The Big List of Alternatives to Parse

Parse is not going away. It’s going to get better.
Ilya Sukhar — April 25th, 2013 on the Future of Parse
Ilya Sukhar — April 25th, 2013 on the Future of Parse
Parse is dead. The great diaspora has begun. The gold rush is on. There’s a huge opportunity for some to feed and grow on Parse’s 600,000 fleeing customers.
Where should you go? What should you do? By now you’ve transitioned through all five stages of grief and ready for stage six: doing something about it. Fortunately there are a lot of options and I’ve gathered as many resources as I can here in one place.
There is a Lot Pain Out There
Parse closing is a bigger deal than most shutterings. There’s even a petition: Don't Shut down Parse.com. That doesn’t happen unless you’ve managed to touch people. What could account for such an outpouring of emotion.
Parse and the massive switch to mobile computing grew up at the same time. Mobile is by definition personal. Many programmers capable of handling UI programming challenge were not as experienced with backend programming and Parse filled that void. When a childhood friend you grew to depend on dies, it hurts. That hurt is deep. It goes into the very Continue reading
A Patreon Architecture Short
 Patreon recently snagged $30 Million in funding. It seems the model of pledging $1 for individual feature releases or code changes won't support fast enough growth. CEO Jack Conte says: We need to bring in so many people so fast. We need to keep up with hiring and keep up with making all of the things.
Patreon recently snagged $30 Million in funding. It seems the model of pledging $1 for individual feature releases or code changes won't support fast enough growth. CEO Jack Conte says: We need to bring in so many people so fast. We need to keep up with hiring and keep up with making all of the things.
Since HighScalability is giving Patreon a try I've naturally wondered how it's built. Modulo some serious security issues Patreon has always worked well. So I was interested to dig up this nugget in a thread on the funding round where the Director of Engineering at Patreon shares a little about how Patreon works:
- Server is in Python using Flask and SQLAlchemy,
- Runs on AWS (EC2, RDS (MySQL), and some Redis, Celery, SQS, etc. to boot).
- A few microservices here and there in other languages too (e.g. real time chat server with Node & Firebase)
- Web code is written in React (with some legacy code in Angular). We tend to use Redux for the non-component pieces, but are still trying out new React-compatible libraries here and there.
- iOS and Android code are written in Objective-C and Java, respectively.
- We use Realm on both platforms for Continue reading
Stuff The Internet Says On Scalability For January 29th, 2016
Hey, it's HighScalability time:

- 88: the too short life of Marvin Minsky; $18.4 billion: profit made by Apple in 3 months; 100M: hours of video watched on Facebook each day; 1.59 billion: Facebook users; $115B: size of game market by 2020; 12 years: Mars rover still going strong; 96.3m: barrels of oil produced per day; 570 Billion: object brighter than the Sun; 134 pounds: carried by drones; $2.4 billion: AWS Q4 sales; 2.5 million: advertisers on the Facebook;
- Quotable Quotes:
- @ptaoussanis: Real-world scaling 101: be in the habit of routinely, objectively asking what parts of your system could stand to be simplified or removed
- @Carnage4Life: Azure revenue up 140%. Search revenue from #BingAds up 21%. Microsoft is killing it in the cloud
- @gabriel_boya: Scaling up a Cloud Service on @azure takes so many hours that your customers may be gone by the time your instances are allocated...
- AJ007: Facebook is the Continue reading
Tinder: How does one of the largest recommendation engines decide who you’ll see next?

We've heard a lot about the Netflix recommendation algorithm for movies, how Amazon matches you with stuff, and Google's infamous PageRank for search. How about Tinder? It turns out Tinder has a surprisingly thoughtful recommendation system for matching people.
This is from an extensive profile, Mr. (Swipe) Right?, on Tinder founder Sean Rad:
Design of a Modern Cache
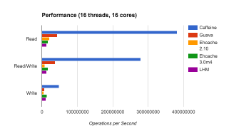
This is a guest post by Benjamin Manes, who did engineery things for Google and is now doing engineery things for a new load documentation startup, LoadDocs.
Caching is a common approach for improving performance, yet most implementations use strictly classical techniques. In this article we will explore the modern methods used by Caffeine, an open-source Java caching library, that yield high hit rates and excellent concurrency. These ideas can be translated to your favorite language and hopefully some readers will be inspired to do just that.
Eviction Policy
A cache’s eviction policy tries to predict which entries are most likely to be used again in the near future, thereby maximizing the hit ratio. The Least Recently Used (LRU) policy is perhaps the most popular due to its simplicity, good runtime performance, and a decent hit rate in common workloads. Its ability to predict the future is limited to the history of the entries residing in the cache, preferring to give the last access the highest priority by guessing that it is the most likely to be reused again soon...
Stuff The Internet Says On Scalability For January 22nd, 2016
Hey, it's HighScalability time:

- 42,000: drones from China securing the South China Sea; 1 billion: WhatsApp active users; 2⁻¹²²: odds of a two GUIDs with 122 random bits colliding; 25,000 to 70,000: memory chip errors per billion hours per megabit; 81,500: calories in a human body; 62: people as wealthy as half of world's population; 1.66 million: App Economy jobs in the US; 521 years: half-life of DNA; 0.000012%: air passenger fatalities; $1B: Microsoft free cloud resources for nonprofits; 4000-7000+: BBC stats collected per second; $1 billion: Google's cost to taste Apple's pie;
- Quotable Quotes:
- @mcclure111: 1995: Every object in your home has a clock & it is blinking 12:00 / 2025: Every object in your home has a IP address & the password is Admin
- @notch: Coming soon to npm: tirefire.js, an asynchronous framework for implementing helper classes for reinventing the wheel. Based on promises.
- @ayetempleton: Fun fact: You are MORE likely to win a million or Continue reading
Why does Unikernel Systems Joining Docker Make A Lot of Sense?

Unikernel Systems Joins Docker. Now this is an interesting match. The themes are security and low overhead, though they do seem to solve the same sort of problem.
So, what's going on?
In FLOSS WEEKLY 302 Open Mirage, starting at about 10 minutes in, there are a series of possible clues. Dr. Anil Madhavapeddy, former CTO of Unikernel Systems, explains their motivation behind the creation of unikernels. And it's a huge and exciting vision...
Building An Infinitely Scaleable Online Recording Campaign For David Guetta

This is a guest repost of an interview posted by Ryan S. Brown that originally appeared on serverlesscode.com. It continues our exploration of building systems on top of Lambda.
Paging David Guetta fans: this week we have an interview with the team that built the site behind his latest ad campaign. On the site, fans can record themselves singing along to his single, “This One’s For You” and build an album cover to go with it.
Under the hood, the site is built on Lambda, API Gateway, and CloudFront. Social campaigns tend to be pretty spiky – when there’s a lot of press a stampede of users can bring infrastructure to a crawl if you’re not ready for it. The team at parall.ax chose Lambda because there are no long-lived servers, and they could offload all the work of scaling their app up and down with demand to Amazon.
James Hall from parall.ax is going to tell us how they built an internationalized app that can handle any level of demand from nothing in just six weeks.
The Interview
Sponsored Post: Netflix, Macmillan, Aerospike, TrueSight Pulse, LaunchDarkly, Robinhood, StatusPage.io, Redis Labs, InMemory.Net, VividCortex, MemSQL, Scalyr, AiScaler, AppDynamics, ManageEngine, Site24x7

Who's Hiring?
- Manager - Site Reliability Engineering: Lead and grow the the front door SRE team in charge of keeping Netflix up and running. You are an expert of operational best practices and can work with stakeholders to positively move the needle on availability. Find details on the position here: https://jobs.netflix.com/jobs/398
- Macmillan Learning, a premier e-learning institute, is looking for VP of DevOps to manage the DevOps teams based in New York and Austin. This is a very exciting team as the company is committed to fully transitioning to the Cloud, using a DevOps approach, with focus on CI/CD, and using technologies like Chef/Puppet/Docker, etc. Please apply here.
- DevOps Engineer at Robinhood. We are looking for an Operations Engineer to take responsibility for our development and production environments deployed across multiple AWS regions. Top candidates will have several years experience as a Systems Administrator, Ops Engineer, or SRE at a massive scale. Please apply here.
- Senior Service Reliability Engineer (SRE): Drive improvements to help reduce both time-to-detect and time-to-resolve while concurrently improving availability through service team engagement. Ability to analyze and triage production issues on a web-scale system a plus. Find details on the position here: https://jobs. Continue reading
Use Google For Throughput, Amazon And Azure For Low Latency

Which cloud should you use? It may depend on what you need to do with it. What Zach Bjornson needs to do is process large amounts scientific data as fast as possible, which means reading data into memory as fast as possible. So, he made benchmark using Google's new multi-cloud PerfKitBenchmarker, to figure out which cloud was best for the job.
The results are in a very detailed article: AWS S3 vs Google Cloud vs Azure: Cloud Storage Performance. Feel free to datamine the results for more insights, but overall his conclusions are:
Stuff The Internet Says On Scalability For January 15th, 2016
Hey, it's HighScalability time:

- 13.5TB: open data from Yahoo for machine learning; 1+ exabytes: data stored in the cloud; 13: reasons autonomous cars should have steering wheels; 3,000: kilowatt-hours of energy generated by the solar bike path; 10TB: helium-filled hard disk; $224 Billion: 2016 gadget spending in US; 85: free ebooks; 17%: Azure price drop on some VMs; 20.5: tons of explosives detonated on Mythbusters; 20 Billion: Apple’s App Store Sales; 70%: Global Internet traffic goes through Northern Virginia; 12: photos showing the beauty of symmetry;
- Quotable Quote:
- @WhatTheFFacts: Scaling Earth's 'life' to 46 years, the industrial revolution began 1 minute ago -- In that time we've destroyed half the world's forests.
- David Brin: The apotheosis of Darth Vader was truly disgusting. Saving one demigod—a good demigod, his son—wiped away all his guilt from slaughtering billions of normal people.
- Brian Brazil: In today’s world, having a 1:1 coupling between machines and services is becoming less Continue reading
Live Video Streaming At Facebook Scale
With 1.49 billion monthly active users, operating at Facebook scale is far from trivial. Facebook's new live video streaming services present a fascinating use case for designing streaming service in global distribution and massive scale.A Beginner’s Guide to Scaling to 11 Million+ Users on Amazon’s AWS
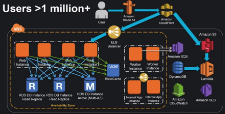
How do you scale a system from one user to more than 11 million users? Joel Williams, Amazon Web Services Solutions Architect, gives an excellent talk on just that subject: AWS re:Invent 2015 Scaling Up to Your First 10 Million Users.
If you are an advanced AWS user this talk is not for you, but it’s a great way to get started if you are new to AWS, new to the cloud, or if you haven’t kept up with with constant stream of new features Amazon keeps pumping out.
As you might expect since this is a talk by Amazon that Amazon services are always front and center as the solution to any problem. Their platform play is impressive and instructive. It's obvious by how the pieces all fit together Amazon has done a great job of mapping out what users need and then making sure they have a product in that space.
Some of the interesting takeaways:
- Start with SQL and only move to NoSQL when necessary.
- A consistent theme is take components and separate them out. This allows those components to scale and fail independently. It applies to breaking up tiers and creating microservices.
- Only invest in tasks Continue reading
Uptime Funk – Best Sysadmin Parody Video Ever!
This is so good! Perfect for your Monday morning jam.
Uptime Funk is a music video (parody of Uptown Funk) from SUSECon 2015 in Amsterdam.
My favorite:
I'm all green (hot patch)
Called a Penguin and Chameleon
I'm all green (hot patch)
Call Torvalds and Kroah-Hartman
It’s too hot (hot patch)
Yo, say my name you know who I am
It’s too hot (hot patch)
I ain't no simple code monkey
Nuthin's down
Stuff The Internet Says On Scalability For January 8th, 2016
Hey, it's HighScalability time:

- 150: # of globular clusters in the Milky Way; 800 million: Facebook Messenger users; 180,000: high-res images of the past; 1 exaflops: 1 million trillion floating-point operations per second; 10%: of Google's traffic is now IPv6; 100 milliseconds: time it takes to remember; 35: percent of all US Internet traffic used by Netflix; 125 million: hours of content delivered each day by Netflix's CDN;
- Quotable Quotes:
- Erik DeBenedictis: We could build an exascale computer today, but we might need a nuclear reactor to power it
- wstrange: What I really wish the cloud providers would do is reduce network egress costs. They seem insanely expensive when compared to dedicated servers.
- rachellaw: What's fascinating is the bot-bandwagon is mirroring the early app market.
With apps, you downloaded things to do things. With bots, you integrate them into things, so they'll do it for you.
-
erichocean: The situation we're in today with RAM is pretty much the identical situation with the disks of Continue reading
Let’s Donate Our Organs and Unused Cloud Cycles to Science

There’s a long history of donating spare compute cycles for worthy causes. Most of those efforts were started in the Desktop Age. Now, in the Cloud Age, how can we donate spare compute capacity? How about through a private spot market?
There are cycles to spare. Public Cloud Usage trends:
-
Instances are underutilized with average utilization rates between 8-9%
-
24% of instance reservations are unused
Maybe all that CapEx sunk into Reserved Instances can be put to some use? Maybe over provisioned instances could be added to the resource pool as well? That’s a lot of power Captain. How could it be put to good use?
There is a need to crunch data. For science. Here’s a great example as described in This is how you count all the trees on Earth. The idea is simple: from satellite pictures count the number of trees. It’s an embarrassingly parallel problem, perfect for the cloud. NASA had a problem. Their cloud is embarrassingly tiny. 400 hypervisors shared amongst many projects. Analysing all the data would would take 10 months. An unthinkable amount of time in this Real-time Age. So they used the spot market on AWS.
The upshot? The test run cost Continue reading
Sponsored Post: Netflix, StatusPage.io, Redis Labs, Jut.io, SignalFx, InMemory.Net, VividCortex, MemSQL, Scalyr, AiScaler, AppDynamics, ManageEngine, Site24x7
Who's Hiring?
- Manager - Site Reliability Engineering: Lead and grow the the front door SRE team in charge of keeping Netflix up and running. You are an expert of operational best practices and can work with stakeholders to positively move the needle on availability. Find details on the position here: https://jobs.netflix.com/jobs/398
- Senior Service Reliability Engineer (SRE): Drive improvements to help reduce both time-to-detect and time-to-resolve while concurrently improving availability through service team engagement. Ability to analyze and triage production issues on a web-scale system a plus. Find details on the position here: https://jobs.netflix.com/jobs/434
- Manager - Performance Engineering: Lead the world-class performance team in charge of both optimizing the Netflix cloud stack and developing the performance observability capabilities which 3rd party vendors fail to provide. Expert on both systems and web-scale application stack performance optimization. Find details on the position here https://jobs.netflix.com/jobs/860482
- Senior Devops Engineer - StatusPage.io is looking for a senior devops engineer to help us in making the internet more transparent around downtime. Your mission: help us create a fast, scalable infrastructure that can be deployed to quickly and reliably.
- UI Engineer– AppDynamics, founded in 2008 and lead Continue reading
Server-Side Architecture. Front-End Servers and Client-Side Random Load Balancing

Chapter by chapter Sergey Ignatchenko is putting together a wonderful book on the Development and Deployment of Massively Multiplayer Games, though it has much broader applicability than games. Here's a recent chapter from his book.
Enter Front-End Servers
[Enter Juliet]
Hamlet:
Thou art as sweet as the sum of the sum of Romeo and his horse and his black cat! Speak thy mind!
[Exit Juliet]

Our Classical Deployment Architecture (especially if you do use FSMs) is not bad, and it will work, but there is still quite a bit of room for improvement for most of the games out there. More specifically, we can add another row of servers in front of the Game Servers, as shown on Fig VI.8:
Stuff The Internet Says On Scalability For January 1st, 2016
Hey, Happy New Year, it's HighScalability time:

- 71: mentions of innovation by the Chinese Communist Party; 60.5%: of all burglaries involve forcible entry; 280,000-squarefoot: Amazon's fulfillment center in India capable of shipping 2 million items; 11 billion: habitable earth like planets in the goldilocks zone in just our galaxy; 800: people working on the iPhone's camera (how about the app store?); 3.3 million: who knew there were so many Hello Kitty fans?; 26 petabytes: size of League of Legends' data warehouse;
- Quotable Quotes:
- George Torwell: Tor is Peace / Prism is Slavery / Internet is Strength
- @SciencePorn: Mr Claus will eat 150 BILLION calories and visit 5,556 houses per second this Christmas Eve.
- @SciencePorn: Blue Whale's heart is so big, a small child can swim through the veins.
- @BenedictEvans: There are close to 4bn people on earth with a phone (depending on your assumptions). Will go to at least 5bn. So these issues will grow.
- @JoeSondow: "In real life you Continue reading
How to choose an in-memory NoSQL solution: Performance measuring
The main purpose of this work is to show results of benchmarking some of the leading in-memory NoSQL databases with a tool named YCSB.
We selected three popular in-memory database management systems: Redis (standalone and in-cloud named Azure Redis Cache), Tarantool and CouchBase and one cache system Memcached. Memcached is not a database management system and does not have persistence. But we decided to take it, because it is also widely used as a fast storage system. Our “firing field” was a group of four virtual machines in Microsoft Azure Cloud. Virtual machines are located close to each other, meaning they are in one datacenter. This is necessary to reduce the impact of network overhead in latency measurements. Images of these VMs can be downloaded by links: one, two, three and four (login: nosql, password: qwerty). A pair of VMs named nosql-1 and nosql-2 is useful for benchmarking Tarantool and CouchBase and another pair of VMs named nosql-3 and nosql-4 is good for Redis, Azure Redis Cache and Memcached. Databases and tests are installed and configured on these images.
Our virtual machines were the basic A3 instances with 4 cores, 7 GB RAM and 120 GB disk Continue reading