vagrant-libvirt Dependency Hell
One of the tiny details Open Networking preachers conveniently forget to mention is the tendency of open-source software to use a gazillion small packages from numerous independent sources to get the job done. Vendors selling commercial products (for example, Cumulus Linux) try their best to select the correct version of every package involved in their product; open-source projects could quickly end in dependency hell.
netlab tries to solve the dependency conundrum with well-defined installation scripts. We recommend you start with a brand new Ubuntu server (or VM) and follow the four lines of instructions1. In that case, you usually get a working system unless something unexpected breaks behind the scenes, like what we experienced a few days ago.
vagrant-libvirt Dependency Hell
One of the tiny details Open Networking preachers conveniently forget to mention is the tendency of open-source software to use a gazillion small packages from numerous independent sources to get the job done. Vendors selling commercial products (for example, Cumulus Linux) try their best to select the correct version of every package involved in their product; open-source projects could quickly end in dependency hell.
netlab tries to solve the dependency conundrum with well-defined installation scripts. We recommend you start with a brand new Ubuntu server (or VM) and follow the four lines of instructions1. In that case, you usually get a working system unless something unexpected breaks behind the scenes, like what we experienced a few days ago.
Worth Reading: NetOps Requires AI/ML and Rules
Here’s some common-sense view on hard-coded rules versus machine learning in network operations by Mark Seery – quite often we can specify our response to an event as a simple set of rules, but if we want to identify deviation from “normal” behavior, machine learning might not be a bad idea.
For more details, watch the Event-Driven Network Automation part of Building Network Automation Solutions online course.
Worth Reading: NetOps Requires AI/ML and Rules
Here’s some common-sense view on hard-coded rules versus machine learning in network operations by Mark Seery – quite often we can specify our response to an event as a simple set of rules, but if we want to identify deviation from “normal” behavior, machine learning might not be a bad idea.
For more details, watch the Event-Driven Network Automation part of Building Network Automation Solutions online course.
Worth Reading: Fail-Slow at Scale
Did you ever wonder why everything in IT becomes slower over time? Our changed expectations and accumulated cruft definitely play a major role.. but it could also be hardware. For more details (and fun reading), explore Fail-Slow at Scale: Evidence of Hardware Performance Faults in Large Production Systems.
Worth Reading: Fail-Slow at Scale
Did you ever wonder why everything in IT becomes slower over time? Our changed expectations and accumulated cruft definitely play a major role.. but it could also be hardware. For more details (and fun reading), explore Fail-Slow at Scale: Evidence of Hardware Performance Faults in Large Production Systems.
Video: IPv6 Traffic Filtering Details
Did you like the traffic filtering in the age of IPv6 video by Christopher Werny? Time for part two: IPv6 traffic filtering details.
You need Free ipSpace.net Subscription to watch the video.
Video: IPv6 Traffic Filtering Details
Did you like the traffic filtering in the age of IPv6 video by Christopher Werny? Time for part two: IPv6 traffic filtering details.
You need Free ipSpace.net Subscription to watch the video.
Arista EOS Configuration Automation
I keep getting questions along the lines of “is network automation practical/a reality?” with arguments like:
Many do not see a value and are OK with just a configuration manager such as Arista CVP (CloudVision Portal) and Cisco DNA.
Configuration consistently is a huge win regardless of how you implement it (it’s perfectly fine if the tools your vendor providers work for you). It prevents opportunistic consistency, as Antti Ristimäki succinctly explained:
Arista EOS Configuration Automation
I keep getting questions along the lines of “is network automation practical/a reality?” with arguments like:
Many do not see a value and are OK with just a configuration manager such as Arista CVP (CloudVision Portal) and Cisco DNA.
Configuration consistently is a huge win regardless of how you implement it (it’s perfectly fine if the tools your vendor providers work for you). It prevents opportunistic consistency, as Antti Ristimäki succinctly explained:
Why Would You Need an Overlay Network?
I got this question from one of ipSpace.net subscribers:
My VP is not a fan of overlays and is determined to move away from our legacy implementation of OTV, VXLAN, and EVPN1. We own and manage our optical network across all sites; however, it’s hard for me to picture a network design without overlays. He keeps asking why we need overlays when we own the optical network.
There are several reasons (apart from RFC 1925 Rule 6a) why you might want to add another layer of abstraction (that’s what overlay networks are in a nutshell) to your network.
Why Would You Need an Overlay Network?
I got this question from one of ipSpace.net subscribers:
My VP is not a fan of overlays and is determined to move away from our legacy implementation of OTV, VXLAN, and EVPN1. We own and manage our optical network across all sites; however, it’s hard for me to picture a network design without overlays. He keeps asking why we need overlays when we own the optical network.
There are several reasons (apart from RFC 1925 Rule 6a) why you might want to add another layer of abstraction (that’s what overlay networks are in a nutshell) to your network.
Running Routing Protocols over MLAG Links
It took vendors like Cisco years to start supporting routing protocols between MLAG-attached routers and a pair of switches in the MLAG cluster. That seems like a no-brainer scenario, so there must be some hidden complexities. Let’s figure out what they are.
We’ll use the familiar MLAG diagram, replacing one of the attached hosts with a router running a routing protocol with both members of the MLAG cluster (for example, R, S1, and S2 are OSPF neighbors).
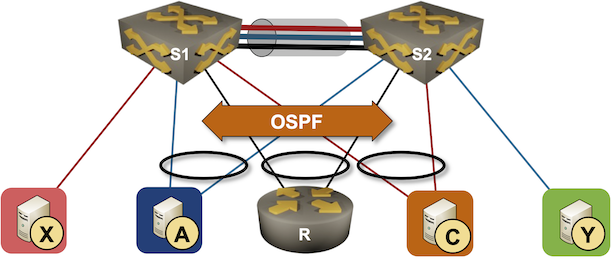
Running Routing Protocols over MLAG Links
It took vendors like Cisco years to start supporting routing protocols between MLAG-attached routers and a pair of switches in the MLAG cluster. That seems like a no-brainer scenario, so there must be some hidden complexities. Let’s figure out what they are.
We’ll use the familiar MLAG diagram, replacing one of the attached hosts with a router running a routing protocol with both members of the MLAG cluster (for example, R, S1, and S2 are OSPF neighbors).
netlab: VRF Lite over VXLAN Transport
One of the comments I received after publishing the Use VRFs for VXLAN-Enabled VLANs claimed that:
I’m firmly of the belief that VXLAN should be solely an access layer/edge technology and if you are running your routing protocols within the tunnel, you’ve already lost the plot.
That’s a pretty good guideline for typical data center fabric deployments, but VXLAN is just a tool that allows you to build multi-access Ethernet networks on top of IP infrastructure. You can use it to emulate E-LAN service or to build networks similar to what you can get with DMVPN (without any built-in security). Today we’ll use it to build a VRF Lite topology with two tenants (red and blue).
netlab: VRF Lite over VXLAN Transport
One of the comments I received after publishing the Use VRFs for VXLAN-Enabled VLANs claimed that:
I’m firmly of the belief that VXLAN should be solely an access layer/edge technology and if you are running your routing protocols within the tunnel, you’ve already lost the plot.
That’s a pretty good guideline for typical data center fabric deployments, but VXLAN is just a tool that allows you to build multi-access Ethernet networks on top of IP infrastructure. You can use it to emulate E-LAN service or to build networks similar to what you can get with DMVPN (without any built-in security). Today we’ll use it to build a VRF Lite topology with two tenants (red and blue).
Worth Reading: Egress Anycast in Cloudflare Network
Cloudflare has been using ingress anycast (advertising the same set of prefixes from all data centers) for ages. Now they did a giant leap forward and implemented another “this thing can never work” technology: egress anycast. Servers from multiple data centers use source addresses from the prefix that’s advertised by all data centers.
Not only that, in the long-established tradition they described their implementation in enough details that someone determined enough could go and implement it (as opposed to the typical look how awesome our secret sauce is approach from Google).
Worth Reading: Egress Anycast in Cloudflare Network
Cloudflare has been using ingress anycast (advertising the same set of prefixes from all data centers) for ages. Now they did a giant leap forward and implemented another “this thing can never work” technology: egress anycast. Servers from multiple data centers use source addresses from the prefix that’s advertised by all data centers.
Not only that, in the long-established tradition they described their implementation in enough details that someone determined enough could go and implement it (as opposed to the typical look how awesome our secret sauce is approach from Google).
Video: What Can Netlab Do?
Time for another netlab video: after explaining how netlab fits into the virtual lab orchestration picture, let’s answer the next question: what exactly can netlab do?
You need Free ipSpace.net Subscription to watch the video and Standard ipSpace.net Subscription to watch the rest of the webinar.
Video: What Can Netlab Do?
Time for another netlab video: after explaining how netlab fits into the virtual lab orchestration picture, let’s answer the following question: what exactly can netlab do?
You need Free ipSpace.net Subscription to watch the video and Standard ipSpace.net Subscription to watch the rest of the webinar.