Using AWS Lambda functions to create print ready files
In a nutshell, Peecho is all about turning your digital content into professionally printed products. Although it might look like a simple task, a lot of stuff happens behind the scenes to make that possible. In this article, we’re going to tell you about our processing architecture as well as at a recent performance improvement with the integration of AWS Lambda functions.
Print-ready files
In order to make digital content ready for printing facilities, there are some procedures that must occur after the order is received and before the final printing. In printing industry this process is called pre-press and the Peecho platform fully automates its initial stages before routing orders to printers.
Once the file has been created by the customer and uploaded to Peecho, it undergoes our processing stage. During processing, the file is checked to make sure it contains all the elements necessary for a successful print run: do the images have the proper format and resolution, are all the fonts included, are the RGB/CMYK colors set up appropriately, are all layout elements such as margins, crop marks and bleeds set up correctly, etc.
All these checks are automated by our backend systems. The entire process is Continue reading
Stuff The Internet Says On Scalability For December 18th, 2015
Hey, it's HighScalability time:

In honor of a certain event what could be better than a double-bladed lightsaber slicing through clouds? (ESA/Hubble & NASA)
- 66,000 yottayears: lifetime of an electron; 3 Gbps: potential throughput for backhaul microwave networks; 1.2 trillion: yearly Google searches; $100 trillion: global investible capital; 2.5cm: range of chip powered by radio waves;
- Quotable Quotes:
- @KarenMN: He's making a database / He's sorting it twice / SELECT * from contacts WHERE behavior = 'nice' / SQL Clause is coming to town
- abrkn: Every program attempts to expand until it has an app store. Those programs which cannot so expand are replaced by ones which can.
- Amin Vahdat: Some recent external measurements indicate that our [Google] backbone carries the equivalent of 10 percent of all the traffic on the global Internet. The rate at which that volume is growing is faster than for the Internet as a whole.
- Prismatic: we also learned content distribution is a tough business and we’ve failed to grow at a rate that justifies continuing to support our Prismatic News Continue reading
How Does the Use of Docker Effect Latency?

A great question came up on the mechanical-sympathy list that many others probably have as well:
I keep hearing about [Docker] as if it is the greatest thing since sliced bread, but I've heard anecdotal evidence that low latency apps take a hit.
Who better to answer than Gil Tene, Vice President of Technology and CTO, Co-Founder, of Azul Systems? Like Stephen Curry draining a deep transition three, Gil can always be counted on for his insight:
- The Black Magic Of Systematically Reducing Linux OS Jitter
- Your Load Generator Is Probably Lying To You - Take The Red Pill And Find Out Why
And here's Gil's answer:
Putting aside questions of taste and style, and focusing on the effects on latency (the original question), the analysis from a pure mechanical point of view is pretty simple: Docker uses Linux containers as a means of execution, with no OS virtualization layer for CPU and memory, and with optional (even if default is on) virtualization layers for i/o.
CPU and Memory
From a latency point of view, Docker's (and any other Linux container's) CPU and memory latency characteristics are pretty much indistinguishable from Linux itself. But the same things Continue reading
Does AMP Counter an Existential Threat to Google?

When AMP (Accelerated Mobile Pages) was first announced it was right inline with Google’s long standing project to make the web faster. Nothing seemingly out of the ordinary.
Then I listened to a great interview on This Week in Google with Richard Gingras, Head of News at Google, that made it clear AMP is more than just another forward looking initiative from Google. Much more.
What is AMP? AMP is two things. AMP is a restricted subset of HTML designed to make the web fast on mobile devices. AMP is also a strategy to counter an existential threat to Google: the mobile web is in trouble and if the mobile web is in trouble then Google is in trouble.
In the interview Richard says (approximately):
The alternative [to a strong vibrant community around AMP] is devastating. We don’t want to see a decline in the viability of the mobile web. We don’t want to see poor experiences on the mobile web propel users into proprietary platforms.
This point, or something very like it, is repeated many times during the interview. With ad blocker usage on the rise there’s a palpable sense of urgency to do something. So Google stepped Continue reading
Stuff The Internet Says On Scalability For December 11th, 2015
Hey, it's HighScalability time:

- 100 million: John Henry as played by a conventional computer loses to a quantum computer; 400,000: cores in PayPal's OpenStack deployment; 10TB: max size of Google Cloud SQL database; 9%: Kickstarter projects that don't deliver; $2.3 trillion: worth of The Forbes 400 members; billions: worth of Spanish treasure ship;
- Quotable Quotes:
- Pandalicious: I actually expect that down the road most large open source projects will start distributing a standardized build environment via docker containers.
- @glasnt: "Optimise for speed flexibility & evolution" "Whoever is iterating faster has a huge advantage" - @adrianco #yow15
- @erikbryn: LIDAR goes from $75K to $500, leaves Moore's Law in the Dust
- Henry Miller: One has to believe wholeheartedly in what one is doing, realize that it is the best one can do at the moment—forego perfection now and always!—and accept the consequences which giving birth entails.
- @jedws: "uber is way more reliable on Saturday and Sunday because there are no engineers working on the.system" #yow15
- Continue reading
Free Red Book: Readings in Database Systems, 5th Edition

For the first time in ten years there has been an update to the classic Red Book, Readings in Database Systems, which offers "readers an opinionated take on both classic and cutting-edge research in the field of data management."
Editors Peter Bailis, Joseph M. Hellerstein, and Michael Stonebraker curated the papers and wrote pithy introductions. Unfortunately, links to the papers are not included, but a kindly wizard, Nindalf, gathered all the referenced papers together and put them in one place.
What's in it?
- Preface
- Background introduced by Michael Stonebraker
- Traditional RDBMS Systems introduced by Michael Stonebraker
- Techniques Everyone Should Know introduced by Peter Bailis
- New DBMS Architectures introduced by Michael Stonebraker
- Large-Scale Dataflow Engines introduced by Peter Bailis
- Weak Isolation and Distribution introduced by Peter Bailis
- Query Optimization introduced by Joe Hellerstein
- Interactive Analytics introduced by Joe Hellerstein
- Languages introduced by Joe Hellerstein
- Web Data introduced by Peter Bailis
- A Biased Take on a Moving Target: Complex Analytics by Michael Stonebraker
- A Biased Take on a Moving Target: Data Integration by Michael Stonebraker
Related Articles
Sponsored Post: StatusPage.io, Redis Labs, Jut.io, SignalFx, InMemory.Net, VividCortex, MemSQL, Scalyr, AiScaler, AppDynamics, ManageEngine, Site24x7

Who's Hiring?
- Senior Devops Engineer - StatusPage.io is looking for a senior devops engineer to help us in making the internet more transparent around downtime. Your mission: help us create a fast, scalable infrastructure that can be deployed to quickly and reliably.
- At Scalyr, we're analyzing multi-gigabyte server logs in a fraction of a second. That requires serious innovation in every part of the technology stack, from frontend to backend. Help us push the envelope on low-latency browser applications, high-speed data processing, and reliable distributed systems. Help extract meaningful data from live servers and present it to users in meaningful ways. At Scalyr, you’ll learn new things, and invent a few of your own. Learn more and apply.
- UI Engineer– AppDynamics, founded in 2008 and lead by proven innovators, is looking for a passionate UI Engineer to design, architect, and develop our their user interface using the latest web and mobile technologies. Make the impossible possible and the hard easy. Apply here.
- Software Engineer - Infrastructure & Big Data – AppDynamics, leader in next generation solutions for managing modern, distributed, and extremely complex applications residing in both the cloud and the data center, is Continue reading
The Serverless Start-up – Down with Servers!
![]()
This is a guest post by Marcel Panse and Sander Nagtegaal from Teletext.io.
In our early Peecho days, we wrote an article explaining how to build a really scalable architecture for next to nothing, using Amazon Web Services. Auto-scaling, merciless decoupling and even automated bidding on unused server capacity were the tricks we used back then to operate on a shoestring. Now, it is time to take it one step further.
We would like to introduce Teletext.io, also known as the serverless start-up - again, entirely built around AWS, but leveraging only the Amazon API Gateway, Lambda functions, DynamoDb, S3 and Cloudfront.
The Virtues of Constraint
We like rules. At our previous start-up Peecho, product owners had to do fifty push-ups as payment for each user story that they wanted to add to an ongoing sprint. Now, at our current company myTomorrows, our developer dance-offs are legendary: during the daily stand-ups, you are only allowed to speak while dancing - leading to the most efficient meetings ever.
This way of thinking goes all the way into our product development. It may seem counter-intuitive at first, but constraints fuel creativity. For example, all Continue reading
Stuff The Internet Says On Scalability For December 4th, 2015
Hey, it's HighScalability time:

- 434,000: square-feet in Facebook's new office; $62.5 billion: Uber's valuation; 11: DigitalOcean datacenters; $4.45 billion: black Friday online sales; 2MPH: speed news traveled in 1500; 95: percent of world covered by mobile broadband; 86%: items Amazon delivers that weigh less than five pounds.
- Quotable Quotes:
- Jeremy Hsu: Is anybody thinking about how we’ll have to code differently to accommodate the jump from a 1-exaflop supercomputer to 10 exaflops? There is not enough attention being paid to this issue.
- @kml: “Process drives away talent” - @adrianco at #yow15
- capkutay: Seems like a lot of the momentum behind containers is driven by the Silicon Valley investment community.
- @taotetek: IoT is turning homes into datacenters with no system administrators and no security team.
- @asymco: On Thursday and early Friday, mobile traffic accounted for nearly 60% of all online shopping traffic, and 40% of all online sales
- Mobile App Developers are Suffering: It’s Continue reading
Deep Lessons from Google and eBay on Building Ecosystems of Microservices
When you look at large scale systems from Google, Twitter, eBay, and Amazon, their architecture has evolved into something similar: a set of polyglot microservices.
What does it looks like when you are in the polyglot microservices end state? Randy Shoup, who worked in high level positions at both Google and eBay, has a very interesting talk exploring just that idea: Service Architectures at Scale: Lessons from Google and eBay.
What I really like about Randy's talk is how he is self-consciously trying to immerse you in the experience of something you probably have no experience of: creating, using, perpetuating, and protecting a large scale architecture.
In the Ecosystem of Services section of the talk Randy asks: What does it look like to have a large scale ecosystem of polyglot microservices? In the Operating Services at Scale section he asks: As a service provider what does it feel like to operate such a service? In the Building a Service section he asks: When you are a service owner what does it look like? And in the Service Anti-Patterns section he asks: What can go wrong?
A very powerful approach.
The highlight of the talk for me was the idea of Continue reading
Stuff The Internet Says On Scalability For November 27th, 2015
Hey, it's HighScalability time:
- $40 billion: P2P lending in China; 20%: amount of all US margin expansion accounted for by Apple since 2010; 11: years of Saturn photos; 117: number of different steering wheels offered for a VW Golf; 1Gbps: speed of a network using a lightbulb.
- Quotable Quotes:
- @jaksprats: If we could compile a subset of JavaScript to Lua, JS could run on Server(Node,js), Browser, Desktop, iOS, & Android.JS could run EVERYWHERE
- @wilkieii: Tech: "Don't roll your own crypto if you aren't an expert" *replaces nutrition with Soylent, currency with bitcoin* *puts wifi in lightbulb*
- @brianpeddle: The architecture of one human brain would require a zettabyte of capacity. Full simulation of a human brain by 2023.
- MarshalBanana: That can still easily be the right choice. Complex algorithms trade asymptotic performance for setup cost and maintenance cost. Sometimes the tradeoff isn't worth it.
- kevindeasi: There are so many things to know nowadays. Backend: Sql, NoSql, NewSql, etc. Middlware: Django, NodeJs, Spring, Groovy, RoR, Symfony, etc. Client: Angular, Ember, React, Jquery, etc. I haven't even mentioned hardware, security, Continue reading
Sponsored Post: StatusPage.io, iStreamPlanet, Redis Labs, Jut.io, SignalFx, InMemory.Net, VividCortex, MemSQL, Scalyr, AiScaler, AppDynamics, ManageEngine, Site24x7
Who's Hiring?
- Senior Devops Engineer - StatusPage.io is looking for a senior devops engineer to help us in making the internet more transparent around downtime. Your mission: help us create a fast, scalable infrastructure that can be deployed to quickly and reliably.
- As a Networking & Systems Software Engineer at iStreamPlanet you’ll be driving the design and implementation of a high-throughput video distribution system. Our cloud-based approach to video streaming requires terabytes of high-definition video routed throughout the world. You will work in a highly-collaborative, agile environment that thrives on success and eats big challenges for lunch. Please apply here.
- As a Scalable Storage Software Engineer at iStreamPlanet you’ll be driving the design and implementation of numerous storage systems including software services, analytics and video archival. Our cloud-based approach to world-wide video streaming requires performant, scalable, and reliable storage and processing of data. You will work on small, collaborative teams to solve big problems, where you can see the impact of your work on the business. Please apply here.
- At Scalyr, we're analyzing multi-gigabyte server logs in a fraction of a second. That requires serious innovation in every part of the technology stack, from frontend to backend. Continue reading
How Wistia Handles Millions of Requests Per Hour and Processes Rich Video Analytics
This is a guest repost from Christophe Limpalair of his interview with Max Schnur, Web Developer at Wistia.
Wistia is video hosting for business. They offer video analytics like heatmaps, and they give you the ability to add calls to action, for example. I was really interested in learning how all the different components work and how they’re able to stream so much video content, so that’s what this episode focuses on.
What does Wistia’s stack look like?
As you will see, Wistia is made up of different parts. Here are some of the technologies powering these different parts:
- HAProxy
- Nginx
- MySQL (Sharded)
- Ruby on Rails
- Unicorn and some services run on Puma
- nsq (they wrote the Ruby library)
- Redis (caching)
- Sidekiq for async job
What scale are you running at?
Stuff The Internet Says On Scalability For November 20th, 2015
Hey, it's HighScalability time:

- $24 billion: amount telcos make selling data about you; $500,000: cost of iOS zero day exploit; 50%: a year's growth of internet users in India; 72: number of cores in Intel's new chip; 30,000: Docker containers started on 1,000 nodes; 1962: when the first Cathode Ray Tube entered interplanetary space; 2x: cognitive improvement with better indoor air quality; 1 million: Kubernetes request per second;
- Quotable Quotes:
- Zuckerberg: One of our goals for the next five to 10 years is to basically get better than human level at all of the primary human senses: vision, hearing, language, general cognition.
- Sawyer Hollenshead: I decided to do what any sane programmer would do: Devise an overly complex solution on AWS for a seemingly simple problem.
- Marvin Minsky: Big companies and bad ideas don't mix very well.
- @mathiasverraes: Events != hooks. Hooks allow you to reach into a procedure, change its state. Events communicate state change. Hooks couple, events decouple
- @neil_conway: Lamport, trolling distributed systems engineers since 1998. Continue reading
Free Book: Practical Scalablility Analysis with the Universal Scalability Law

If you are very comfortable with math and modeling Dr. Neil Gunther's Universal Scalability Law is a powerful way of predicting system performance and whittling down those bottlenecks. If not, the USL can be hard to wrap your head around.
There's a free eBook for that. Performance and scalability expert Baron Schwartz, founder of VividCortex, has written a wonderful exploration of scalability truths using the USL as a lens: Practical Scalablility Analysis with the Universal Scalability Law.
As a sample of what you'll learn, here are some of the key takeaways from the book:
- Scalability is a formal concept that is best defined as a mathematical function.
- Linear scalability means equal return on investment. Double down on workers and you’ll get twice as much work done; add twice as many nodes and you’ll increase the maximum capacity twofold. Linear scalability is oft claimed but seldom delivered.
- Systems scale sublinearly because of contention, which adds queueing delay, and crosstalk, which inflates service times. The penalty for contention grows linearly and the crosstalk penalty grows quadratically. (An alternative to the crosstalk theory is that longer queues are more costly to manage.)
- Contention causes throughput to asymptotically approach the reciprocal of Continue reading
9ish Low Latency Strategies for SaaS Companies

Achieving very low latencies takes special engineering, but if you are a SaaS company latencies of a few hundred milliseconds are possible for complex business logic using standard technologies like load balancers, queues, JVMs, and rest APIs.
Itai Frenkel, a software engineer at Forter, which provides a Fraud Prevention Decision as a Service, shows how in an excellent article: 9.5 Low Latency Decision as a Service Design Patterns.
While any article on latency will have some familiar suggestions, Itai goes into some new territory you can really learn from. The full article is rich with detail, so you'll want to read it, but here's a short gloss:
How Facebook’s Safety Check Works
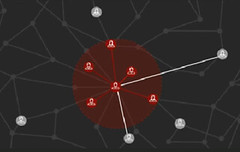
I noticed on Facebook during this horrible tragedy in Paris that there was some worry because not everyone had checked in using Safety Check. So I thought people might want to know a little more about how Safety Check works.
If a friend or family member hasn't checked-in yet it doesn't mean anything bad has happened to them. Please keep that in mind. Safety Check is a good system, but not a perfect system, so keep your hopes up.
This is a really short version, there's a longer article if you are interested.
-
How it works:
-
If you are in an area impacted by a disaster Facebook will send you a push notification asking if you are OK.
-
Tapping the “I’m Safe” button marks that your are safe.
-
All your friends are notified that you are safe.
-
Friends can also see a list of all the people impacted by the disaster and how they are doing.
-
-
How do you build the pool of people impacted by a disaster in a certain area? Building a geoindex is the obvious solution, but it has weaknesses.
-
People are constantly moving so the index will be stale.
-
A geoindex of 1.5 billion Continue reading
-
Stuff The Internet Says On Scalability For November 13th, 2015
Hey, it's HighScalability time:

- 14.3 billion: Alibaba single day sales; 1.55 billion: Facebook monthly active users; 6 billion: Snapchat video views per day; unlimited: now defined as 300 GB by Comcast; 80km: circumference of China's proposed supercolider; 500: alien worlds visualized; 50: future sensors per acre on farms; 1 million: Instagram requests per second.
- Quotable Quotes:
- Adam Savage~ Lesson learned: do not test fire rockets indoors.
- dave_sullivan: I'm going to say something unpopular, but horizontally-scaled deep learning is overkill for most applications. Can anyone here present a use case where they have personally needed horizontal scaling because a Titan X couldn't fit what they were trying to do?
- @bcantrill: Question I've been posing at #KubeCon: are we near Peak Confusion in the container space? Consensus: no -- confusion still accelerating!
- @PeterGleick: When I was born, CO2 levels were ~300 ppm. This week may be the last time anyone alive will see less than 400 ppm.
- @patio11: "So I'm clear on this: our business is to employ Continue reading
Sponsored Post: StatusPage.io, Digit, iStreamPlanet, Instrumental, Redis Labs, Jut.io, SignalFx, InMemory.Net, VividCortex, MemSQL, Scalyr, AiScaler, AppDynamics, ManageEngine, Site24x7
Who's Hiring?
- Senior Devops Engineer - StatusPage.io is looking for a senior devops engineer to help us in making the internet more transparent around downtime. Your mission: help us create a fast, scalable infrastructure that can be deployed to quickly and reliably.
- Digit Game Studios, Irish’s largest game development studio, is looking for game server engineers to work on existing and new mobile 3D MMO games. Our most recent project in development is based on an iconic AAA-IP and therefore we expect very high DAU & CCU numbers. If you are passionate about games and if you are experienced in creating low-latency architectures and/or highly scalable but consistent solutions then talk to us and apply here.
- As a Networking & Systems Software Engineer at iStreamPlanet you’ll be driving the design and implementation of a high-throughput video distribution system. Our cloud-based approach to video streaming requires terabytes of high-definition video routed throughout the world. You will work in a highly-collaborative, agile environment that thrives on success and eats big challenges for lunch. Please apply here.
- As a Scalable Storage Software Engineer at iStreamPlanet you’ll be driving the design and implementation of numerous storage systems including software services, analytics and video Continue reading
A 360 Degree View of the Entire Netflix Stack

This is a guest repost by Chris Ueland, creator of Scale Scale, with a creative high level view of the Netflix stack.
As we research and dig deeper into scaling, we keep running into Netflix. They are very public with their stories. This post is a round up that we put together with Bryan’s help. We collected info from all over the internet. If you’d like to reach out with more info, we’ll append this post. Otherwise, please enjoy!
–Chris / ScaleScale / MaxCDN
