netlab as the Universal Configuration Translator
Dan Partelly, a heavy netlab user (and an active contributor), sent me this interesting perspective on how one might want to use netlab without ever building a lab with it. All I added was a bit of AI-assisted editing; my comments are on a grey background.
In all podcasts and interviews I listened to, netlab was referred to as a “lab management solution”. But this is misleading. It’s also a translator, due to its ability to abstract devices, and can easily generate perfectly usable configs for devices or technologies you have never worked on.
Fun Reading: From XML to LLMs
In his latest blog post (Systems design 3: LLMs and the semantic revolution), Avery Pennarun claims that LLMs might solve the problem we consistently failed to solve on a large scale for the last 60 (or so) years – the automated B2B data exchange.
You might agree with him or not (for example, an accountant or two might get upset with hallucinated invoice items), but his articles are always a fun read.
Lab: IS-IS Route Redistribution
Route redistribution into IS-IS seems even easier than its OSPFv2/OSPFv3 counterparts. There are no additional LSAs/LSPs; the redistributed prefixes are included in the router LSP. Things get much more interesting once you start looking into the gory details and exploring how different implementations use (or do not) the various metric bits and TLVs.
You’ll find more details (and the opportunity to explore the LSP database contents in a safe environment) in the IS-IS Route Redistribution lab exercise.

Click here to start the lab in your browser using GitHub Codespaces (or set up your own lab infrastructure). After starting the lab environment, change the directory to feature/7-redistribute and execute netlab up.
OSPFv3 Router ID Documentation on Arista EOS
When I published a blog post making fun of the ridiculously incorrect Cisco IOS/XE OSPFv3 documentation, an engineer working for Cisco quickly sent me an email saying, “Well, the other vendors are not much better.”
Let’s see how well Arista EOS is doing; this is their description of the router-id command (taken from EOS 4.35.0F documentation; unchanged for at least a dozen releases):

Testing IP Multicast with netlab
Aleksandr Albin built a large (almost 20-router) lab topology (based on an example from Jeff Doyle’s Routing TCP/IP Volume 2) that he uses to practice inter-AS IP multicast. He also published the topology file (and additional configuration templates) on GitHub and documented his experience in a LinkedIn post.
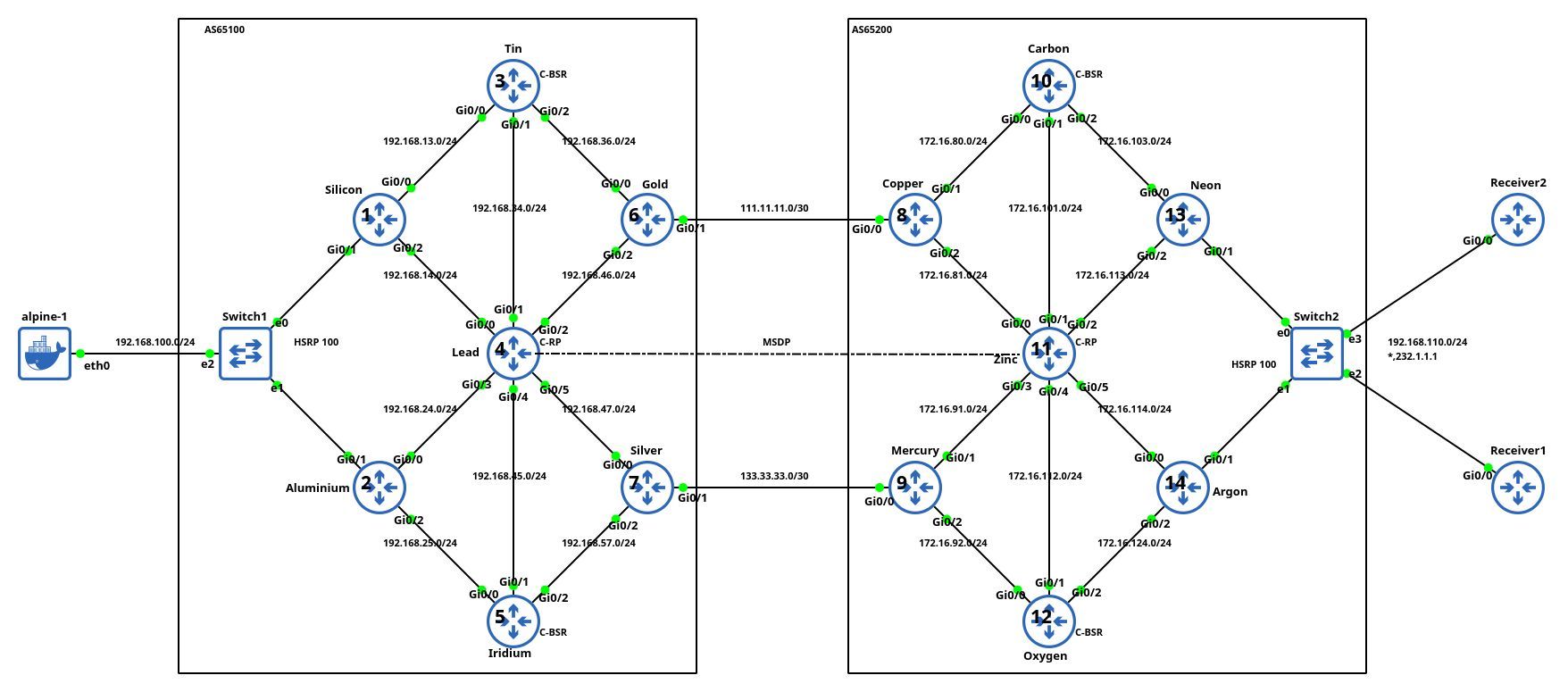
Lab topology, copied with permission by Aleksandr Albin
It’s so nice to see engineers using your tool in real-life scenarios. Thanks a million, Aleksandr, for sharing it.
Multi-Pod EVPN Troubleshooting (Route Targets)
Last week, we fixed the incorrect BGP next hops in our sample multi-pod EVPN fabric. With that fixed, every PE device should see every other PE device as a remote VTEP for ingress replication purposes. However, that’s not the case; let’s see why and fix it.
Note: This is the fourth blog post in the Multi-Pod EVPN series. If you stumbled upon it, start with the design overview and troubleshooting overview posts. More importantly, familiarize yourself with the topology we’ll be using; it’s described in the Multi-Pod EVPN Troubleshooting: Fixing Next Hops.
Ready? Let’s go. Here’s our network topology:
IOS/XR Route Redistribution Configuration Mess
One would hope that the developers of a network operating system wouldn’t feel the irresistible urge to reinvent what should have been a common configuration feature for every routing protocol. Alas, the IOS/XR developers failed to get that memo.
I decided to implement route redistribution (known as route import in netlab) for OSPFv2/OSPFv3, IS-IS, and BGP on IOS/XR (Cisco 8000v running IOS/XR release 24.4.1) and found that each routing protocol uses a different syntax for the source routing protocol part of the redistribute command.
Public Videos: Bridging with EVPN

The EVPN in the Data Center and Bridging with EVPN parts of the EVPN webinar, featuring Dinesh Dutt, are now available without a valid ipSpace.net account. Enjoy!
Building VXLAN/EVPN Data Center Lab with netlab
Dmitry Klepcha published an excellent document describing how you can use netlab to build a series of data center fabric labs, starting from a simple IP network (without routing) and finishing with a complex EVPN/VXLAN network using symmetric IRB and MLAG toward hosts.
But wait, there’s more: all the lab topologies he used in his exercises are available on GitHub, which means that you could just clone the repo and start using them (I also “borrowed” some of his ideas as future netlab improvements).
Finally, thanks a million to Roman Pomazanov for bringing Dmitry’s work to my attention (and for the quote at the end of his post ;).
Interesting: an MCP Agent for Link-State Routing Protocols
Vadim Semenov created a nice demo that allows you to use an LLM to query the collected link-state graphs through an MCP agent (SuzieQ would probably be faster and easier to deploy, but hey, AI).
If you want to kick the tires, you’ll find the source code on GitHub (Network AI assistant, MCP server for Topolograph service). You’ll also need Vadim’s previous projects: Topolograph and OSPF watcher or IS-IS watcher.
Multi-Pod EVPN Troubleshooting: Fixing Next Hops
Last month, I wrote about the specifics of troubleshooting multi-pod EVPN designs. Today, I’d like to start a journey through an example in which (channeling my inner CCIE preparation lab instructor) I broke as many things as I could think of.
Here’s the lab topology we’ll use (and as usual, the corresponding netlab topology file and device configurations are on GitHub). Our network has two sites (pods), each with a spine switch, a leaf switch, and a host attached to the leaf switch. The inter-pod link is connected to the spine switches to minimize the number of devices.
AI Enshittification: Swiss Airlines Edition
Remember the vendor consultants who persuasively told you how to use their gear to build a disaster recovery solution with stretched VLANs, even though the only disaster recovery they ever experienced was the frantic attempt to restart their PowerPoint slide deck? Fortunately, I was only involved in the aftermath of their activity when the laws of physics reasserted themselves, and I helped the poor victims rearchitect their network into a somewhat saner state.
There’s another batch of snake-oil salesmen consultants peddling their warez to the gullible incompetent managers: the AI preachers promising reduction in support costs. Like the other group of consultants, they have never worked in support and have never implemented a working AI solution in their lives, but that never bothered them or their audience.
Unfortunately, this time I had the unfortunate “privilege” of having the painful front-row seat.
Using netlab for Classroom Training with Sander Steffann
In March 2024, I received my first PR from an airplane: Sander Steffann was flying to South Africa to deliver an Ansible training and fixed a minor annoyance in the then-new multilab feature.
Of course, I wanted to know more about his setup, but it took us over a year and a half till we managed to sit down (virtually) and chat about it, the state of IPv6, the impact of CG-NAT on fraud prevention, and why digital twins don’t make sense in large datacenter migrations.
For more details, listen to Episode 202 of Software Gone Wild.
netlab 25.11: SRv6 on IOS/XE, Streamlined Graphs and Reports
I managed to push out netlab release 25.11 yesterday. Here are the highlights:
- SRv6 on IOS/XE. It works with Catalyst 8000v, IOL, and IOL layer-2 image, and can be used to build L3VPNs (the IOS/XE image I have supports no other service on top of SRv6)
- RIPv2/RIPng on OpenBSD
- A more streamlined way to create reports and graphs
- The netlab graph command creates the SVG/PNG/JPEG/PDF graph instead of a graph description file if you’ve installed D2/Graphviz on your system.
We also had to make a few potentially-breaking changes, fixed a bunch of bugs, and added over a dozen small improvements.
You’ll find all the details in the release notes.
Worth Reading: The Majority AI View
Many engineers who tried out (or use) various AI products would agree that they’re useful when used correctly, but way overhyped. However, as Anil Dash explains in his Majority AI View article, we rarely hear that opinion:
What’s amazing is the reality that virtually 100% of tech experts I talk to in the industry feel this way, yet nobody outside of that cohort will mention this reality.
One-Arm Hub-and-Spoke VPN on Arista EOS
In September 2024, I described how you can build One-Arm Hub-and-Spoke VPN with MPLS/VPN. In that blog post, I mentioned that the solution doesn’t work on Arista EOS because it allocates MPLS labels to whole VRFs (per-VRF label allocation).
In early September, I received an email from Daniel Blažek telling me that Arista fixed this particular annoyance in the EOS release 4.34.2F. It still uses per-VRF label allocation, but now, you can assign a different label to the default route. Let’s see how that works with our one-arm hub-and-spoke topology:
netlab: Test IPv6 IGP Deployment
Imagine you have an IPv4-only network1 and want to try out how to deploy a routing protocol for IPv6. netlab is a pretty good tool for the job as it:
Lab: Adjust IS-IS Timers
Like any other routing protocol, IS-IS has several timers you can tweak to improve the convergence speed of your network, or make your network unstable (eventually breaking it completely) if you reduce them too much (if you care about fast convergence, you REALLY SHOULD use BFD).
You’ll find more details (and the opportunity to tweak the timers in a safe environment) in the Adjust IS-IS Timers lab exercise.

Click here to start the lab in your browser using GitHub Codespaces (or set up your own lab infrastructure). After starting the lab environment, change the directory to feature/6-timers and execute netlab up.
Presentation: Testing Disaster Recovery Designs
Someone asked for my DEEP 2025 presentation (Testing Disaster Recovery Designs). You can download it here (no strings attached). I hope you’ll find it interesting.
The organizers plan to make the recorded videos public after a few months. Of course, I’ll post a link when they do that.
Worth Reading: AI Won’t Replace Network Engineers
Jason Gintert published an excellent explanation why AI won’t replace (all) network engineers, and reading it, I felt like reading one of my “automation won’t replace network engineers” blog posts.
Here’s a quote to get you in the mood:
AI will make good engineers better and will expose mediocre ones. If your value proposition is memorizing CLI commands or being a human grep for log files, then yes, you might need to be worried.