Author Archives: Todd Hoff
Author Archives: Todd Hoff

This is a guest repost by Bryan Helmig, Co-founder & CTO at Zapier, who makes it easy to automate tasks between web apps.

Zapier is a web service that automates data flow between over 500 web apps, including MailChimp, Salesforce, GitHub, Trello and many more.
Imagine building a workflow (or a "Zap" as we call it) that triggers when a user fills out your Typeform form, then automatically creates an event on your Google Calendar, sends a Slack notification and finishes up by adding a row to a Google Sheets spreadsheet. That's Zapier. Building Zaps like this is very easy, even for non-technical users, and is infinitely customizable.
As CTO and co-founder, I built much of the original core system, and today lead the engineering team. I'd like to take you on a journey through our stack, how we built it and how we're still improving it today!
It takes a lot to make Zapier tick, so we have four distinct teams in engineering:

This is a guest repost by Barzan Mozafari, who is part of a new startup, www.snappydata.io, that recently launched an open source OLTP + OLAP Database built on Spark.
The growing market for Big Data has created a lot of interest around approximate query processing (AQP) as a means of achieving interactive response times (e.g., sub-second latencies) when faced with terabytes and petabytes of data. At the same time, there is a lot of misinformation about this technology and what it can or cannot do.
Having been involved in building a few academic prototypes and industrial engines for approximate query processing, I have heard many interesting statements about AQP and/or sampling techniques (from both DB vendors and end-users):
Myth #1. Sampling is only useful when you know your queries in advance
Myth #2. Sampling misses out on rare events or outliers in the data
Myth #3. AQP systems cannot handle join queries
Myth #4. It is hard for end-users to use approximate answers
Myth #5. Sampling is just like indexing
Myth #6. Sampling will break the BI tools
Myth #7. There is no point approximating if your data fits in memory
Although there is a Continue reading
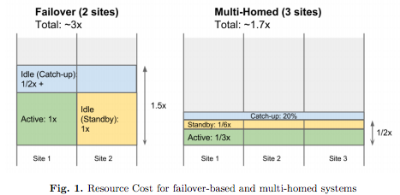
Making a system work in one datacenter is hard. Now imagine you move to two datacenters. Now imagine you need to support multiple geographically distributed datacenters. That’s the journey described in another excellent and thought provoking paper from Google: High-Availability at Massive Scale: Building Google’s Data Infrastructure for Ads.
The main idea of the paper is that the typical failover architecture used when moving from a single datacenter to multiple datacenters doesn’t work well in practice. What does work, where work means using fewer resources while providing high availability and consistency, is a natively multihomed architecture:
Our current approach is to build natively multihomed systems. Such systems run hot in multiple datacenters all the time, and adaptively move load between datacenters, with the ability to handle outages of any scale completely transparently. Additionally, planned datacenter outages and maintenance events are completely transparent, causing minimal disruption to the operational systems. In the past, such events required labor-intensive efforts to move operational systems from one datacenter to another
The use of “multihoming” in this context may be confusing because multihoming usually refers to a computer connected to more than one network. At Google scale perhaps it’s just as natural Continue reading
This is a guest post by Kalpesh Patel, an Architect, who works from home. He and his colleagues spends their productive hours scaling one of the largest distributed file-system out there. He works at Egnyte, an Enterprise File Synchronization Sharing and Analytics startup and you can reach him at @kpatelwork.
Your Laptop has a filesystem used by hundreds of processes, it is limited by the disk space, it can’t expand storage elastically, it chokes if you run few I/O intensive processes or try sharing it with 100 other users. Now take this problem and magnify it to a file-system used by millions of paid users spread across world and you get a roller coaster ride scaling the system to meet monthly growth needs and meeting SLA requirements.
Egnyte is an Enterprise File Synchronization and Sharing startup founded in 2007, when Google drive wasn't born and AWS S3 was cost prohibitive. Our only option was to roll our sleeves and build an object store ourselves, overtime costs for S3 and GCS became reasonable and because our storage layer was based on a plugin architecture, we can now plug-in any storage backend that is cheaper. We have re-architected many of Continue reading
In a fragmented world of hospitality systems, integration is a necessity. Your system will need to interact with different systems from different providers, each providing its own Application Program Interface (API). Not only that, but as you integrate with more hotel customers, the more instances you will need to connect and manage this connection. A Property Management System (PMS) is the core system of any hotel and integration is paramount as the industry moves to become more connected.
To provide software solutions in the hospitality industry, you will certainly need to establish a 2-way integration with the PMS providers. The challenge is building and managing these connections at scale, with multiple PMS instances across multiple hotels. There are several approaches you can leverage to implement these integrations. Here, I present one simple architectural design to building an integration foundation that will increase ROI as you grow. This approach is the use of microservices.

Since Parse's big announcement it looks like the release of migration guides from various alternative services has died down.
The biggest surprise is the rise of Parse's own open source Parse Server. Check out its commit velocity on GitHub. It seems to be on its way to becoming a vibrant and viable platform.
The immediate release of Parse Server with the announcement of the closing of Parse was surprising. How could it be out so soon? That's a lot of work. Some options came to mind. Maybe it's a version of an on-premise system they already had in the works? Maybe it's a version of the simulation software they use for internal testing? Or maybe they had enough advanced notice they could make an open source version of Parse?
The winner is...
Charity Majors, formerly of Parse/Facebook, says in How to Survive an Acquisition, tells all:
Massive props to Kevin Lacker and those who saw the writing on the wall and did an amazing job preparing to open up the ecosystem.
That's impressive. It seems clear the folks at Parse weren't on board with Facebook's decision, but they certainly did everything possible to make the best Continue reading
What’s next? Mobile is entering its comforting middle age period of development. Conversational commerce is a thing, a good thing, but is it really a great thing?
What’s next may be what has been next for decades: Augmented reality (AR) (and VR). AR systems will be here sooner than you might think. A matter of years, not decades. Robert Scoble, for example, thinks Meta, an early startup in AR industry, will be bigger than the Macintosh. More on that in a later post. Magic Leap has no product and $1.3 billion in funding. Facebook has Oculus. Microsoft has HoloLens. Google may be releasing a VR system later this year. Apple is working on VR. Becoming the next iPhone is up for grabs.
This is a technological revolution that will be bigger than mobile. Opportunities in mobile for developers have largely played out. Experience shows the earlier you get in on a revolution the better the opportunity will be. Do you want to be writing free iOS apps forever?
It’s so early we don’t really have an idea what AR is or what the market will be Continue reading
Parse is dead. The great diaspora has begun. The gold rush is on. There’s a huge opportunity for some to feed and grow on Parse’s 600,000 fleeing customers.
Where should you go? What should you do? By now you’ve transitioned through all five stages of grief and ready for stage six: doing something about it. Fortunately there are a lot of options and I’ve gathered as many resources as I can here in one place.
Parse closing is a bigger deal than most shutterings. There’s even a petition: Don't Shut down Parse.com. That doesn’t happen unless you’ve managed to touch people. What could account for such an outpouring of emotion.
Parse and the massive switch to mobile computing grew up at the same time. Mobile is by definition personal. Many programmers capable of handling UI programming challenge were not as experienced with backend programming and Parse filled that void. When a childhood friend you grew to depend on dies, it hurts. That hurt is deep. It goes into the very Continue reading
 Patreon recently snagged $30 Million in funding. It seems the model of pledging $1 for individual feature releases or code changes won't support fast enough growth. CEO Jack Conte says: We need to bring in so many people so fast. We need to keep up with hiring and keep up with making all of the things.
Patreon recently snagged $30 Million in funding. It seems the model of pledging $1 for individual feature releases or code changes won't support fast enough growth. CEO Jack Conte says: We need to bring in so many people so fast. We need to keep up with hiring and keep up with making all of the things.
Since HighScalability is giving Patreon a try I've naturally wondered how it's built. Modulo some serious security issues Patreon has always worked well. So I was interested to dig up this nugget in a thread on the funding round where the Director of Engineering at Patreon shares a little about how Patreon works:
Hey, it's HighScalability time:

We've heard a lot about the Netflix recommendation algorithm for movies, how Amazon matches you with stuff, and Google's infamous PageRank for search. How about Tinder? It turns out Tinder has a surprisingly thoughtful recommendation system for matching people.
This is from an extensive profile, Mr. (Swipe) Right?, on Tinder founder Sean Rad:
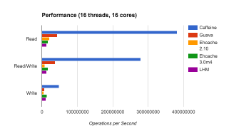
This is a guest post by Benjamin Manes, who did engineery things for Google and is now doing engineery things for a new load documentation startup, LoadDocs.
Caching is a common approach for improving performance, yet most implementations use strictly classical techniques. In this article we will explore the modern methods used by Caffeine, an open-source Java caching library, that yield high hit rates and excellent concurrency. These ideas can be translated to your favorite language and hopefully some readers will be inspired to do just that.
A cache’s eviction policy tries to predict which entries are most likely to be used again in the near future, thereby maximizing the hit ratio. The Least Recently Used (LRU) policy is perhaps the most popular due to its simplicity, good runtime performance, and a decent hit rate in common workloads. Its ability to predict the future is limited to the history of the entries residing in the cache, preferring to give the last access the highest priority by guessing that it is the most likely to be reused again soon...
Hey, it's HighScalability time:

Unikernel Systems Joins Docker. Now this is an interesting match. The themes are security and low overhead, though they do seem to solve the same sort of problem.
So, what's going on?
In FLOSS WEEKLY 302 Open Mirage, starting at about 10 minutes in, there are a series of possible clues. Dr. Anil Madhavapeddy, former CTO of Unikernel Systems, explains their motivation behind the creation of unikernels. And it's a huge and exciting vision...