Arista EOS Hates a Routing Instance with No Interfaces
I always ask engineers reporting a netlab bug to provide a minimal lab topology that would reproduce the error, sometimes resulting in “interesting” side effects. For example, I was trying to debug a BGP-related Arista EOS issue using a netlab topology similar to this one:
defaults.device: eos
module: [ bgp ]
nodes:
a: { bgp.as: 65000 }
b: { bgp.as: 65001 }
Imagine my astonishment when the two switches failed to configure BGP. Here’s the error message I got when running the netlab’s deploy device configurations Ansible playbook:
SwiNOG 40: When a Routing Control Functions Is Too Fresh
During integration testing, I find unexpected quirks in network devices way too often. However, that’s infinitely better than experiencing them in production (even after thoroughly testing stuff) while discovering that your peers don’t care about routing security, RPKI, and similar useless stuff.
For example, what happens if you define a new Routing Control Function (RFC) on Arista EOS and apply it to BGP routing updates in the same configuration session? You’ll find out in the Sorry We Messed Up (video) presentation Stefan Funke had at SwiNOG 40 (note: the bug has been fixed in the meantime).
Updated: netlab Network Topology Graphs
netlab release 25.09 introduced numerous graphing enhancements and a new graph type (IS-IS graphs), so I decided to write a series of blog posts explaining how you can generate graphs from netlab lab topologies.
I wrote an intro to netlab topology graphs years ago, and as expected, it was hopelessly outdated, so I started the project with a complete overhaul of that article.
[FATAL] Ansible Release 12.0 Breaks netlab Jinja2 Templates
On September 9th, the ansible release 12.0 appeared on PyPi. It requires ansible-core release 2.19, which includes breaking changes to Jinja2 templating. netlab Jinja2 templates rely on a few Ansible Jinja2 filters; netlab thus imports and uses those filters, and it looks like those imports pulled in the breaking changes that consequently broke the netlab containerlab configuration file template (details).
netlab did not check the Ansible core version (we never had a similar problem in the past), and the installation scripts did not pin the Ansible version (feel free to blame me for this one), which means that any new netlab installation created after September 9th crashed miserably on the simplest lab topologies.
This is the workaround we implemented in netlab release 25.09-post1 (released earlier today):
Lab: Running IS-IS over IPv4 Unnumbered and IPv6 LLA Interfaces
IS-IS does not use IPv4 or IPv6, so it should be a no-brainer to run it over IPv4 unnumbered or IPv6 LLA interfaces. The latter is true; the former is smack in the middle of the It Depends™ territory.
Want to know more or test the devices you’re usually working with? The Running IS-IS Over Unnumbered/LLA-only Interfaces lab exercise is just what you need.

Click here to start the lab in your browser using GitHub Codespaces (or set up your own lab infrastructure). After starting the lab environment, change the directory to basic/7-unnumbered and execute netlab up.
The Curious Case of ‘ip host’ Configuration Command
Since time immemorial, I have used the ip host router configuration command to get host-to-IP mappings in networking labs without going through the hassle of setting up a DNS server. Some devices even accepted multiple IP addresses in the ip host command, allowing you to list all router interfaces in a single command and get reverse (IP-to-host) mapping working like a charm. Or so I thought 🤦♂️
It turns out I’m too old, and what I know is sometimes no longer true. It seems that the last implementation working as I expected is Cisco IOS Classic ☹️
Labbing Network Technology Details with netlab
It’s been over four years since I published the last Software Gone Wild episode. In the meantime, I spent most of my time developing an open-source labbing tool, so it should be no surprise that the first post-hiatus episode focused on a netlab use case: how Ethan Banks (of the PacketPushers fame) is using the tool to quickly check the technology details for his N is for Networking podcast.
As expected, our discussion took us all over the place, including (according to Riverside AI):
SwiNOG 40: Reliability of High-Speed Transceivers
Whenever you see Gerhard Stein and Thomas Weible from Flexoptix in a list of presenters, three things immediately become obvious:
- It will be about transceivers
- It will be fun
- It will include some crazy stuff
Their SwiNOG 40 presentation (video) met all three expectation. We learned how well transceivers cope with high temperatures and what happens when you try to melt them with a heat gun.
netlab 25.09: IPv6 RA, Link Impairments, and Performance Gains
netlab release 25.09 includes:
- Link impairment (implemented with Linux netem queuing discipline) defined in lab topology or configured/controlled with the netlab tc command
- Configurable IPv6 Router Advertisement parameters
- The files plugin to store the content of short files (including custom configuration templates) directly in the lab topology
- Support for Nokia SR-OS container (SR-SIM)
- Support for very large topologies (tested so far: approximately 3000 lab devices)
But wait, there’s more (as always):
How Many Lab Devices Can netlab Handle?
TL&DR: Over 3000
A few weeks ago, Christian opened an issue describing how netlab breaks when the lab topology has more than 250 devices. We fixed that, only to get into another morass: some code has complexity higher than O(n) (meaning that going from 100 to 200 devices makes things more than twice as slow). Christian is working on one of those problems at the moment (it’s not that his ginormous labs won’t start, it just takes a long time), and I decided it’s time to polish a few other bits of the code.
SwiNOG 40: Submarine Cables
If you know as much about submarine cables (the thingies that carry 90% of international Internet traffic) as I do (= nothing), you SHOULD watch the Technical Update on Submarine Cables (video) presentation Liam Taylor had at the SwiNOG 40 event. Have fun ;)
Netlab: The Fastest Way to Build Network Labs
Suresh Vina published a great netlab tutorial, going from the very basics to a full-blown MPLS network with custom multi-vendor device configuration. Thank you!
iBGP Local-AS Route Propagation
In the previous blog post on this topic, I described the iBGP local-as functionality and explained why we MUST change the BGP next hop on the routes sent over the fake iBGP session (TL&DR: because we’re not running IGP across that link).
That blog post used a simple topology with three routers. Now let’s add a few more routers to the mix and see what happens.
Network Automation Reality Check with William Collins
In early August, William Collins invited me to chat about a sarcastic comment I made about a specific automation tool I have a love-hate relationship with on LinkedIn.
We quickly agreed not to go (too deep) into tool-bashing. Instead, we discussed the eternal problems of network automation, from unhealthy obsession with tools to focus on point solutions while lacking the bigger picture or believing in vendor-delivered nirvana.
SwiNOG 40: Application-Based Source Routing with SRv6
The we should give different applications different paths across the network idea never dies (even though in many places the residential Internet gives you enough bandwidth to watch 4K videos), and the Leveraging Intent-Based Networking and SRv6 for Dynamic End-to-End Traffic Steering (video) by Severin Dellsperger was an interesting new riff on that ancient grailhunt.
Their solution uses SRv6 for traffic steering1, an Intent-Based System2 that figures out paths across the network, and eBPF on client hosts3 to add per-application SRv6 headers to outgoing traffic.
EVPN Designs: Layer-3 Inter-AS Option A
A netlab user wanted to explore a multi-site design where every site runs an independent EVPN fabric, and the inter-site link is either a layer-2 or a layer-3 interconnect (DCI). Let’s start with the easiest scenario: a layer-3 DCI with a separate (virtual) link for every tenant (in the MPLS/VPN world, we’d call that Inter-AS Option A)
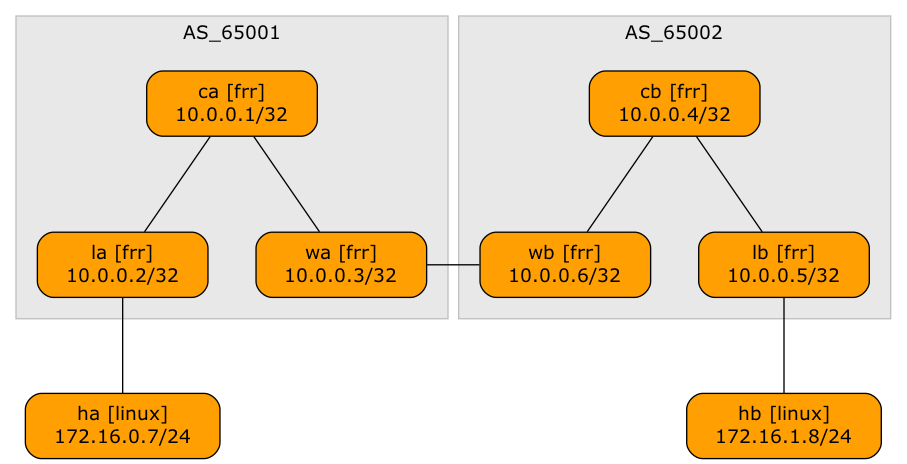
Lab topology
When Switches Flood LLDP Traffic
A networking engineer (let’s call him Joe1) sent me an interesting challenge: they built a data center network with Cisco switches, and the switches flood LLDP packets between servers.
That would be interesting by itself (the whole network would appear as a single hub), but they’re also using DCBX (which is riding in LLDP TLVs), and the DCBX parameters are negotiated between servers (not between servers and adjacent switches), sometimes resulting in NIC resets2.
ArubaCX Decides When You’re Done Changing a BGP Routing Policy
When I was cleaning the “set BGP MED” integration test, I decided that once a BGP prefix is in the BGP table of the BGP peer, there’s no need for a further wait before checking its MED value. After all:
- We configure an outbound routing policy to change MED;
- We execute do clear bgp * soft out at the end of most BGP policy configuration templates1
- The device under test should thus immediately (re)send the expected BGP prefix with the target MED.
That approach failed miserably with ArubaCX; it was time to investigate the details.
Configuring BGP Community Propagation is Confusing
A large number of vendors claim to use industry-standard CLI, which means “something that looks like Cisco IOS, but we can’t say that in public.” The implementations of that “standard” are full of quirks; as I was making fun of Cisco IOS last week, it’s only fair to look at how others deal with BGP community propagation.
netlab has BGP configuration templates for 14 different platforms1, including these implementations that look like Cisco IOS from a distance if you squint just right2: Arista EOS, Aruba CX, and FRRouting. You can check the configuration templates if you wish; here’s the TC&DB3 overview:
SwiNOG 40: Trustworthy Network Automation
The SwiNOG 40 event started with an interesting presentation on Building Trustworthy Network Automation (video) by Damien Garros (now CEO @ OpsMill) who discussed the principles one can use to build a trustworthy network automation solution, including idempotency, dry runs, and transactional changes. He also covered the crucial roles of the declarative approach, version control, and testing.
If you have ever watched any of my network automation materials, you won’t be surprised by anything he said, but if you’re just starting your network automation journey, you MUST watch this presentation to get your bearings straight.