Hadoop and Salesforce Integration: the Ultimate Successful Database Merger
 How we can transfer salesforce data to hadoop? It is big challenge to everyday users. What are different features of data transfer tools.
How we can transfer salesforce data to hadoop? It is big challenge to everyday users. What are different features of data transfer tools.
Stuff The Internet Says On Scalability For April 15th, 2016
Hey, it's HighScalability time:

- $14 billion: one day of purchases on Alibaba; 47 megawatts: Microsoft's new data center space for its MegaCloud; 50%: do not speak English on Facebook; 70-80%: of all Intel servers shipped will be deployed in large scale datacenters by 2025; 1024 TB: of storage for 3D imagery currently in Google Earth; $7: WeChat average revenue per user; 1 trillion: new trees;
- Quotable Quotes:
- @PicardTips: Picard management tip: Know your audience. Display strength to Klingons, logic to Vulcans, and opportunity to Ferengi.
- Mark Burgess: Microservices cannot be a panacea. What we see clearly from cities is that they can be semantically valuable, but they can be economically expensive, scaling with superlinear cost.
- ethanpil: I'm crying. Remember when messaging was built on open platforms and standards like XMPP and IRC? The golden year(s?) when Google Talk worked with AIM and anyone could choose whatever client they preferred?
- @acmurthy: @raghurwi from @Microsoft talking about scaling Hadoop YARN to 100K+ clusters. Yes, 100,000
- @ryanbigg: Took Continue reading
10 Stack Benchmarking DOs and DON’Ts

An interesting question came up on the mechanical-sympathy list about how to best benchmark a stack of different queue (aeron/argona, jctools, dpdk, pony) and transport (aeron, dpdk, seastar) options.
Who better to answer than Gil Tene, Vice President of Technology and CTO, Co-Founder, of Azul Systems? Here's his usual insightful and helpful response:
If you are looking at the set of "stacks" (all of which are queues/transports), I would strongly encourage you to avoid repeating the mistakes of testing methodologies that focus entirely on max achievable throughput and then report some (usually bogus) latency stats at those max throughout modes.
The tech empower numbers are a classic example of this in play, and while they do provide some basis for comparing a small aspect of behavior (what I call the "how fast can this thing drive off a cliff" comparison, or "peddle to the metal" testing), those results are not very useful for comparing load carrying capacities for anything that actually needs to maintain some form of responsiveness SLA or latency spectrum requirements.
Rules of thumb I'd start with (some simple DOs and DON'Ts):
Sponsored Post: TechSummit, Netflix, Aerospike, TrueSight Pulse, Redis Labs, InMemory.Net, VividCortex, MemSQL, Scalyr, AiScaler, AppDynamics, ManageEngine, Site24x7

Who's Hiring?
- Senior Service Reliability Engineer (SRE): Drive improvements to help reduce both time-to-detect and time-to-resolve while concurrently improving availability through service team engagement. Ability to analyze and triage production issues on a web-scale system a plus. Find details on the position here: https://jobs.netflix.com/jobs/434
- Manager - Performance Engineering: Lead the world-class performance team in charge of both optimizing the Netflix cloud stack and developing the performance observability capabilities which 3rd party vendors fail to provide. Expert on both systems and web-scale application stack performance optimization. Find details on the position here https://jobs.netflix.com/jobs/860482
- Software Engineer (DevOps). You are one of those rare engineers who loves to tinker with distributed systems at high scale. You know how to build these from scratch, and how to take a system that has reached a scalability limit and break through that barrier to new heights. You are a hands on doer, a code doctor, who loves to get something done the right way. You love designing clean APIs, data models, code structures and system architectures, but retain the humility to learn from others who see things differently. Apply to AppDynamics
- Software Engineer (C++). You will be responsible for building Continue reading
The Gig Economy Breaks Social Security

With the tax deadline looming in the US and the future of the gig economy as the engine of scaling startup workforces under fire, there's an important point to consider: In the gig economy the entire social contract is kaput. Here's why.
Everyone who works in the US pays into the Social Security system. The whole idea of Social Security is young people pay in and old people take out.
When you are an employee Social Security taxes are taken directly out of your paycheck. You don't even have to think about it.
When you work in the gig economy you get a 1099-MISC at the end of the year. A 1099 reports payments made by the hiring company during the year and it's sent by the hiring company both to the worker and the IRS.
It's up to the worker to identify their income on their tax return as self employment income, which is subject to a Social Security tax of 15.3%. Most gig workers probably won't declare this income because a lot of them don't even know they are supposed to. My wife, Linda Coleman, a respected Enrolled Agent, says from people she has talked to Continue reading
Stuff The Internet Says On Scalability For April 8th, 2016
Hey, it's HighScalability time:

- 12,000: base pairs in the largest biological circuit ever built; 3x: places GitHub data is now stored; 3.5x: Slacks daily user growth this year; 56 million: events/sec processed through BigTable; 100 Billion: requests per day served by Google App Engine
- Quotable Quotes:
- Horst724: #PanamaPapers is the biggest secret data leak in history. It involves 2,6 TB of data, a total of 11.5 million documents that have been leaked by an anonymous insider.
- Amazon cloud has 1 million users and is near $10 billion in annual sales: Today, AWS offers more than 70 services for compute, storage, databases, analytics, mobile, Internet of Things, and enterprise applications. We also offer 33 Availability Zones across 12 geographic regions worldwide, with another five regions and 11 Availability Zones.
- @CodeWisdom: "Give someone a program, you frustrate them for a day; teach them how to program, you frustrate them for a lifetime." - David Leinweber
- @peterseibel: OH: it is Continue reading
How to Remove Duplicates in a Large Dataset Reducing Memory Requirements by 99%

This is a guest repost by Suresh Kondamudi from CleverTap.
Dealing with large datasets is often daunting. With limited computing resources, particularly memory, it can be challenging to perform even basic tasks like counting distinct elements, membership check, filtering duplicate elements, finding minimum, maximum, top-n elements, or set operations like union, intersection, similarity and so on
Probabilistic Data Structures to the Rescue
Probabilistic data structures can come in pretty handy in these cases, in that they dramatically reduce memory requirements, while still providing acceptable accuracy. Moreover, you get time efficiencies, as lookups (and adds) rely on multiple independent hash functions, which can be parallelized. We use structures like Bloom filters, MinHash, Count-min sketch, HyperLogLog extensively to solve a variety of problems. One fairly straightforward example is presented below.
The Problem
We at CleverTap manage mobile push notifications for our customers, and one of the things we need to guard against is sending multiple notifications to the same user for the same campaign. Push notifications are routed to individual devices/users based on push notification tokens generated by the mobile platforms. Because of their size (anywhere from 32b to 4kb), it’s non-performant for us to index Continue reading
Stuff The Internet Says On Scalability For April 1st, 2016
Hey, this is no joke, it's HighScalability time:

A glorious battle in EVE. Tens of thousands of pilots fighting tens of thousands of pilots in a real time all on a single shard.
- $9.3B: punishment for Google's temerity of using Java; 200: computer scientists and neuroscientists at Google’s DeepMind; 22: cores in Intel's new Xeon E5-2600 V4 CPU; 12: fold boost in spectrum efficiency over current 4G cellular technology using a massive antenna system;
- Quotable Quotes:
- Linus Torvalds: I’m not a big visionary. I’m a very plodding pedestrian engineer, and I try to keep my eyes firmly on the ground. I’ll let others make the big predictions about where we’ll be in 5, 10 or 25 years
- theymos: "Core" doesn't think anything because it's not any sort of unified organization.
- whalesalad: We are running Kubernetes in production at FarmLogs and LOVE it.
- @StackPointCloud: The operational complexity associated with monitoring containers is multiplied given the 1:N relationship of host:containers. #NYCK8s
- hu6Bi5To: AWS is significantly more expensive like-for-like, but it's worth remembering that you wouldn't architect your whole system that way if Continue reading
Should Apple Build their Own Cloud?

This is one of the most interesting build or buy questions of all time: should Apple build their own cloud? Or should Apple concentrate on what they do best and buy cloud services from the likes of Amazon, Microsoft, and Google?
It’s a decision a lot of companies have to make, just a lot bigger, and because it’s Apple, more fraught with an underlying need to make a big deal out of it.
This build or buy question was raised and thoroughly discussed across two episodes of the Exponent podcast, Low Hanging Fruit and Pickaxe Retailers, with hosts Ben Thompson and James Allworth, who regularly talk about business strategy with an emphasis on tech. A great podcast, highly recommended. There’s occasional wit and much wisdom.
Dark Clouds Over Apple’s Infrastructure Efforts
Sponsored Post: TechSummit, zanox Group, Varnish, LaunchDarkly, Swrve, Netflix, Aerospike, TrueSight Pulse, Redis Labs, InMemory.Net, VividCortex, MemSQL, Scalyr, AiScaler, AppDynamics, ManageEngine, Site24x7
Who's Hiring?
- The zanox Group are looking for a Senior Architect. We're looking for someone smart and pragmatic to help our engineering teams build fast, scalable and reliable solutions for our industry leading affiliate marketing platform. The role will involve a healthy mixture of strategic thinking and hands-on work - there are no ivory towers here! Our stack is diverse and interesting. You can apply for the role in either London or Berlin.
- Swrve -- In November we closed a $30m funding round, and we’re now expanding our engineering team based in Dublin (Ireland). Our mobile marketing platform is powered by 8bn+ events a day, processed in real time. We’re hiring intermediate and senior backend software developers to join the existing team of thirty engineers. Sound like fun? Come join us.
- Senior Service Reliability Engineer (SRE): Drive improvements to help reduce both time-to-detect and time-to-resolve while concurrently improving availability through service team engagement. Ability to analyze and triage production issues on a web-scale system a plus. Find details on the position here: https://jobs.netflix.com/jobs/434
- Manager - Performance Engineering: Lead the world-class performance team in charge of both optimizing the Netflix cloud stack and developing the performance observability capabilities Continue reading
How we implemented the video player in Mail.Ru Cloud
We’ve recently added video streaming service to Mail.Ru Cloud. Development started with contemplating the new feature as an all-purpose “Swiss Army knife” that would both play files of any format and work on any device with the Cloud available. Video content uploaded to the Cloud mostly falls into one of the two categories: “movies/series” and “users’ videos”. The latter are the videos that users shoot with their phones and cameras, and these videos are most versatile in terms of formats and codecs. For many reasons, it is often a problem to watch these videos on other end-user devices without prior normalization: a required codec is missing, or the file size is too big to download, or whatever.
In this article, I’ll go into detail to explain how video playback works in Mail.Ru Cloud, and how we made the Cloud player “omnivorous” and ensured support on a maximum number of end-user devices.
Storing and Caching: two approaches
Stuff The Internet Says On Scalability For March 25th, 2016

- 51%: of billion-dollar startups founded by immigrants; 2.8 billion: Twitter metric ingestion service writes per minute; 1 billion: Urban Airship push notifications a day; 1.5 billion: Slack messages sent per month; 35 million: server nodes in the world; 10: more regions will be added to Google Cloud; 697 million: WeChat active monthly users;
- Quotable Quotes:
- Dark Territory: When officials in the Air Force or the NSA neglected to let Microsoft (or Cisco, Google, Intel, or any number of other firms) know about vulnerabilities in its software, when they left a hole unplugged so they could exploit the vulnerability in a Russian, Chinese, Iranian, or some other adversary’s computer system, they also left American citizens open to the same exploitations—whether by wayward intelligence agencies or by cyber criminals, foreign spies, or terrorists who happened to learn about the unplugged hole, too.
- @xaprb: If you adopt a microservices architecture with 1000x more things to monitor, you should not expect your monitoring cost Continue reading
What does Etsy’s architecture look like today?

This is a guest post by Christophe Limpalair based on an interview (video) he did with Jon Cowie, Staff Operations Engineer and Breaksmith @ Etsy.
Etsy has been a fascinating platform to watch, and study, as they transitioned from a new platform to a stable and well-established e-commerce engine. That shift required a lot of cultural change, but the end result is striking.
In case you haven't seen it already, there's a post from 2012 that outlines their growth and shift. But what has happened since then? Are they still innovating? How are engineering decisions made, and how does this shape their engineering culture? These are questions we explored with Jon Cowie, a Staff Operations Engineer at Etsy, and the author of Customizing Chef, in a new podcast episode.
What does Etsy's architecture look like nowadays?
To Compress or Not to Compress, that was Uber’s Question
 Uber faced a challenge. They store a lot of trip data. A trip is represented as a 20K blob of JSON. It doesn't sound like much, but at Uber's growth rate saving several KB per trip across hundreds of millions of trips per year would save a lot of space. Even Uber cares about being efficient with disk space, as long as performance doesn't suffer.
Uber faced a challenge. They store a lot of trip data. A trip is represented as a 20K blob of JSON. It doesn't sound like much, but at Uber's growth rate saving several KB per trip across hundreds of millions of trips per year would save a lot of space. Even Uber cares about being efficient with disk space, as long as performance doesn't suffer.
This highlights a key difference between linear and hypergrowth. Growing linearly means the storage needs would remain manageable. At hypergrowth Uber calculated when storing raw JSON, 32 TB of storage would last than than 3 years for 1 million trips, less than 1 year for 3 million trips, and less 4 months for 10 million trips.
Uber went about solving their problem in a very measured and methodical fashion: they tested the hell out of it. The goal of all their benchmarking was to find a solution that both yielded a small size and a short time to encode and decode.
The whole experience is described in loving detail in the article: How Uber Engineering Evaluated JSON Encoding and Compression Algorithms to Put the Squeeze on Trip Data. They came up with a matrix of Continue reading
Stuff The Internet Says On Scalability For March 18th, 2016
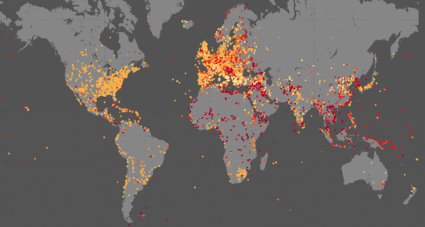
- 500 petabytes: data stored in Dropbox; 8.5 kB: amount of drum memory in an IBM 650; JavaScript: most popular programming language in the world (OMG); $20+ billion: Twitch in 2020; Two years: time it took to fill the Mediterranean;
- Quotable Quotes:
- Dark Territory: The other bit of luck was that the Serbs had recently given their phone system a software upgrade. The Swiss company that sold them the software gave U.S. intelligence the security codes.
- Alec Ross~ The principle political binary of the 20th century is left versus right. In the 21st century the principle political binary is open versus closed. The real tension both inside and outside countries are those that embrace more open economic, political and cultural systems versus those that are more closed. Looking forward to the next 20 years the states and societies that are more open are those that will compete and succeed more effectively in tomorrows industry.
- @chrismaddern: "Population size: 1. Facebook 2. China ?? 3. Continue reading
Jeff Dean on Large-Scale Deep Learning at Google
If you can’t understand what’s in information then it’s going to be very difficult to organize it.
This quote is from Jeff Dean, currently a Wizard, er, Fellow in Google’s Systems Infrastructure Group. It’s taken from his recent talk: Large-Scale Deep Learning for Intelligent Computer Systems.
Since AlphaGo vs Lee Se-dol, the modern version of John Henry’s fatal race against a steam hammer, has captivated the world, as has the generalized fear of an AI apocalypse, it seems like an excellent time to gloss Jeff’s talk. And if you think AlphaGo is good now, just wait until it reaches beta.
Jeff is referring, of course, to Google’s infamous motto: organize the world’s information and make it universally accessible and useful.
Historically we might associate ‘organizing’ with gathering, cleaning, storing, indexing, reporting, and searching data. All the stuff early Google mastered. With that mission accomplished Google has moved on to the next challenge.
Now organizing means understanding.
Some highlights from the talk for me:
-
Real neural networks are composed of hundreds of millions of parameters. The skill that Google has is in how to build and rapidly train these huge models on large interesting datasets, Continue reading
Sponsored Post: zanox Group, Varnish, LaunchDarkly, Swrve, Netflix, Aerospike, TrueSight Pulse, Redis Labs, InMemory.Net, VividCortex, MemSQL, Scalyr, AiScaler, AppDynamics, ManageEngine, Site24x7
Who's Hiring?
- The zanox Group are looking for a Senior Architect. We're looking for someone smart and pragmatic to help our engineering teams build fast, scalable and reliable solutions for our industry leading affiliate marketing platform. The role will involve a healthy mixture of strategic thinking and hands-on work - there are no ivory towers here! Our stack is diverse and interesting. You can apply for the role in either London or Berlin.
- Swrve -- In November we closed a $30m funding round, and we’re now expanding our engineering team based in Dublin (Ireland). Our mobile marketing platform is powered by 8bn+ events a day, processed in real time. We’re hiring intermediate and senior backend software developers to join the existing team of thirty engineers. Sound like fun? Come join us.
- Senior Service Reliability Engineer (SRE): Drive improvements to help reduce both time-to-detect and time-to-resolve while concurrently improving availability through service team engagement. Ability to analyze and triage production issues on a web-scale system a plus. Find details on the position here: https://jobs.netflix.com/jobs/434
- Manager - Performance Engineering: Lead the world-class performance team in charge of both optimizing the Netflix cloud stack and developing the performance observability capabilities Continue reading
Snuggling Up to Papers We Love – What’s Your Favorite Paper?

From a talk by @aysylu22 at QCon London on modern computer science applied to distributed systems in practice.
"CS research is timeless." Lessons learned are always pertinent. @aysylu22 #qconlondon
— Paula Walter (@paulacwalter) March 8, 2016
There has been a renaissance in the appreciation of computer science papers as a relevant source of wisdom for building today's complex systems. If you're having a problem there's likely some obscure paper written by a researcher twenty years ago that just might help. Which isn't to say there aren't problems with papers, but there's no doubt much of the technology we take for granted today had its start in a research paper. If you want to push the edge it helps to learn from primary research that has helped define the edge.
If you would like to share your love of papers, be proud, you are not alone:
- There's a very active Papers We Love Twitter account. And a Facebook group.
- There's a Papers We Love website that lists all the Papers We Love meetups from around the world. And there are lots of them. Here's the meetup for SF, New York, London, Bangalore, Singapore.
- Even Continue reading
Stuff The Internet Says On Scalability For March 11th, 2016
- 400Gbps: DDoS attack; 50,000: frames per second Mythbusters films in HD; 3,900: pages Paul Klee’s Personal Notebooks; 1 terabit: satellites deliver in-flight Internet access at hundreds of megabits per second; 18%: overall mobile market revenue increase; 21 TB: amount of date the BBC writes daily to S3; $300 million: Snapchat revenue;
- Quotable Quotes:
- Dark Territory: Yes, he told them, the NORAD computer was supposed to be closed, but some officers wanted to work from home on the weekend, so they’d leave a port open.
- @davefarley77: If heartbeat was a clock cycle, retrieving data from fastest SSD is equivalent to crossing whole of London on foot @__Abigor__ #qconlondon
- @fiddur: "Legacy is everything you wrote before lunch." - @russmiles #qconlondon
- @BarryNL: Persistent memory could be the biggest change to computer architecture in 50 years. #qconlondon
- @mpaluchowski: "You can tell which services are too big. That's the ones developers don't want to work with." #qconlondon @SteveGodwin
- @danielbryantuk: "I'm not going to say how big Continue reading
The Simple Leads to the Spectacular
Steve Kerr, head coach of the record setting Golden State Warriors (my local Bay Area NBA basketball team), has this to say about what the team needs to do to get back on track (paraphrased):
What we have to get back to is simple, simple, simple. That's good enough. The simple leads to the spectacular. You can't try the spectacular without doing the simple first. Make the simple pass. Our guys are trying to make the spectacular plays when we just have to make the easy ones. If we don't get that cleaned up we're in big trouble.
If you play the software game, doesn't this resonate somewhere deep down in your git repository?
If you don't like basketball or despise sports metaphors this is a good place to stop reading. The idea that "The simple leads to the spectacular" is probably the best TLDR of Keep it Simple Stupid I've ever heard.
Software development is fundamentally a team sport. It usually takes a while for this lesson to pound itself into the typical lone wolf developer brain. After experiencing a stack of failed projects I know it took an embarrassingly long time for me to Continue reading