Stuff The Internet Says On Scalability For November 6th, 2015
Hey, it's HighScalability time:

- 9,000: Artifacts Uncovered in California Desert; 400 Million: LinkedIn members; 100: CEOs have more retirement assets than 41% of American families; $160B: worth of AWS; 12,000: potential age of oldest oral history; fungi: world's largest miners
- Quotable Quotes:
- @jaykreps: Someone tell @TheEconomist that people claiming you can build Facebook on top of a p2p blockchain are totally high.
- Larry Page: I think my job is to create a scale that we haven't quite seen from other companies. How we invest all that capital, and so on.
- Tiquor: I like how one of the oldest concepts in programming, the ifdef, has now become (if you read the press) a "revolutionary idea" created by Facebook and apparently the core of a company's business. I'm only being a little sarcastic.
- @DrQz: +1 Data comes from the Devil, only models come from God.
- @DakarMoto: Great talk by @adrianco today quote of the day "i'm getting bored with #microservices, and I’m getting very interested in #teraservices.”
- @adrianco: Early #teraservices enablers - Diablo Memory1 DIMMs, 2TB AWS X1 instances, in-memory databases and analytics...
- @PatrickMcFadin: Average DRAM Contract Price Continue reading
Strategy: Avoid Lots of Little Files

I've been bitten by this one. It happens when you quite naturally use the file system as a quick and dirty database. A directory is a lot like a table and a file name looks a lot like a key. You can store many-to-one relationships via subdirectories. And the path to a file makes a handy quick lookup key.
The problem is a file system isn't a database. That realization doesn't hit until you reach a threshold where there are actually lots of files. Everything works perfectly until then.
When the threshold is hit iterating a directory becomes very slow because most file system directory data structures are not optimized for the lots of small files case. And even opening a file becomes slow.
According to Steve Gibson on Security Now (@16:10) LastPass ran into this problem. LastPass stored every item in their vault in an individual file. This allowed standard file syncing technology to be used to update only the changed files. Updating a password changes just one file so only that file is synced.
Steve thinks this is a design mistake, but this approach makes perfect sense. It's simple and robust, which is good design given, what I assume, Continue reading
Paper: Coordination Avoidance in Distributed Databases By Peter Bailis

Peter Bailis has released the work of a lifetime, his dissertion is now available online: Coordination Avoidance in Distributed Databases.
The topic Peter is addressing is summed up nicely by his thesis statement:
Many semantic requirements of database-backed applications can be efficiently enforced without coordination, thus improving scalability, latency, and availability.
I'd like to say I've read the entire dissertation and can offer cogent insightful analysis, but that would be a lie. Though I have watched several of Peter's videos (see Related Articles). He's doing important and interesting work, that as much University research has done, may change the future of what everyone is doing.
From the introduction:
The rise of Internet-scale geo-replicated services has led to upheaval in the design of modern data management systems. Given the availability, latency, and throughput penalties associated with classic mechanisms such as serializable transactions, a broad class of systems (e.g., “NoSQL”) has sought weaker alternatives that reduce the use of expensive coordination during system operation, often at the cost of application integrity. When can we safely forego the cost of this expensive coordination, and when must we pay the price?
In this thesis, we investigate the potential for coordination avoidance—the Continue reading
How Shopify Scales to Handle Flash Sales from Kanye West and the Superbowl

This is a guest repost by Christophe Limpalair, creator of Scale Your Code.
In this article, we take a look at methods used by Shopify to make their platform resilient. Not only is this interesting to read about, but it can also be practical and help you with your own applications.
Shopify's Scaling Challenges
Shopify, an ecommerce solution, handles about 300 million unique visitors a month, but as you'll see, these 300M people don't show up in an evenly distributed fashion.
One of their biggest challenge is what they call "flash sales". These flash sales are when tremendously popular stores sell something at a specific time.
For example, Kanye West might sell new shoes. Combined with Kim Kardashian, they have a following of 50 million people on Twitter alone.
They also have customers who advertise on the Superbowl. Because of this, they have no idea how much traffic to expect. It could be 200,000 people showing up at 3:00 for a special sale that ends within a few hours.
How does Shopify scale to these sudden increases in traffic? Even if they can't scale that well for a particular sale, how can they make sure it doesn't affect Continue reading
Stuff The Internet Says On Scalability For October 30th, 2015
Hey, it's HighScalability time:

Movie goers Force Crashed websites with record ticket presales. Yoda commented: Do. Or do not. There is no try.
- $51.5 billion: Apple quarterly revenue; 1,481: distance in light years of a potential Dyson Sphere; $470 billion: size of insurance industry data play; 31,257: computer related documents in a scanned library; $1.2B: dollars lost to business email scams; 46 billion: pixels in largest astronomical image; 27: seconds of distraction after doing anything interesting in a car; 10 billion: transistor SPARC M7 chip; 10K: cost to get a pound in to low earth orbit; $8.2 billion: Microsoft cloud revenue;
- Quotable Quotes:
- @jasongorman: A $trillion industry has been built on the very lucky fact that Tim Berners-Lee never thought "how do I monetise this?"
- Cade Metz: Sure, the app [WhatsApp] was simple. But it met a real need. And it could serve as a platform for building all sorts of other simple services in places where wireless bandwidth is limited but people are hungry for the sort of instant communication we take for granted here in the US.
- Adrian Hanft: Brand experts insist that success comes from promoting your Continue reading
Five Lessons from Ten Years of IT Failures

IEEE Spectrum has a wonderful article series on Lessons From a Decade of IT Failures. It’s not your typical series in that there are very cool interactive graphs and charts based on data collected from past project failures. They are really fun to play with and I can only imagine how much work it took to put them together.
The overall takeaway of the series is:
Even given the limitations of the data, the lessons we draw from them indicate that IT project failures and operational issues are occurring more regularly and with bigger consequences. This isn’t surprising as IT in all its various forms now permeates every aspect of global society. It is easy to forget that Facebook launched in 2004, YouTube in 2005, Apple’s iPhone in 2007, or that there has been three new versions of Microsoft Windows released since 2005. IT systems are definitely getting more complex and larger (in terms of data captured, stored and manipulated), which means not only are they increasing difficult and costly to develop, but they’re also harder to maintain.
Here are the specific lessons:
Sponsored Post: Digit, iStreamPlanet, Instrumental, Redis Labs, Jut.io, SignalFx, InMemory.Net, VividCortex, MemSQL, Scalyr, AiScaler, AppDynamics, ManageEngine, Site24x7

Who's Hiring?
- Digit Game Studios, Irish’s largest game development studio, is looking for game server engineers to work on existing and new mobile 3D MMO games. Our most recent project in development is based on an iconic AAA-IP and therefore we expect very high DAU & CCU numbers. If you are passionate about games and if you are experienced in creating low-latency architectures and/or highly scalable but consistent solutions then talk to us and apply here.
- As a Networking & Systems Software Engineer at iStreamPlanet you’ll be driving the design and implementation of a high-throughput video distribution system. Our cloud-based approach to video streaming requires terabytes of high-definition video routed throughout the world. You will work in a highly-collaborative, agile environment that thrives on success and eats big challenges for lunch. Please apply here.
- As a Scalable Storage Software Engineer at iStreamPlanet you’ll be driving the design and implementation of numerous storage systems including software services, analytics and video archival. Our cloud-based approach to world-wide video streaming requires performant, scalable, and reliable storage and processing of data. You will work on small, collaborative teams to solve big problems, where you can see the impact of your work on the business. Continue reading
What ideas in IT must die?

Are there ideas in IT that must die for progress to be made?
Max Planck wryly observed that scientific progress is often less meritocracy and more Lord of the Flies:
A new scientific truth does not triumph by convincing its opponents and making them see the light, but rather because its opponents eventually die, and a new generation grows up that is familiar with it.
Playing off this insight is a thought provoking book collection of responses to a question posed on the Edge: This Idea Must Die: Scientific Theories That Are Blocking Progress. From the book blurb some of the ideas that should transition into the postmortem are: Jared Diamond explores the diverse ways that new ideas emerge; Nassim Nicholas Taleb takes down the standard deviation; Richard Thaler and novelist Ian McEwan reveal the usefulness of "bad" ideas; Steven Pinker dismantles the working theory of human behavior.
Let’s get edgy: Are there ideas that should die in IT?
What ideas do you think should pass into the great version control system called history? What ideas if garbage collected would allow us to transmigrate into a bright shiny new future? Be as deep and bizarre as you want. This is Continue reading
Stuff The Internet Says On Scalability For October 23rd, 2015
Hey, it's HighScalability time:

- $18 billion: wasted on US Army Future Combat system; 70%: Americans who support an Internet sales tax; $1.3 billion: wasted on an interoperable health record system; trillions: NSA breaking Web and VPN connections; 615: human data teams beat by a computer; $900,000: cost of apps on your smartphone 30 years ago.
- Quotable Quotes:
- @PatrickMcFadin: 'Sup 10x coder. Grace Hopper invented the compiler and has a US Navy destroyer named after her. Just how badass are you again?
- @benwerd: I love Marty McFly too, but more importantly, the first transatlantic voice transmission was sent 100 years ago today. What a century.
- Martin Goodwell: The nearly two-billion requests that Netflix receives each day result in roughly 20 billion internal API calls.
- sigma914: It's great to see people implementing distributed services using a vertically scalable technology stack again. The past ~decade has seen a lot of "We can scale sideways so constant overheads are irrelevant! We'll just use Java and add Continue reading
5 Lessons from 5 Years of Building Instagram

Instagram has always been generous in sharing their accumulated wisdom. Just take a look at the Related Articles section of this post to see how generous.
The tradition continues. Mike Krieger, Instagram co-founder, wrote a really good article on lessons learned from milestones achieved during Five Years of Building Instagram. Here's a summary of the lessons, but the article goes into much more of the connective tissue and is well worth reading.
- Do the simple thing first. This is the secret of supporting exponential growth. There's no need to future proof everything you do. That leads to paralysis. For each new challenge find the fastest, simplest fix for each.
- Do fewer things better. Focus on a single platform. This allows you to iterate faster because not everything has to be done twice. When you have to expand create a team explicitly for each platform.
- Upfront work but can pay huge dividends. Create an automated scriptable infrastructure implementing a repeatable server provisioning process. This makes it easier to bring on new hires and handle disasters. Hire engineers with the right stuff who aren't afraid to work through a disaster.
- Don’t reinvent the wheel. Instagram moved to Facebook's infrastructure because Continue reading
Segment: Rebuilding Our Infrastructure with Docker, ECS, and Terraform
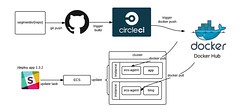
This is a guest repost from Calvin French-Owen, CTO/Co-Founder of Segment.
In Segment’s early days, our infrastructure was pretty hacked together. We provisioned instances through the AWS UI, had a graveyard of unused AMIs, and configuration was implemented three different ways.
As the business started taking off, we grew the size of the eng team and the complexity of our architecture. But working with production was still limited to a handful of folks who knew the arcane gotchas. We’d been improving the process incrementally, but we needed to give our infrastructure a deeper overhaul to keep moving quickly.
So a few months ago, we sat down and asked ourselves: “What would an infrastructure setup look like if we designed it today?”
Over the course of 10 weeks, we completely re-worked our infrastructure. We retired nearly every single instance and old config, moved our services to run in Docker containers, and switched over to use fresh AWS accounts.
We spent a lot of time thinking about how we could make a production setup that’s auditable, simple, and easy to use–while still allowing for the flexibility to scale and grow.
Here’s our solution.
Separate AWS Accounts
Stuff The Internet Says On Scalability For October 16th, 2015
Hey, it's HighScalability time:

The other world beauty of the world's largest underground Neutrino Detector. Yes, this is a real thing.
- 170,000: depression era photos; $465m: amount lost due to a software bug; 368,778: likes in 4 hours as a reaction to Mark Zuckerberg's post on Reactions; 1.8 billion: pictures uploaded every day; 158: # of families generously volunteering to privately fund US elections.
- Quotable Quotes:
- @PreetamJinka: I want to run a 2 TB #golang program with 100 vCPUs on an AWS X1 instance.
- Richard Stallman: The computer industry is the only industry that is more fashion-driven than women's fashion.
- The evolution of bottlenecks in the Big Data ecosystem: Seeing all these efforts to bypass the garbage collector, we are entitled to wonder why we use a platform whose main asset is to offer a managed memory, if it is to avoid using it?
- James Hamilton: Services like Lambda that abstract away servers entirely make it even easier to run alternative instruction set architectures.
- @adrianfcole: Q: Are we losing money? A: Continue reading
Save some bandwidth by turning off TCP Timestamps

This is a guest post by Donatas Abraitis, System Engineer at Vinted, with an unusual approach for saving a little bandwidth.
Looking at https://tools.ietf.org/html/rfc1323 there is a nice title: 'TCP Extensions for High Performance'. It's worth to take a look at date May 1992. Timestamps option may appear in any data or ACK segment, adding 12 bytes to the 20-byte TCP header.
Using TCP options, the sender places a timestamp in each data segment, and the receiver reflects these timestamps back in ACK segments. Then a single subtract gives the sender an accurate RTT measurement for every ACK segment.
To prove this let's dig into kernel source:
./include/net/tcp.h:#define TCPOLEN_TSTAMP_ALIGNED 12
./net/ipv4/tcp_output.c:static void tcp_connect_init(struct sock *sk)
...
tp->tcp_header_len = sizeof(struct tcphdr) +
(sysctl_tcp_timestamps ? TCPOLEN_TSTAMP_ALIGNED : 0);
Some visualizations:
More concurrency: Improved locking in PostgreSQL
If you want to build a large scale website, scaling out the webserver is not enough. It is also necessary to cleverly manage the database side. a key to high scalability is locking.
In PostgreSQL we got a couple of new cool features to reduce locking and to speed up things due to improved concurrency.
General recommendations: Before attacking locking, however, it makes sense to check what is really going on on your PostgreSQL database server. To do so I recommend to take a look at pg_stat_statements and to carefully track down bottlenecks. Here is how it works:
Sponsored Post: IStreamPlanet, Close.Io, Instrumental, Location Labs, Surge, Redis Labs, Jut.Io, VoltDB, Datadog, SignalFx, InMemory.Net, VividCortex, MemSQL, Scalyr, AiScaler, AppDynamics, ManageEngine, Site24x7
Who's Hiring?
- As a Networking & Systems Software Engineer at iStreamPlanet you’ll be driving the design and implementation of a high-throughput video distribution system. Our cloud-based approach to video streaming requires terabytes of high-definition video routed throughout the world. You will work in a highly-collaborative, agile environment that thrives on success and eats big challenges for lunch. Please apply here.
- As a Scalable Storage Software Engineer at iStreamPlanet you’ll be driving the design and implementation of numerous storage systems including software services, analytics and video archival. Our cloud-based approach to world-wide video streaming requires performant, scalable, and reliable storage and processing of data. You will work on small, collaborative teams to solve big problems, where you can see the impact of your work on the business. Please apply here.
- Close.io is a *profitable* fast-growing SaaS startup looking for a Lead DevOps/Infrastructure engineer to join our ~10 person team in Palo Alto or *remotely*. Come help us improve API performance, tune our databases, tighten up security, setup autoscaling, make deployments faster and safer, scale our MongoDB/Elasticsearch/MySQL/Redis data stores, setup centralized logging, instrument our app with metric collection, set up better monitoring, etc. Learn more and apply here.
- Location Labs is Continue reading
Making the Case for Building Scalable Stateful Services in the Modern Era
For a long time now stateless services have been the royal road to scalability. Nearly every treatise on scalability declares statelessness as the best practices approved method for building scalable systems. A stateless architecture is easy to scale horizontally and only requires simple round-robin load balancing.
What’s not to love? Perhaps the increased latency from the roundtrips to the database. Or maybe the complexity of the caching layer required to hide database latency problems. Or even the troublesome consistency issues.
But what of stateful services? Isn’t preserving identity by shipping functions to data instead of shipping data to functions a better approach? It often is, but we don’t hear much about how to build stateful services. In fact, do a search and there’s very little in the way of a systematic approach to building stateful services. Wikipedia doesn’t even have an entry for stateful service.
Caitie McCaffrey, Tech Lead for Observability at Twitter, is fixing all that with a refreshing talk she gave at the Strange Loop conference on Building Scalable Stateful Services (slides).
Refreshing because I’ve never quite heard of building stateful services in the way Caitie talks about building them. You’ll recognize most of the Continue reading
Stuff The Internet Says On Scalability For October 9th, 2015
Hey, it's HighScalability time:

- millions: # of Facebook users have no idea they’re using the internet; 8%: total of wealth in tax havens; $7.3B: AWS revenues; 11X: YouTube bigger than Facebook; 10: days 6s would last on diesel; 65: years ago the transistor was patented; 80X: reduction in # of new drugs approved per billion US dollars spent since 1950; 37 trillion: cells in the human body; 83%: accuracy of predicting activities from pictures.
- Quotable Quotes:
- @Nick_Craver: Stack Overflow HTTP, last 30 days: Bytes 128,095,601,184,645 Hits 5,795,253,218 Pages 1,921,499,030 SQL 19,229,946,858 Redis 11,752,754,019
- @merv: #reinvent Amazon process for creating new offerings: once decision is made "write the press release and the FAQ you’ll use - then build it."
- @PaulMiller: @monkchips to @ajassy, “One of your biggest competitors is stupidity.” Quite. Or inertia. #reInvent
- @DanHarper7: If SpaceX can publish their pricing for going to space, your little SaaS does NOT need "Contact us for pricing"
- Continue reading
Zappos’s Website Frozen for Two Years as it Integrates with Amazon

Here's an interesting nugget from a wonderfully written and deeply interesting article by Roger Hodge in the New Republic: A radical experiment at Zappos to end the office workplace as we know it:
Zappos's customer-facing web site has been basically frozen for the last few years while the company migrates its backend systems to Amazon's platforms, a multiyear project known as Supercloud.
It's a testament to Zappos that they still sell well with a frozen website while most of the rest of the world has adopted a model of continuous deployment and constant evolution across multiple platforms.
Amazon is requiring the move, otherwise a company like Zappos would probably be sensitive to the Conway's law implication of such a deep integration. Keep in mind Facebook is reportedly keeping WhatsApp and Instagram independent. This stop the world plan must mean something, unfortunately I don't have the strategic insight to understand why this might be. Any thoughts?
The article has more tantalizing details about what's going on with the move:
Your Load Generator is Probably Lying to You – Take the Red Pill and Find Out Why

Pretty much all your load generation and monitoring tools do not work correctly. Those charts you thought were full of relevant information about how your system is performing are really just telling you a lie. Your sensory inputs are being jammed.
To find out how listen to the Morpheous of performance monitoring Gil Tene, CTO and co-founder at Azul Systems, makers of truly high performance JVMs, in a mesmerizing talk on How NOT to Measure Latency.
This talk is about removing the wool from your eyes. It's the red pill option for what you thought you were testing with load generators.
Some highlights:
-
If you want to hide the truth from someone show them a chart of all normal traffic with one just one bad spike surging into 95 percentile territory.
-
The number one indicator you should never get rid of is the maximum value. That’s not noise, it’s the signal, the rest is noise.
-
99% of users experience ~99.995%’ile response times, so why are you even looking at 95%'ile numbers?
-
Monitoring tools routinely drop important samples in the result set, leading you to draw really bad conclusions about the quality of the performance of Continue reading
Stuff The Internet Says On Scalability For October 2nd, 2015
Hey, it's HighScalability time:

Elon Musk's presentation of the Tesla Model X had more in common with a new iPhone event than a traditional car demo.
- 1.4 billion: Android devices; 1000: # of qubits in Google's new quantum computer; 150Gbps: Linux botnet DDoS attack; 3,000: iPhones sold per minute; smith: the most common last name in the US; 50%: storage reduction by using erasure coding in Hadoop; 101: calories burned during sex.
- Quotable Quotes:
- @peterseibel: How to be a 10x engineer: help ten other engineers be twice as good.
- The Master Algorithm: Scientists make theories, and engineers make devices. Computer scientists make algorithms, which are both theories and devices
- @immolations: Feudalism may not be perfect but it's the best system we've got. More of us have chainmail today than at any point in history
- @mjpt777: We managed to transfer almost 10 GB/s worth of 1000 byte messages via Aeron IPC. That's more than a 100GigE network. Way to scale up on box!
- @caitie: lol what my services do 1.5 billion writes per Continue reading