Author Archives: Rakesh M
Author Archives: Rakesh M
LLM is a technology which needs no introduction.
LLMs + Networking = Awesome!  Just dropped a playlist with the 9 key prompting bits that’ll help you organize and understand your network stuff way better. You know what to do!
Just dropped a playlist with the 9 key prompting bits that’ll help you organize and understand your network stuff way better. You know what to do!
One of the most important aspect is function calling where you can use the power of structured data and calling a specific tool to help you get the information in a right format. Let me know your thoughts.

Image – https://www.oracle.com/cloud/cloud-at-customer/dedicated-region/
Note : All opinions and writings are of my own understanding and may not represent latest or historical product development facts, please consult Oracle Documentation and Sales teams for accurate information.
Oracle’s Dedicated Region Cloud@Customer (DRCC) has emerged as a transformative solution for organisations requiring cloud capabilities within their own data centers. Recent advancements in DRCC, particularly those announced in 2024 and 2025, have introduced groundbreaking features that redefine network architecture, scalability, and edge computing. This article delves into the technical nuances of these innovations, focusing on their implications for network engineers tasked with designing, deploying, and managing hybrid and multi-cloud environments.
Oracle’s introduction of Dedicated Region25 marks a significant shift in on-premises cloud deployment. With a 75% smaller physical footprint compared to previous iterations, this configuration starts at three racks and scales incrementally, enabling organizations to deploy cloud infrastructure in constrained spaces while maintaining access to over 150 OCI services. For network engineers, this modularity necessitates a reevaluation of data center design principles.
The reduced footprint simplifies integration into existing network topologies but requires meticulous planning for Continue reading
This should summarise it all.
Colab Notebook – https://colab.research.google.com/drive/1WV6J8IqEfYbn__H2g9-hOoHqfx-YD5iA?usp=sharing
https://www.deepseek.com/ – DeepSeek has taken the AI world by storm. Their new reasoning model, which is open source, achieves results comparable to OpenAI’s O1 model but at a fraction of the cost. Many AI companies are now studying DeepSeek’s white paper to understand how they achieved this.
This post analyses reasoning capabilities from a Network Engineer’s perspective, using a simple BGP message scenario. Whether you’re new to networking or looking to refresh your reasoning skills for building networking code, DeepSeek’s model is worth exploring. The model is highly accessible – it can run on Google Colab or even a decent GPU/MacBook, thanks to DeepSeek’s focus on efficiency.
For newcomers: The model is accessed through a local endpoint, with queries and responses handled through a Python program. Think of it as a programmatic way to interact with a chat interface.
Code block
Simple code. One function block has prompt set to LLM to be a expert Network engineer. We are more interested in the thought process. The output of the block is a sample BGP output from a industry standard device, nothing fancy here.
import requests
import json
def analyze_bgp_output(device_output: str) -> str:
url = "<http://localhost:11434/api/chat>"
# Craft prompt Continue readingDr. Werner Vogels’ keynote at AWS re:Invent 2024 explores how simplicity can lead to complexity, highlighting innovations in AWS services and the importance of maintaining manageable systems.
 Simplicity breeds complexity: AWS services like S3 exemplify the journey from simple beginnings to complex systems.
Simplicity breeds complexity: AWS services like S3 exemplify the journey from simple beginnings to complex systems. The Two-Pizza Team: Small, autonomous teams enhance innovation while managing complexity effectively.
The Two-Pizza Team: Small, autonomous teams enhance innovation while managing complexity effectively. Continuous learning: Emphasis on adapting structures and processes to accommodate growth and change.
Continuous learning: Emphasis on adapting structures and processes to accommodate growth and change. Global scalability: AWS focuses on building technologies that enable businesses to expand effortlessly across regions.
Global scalability: AWS focuses on building technologies that enable businesses to expand effortlessly across regions. Importance of observability: Understanding and managing system complexity through effective monitoring and metrics.
Importance of observability: Understanding and managing system complexity through effective monitoring and metrics. Security by design: Embedding security measures from the outset to ensure robust systems.
Security by design: Embedding security measures from the outset to ensure robust systems. Community involvement: Encouraging tech professionals to support initiatives that address global challenges.
Community involvement: Encouraging tech professionals to support initiatives that address global challenges. Managing Complexity: Systems evolve over time, and complexity is inevitable. Organizations must strategically manage this complexity to avoid fragility while ensuring functionality.
Managing Complexity: Systems evolve over time, and complexity is inevitable. Organizations must strategically manage this complexity to avoid fragility while ensuring functionality. Evolvability as a Requirement: Building systems with the ability to evolve in response to user needs is essential. Flexibility in architecture allows for future changes without major disruptions.
Evolvability as a Requirement: Building systems with the ability to evolve in response to user needs is essential. Flexibility in architecture allows for future changes without major disruptions. Decoupling Systems: Breaking down monolithic systems into smaller, independently functioning components enhances Continue reading
Decoupling Systems: Breaking down monolithic systems into smaller, independently functioning components enhances Continue readingTemplating and Data Representation: Aspect of Network Automation using a tailor made AI Chatbot just to handle this scenario

In today’s exploration, we’ll dive into the fascinating world of automation frameworks and how different data formats work together to create powerful, maintainable solutions. Drawing from extensive hands-on experience, I’ll share insights into how XML, JSON, and YAML complement each other in modern automation landscapes.
The Three Pillars of Automation Data Handling
Disclaimer: All Writings And Opinions Are My Own And Are Interpreted Solely From My Understanding. Please Contact The Concerned Support Teams For A Professional Opinion, As Technology And Features Change Rapidly.
This series of blog posts will focus on one feature at a time to simplify understanding.
At this point, ChatGPT—or any Large Language Model (LLM)—needs no introduction. I’ve been exploring GPTs with relative success, and I’ve found that API interaction makes them even more effective.
But how can we turn this into a workflow, even a simple one? What are our use cases and advantages? For simplicity, we’ll use the OpenAI API rather than open-source, self-hosted LLMs like Meta’s Llama.
Let’s consider an example: searching for all OSPF-related RFCs on the web. Technically, we’ll use a popular search engine, but to do this programmatically, I’ll use Serper. You can find more details at https://serper.dev. Serper is a powerful search API that allows developers to programmatically access search engine results. It provides a simple interface to retrieve structured data from search queries, making it easier to integrate search functionality into applications and workflows.
Let’s build the first building block and try to fetch results using Serper. When you sign Continue reading
I stumbled across this tool, while am always a fan of VRNET-LAB https://github.com/vrnetlab/vrnetlab and it operates on docker containers, i could not get it properly bridge it with Local network meaning reachability to internet is something that I never worked on.
A container lab is a virtualized environment that utilises containers to create and manage network testing labs. It offers a flexible and efficient way to simulate complex network topologies, test new features, and perform various network experiments.
One striking feature that i really liked about containerlab is that representation is in a straight yaml which most of the network engineers now a days are Familiar with and its easy to edit the representation.
Other advantages

Host mappings after spinning up the lab

Slide explaining the capture process – Courtesy Petr Ankudinov (https://arista-netdevops-community.github.io/building-containerlab-with-ceos/#1)
https://containerlab.dev/quickstart/ – Will give you how to do a quick start and install containerlab.
https://github.com/topics/clab-topo – Topologies contributed by community
https://github.com/arista-netdevops-community/building-containerlab-with-ceos/tree/main?tab=readme-ov-file – Amazing Repo
https://arista-netdevops-community.github.io/building-containerlab-with-ceos/ -> This presentation has some a eVPN topology and also explain how to spin up a quick eVPN with ceos Continue reading
Disclaimer: All Writings And Opinions Are My Own And Are Interpreted Solely From My Understanding. Please Contact The Concerned Support Teams For A Professional Opinion, As Technology And Features Change Rapidly.
And No! This can’t replace the accuracy of static templating configurations. This helps us to better understand and develop the templates. This was almost rocket science to me when I first got to know about them.
Most modern day deployments have some sort of variable files and template files (YAML and Jinja2). These can be intimidating. It was mysterious. When I first looked at them years ago, I found them confusing. Today, with LLM you don’t have to really be worried about how to generate it. The parser in itself can come up on the fly to generate popular networking gear. More than that, it’s more than willing to take in the data to spit out whatever configuration is needed.

Lets say I just appreciated the way the configuration files are generated today. I wanted to quickly see if an LLM can generate the config. It also do the deployment for me. Then it helps me with some pre-checks, all without writing the code.
Let’s not go too far Continue reading

Disclaimer: All Writings And Opinions Are My Own And Are Interpreted Solely From My Understanding. Please Contact The Concerned Support Teams For A Professional Opinion, As Technology And Features Change Rapidly.
In a world where even your toaster might soon have a PhD in quantum physics, LLMs are taking over faster than a cat video going viral! LLMs are becoming increasingly powerful and are being integrated into various business and personal use cases. Networking is no different. Due to reasons like privacy, connectivity, and cost, deploying smaller form factor models or larger ones (if you can afford in-house compute) is becoming more feasible for faster inference and lower cost.
The availability and cost of model inference are improving rapidly. While OpenAI’s ChatGPT-4 is well-known, Meta and other firms are also developing LLMs that can be deployed in-house and fine-tuned for various scenarios.
Let’s explore how to deploy an open-source model in the context of coding. For beginners, ease of deployment is crucial; nothing is more off-putting than a complicated setup.
Reference : Ollama.com (https://github.com/ollama/ollama?tab=readme-ov-file) simplifies fetching a model and starting work immediately.
Visit ollama.com to understand what a codellama model looks like and what Continue reading
Disclaimer: All writings and opinions are my own and are interpreted solely from my understanding. Please contact the concerned support teams for a professional opinion, as technology and features change rapidly.
My name is Stephen King, and you are reading my novel. Absolutely Not! He is the most incredible author of all time! And you are reading my blog! One of my many, many, many interests is traffic mirroring and monitoring in public clouds, especially inter-VCN/VPC traffic. Traffic from an instance is mirrored and sent for any analysis, whether regulatory or troubleshooting. I quickly set up something in my OCI; the results and learnings are fascinating.
TLDR: Traffic Mirroring and Monitoring in Oracle OCI using VTAPs

Topology and a refresher

IGW helps us connect to the Internet, NLB helps us send traffic to VTAP-HOST mirrored from VTAP, and a DRG helps us communicate with other VCNs.
What is the end goal? Mirror and send all the traffic from Host-1 with IP 192.168.1.6 to VTAP-Host for further analysis.
Below is generated by OCI Network Visualiser, which is very cool.

A few things Continue reading
Disclaimer: All writings and opinions are my own and are interpreted solely from my understanding. Please contact the concerned support teams for a professional opinion, as technology and features change rapidly.
Topics Discussed: DRCCs Intro and OCI Cloud Regional Subnet
Spoiler alert: This involves an on-premises cloud for customers offered by Oracle. All offerings for cloud@customer by Oracle can be viewed at https://www.oracle.com/cloud/cloud-at-customer/
Dedicate Region Cloud @Customer – DRCC

Ref: https://www.oracle.com/cloud/cloud-at-customer/dedicated-region/#rc30category-documentation
Before understanding DRCC, let’s consider the scope of improvement on customer premises with their own Data Center and what it tries to solve. Fair? Let’s imagine I have my own data centre. Great! My infrastructure supports some of my workloads, but how do I get the latest technology stack, support, and services that the public cloud offers?
For example, how can someone leverage all these services without having to invest in development cycles yet meet latency/integration/data security and multiple other requirements?

Ref: https://www.oracle.com/cloud/
| Scope of improvement on customer premises | Oracle Dedicated Region Cloud at Customer Solutions |
| Data Security and Compliance Concerns | Provides a fully managed cloud region in the customer’s datacenter, ensuring data sovereignty and compliance with local regulations. |
| Latency Continue reading |
This post is a bit different from my usual networking content. I won’t be discussing power grid inefficiencies or pollution. After learning some principles from permaculture, an ethical design science focused on life, it’s more of a personal reflection. I’m concerned about our society’s reliance on non-producing, ever-consuming and our mindset to depend on external producers. Even simple things that can be eliminated or produced without much effort have become needlessly complex, creating unnecessary consumption, erasing the human spark to make or say no to mindless consumerism, and creating vast dump yards. We used to be producers but have become ultimate consumers of life’s simple things.

TLDR: It’s not about affordability or money; I think everyone here can afford spinach or charge their devices happily, paying a service provider; the question is, why are we dependent on external grids and super-stores for simple things in life that were free at one point of time in our society, over consumerism, isolated and end up creating our own silo kingdoms?
Why did it make sense to me?
At a very high level, we all know that the climatic changes and food production, in general, have affected the topsoil so much that Continue reading
It has been quite some time since my last blog post. The past few months have been busy, leaving little time to write. I am happy to share that I have started working as a site-reliability developer at Oracle. While it has only been a short while, I am enjoying the work.
Reflecting on the past year, I am happy to say it has been productive overall. I have had the opportunity to collaborate with various networking and software teams, which has taught me a lot about high-scale traffic patterns and migrations. Working in an operations role has been beneficial since it requires constant fire-fighting and documentation for improvements. This has made me more aware of traffic patterns and ways to improve reliability.
What can be improved?
However, I could benefit from more study on the software architecture and distributed system design parameters from a business perspective. I want to write more this year; the first half was better, but lacked in the second half, where most of the writing was private.
From a personal standpoint, 2024 needs more travel absolutely and some improvements in garden automation for summer 2024
Other updates
Finally, I have been working on some JNCIA-Devops Continue reading
< MEDIUM :https://towardsaws.com/aws-advanced-networking-speciality-1-3-considerations-402e0d057dfb >
List of blogs on AWS Advanced Networking Speciality Exam — https://medium.com/@raaki-88/list/aws-advanced-network-speciality-24009c3d8474

AWS Shared-Responsibility Model defines how data protection applies in ELBs. It boils down to AWS protecting global infrastructure while the service consumer is more responsible for preserving the content and control over the hosted content.
Few important suggestions for accessing/Securing
Encryption at rest: Server-side encryption for S3 (SSE-S3) is used for ELB access logs. ELB automatically encrypts each log file before storing it in the S3 bucket and decrypts the access log files when you access them. Each log file is encrypted with a unique key, which is encrypted with a master key that is regularly rotated.
Encryption in Transit:
HTTPS/TLS traffic can be terminated at the ELB. ELB can encrypt and decrypt the traffic instead of additional EC2 instances or current EC2 backend instances doing this TLS termination. Using ACM (AWS Certificate Continue reading
List of blogs on AWS Advanced Networking Speciality Exam — https://medium.com/@raaki-88/list/aws-advanced-network-speciality-24009c3d8474

Before understanding LoadBalancer Service, it’s worth understanding a few things about NodePort service.
NodePort service opens a port on each node. External agents can connect directly to the node on the NodePort. If not mentioned, a randomly chosen service is picked up for NodePort. LoadBalancing here is managed by front-end service, which listens to a port and load balances across the Pods, which responds to service requests.


Like NodePort Service, the LoadBalancer service extends the functionality by adding a load balancer in front of all the nodes. Kubernetes requests ELB and registers all the nodes. It’s worth noting that Load Balancer will not detect where the pods are running. Worker nodes are added as backend instances in the load balancer. The classic-load balancer is the default LB the service chooses and can be changed to NLB(Network Load Balancer). CLB routes the requests to Front-end, then to internal service ports Continue reading
<MEDIUM : https://towardsaws.com/aws-advanced-networking-speciality-1-3-5484de6c8da >
A Target group routes requests to one or more registered targets. They can be EC2 Instances, IP addresses, Kubernetes Cluster, Lambda Functions etc. Target groups are specified when you create a listener rule. You can also define various health checks and associate them with each target-groups.


What is Geneve, and what is the context with ELB: Generic Network Virtualisation Encapsulation
In the context of Gateway Load Balancer, a flow can be associated with either 5-Tuple or 3-Tuple.A flow can be associated with either a 5-tuple or 3-tuple flow in load balancers.
A 5-tuple flow includes the source IP address, destination IP address, source port, destination port, and protocol number. This is used for TCP, UDP, and SCTP protocols.
A 3-tuple flow includes the source IP address, destination IP address, and protocol number. This is used for ICMP and ICMPv6 protocols.
Gateway Load balancers and their registered virtual appliances use GENEVE protocol to exchange application traffic on port 6081

References :
https://docs.aws.amazon.com/elasticloadbalancing/latest/application/introduction.html
https://datatracker.ietf.org/doc/html/rfc8926 Continue reading
< MEDIUM : https://raaki-88.medium.com/aws-advanced-networking-speciality-1-3-deedc0217ea6 >
Advanced Network Speciality Exam — Blogs
https://medium.com/@raaki-88/list/aws-advanced-network-speciality-24009c3d8474
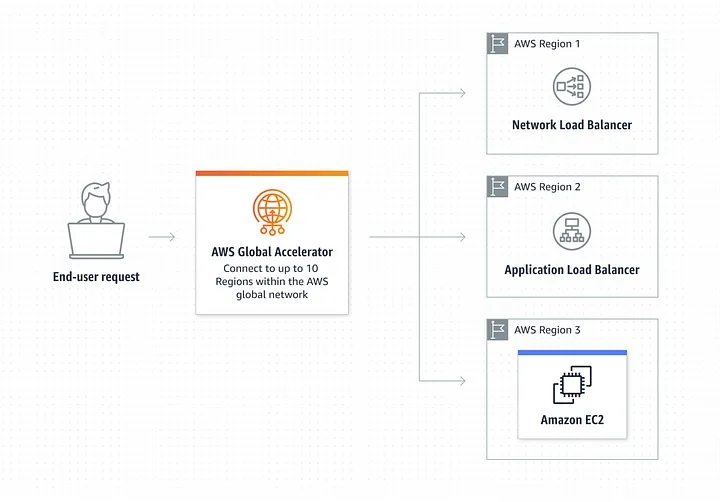
Global Accelerator — A service that provides static ip addresses with your accelerator. These IP addresses are Anycast from the AWS edge network, meaning the global accelerator diverts your application’s traffic to the nearest region to the client.
Two types of Global Accelerators — Standard Accelerators and Custom Routing accelerators.
Standard Accelerators uses aws global network to route traffic to the optimal regional endpoint based on health, client location and policies that the user configures, increasing availability and decreasing latency to the end users. Standard-accelerator endpoints can be Network Load balancers, Application load balancers from load balancing context. Custom routing accelerators do not support load balancer endpoints as of today.
When using accelerators and Load-balancers, update DNS records so that application traffic uses accelerator end-point, redirecting the traffic to load-balancer endpoints.
When using an application load balancer in ELB, cloud-front meant to cache the objects can reduce the load on ALBs and improve performance. CF can also protect ALB and internal services from DDOS attacks, as with AWS WAF. But for this to succeed, administrators Continue reading
< MEDIUM: https://raaki-88.medium.com/aws-advanced-networking-speciality-1-3-23eb011b74df >
Previous posts :
https://towardsaws.com/aws-advanced-networking-task-statement-1-3-c457fa0ed893
https://raaki-88.medium.com/aws-advanced-networking-speciality-1-3-3ffe2a43e2f3
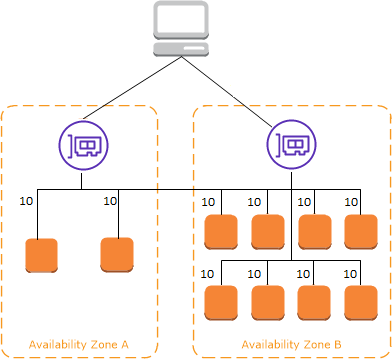
Internal ELB — An internal Load balancer is not exposed to the internet and is deployed in a private subnet. A DNS record gets created, which will have a private-IP address of the load-balancer. It’s worth noting to know DNS records will be publicly resolvable. The main intention is to distribute traffic to EC2 instances. Across availability zones, provided all of them have access to VPCs.
External ELB — Also called an Internet-Facing Load Balancer and deployed in the Public subnet. Similar to Internal ELB, this can also be used to distribute and balance traffic across two availability zones.
Example Architecture Reference — https://docs.aws.amazon.com/prescriptive-guidance/latest/patterns/deploy-an-amazon-api-gateway-api-on-an-internal-website-using-private-endpoints-and-an-application-load-balancer.html?did=pg_card&trk=pg_card
– Rakesh
< MEDIUM: https://raaki-88.medium.com/aws-advanced-networking-speciality-1-3-3ffe2a43e2f3 >
https://medium.com/towards-aws/aws-advanced-networking-task-statement-1-3-c457fa0ed893 — Has intro details for the speciality exam topic

Different types of Load-Balancers
High Availability Aspect: ELB (Can be any load-balancing) can distribute traffic across various different targets, including EC2-Instances, Containers, and IP addresses in either a single AZ or multiple AZs within a region.

Health Checks: An additional health check can be included to ensure that the end hos serving the application is healthy. This is typically done through HTTP status codes, with a return value 200 indicating a healthy host. If discrepancies are found during the health check, the ELB can gracefully drain traffic and divert it to another host in the target group. If auto-scaling is set up, it can also auto-scale as needed.
Network Design: Depending on the type of traffic and Application traffic pattern, the load and burst-rate choice of load-balancer will differ.
Various Features — High-Availability, High-Throughput, Health-Checks, Sticky-Sessions, Operational-Monitoring and Logging, Delete-Protection.
TLS Termination — You can also have integrated certificate management and SSL decryption which offloads end-host CPU load and acts as a central Continue reading

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}