Author Archives: Todd Hoff
Author Archives: Todd Hoff

For a long time now stateless services have been the royal road to scalability. Nearly every treatise on scalability declares statelessness as the best practices approved method for building scalable systems. A stateless architecture is easy to scale horizontally and only requires simple round-robin load balancing.
What’s not to love? Perhaps the increased latency from the roundtrips to the database. Or maybe the complexity of the caching layer required to hide database latency problems. Or even the troublesome consistency issues.
But what of stateful services? Isn’t preserving identity by shipping functions to data instead of shipping data to functions a better approach? It often is, but we don’t hear much about how to build stateful services. In fact, do a search and there’s very little in the way of a systematic approach to building stateful services. Wikipedia doesn’t even have an entry for stateful service.
Caitie McCaffrey, Tech Lead for Observability at Twitter, is fixing all that with a refreshing talk she gave at the Strange Loop conference on Building Scalable Stateful Services (slides).
Refreshing because I’ve never quite heard of building stateful services in the way Caitie talks about building them. You’ll recognize most of the Continue reading
Hey, it's HighScalability time:

Here's an interesting nugget from a wonderfully written and deeply interesting article by Roger Hodge in the New Republic: A radical experiment at Zappos to end the office workplace as we know it:
Zappos's customer-facing web site has been basically frozen for the last few years while the company migrates its backend systems to Amazon's platforms, a multiyear project known as Supercloud.
It's a testament to Zappos that they still sell well with a frozen website while most of the rest of the world has adopted a model of continuous deployment and constant evolution across multiple platforms.
Amazon is requiring the move, otherwise a company like Zappos would probably be sensitive to the Conway's law implication of such a deep integration. Keep in mind Facebook is reportedly keeping WhatsApp and Instagram independent. This stop the world plan must mean something, unfortunately I don't have the strategic insight to understand why this might be. Any thoughts?
The article has more tantalizing details about what's going on with the move:

Pretty much all your load generation and monitoring tools do not work correctly. Those charts you thought were full of relevant information about how your system is performing are really just telling you a lie. Your sensory inputs are being jammed.
To find out how listen to the Morpheous of performance monitoring Gil Tene, CTO and co-founder at Azul Systems, makers of truly high performance JVMs, in a mesmerizing talk on How NOT to Measure Latency.
This talk is about removing the wool from your eyes. It's the red pill option for what you thought you were testing with load generators.
Some highlights:
If you want to hide the truth from someone show them a chart of all normal traffic with one just one bad spike surging into 95 percentile territory.
The number one indicator you should never get rid of is the maximum value. That’s not noise, it’s the signal, the rest is noise.
99% of users experience ~99.995%’ile response times, so why are you even looking at 95%'ile numbers?
Monitoring tools routinely drop important samples in the result set, leading you to draw really bad conclusions about the quality of the performance of Continue reading
Hey, it's HighScalability time:


When nanoseconds matter you have to pay attention to OS scheduling details. Mark Price, who works in the rarified high performance environment of high finance, shows how in his excellent article on Reducing system jitter.
For a tuning example he uses the famous Disrupter inter-thread messaging library. The goal is to keep the OS continuously feeding CPUs work from high priority threads. His baseline test shows the fastest message is sent in 76 nanoseconds, 1 in 100 messages took longer than 2 milliseconds, and the longest delay was 11 milliseconds.
The next section of the article shows in loving detail how to bring those latencies lower and more consistent, a job many people will need to do in practice. You'll want to read the article for a full explanation, including how to use perf_events and HdrHistogram. It's really great at showing the process, but in short:
In a disaster there’s a raw and immediate need to know your loved ones are safe. I felt this way during 9/11. I know I’ll feel this way during the next wild fire in our area. And I vividly remember feeling this way during the 1989 Loma Prieta earthquake.
Most earthquakes pass beneath notice. Not this one and everyone knew it. After ceiling tiles stopped falling like snowflakes in the computer lab, we convinced ourselves the building would not collapse, and all thoughts turned to the safety of loved ones. As it must have for everyone else. Making an outgoing call was nearly impossible, all the phone lines were busy as calls poured into the Bay Area from all over the nation. Information was stuck. Many tense hours were spent in ignorance as the TV showed a constant stream of death and destruction.
It’s over a quarter of a century later, can we do any better?
Facebook can. Through a product called Safety Check, which connects friends and loved ones during a disaster. When a disaster hits Safety Check prompts people in the area to indicate if they are OK or not. Then Facebook closes the worry loop by Continue reading
Hey, it's HighScalability time:


This is a guest post by Yiftach Shoolman, Co-founder & CTO of redislabs. Will 3D XPoint change everything? Not as much as you might hope...
Recently, investors, analysts, partners and customers have asked me how the announcement from Intel and Micron about their new 3D XPoint memory technology will affect the in-memory databases market. In these discussions, a common question was “Who needs an in-memory database if all the non in-memory databases will achieve similar performance with 3D XPoint technology?” Well, I think that's a valid question so I've decided to take a moment to describe how we think this technology will influence our market.
First, a little background...
The motivation of Intel and Micron is clear -- DRAM is expensive and hasn’t changed much during the last few years (as shown below). In addition, there are currently only three major makers of DRAM on the planet (Samsung Electronics, Micron and SK Hynix), which means that the competition between them is not as cutthroat as it used to be between four and five major manufacturers several years ago.
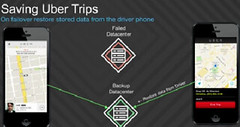
In How Uber Scales Their Real-Time Market Platform one of the most intriguing hints was how Uber handles datacenter failovers using driver phones as an external distributed storage system for recovery.
Now we know a lot more about how that system works from Uber's Nikunj Aggarwal and Joshua Corbin, who gave a very interesting talk at the @Scale conference: How Uber Uses your Phone as a Backup Datacenter.
Rather than use a traditional backend replication scheme where databases sync state between datacenters to achieve a measure of k-safety, Uber did something different, what they do is store enough state on driver phones so that if a datacenter failover occurs trip information can not be lost on the failover.
Why choose this approach? The traditional approach would be much simpler. I think it is to make sure the customer always has a good customer experience and losing trip information for an active trip would make for a horrible customer experience.
By building their syncing strategy around the phone, even thought it's complicated and takes a lot work, Uber is able to preserve trip data and make for a seamless customer experience even on datacenter failures. And making the customer Continue reading
Hey, it's HighScalability time:

Reportedly Uber has grown an astonishing 38 times bigger in just four years. Now, for what I think is the first time, Matt Ranney, Chief Systems Architect at Uber, in a very interesting and detailed talk--Scaling Uber's Real-time Market Platform---tells us a lot about how Uber’s software works.
If you are interested in Surge pricing, that’s not covered in the talk. We do learn about Uber’s dispatch system, how they implement geospatial indexing, how they scale their system, how they implement high availability, and how they handle failure, including the surprising way they handle datacenter failures using driver phones as an external distributed storage system for recovery.
The overall impression of the talk is one of very rapid growth. Many of the architectural choices they’ve made are a consequence of growing so fast and trying to empower recently assembled teams to move as quickly as possible. A lot of technology has been used on the backend because their major goal has been for teams to get the engineering velocity as high as possible.
After a understandably chaotic (and very successful) start it seems Uber has learned a lot about their business and what they really need to Continue reading
Hey, it's HighScalability time:

Very early in my web career I was introduced to the almost mystical holy grail of web (and now app) properties: increasing user engagement.
The reason is simple. The more time people spend with your property the more stuff you can sell them. The more stuff you can sell the more value you have. Your time is money. So we design for addiction.
Famously Facebook, through the ties that bind, is the engagement leader with U.S. adults spending a stunning average of 42.1 minutes per day on Facebook. Cha-ching.
Immense resources are spent trying to make websites and apps sticky. Psychological tricks and gamification strategies are deployed with abandon to get you not to leave a website or to keep playing an app.
It turns out this is a very old idea. Casinos are designed to keep you gambling, for example. And though I’d never really thought about it before, I shouldn’t have been surprised to learn retail stores of yore used devices called trade stimulators to keep customers hanging around and spending money.
Never heard of trade stimulators? I hadn’t either until, while watching American Pickers, one of my favorite shows, they talked about this whole Continue reading
I serendipitously found this fascinating reply by Richard Farley, your friendly neighborhood meter reader, in a local email list giving a rare first-hand account of how the Advanced Metering Infrastructure works in California. This is real Internet of Things territory. So if it doesn't have a typical post structure that is why. He generously allowed it to be reposted with a few redactions. When you see “A Major US Utility”, please replace it with the most likely California power company.
Old mechanical meters had bearings that over time wore out and caused friction that threw off readings. That friction would cause the analog gauge to spin slower than it should, resulting in lower readings than actual usage -- hence "free power". It's like a clock falling behind over time as the gears wear down.
For A Major US Utility "estimated billing" happens when your meter, for whatever reason, was not able to be read. The algorithms approved by the CPUC and are almost always favorable to the consumer. A Major US Utility hates to have to do estimated billing because they almost always have to underestimate based on the algorithms and CPUC rules. Not 100% sure about this, but if they Continue reading
Hey, it's HighScalability time:

This is a guest repost by Siddharth Anand, Data Architect at Agari, on Airbnb's open source project Airflow, a workflow scheduler for data pipelines. Some think Airflow has a superior approach.
Workflow schedulers are systems that are responsbile for the periodic execution of workflows in a reliable and scalable manner. Workflow schedulers are pervasive - for instance, any company that has a data warehouse, a specialized database typically used for reporting, uses a workflow scheduler to coordinate nightly data loads into the data warehouse. Of more interest to companies like Agari is the use of workflow schedulers to reliably execute complex and business-critical "big" data science workloads! Agari, an email security company that tackles the problem of phishing, is increasingly leveraging data science, machine learning, and big data practices typically seen in data-driven companies like LinkedIn, Google, and Facebook in order to meet the demands of burgeoning data and dynamicism around modeling.
In a previous post, I described how we leverage AWS to build a scalable data pipeline at Agari. In this post, I discuss our need for a workflow scheduler in order to improve the reliablity of our data pipelines, providing the previous post's pipeline Continue reading


