Author Archives: Todd Hoff
Author Archives: Todd Hoff

This is a guest repost of an interview posted by Ryan S. Brown that originally appeared on serverlesscode.com. It continues our exploration of building systems on top of Lambda.
Paging David Guetta fans: this week we have an interview with the team that built the site behind his latest ad campaign. On the site, fans can record themselves singing along to his single, “This One’s For You” and build an album cover to go with it.
Under the hood, the site is built on Lambda, API Gateway, and CloudFront. Social campaigns tend to be pretty spiky – when there’s a lot of press a stampede of users can bring infrastructure to a crawl if you’re not ready for it. The team at parall.ax chose Lambda because there are no long-lived servers, and they could offload all the work of scaling their app up and down with demand to Amazon.
James Hall from parall.ax is going to tell us how they built an internationalized app that can handle any level of demand from nothing in just six weeks.

Hey, it's HighScalability time:
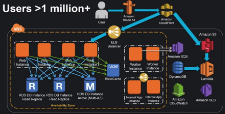
How do you scale a system from one user to more than 11 million users? Joel Williams, Amazon Web Services Solutions Architect, gives an excellent talk on just that subject: AWS re:Invent 2015 Scaling Up to Your First 10 Million Users.
If you are an advanced AWS user this talk is not for you, but it’s a great way to get started if you are new to AWS, new to the cloud, or if you haven’t kept up with with constant stream of new features Amazon keeps pumping out.
As you might expect since this is a talk by Amazon that Amazon services are always front and center as the solution to any problem. Their platform play is impressive and instructive. It's obvious by how the pieces all fit together Amazon has done a great job of mapping out what users need and then making sure they have a product in that space.
Some of the interesting takeaways:
I'm all green (hot patch)
Called a Penguin and Chameleon
I'm all green (hot patch)
Call Torvalds and Kroah-Hartman
It’s too hot (hot patch)
Yo, say my name you know who I am
It’s too hot (hot patch)
I ain't no simple code monkey
Nuthin's down
Hey, it's HighScalability time:

There’s a long history of donating spare compute cycles for worthy causes. Most of those efforts were started in the Desktop Age. Now, in the Cloud Age, how can we donate spare compute capacity? How about through a private spot market?
There are cycles to spare. Public Cloud Usage trends:
Instances are underutilized with average utilization rates between 8-9%
24% of instance reservations are unused
Maybe all that CapEx sunk into Reserved Instances can be put to some use? Maybe over provisioned instances could be added to the resource pool as well? That’s a lot of power Captain. How could it be put to good use?
There is a need to crunch data. For science. Here’s a great example as described in This is how you count all the trees on Earth. The idea is simple: from satellite pictures count the number of trees. It’s an embarrassingly parallel problem, perfect for the cloud. NASA had a problem. Their cloud is embarrassingly tiny. 400 hypervisors shared amongst many projects. Analysing all the data would would take 10 months. An unthinkable amount of time in this Real-time Age. So they used the spot market on AWS.
The upshot? The test run cost Continue reading

Chapter by chapter Sergey Ignatchenko is putting together a wonderful book on the Development and Deployment of Massively Multiplayer Games, though it has much broader applicability than games. Here's a recent chapter from his book.
[Enter Juliet]
Hamlet:
Thou art as sweet as the sum of the sum of Romeo and his horse and his black cat! Speak thy mind!
[Exit Juliet]

Our Classical Deployment Architecture (especially if you do use FSMs) is not bad, and it will work, but there is still quite a bit of room for improvement for most of the games out there. More specifically, we can add another row of servers in front of the Game Servers, as shown on Fig VI.8:
Hey, Happy New Year, it's HighScalability time:
Hey, it's HighScalability time:


A great question came up on the mechanical-sympathy list that many others probably have as well:
I keep hearing about [Docker] as if it is the greatest thing since sliced bread, but I've heard anecdotal evidence that low latency apps take a hit.
Who better to answer than Gil Tene, Vice President of Technology and CTO, Co-Founder, of Azul Systems? Like Stephen Curry draining a deep transition three, Gil can always be counted on for his insight:
And here's Gil's answer:
Putting aside questions of taste and style, and focusing on the effects on latency (the original question), the analysis from a pure mechanical point of view is pretty simple: Docker uses Linux containers as a means of execution, with no OS virtualization layer for CPU and memory, and with optional (even if default is on) virtualization layers for i/o.
From a latency point of view, Docker's (and any other Linux container's) CPU and memory latency characteristics are pretty much indistinguishable from Linux itself. But the same things Continue reading

When AMP (Accelerated Mobile Pages) was first announced it was right inline with Google’s long standing project to make the web faster. Nothing seemingly out of the ordinary.
Then I listened to a great interview on This Week in Google with Richard Gingras, Head of News at Google, that made it clear AMP is more than just another forward looking initiative from Google. Much more.
What is AMP? AMP is two things. AMP is a restricted subset of HTML designed to make the web fast on mobile devices. AMP is also a strategy to counter an existential threat to Google: the mobile web is in trouble and if the mobile web is in trouble then Google is in trouble.
In the interview Richard says (approximately):
The alternative [to a strong vibrant community around AMP] is devastating. We don’t want to see a decline in the viability of the mobile web. We don’t want to see poor experiences on the mobile web propel users into proprietary platforms.
This point, or something very like it, is repeated many times during the interview. With ad blocker usage on the rise there’s a palpable sense of urgency to do something. So Google stepped Continue reading
Hey, it's HighScalability time:

For the first time in ten years there has been an update to the classic Red Book, Readings in Database Systems, which offers "readers an opinionated take on both classic and cutting-edge research in the field of data management."
Editors Peter Bailis, Joseph M. Hellerstein, and Michael Stonebraker curated the papers and wrote pithy introductions. Unfortunately, links to the papers are not included, but a kindly wizard, Nindalf, gathered all the referenced papers together and put them in one place.
What's in it?
![]()
This is a guest post by Marcel Panse and Sander Nagtegaal from Teletext.io.
In our early Peecho days, we wrote an article explaining how to build a really scalable architecture for next to nothing, using Amazon Web Services. Auto-scaling, merciless decoupling and even automated bidding on unused server capacity were the tricks we used back then to operate on a shoestring. Now, it is time to take it one step further.
We would like to introduce Teletext.io, also known as the serverless start-up - again, entirely built around AWS, but leveraging only the Amazon API Gateway, Lambda functions, DynamoDb, S3 and Cloudfront.
We like rules. At our previous start-up Peecho, product owners had to do fifty push-ups as payment for each user story that they wanted to add to an ongoing sprint. Now, at our current company myTomorrows, our developer dance-offs are legendary: during the daily stand-ups, you are only allowed to speak while dancing - leading to the most efficient meetings ever.
This way of thinking goes all the way into our product development. It may seem counter-intuitive at first, but constraints fuel creativity. For example, all Continue reading
Hey, it's HighScalability time:
When you look at large scale systems from Google, Twitter, eBay, and Amazon, their architecture has evolved into something similar: a set of polyglot microservices.
What does it looks like when you are in the polyglot microservices end state? Randy Shoup, who worked in high level positions at both Google and eBay, has a very interesting talk exploring just that idea: Service Architectures at Scale: Lessons from Google and eBay.
What I really like about Randy's talk is how he is self-consciously trying to immerse you in the experience of something you probably have no experience of: creating, using, perpetuating, and protecting a large scale architecture.
In the Ecosystem of Services section of the talk Randy asks: What does it look like to have a large scale ecosystem of polyglot microservices? In the Operating Services at Scale section he asks: As a service provider what does it feel like to operate such a service? In the Building a Service section he asks: When you are a service owner what does it look like? And in the Service Anti-Patterns section he asks: What can go wrong?
A very powerful approach.
The highlight of the talk for me was the idea of Continue reading
Hey, it's HighScalability time: