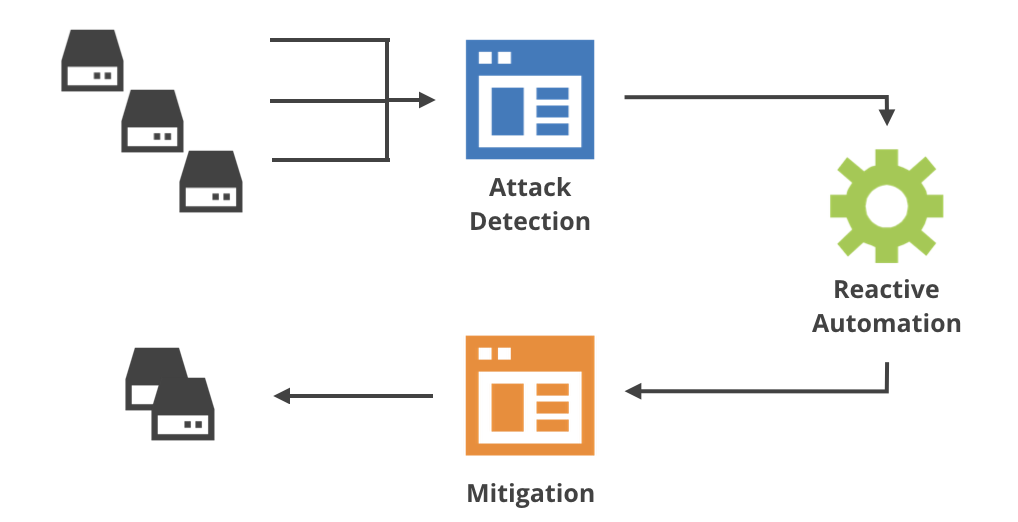
Cloudflare’s network is large, handles many different types of traffic and mitigates different types of known and not-yet-seen attacks. The Gatebot pipeline manages this complexity in three separate stages:
The benign-sounding "reactive automation" part is actually the most complicated stage in the pipeline. We expected that from the start, which is why we implemented this stage using a custom Functional Reactive Programming (FRP) framework. If you want to know more about it, see the talk and the presentation.
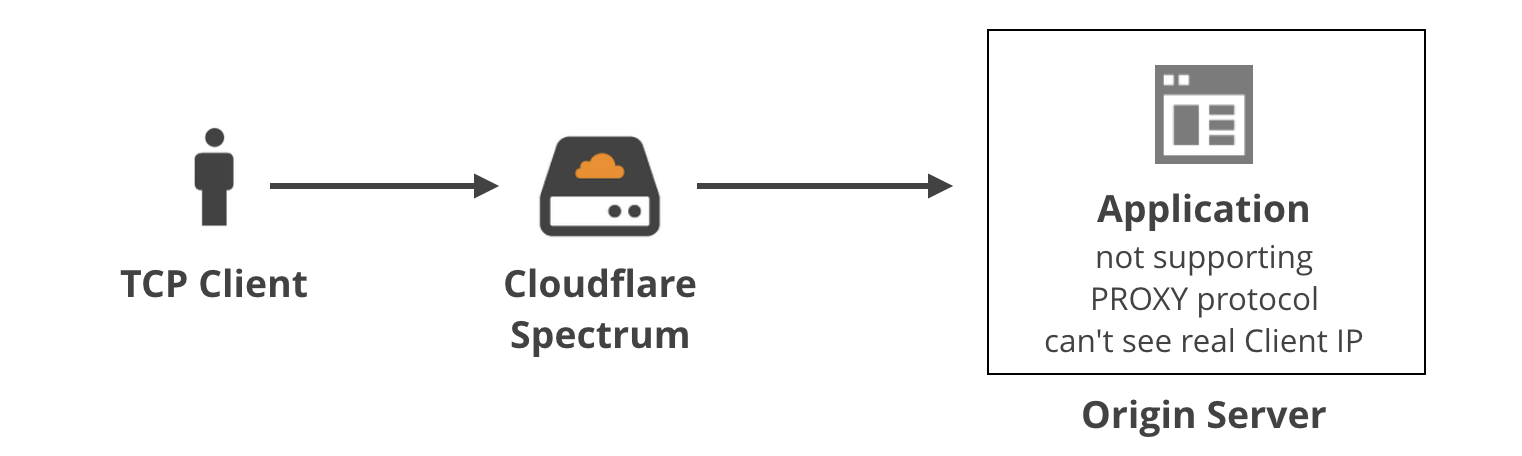
In previous blog post we discussed how we use the TPROXY iptables module to power Cloudflare Spectrum. With TPROXY we solved a major technical issue on the server side, and we thought we might find another use for it on the client side of our product.
This is Addressograph. Source Wikipedia
When building an application level proxy, the first consideration is always about retaining real client source IP addresses. Some protocols make it easy, e.g. HTTP has a defined X-Forwarded-For header[1], but there isn't a similar thing for generic TCP tunnels.
Others have faced this problem before us, and have devised three general solutions:
For certain applications it may be okay to ignore the real client IP address. For example, sometimes the client needs to identify itself with a username and password anyway, so the source IP doesn't really matter. In general, it's not a good practice because...
A second method was developed by Akamai: the client IP is saved inside a custom option in the TCP header in the SYN packet. Early implementations of this method weren't conforming to any standards, e.g. using option field 28 Continue reading

Today we are introducing Spectrum: a new Cloudflare feature that brings DDoS protection, load balancing, and content acceleration to any TCP-based protocol.

CC BY-SA 2.0 image by Staffan Vilcans
Soon after we started building Spectrum, we hit a major technical obstacle: Spectrum requires us to accept connections on any valid TCP port, from 1 to 65535. On our Linux edge servers it's impossible to "accept inbound connections on any port number". This is not a Linux-specific limitation: it's a characteristic of the BSD sockets API, the basis for network applications on most operating systems. Under the hood there are two overlapping problems that we needed to solve in order to deliver Spectrum:
Cloudflare’s edge servers have an almost identical configuration. In our early days, we used to assign specific /32 (and /128) IP addresses to the loopback network interface[1]. This worked well when we had dozens of IP Continue reading
A friend gave me an interesting task: extract IP TTL values from TCP connections established by a userspace program. This seemingly simple task quickly exploded into an epic Linux system programming hack. The result code is grossly over engineered, but boy, did we learn plenty in the process!

CC BY-SA 2.0 image by Paul Miller
You may wonder why she wanted to inspect the TTL packet field (formally known as "IP Time To Live (TTL)" in IPv4, or "Hop Count" in IPv6)? The reason is simple - she wanted to ensure that the connections are routed outside of our datacenter. The "Hop Distance" - the difference between the TTL value set by the originating machine and the TTL value in the packet received at its destination - shows how many routers the packet crossed. If a packet crossed two or more routers, we know it indeed came from outside of our datacenter.

It's uncommon to look at TTL values (except for their intended purpose of mitigating routing loops by checking when the TTL reaches zero). The normal way to deal with the problem we had would be to blacklist IP ranges of our servers. But it’s not that Continue reading
A week ago we published a story about new amplification attacks using memcached protocol on UDP port 11211. A few things happened since then:
Let's take a deep breath and discuss why such large DDoS attacks are even possible on the modern internet.

CC BY-SA 2.0 image by DaPuglet
All the gigantic headline-grabbing attacks are what we call "L3" (Layer 3 OSI[1]). This kind of attack has a common trait - the malicious software sends as many packets as possible onto the network. For greater speed these packets are hand crafted by attackers - they are not generated using high-level, well-behaved libraries. Packets are mashed together as a series of bytes and fired onto the network to inflict the greatest damage.
L3 attacks can be divided into two categories, depending on where the attacker directs their traffic:
Direct: where the traffic is sent directly against a victim IP. A SYN flood is a common attack of this type.
Amplification: the traffic is sent to vulnerable Continue reading
 CC BY-SA 2.0 image by David Trawin
CC BY-SA 2.0 image by David Trawin
Over last couple of days we've seen a big increase in an obscure amplification attack vector - using the memcached protocol, coming from UDP port 11211.
In the past, we have talked a lot about amplification attacks happening on the internet. Our most recent two blog posts on this subject were:
The general idea behind all amplification attacks is the same. An IP-spoofing capable attacker sends forged requests to a vulnerable UDP server. The UDP server, not knowing the request is forged, politely prepares the response. The problem happens when thousands of responses are delivered to an unsuspecting target host, overwhelming its resources - most typically the network itself.

Amplification attacks are effective, because often the response packets are much larger than the request packets. A carefully prepared technique allows an attacker with limited IP spoofing capacity (such as 1Gbps) to launch very large attacks (reaching 100s Gbps) "amplifying" the attacker's bandwidth.
Obscure amplification attacks happen all the time. We often see "chargen" or "call Continue reading
Here at Cloudflare, we have a lot of experience of operating servers on the wild Internet. But we are always improving our mastery of this black art. On this very blog we have touched on multiple dark corners of the Internet protocols: like understanding FIN-WAIT-2 or receive buffer tuning.

CC BY 2.0 image by Isaí Moreno
One subject hasn't had enough attention though - SYN floods. We use Linux and it turns out that SYN packet handling in Linux is truly complex. In this post we'll shine some light on this subject.
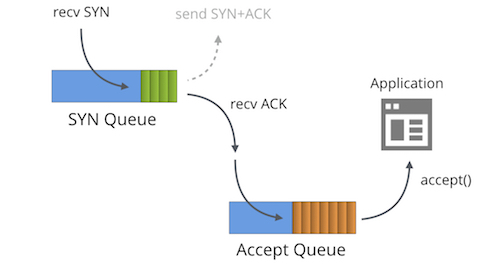
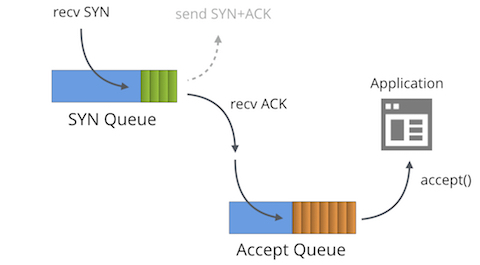
First we must understand that each bound socket, in the "LISTENING" TCP state has two separate queues:
In the literature these queues are often given other names such as "reqsk_queue", "ACK backlog", "listen backlog" or even "TCP backlog", but I'll stick to the names above to avoid confusion.
The SYN Queue stores inbound SYN packets[1] (specifically: struct inet_request_sock). It's responsible for sending out SYN+ACK packets and retrying them on timeout. On Linux the number of retries is configured with:
$ sysctl net.ipv4.tcp_synack_retries
net.ipv4.tcp_synack_retries = 5
In a recent blog post we discussed epoll behavior causing uneven load among NGINX worker processes. We suggested a work around - the REUSEPORT socket option. It changes the queuing from "combined queue model" aka Waitrose (formally: M/M/s), to a dedicated accept queue per worker aka "the Tesco superstore model" (formally: M/M/1). With this setup the load is spread more evenly, but in certain conditions the latency distribution might suffer.
After reading that piece, a colleague of mine, John, said: "Hey Marek, don't forget that REUSEPORT has an additional advantage: it can improve packet locality! Packets can avoid being passed around CPUs!"
John had a point. Let's dig into this step by step.
In this blog post we'll explain the REUSEPORT socket option, how it can help with packet locality and its performance implications. We'll show three advanced SystemTap scripts which we used to help us understand and measure the packet locality.
The standard BSD socket API model is rather simple. In order to receive new TCP connections a program calls bind() and then listen() on a fresh socket. This will create a single accept queue. Programs can share the file descriptor - pointing Continue reading

Scaling up TCP servers is usually straightforward. Most deployments start by using a single process setup. When the need arises more worker processes are added. This is a scalability model for many applications, including HTTP servers like Apache, NGINX or Lighttpd.
 CC BY-SA 2.0 image by Paul Townsend
CC BY-SA 2.0 image by Paul Townsend
Increasing the number of worker processes is a great way to overcome a single CPU core bottleneck, but opens a whole new set of problems.
There are generally three ways of designing a TCP server with regard to performance:
(a) Single listen socket, single worker process.
(b) Single listen socket, multiple worker processes.
(c) Multiple worker processes, each with separate listen socket.

(a) Single listen socket, single worker process This is the simplest model, where processing is limited to a single CPU. A single worker process is doing both accept() calls to receive the new connections and processing of the requests themselves. This model is the preferred Lighttpd setup.
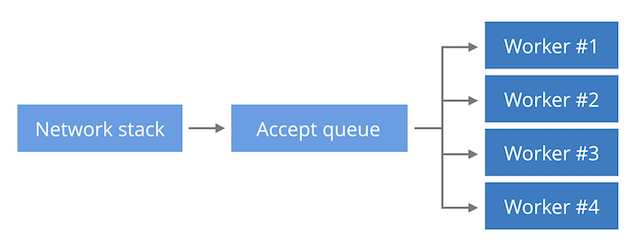
(b) Single listen socket, multiple worker process The new connections sit in a single kernel data structure (the listen socket). Multiple worker processes are doing both the accept() calls and processing of the requests. This model enables some spreading of the inbound Continue reading
In the past, we’ve spoken about how Cloudflare is architected to sustain the largest DDoS attacks. During traffic surges we spread the traffic across a very large number of edge servers. This architecture allows us to avoid having a single choke point because the traffic gets distributed externally across multiple datacenters and internally across multiple servers. We do that by employing Anycast and ECMP.

We don't use separate scrubbing boxes or specialized hardware - every one of our edge servers can perform advanced traffic filtering if the need arises. This allows us to scale up our DDoS capacity as we grow. Each of the new servers we add to our datacenters increases our maximum theoretical DDoS “scrubbing” power. It also scales down nicely - in smaller datacenters we don't have to overinvest in expensive dedicated hardware.
During normal operations our attitude to attacks is rather pragmatic. Since the inbound traffic is distributed across hundreds of servers we can survive periodic spikes and small attacks without doing anything. Vanilla Linux is remarkably resilient against unexpected network events. This is especially true since kernel 4.4 when the performance of SYN cookies was greatly improved.
But at some point, malicious traffic volume Continue reading
As opposed to the public telephone network, the internet has a Packet Switched design. But just how big can these packets be?
 CC BY 2.0 image by ajmexico, inspired by
CC BY 2.0 image by ajmexico, inspired by
This is an old question and the IPv4 RFCs answer it pretty clearly. The idea was to split the problem into two separate concerns:
What is the maximum packet size that can be handled by operating systems on both ends?
What is the maximum permitted datagram size that can be safely pushed through the physical connections between the hosts?
When a packet is too big for a physical link, an intermediate router might chop it into multiple smaller datagrams in order to make it fit. This process is called "forward" IP fragmentation and the smaller datagrams are called IP fragments1.
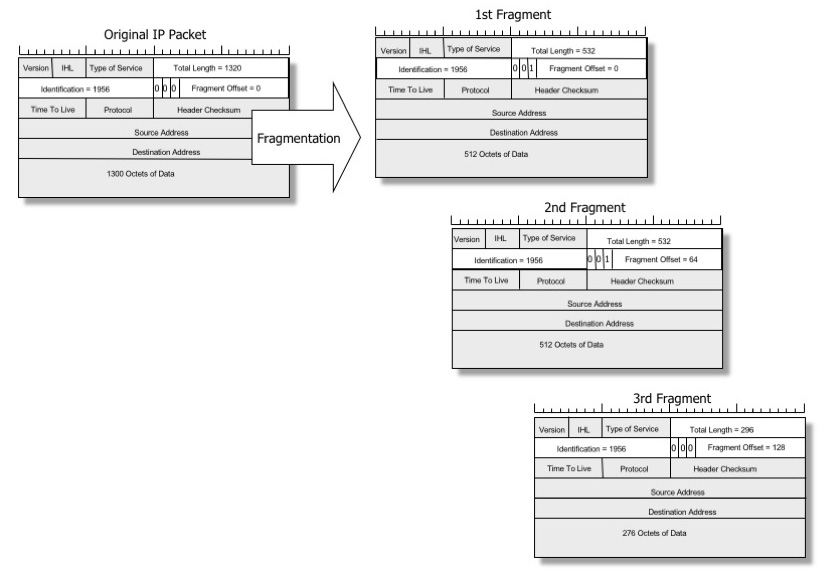 Image by Geoff Huston, reproduced with permission
Image by Geoff Huston, reproduced with permission
The IPv4 specification defines the minimal requirements. From the RFC791:
Every internet destination must be able to receive a datagram
of 576 octets either in one piece or in fragments to
be reassembled. [...]
Every internet module must be able to forward a datagram of 68
octets without further fragmentation. [...]
The first value - Continue reading
Last month we shared statistics on some popular reflection attacks. Back then the average SSDP attack size was ~12 Gbps and largest SSDP reflection we recorded was:
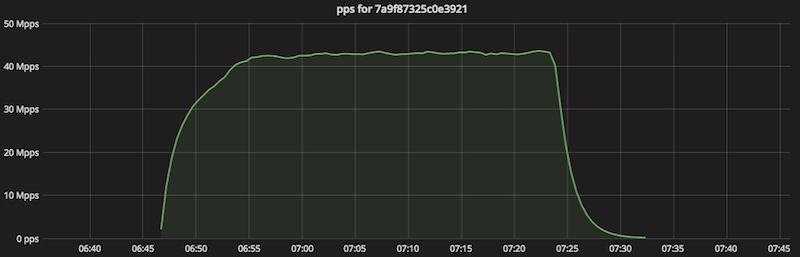
This changed a couple of days ago when we noticed an unusually large SSDP amplification. It's worth deeper investigation since it crossed the symbolic threshold of 100 Gbps.
The packets per second chart during the attack looked like this:
The bandwidth usage:

This packet flood lasted 38 minutes. According to our sampled netflow data it utilized 930k reflector servers. We estimate that the during 38 minutes of the attack each reflector sent 112k packets to Cloudflare.
The reflector servers are across the globe, with a large presence in Argentina, Russia and China. Here are the unique IPs per country:
$ cat ips-nf-ct.txt|uniq|cut -f 2|sort|uniq -c|sort -nr|head
439126 CN
135783 RU
74825 AR
51222 US
41353 TW
32850 CA
19558 MY
18962 CO
14234 BR
10824 KR
10334 UA
9103 IT
...
The reflector IP distribution across ASNs is typical. It pretty much follows the world’s largest residential ISPs:
$ cat ips-nf-asn.txt |uniq|cut -f 2|sort|uniq Continue readingRecently Akamai published an article about CLDAP reflection attacks. This got us thinking. We saw attacks from Conectionless LDAP servers back in November 2016 but totally ignored them because our systems were automatically dropping the attack traffic without any impact.
We decided to take a second look through our logs and share some statistics about reflection attacks we see regularly. In this blog post, I'll describe popular reflection attacks, explain how to defend against them and why Cloudflare and our customers are immune to most of them.

Let's start with a brief reminder on how reflection attacks (often called "amplification attacks") work.
To bake a reflection attack, the villain needs four ingredients:
The general idea:
We extensively monitor our network and use multiple systems that give us visibility including external monitoring and internal alerts when things go wrong. One of the most useful systems is Grafana that allows us to quickly create arbitrary dashboards. And a heavy user of Grafana we are: at last count we had 645 different Grafana dashboards configured in our system!
grafana=> select count(1) from dashboard;
count
-------
645
(1 row)
This post is not about our Grafana systems though. It's about something we noticed a few days ago, while looking at one of those dashboards. We noticed this:
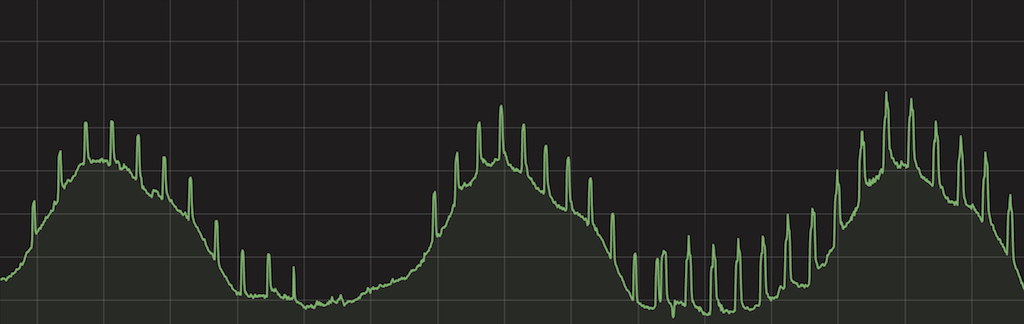
This chart shows the number of HTTP requests per second handled by our systems globally. You can clearly see multiple spikes, and this chart most definitely should not look like a porcupine! The spikes were large in scale - 500k to 1M HTTP requests per second. Something very strange was going on.
Our intuition indicated an attack - but our attack mitigation systems didn't confirm it. We'd seen no major HTTP attacks at those times.
It would be bad if we were under such heavy HTTP attack and our mitigation systems didn't notice it. Without more ideas, we Continue reading
Recent headline grabbing DDoS attacks provoked heated debates in the DNS community. Everyone has strong opinions on how to harden DNS to avoid downtime in the future. Is it better to use a single DNS provider or multiple? What DNS TTL values are best? Does DNSSEC make you more or less exposed?
 CC BY 2.0 image by Leticia Chamorro
CC BY 2.0 image by Leticia Chamorro
These are valid questions worth serious discussion, but tuning your own DNS server settings is not the full story. Together, as a community, we need to harden the DNS protocol itself. We need to prepare it to withstand the toughest DDoS attacks the future will surely bring. In this blog post I'll point out an obscure feature in the core DNS protocol. It is not practical to use this "hidden" feature for DDoS mitigation now, but with a small tweak it could become extremely useful. The feature is currently unused not due to protocol problems - it's unused because of the DNS Top Level Domain (TLD) operators' apathy. If it was working it would reduce DDoS recovery time for the DNS servers under attack.
The feature in question is: DNS TLD glue records. More specifically DNS TLD glue records with Continue reading
Over the last few weeks we've seen DDoS attacks hitting our systems that show that attackers have switched to new, large methods of bringing down web applications. They appear to come from the Mirai botnet (and relations) which were responsible for the large attacks against Brian Krebs.
Our automatic DDoS mitigation systems have been handling these attacks, but we thought it would be interesting to publish some of the details of what we are seeing. In this article we'll share data on two attacks, which are perfect examples of the new trends in DDoS.
In the past we've written extensively about volumetric DDoS attacks and how to mitigate them. The Mirai attacks are distinguished by their heavy use of L7 (i.e. HTTP) attacks as opposed to the more familiar SYN floods, ACK floods, and NTP and DNS reflection attacks.
Many DDoS mitigation systems are tuned to handle volumetric L3/4 attacks; in this instance attackers have switched to L7 attacks in an attempt to knock web applications offline.
Seeing the move towards L7 DDoS attacks we put in place a new system that recognizes and blocks these attacks as they happen. The Continue reading


.jpg){kind=link}
{kind=link}
{kind=link}