Author Archives: Tom Kacprzynski
Author Archives: Tom Kacprzynski
Over the last year, I haven’t been writing many new blog posts. I have been pretty busy with a new job, but also starting a new networking group called the Chicago Network Operators Group (CHI-NOG). The idea behind it is that there aren’t that many places where network engineers can meet to talk about technology, learn something new and network with each other. The communities are mostly virtual and that’s something I wanted to change by creating CHI-NOG.
Chicago Network Operators Group
Last year Brian McGahan, Jason Craft and I met to talk about the void of the networking community. A lot of times people only know each other from email or forum exchanges. We wanted to bring in the Chicago community together and have a place to met and discuss the topics that interests us and learn from each other.
We try to host CHI-NOG events 3 times a year. So far our events have been in the evenings for few hours. For each event we have a number of guest speakers. They present on any topic relating to networking, which is a good way to spark conversation for the social hours that start right after.
This October Continue reading
I usually don’t think much about Pseudowires Sub-TLV until I encountered two IOS-XR boxes that didn’t use the same value and didn’t forward any packets. There is a special corner case of pseudowires using Flow Labels Transport (FAT) that can cause unexpected behavior and if you don’t watch out you might drop traffic. In this post I’ll go over the details of using FAT with different IOS-XR versions and what can go wrong.
Flow Aware Transport pseudowire (RFC6391) is a type of L2VPN that operates over MPLS. The main benefit of it is that it implements a mechanism which allows you to load-balance one pseudowire over multiple equal cost paths (i.e. ECMP). ECMP of a pseudowire becomes an advantage when transporting large amount of traffic such as 10Gbps or more. FAT is a special interface sub-TLV that’s negotiated between two PE.
The problem relates to Flow Aware Transport (FAT) pseudowires where one side terminating router operates the IOS-XR version 4.3.2 and the other any version up to 4.3.1. The symptom is lack to forwarding of tunneled packets. Both sides show PW as up and operational but no traffic is being forwarded over it. Continue reading
GNS3 has been a crucial tool used by many network engineers to emulate computer networks. It has proven to be fundamental studying for all network certification levels such as CCNA, CCNP and CCIE. It has been crucial for network design validations within many companies. With the news of Cisco’s VIRL, many said that GNS3 will disappear, but that doesn’t seem to be the case. GNS3 is going through a major redesign and needs the help of all the engineers that it helped over the years.
Recently, Stephen Guppy from GNS3.net contacted me about some of the changes coming to GNS3. He was very excited to share with me the new direction they are heading and the croudfounding campaign going on. These new software improvements incorporate:
Switching has been a major feature preventing network engineer from exclusively using GNS3 for their certification study. The difficulty in supporting switching platforms is that most of their ASCIs were build on proprietary hardware and can’t be easily ported. With the new GNS3, switching will be supported using L2IOU. Some features are not supported Continue reading
Recently I came across an idea to implement anycast DNS within an enterprise environment. The concept is similar to Google’s public DNS, but at an enterprise level. Using IP SLA DNS, a static tracked route and some redistribution it makes it an easy solution. The biggest benefits is that all internal clients can use the same DNS IP address no matter what locations they reside in; additional benefit is distributing the load when DNS attacks occur.
First you’ll have to configure the Cisco’s IP SLA. Using the DNS feature is much better than just ICMP. It will actually verify that the DNS server is responding to a specified query. In my example below I’m using a query for test001dns.me which is configured on the server as an A record. The DNS query is sent to a distinct IP address of the server 10.90.1.5. All local DNS server have two IP addresses: distinct and anycast. The anycast address is configured as a secondary IP (10.10.10.10) a numerous DNS servers throughout the enterprise.
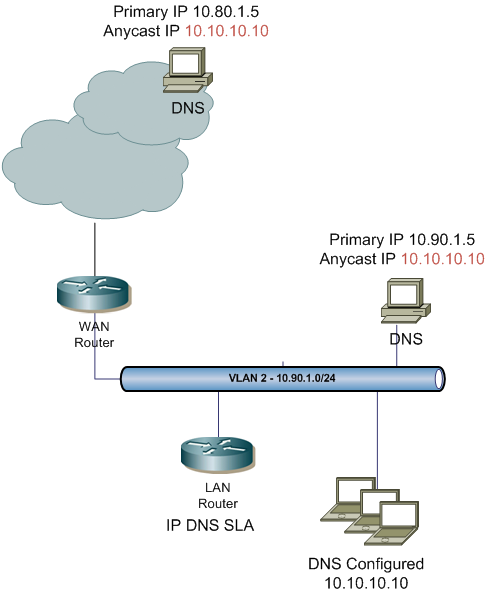
Below is the IP SLA configuration using the DNS feature. It is configured on a LAN router.
ip sla 10 dns test001dns. Continue reading
When configuring RSVP, the “ip rsvp bandwidth (bandwidth) [per flow limit]” command there is an optional parameter which limits the per flow bandwidth of individual RSVP reservation. When using Call Admission Control for VoIP, that is the rate of an individual voice call in one direction, but the behavior is not as clear cut as it seems.
This feature was added to prevent other application from reserving all of interface’s reservable bandwidth. If a video application uses RSVP within the network, it can take up majority of the reservation with a single video call. For example if the smallest interface only has 500 kbps RSVP bandwidth and a video conference request all 500 kbps, no voice calls will be allowed through. Per flow limit wouldn’t allow one reservation to request all of the bandwidth. There are other methods to limit other application’s ability to reserve bandwidth with a more granular method using a RSVP local policy.
The actual VoIP rate is depended on many factors such as codec, sampling rate and header overhead.[1] The most common codec is either G.711 or G.729. For the G.711 codec, the IP rate is 80 Continue reading
Configuring RSVP on DMVPN mGRE tunnels requires few extra steps and a little bit of calculations to figure out the additional overhead. Without correctly configured overhead, the mismatch between RSVP and available LLQ bandwidth can cause degraded VoIP call performance.
By default, the bandwidth value on the tunnel interfaces is set to a low value. Older IOS versions use 8 Kbps while some of the newer IOS versions use 100 Kbps. The idea behind setting such a low bandwidth value is to make it less preferred by routing protocols like EIGRP and OSPF that rely on bandwidth for metric calculation to prevent recursive routing.
A low bandwidth value set on a tunnel interface can cause RSVP problem. If RSVP is enabled on a tunnel interface, by default 75% of its bandwidth is reserved for RSVP. Eight kbps or 100 kbps is too small for any VoIP calls. Ensure that that the correct bandwidth of the underlying physical interface is manually set. It is very easy to miss that Tun2 only have 75 Kbps of reservable bandwidth, while Gi0/2 has 75 Mbps.
b-ro02#sh ip rsvp interface
interface rsvp allocated i/f max flow max sub max VRF
Gi0/0 ena 0 Continue reading
When using RSVP Call Admission Control (CAC) for VoIP, DMVPN and RSVP have limitations that prevent RSVP from working over DMVPN. If you have VoIP and you can’t use location based CAC, RSVP is the only answers. So what’s the problem with RSVP over DMVPN? The root of the problem is RSVP’s loop prevention mechanism. In this post I’ll describe an original solutions to make RSVP CAC work over DMVPN.
RSVP has a little known behavior used for loop prevention. It is similar to the split-horizon rule of many Distance Vector routing protocols and is described in RFC2205:
“[S]tate that is received through a particular interface must never be forwarded out the same interface.” [1]
When RSVP is set to be mandatory for call setup between two locations, RSVP has to successfully establish a reservation for each one way RTP audio stream. That reservation is done by voice gateways acting as the RSVP agents for IP phones. IP phones do not have RSVP running, but rely on voice gateways for that functionality.
Normally, when using DMVPN Phase 3, the initial packets sent between two spoke sites, match a route with the next-hop of the Continue reading
At Cisco Live I was able to attend the CCIE Service Provider technical session by Vincent Zhou who is the product manager of CCIE SP. It was a very good informative session (BRKCCIE-9163) that gave a nice insights into the lab test. Below are my notes from the session, hopefully you’ll find them useful.
– CCIE SP blueprint version 3 was first introduced in April 18th 2011. When I asked Vincent about upcoming changes to the blueprint, he assured me that there won’t be any change for another year.
– All devices are preconfigured. The preconfiguration has basic IPv4/IPv6 addressing, VTP, VLANs, basic routing, basic MPLS..etc. anything that is preconfigured can’t be changed unless explicitly states in the task.
– The GUI and questions are all electronic, there are no printer workbooks, similar to the CCIE R&S lab test. All rack equipment is accessed thought remote access. San Jose and RTP don’t have any local equipment. Most of the IOS devices are running IOU, IOS-XR and Catalyst are using physical devices.
– Passing rate for SP is a lot higher than CCIE R&S. With the addition of IOS-XR there was a significant drop of CCIE Continue reading
At Cisco Live in Orlando I had the chance to demo the Virtual Internet Routing Lab (VIRL). It is Cisco’s answer to GNS3 or Junipers’ Junosphere using virtualization to create virtual network topologies. This tools will be as revolutionary as GNS3, but at a much larger scale. It is an awesome tool that can be used for certification studying but also to validate production designs. Everyone I spoke to couldn’t wait to get their hands on it, including me!
Below is a screen shot of VIRL. It is using Oracles VMMaestro GUI based on Java. In the screen you can see network topology which is drop and drag. On the left side in purple there is a list of all saved networks. The right middle side has a list of supported devices. Top right side has all of the currently running devices and bottom right preconfiguration tabs. To access CLI of these routers, you has to run in simulation mode then Telnet to individual devices. The preconfiguration is a nice feature that allows you preconfigure IP addresses, Loopback interfaces or routing protocols like OSPF or BGP.
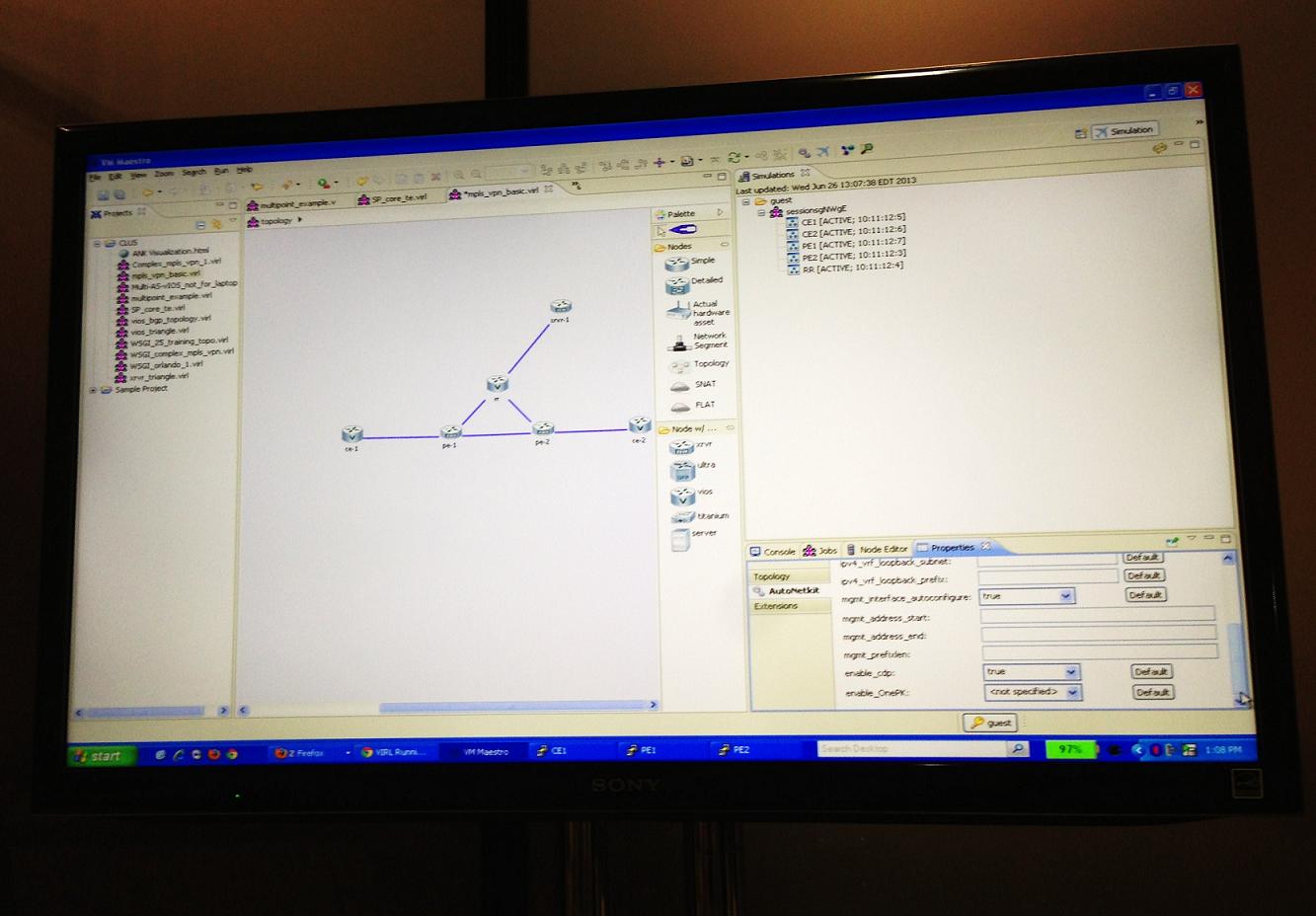
Virtual Internet Routing Laboratory screen shot.
VIRL supports virtualizing Cisco’s modified operations system. Cisco Continue reading
I’ve been trying to setup a BFD neighbor for a link connecting two important sites on a Nexus 7010. That link is only using iBGP for routing. This seems like a really easy thing to, unless you run into bad documentation with few key missing facts.
I was reading the Nexus 7000 Cisco Configuration Guide for Enabling BFD for BGP at http://www.cisco.com/en/US/docs/switches/datacenter/sw/6_x/nx-os/interfaces/configuration/guide/if_bfd.html. The document specifies that all you have to do to enable BFD for BGP is :
1. enable the bfd feature,
2. enable bfd on an interface
3. enable bfd under the BGP neighbor.
See below for the configuration as specified by Cisco.
feature bfd interface Ethernet1/10 bfd interval 100 min_rx 100 multiplier 5 router bgp 65100 neighbor 172.16.2.1 remote-as 65100 bfd
The problem with this feature is that BFD won’t see each other as neighbors. You won’t see any debug messages or keepalives or any other bfd packets. When I was troubleshooting it, I noticed that by specifying a source and destination IP address for BFD neighbors (under the interface) brought up the adj. The problem with that was that BGP didn’t recognize that IP address and during testing, BFD Continue reading
In the good old days of IPv4, an interface on a host could have only one IPv4 IP address. Things were very simple, every IP host would use that one address as the source IP for all communication. When we get into IPv6, each interface can have multiple IPv6 addresses. These addresses have different scopes such as global, unique-local and link-local. If an IPv6 enabled host would like to send a packets to another host, which source IPv6 address does it choose? What if it has four addresses: 2001:10::3/64 (Global from ISP A), 2001:23::3/64 (Global from ISP B), fc00:23::3/64 (Unique-Local) and fe80:23::3 (Link-Local)?
As with almost everything there is a nice RFC written on this topic. RFC6724 Default Address Selection for Internet Protocol Version 6 (IPv6) defines how to select a source IPv6 address. It mentions eight rules for source selection, here is the summary and translation:
Rule 1: Prefer same address
Rule 2: Prefer appropriate scope
Rule 3: Avoid deprecated addresses
Rule 4: Prefer home addresses
Rule 5: Prefer outgoing interface
Rule 6: Prefer matching label
Rule 7: Prefer temporary addresses
Rule 8: Use longest matching prefix
In the remainder of Continue reading
EIGRP Offset-list is usually used to increase the metric of routes being advertised over a link, but can it be used to filter EIGRP prefixes?
I thought about using offset-list in RIP to filter specific routes and thought how about doing the same thing in EIGRP? I haven’t run into any examples or blog posts of using Offset-list in EIGRP to filter routes so I thought about labing it out to see if that’s possible.
To test it, I went to the handy GNS3 with the following topology.

Three routes R1, R2 and R3. R1 advertises a Loopback0 subnet 10.1.1.1/32 which I will use to test filtering using offset-list. As you can see in the diagram, I changed the Delay for each interface to 1 just to make things easier for metric calculation (including loop0 interface). I also set the EIGRP metric weight to only consider delay and not to look at bandwidth for metric calculation, again to make things easier.
My goal is to set an offset-list on R2 to filter routes to R3 using Delay and offset-list commands only. Theoretically, if I know the max metric of EIGRP routes and I apply an offset-list with Continue reading
Is there a way to provide internet service over a dot1q tunnel using VLAN tunneling? Yes, there is a way, it is not the most intuitive method but works nicely. Basically it has to do with what does the switch do with untagged frames when they arrive on a tunnel port. In this configuration, the untagged frames (native VLAN 200) are not tunneled but go to the routed interface for processing. As long as the provider’s switches has a routed interface for the customer ID VLAN and a default route, traffic should reach the Internet.
To explain this, I’ll use a basic topology with 4 switches and one router. SW1 and SW2 are service provider switches, with their interfaces Fa0/21 configured as dot1q-tunnels using access VLAN 100. SW3 and SW4 are customer switches and R1 is acting as the service-providers internet edge router.
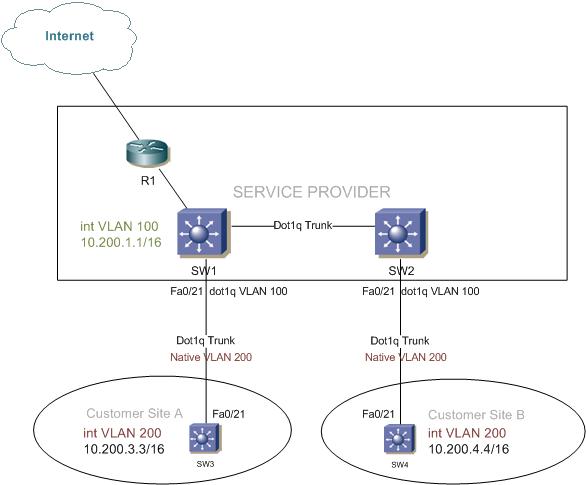
Service provider’s switches SW1 and SW2 relevant configuration:
interface FastEthernet0/21 switchport access vlan 100 switchport trunk encapsulation dot1q switchport mode dot1q-tunnel no cdp enable
Customer ID is VLAN 100 and the port fa0/21 is set to mode dot1q-tunnel.
Customer Site A’s SW3 relevant configuration:
interface FastEthernet0/21 switchport trunk encapsulation dot1q switchport trunk native vlan 200 switchport Continue reading
Over the weekend I attended the CCDE group study sponsored by INE in Chicago. Discussion and material were let by Petr Lapukhov and Brian McGahan. I’m very excited to see high level networking event in my hometown. We had about 15-20 people in the class. This was my first exposure to CCDE so it was a lot of information absorbing. The test is composed of 4 scenarios. You have about 8 hours to pass the computerized test. Just like in other written Cisco certifications, you can’t go back once you answer the question. The test seems to be based on mastering the design’s information extraction from pages and pages of information. Most of the technology focus is on MPLS, routing, QoS and some security.
In the group study we went through Cisco’s CCDE practice demo (https://learningnetwork.cisco.com/docs/DOC-2438). I thought the discussion was very interested, especially from people that have been studying for the test. If you take it and want to look at the solution you can find it at http://www.shafagh.net/2012/08/ccde-demomystery-solved.html. Next we went through INE’s CCDE practice scenarios written by Petr and Brian.
Mainly, I wanted to post some very interesting documents that Continue reading
Recently I had to recover the admin password on the Nexus 5548. The Cisco doc was a little bit uncleared so I figured I’ll make some notes on it.
First thing reboot the switch. The power supplies on these don’t have a on/off switch so you’ll have to pull the power cable.
When you see the output of “Loading system…” press the break command sequence Ctrl+]. This will bring you into the boot mode:
Version 2.00.1201. Copyright (C) 2009 American Megatrends, Inc. Booting kickstart image: bootflash:/n5000-uk9-kickstart.5.2.1.N1.1b.bin.... ............................................................................... ........................Image verification OK INIT: I2C - Mezz absent Starting system POST..... Executing Mod 1 1 SEEPROM Test:...done (0 seconds) Executing Mod 1 1 GigE Port Test:....done (32 seconds) Executing Mod 1 1 PCIE Test:.................done (0 seconds) Mod 1 1 Post Completed Successfully POST is completed can't create lock file /var/lock/mtab~193: No such file or directory (use -n flag to override) nohup: redirecting stderr to stdout autoneg unmodified, ignoring autoneg unmodified, ignoring Checking all filesystems....r. done. ^]Loading system <
I was interested to see what commands are available in this mode, there are few that I’ll use for the recovery (->):
switch(boot)# ? Continue reading
I updated the CCIE page to include CCIE Supermemo questions. Please go to CCIE Supermemo Questions. As time progresses I’ll update more and more of these.
Cisco’s BGP decision process basically decides which BGP route to take when comparing multiple prefixes to the same destination. It is a rather long process and somewhat tricky. Below, I created a quick reference to its steps.

Before I talk about each step I would like to discuss in what order are multiple prefixes compared. For example if you have three prefixes to 10.2.0.0/16 how do you compare all three at once? By default Cisco’s algorithm will compare the younger prefixes to the older and finally compare the oldest to the winner.
The rest of this post are my notes on the BGP decision process. Hopefully you’ll find it useful.
For any path to be considered valid it has to meet these requirements.
The very simple answer is when the local NTP master controller is synching to the IP address 127.127.7.1 instead of 127.127.1.1. Ok, I think I need to clarify few things. In a number of CCIE workbooks, you’ll get a task to configure NTP access-control on the master NTP router to only peer with R1. After trying for a long time, you lookup the solution guide and realize that you were missing an ACL entry for the local address 127.127.7.1. Or you finished the task, everything works, you check the solution guide and ask yourself “why did they have an ACL for the IP address 127.127.7.1? I did it without it and it worked.”
This is something that I found to be very frustrating and without any information on the web. After doing some of my own research, it appears Cisco made few changes that are not very clearly documented.
To give you an example, R4 is the NTP master and R6 (150.1.6.6) is the NTP peer.
R4#sh run | i ntp | access-list
ntp master 4
ntp access-group peer 1
access-list 1 permit 150.1. Continue reading
I was troubleshooting an OSPF area range summarization and came upon something I haven’t seen before called Passive Advertisement. There weren’t too many Cisco documents that explained it so I decided to post a really quick description explaining it in little detail and where you could see it . This could be useful for the CCIE troubleshooting section, when dealing with OSPF area summarization problems.
I will use R3 to demonstrate. This router is connected to area 0 and area 1 which makes it the only ABR connecting the two areas. R3 should be sending a summary route 4.4.0.0/16 for the two component routes 4.4.4.0/24 and 4.4.5.0/24. Looks pretty simple. To verify, I check the output of show ip ospf to make sure the area 0 range 4.4.0.0 255.255.0.0 command is configured:
R3#sh ip ospf
Routing Process "ospf 1" with ID 10.3.3.3
Start time: 00:00:23.404, Time elapsed: 00:01:06.080
Supports only single TOS(TOS0) routes
Supports opaque LSA
Supports Link-local Signaling (LLS)
Supports area transit capability
It is an area border and autonomous system boundary router
Redistributing External Routes from,
rip
Router is Continue reading
What is IPv6 6to4 tunnel address? 2022::/16 or 2002::/16? How do you convert the IPv4 address into IPv6 6to4 tunnel address? Well there is the long way, which you should understand and then there is the easy way in case you need to configure it really quickly. I found this nice method where you can use the IPv6 General Prefix feature to automatically calculate the conversion. Originally this feature was used to create a variable for IPv6 network, the “general-prefix”, to easily change all IPv6 addresses in case reassignment of IP subnets.
Configuration is pretty simple. First make sure to have the 6to4 Tunnel’s source interface configured, in my example that’s Loopback0 150.1.1.1.
Rack1R1#sh ip int brief loop0 Interface IP-Address OK? Method Status Protocol Loopback0 150.1.1.1 YES manual up up
Then configure the IPv6 general-prefix for 6to4 type using loop0.
Rack1R1(config)#ipv6 general-prefix MY-GEN-PRE 6to4 loopback0 Rack1R1#sh ipv6 general-prefix IPv6 Prefix MY-GEN-PRE, acquired via 6to4 2002:9601:101::/48 Valid lifetime infinite, preferred lifetime infinite
The way you apply it on the tunnel is using regular ipv6 address command:
R1(config)#int tun1 R1(config-if)#ipv6 address ? WORD General prefix name X:X:X:X::X IPv6 link-local address X:X:X:X::X/ IPv6 prefix autoconfig Obtain address Continue reading