Ansible for Extreme Devices
Here’s something I’ve been working on recently: Ansible modules for Extreme SLX switches & routers. Ansible is a popular automation framework, and with good reason: it has a low barrier to entry. Time to usefulness is short. But you need device-specific modules to work with networking devices. Finally we have some modules for SLX. Read on for how to use them.
This blog is not an intro to Ansible in general. There’s plenty of good intros out there. This is specifically about demonstrating Ansible with SLX switches.
Background
Ansible is an agent-less configuration management system. It uses “playbooks”, written in YAML, to define desired configuration state. “modules” written in Python translate this into whatever is needed to configure the system, application, database or network device.
Ansible has been making great strides in adding network automation capabilities. But we haven’t had any modules for working with ~Brocade~ Extreme devices. That is now changing.
PaulQuack has contributed MLXe (Ironware) modules, which will go GA in Ansible 2.5 (due for release in March 2018). And I’ve been working on modules for the SLX, with my colleagues. These have not yet been merged upstream, but it’s Open Source, so you can grab Continue reading
It Takes a Village to Raise a Child
It takes a village to raise a child. Or so the old saying goes. Creating a product is the same. It takes more than small group of developers (or parents) to raise a product. There’s a lot more to creating a product than writing an application. Don’t mistake a feature or application for a product.
Look, Six Engineers Created a Product!
People hear about new applications or protocols, or small companies selling for millions. They then leap to conclusions:
“Why is it that big vendors like Cisco need thousands of people to create a product? Facebook can put 6 engineers on a project and produce something like Open/R. It’s easy, right? We don’t need big vendors any more!”
“Look at Instagram - they only had a dozen people and they sold their company for $1 billion dollars! You don’t need any more people than that.”
Let’s look a bit closer at Instagram. How much revenue did they have? Zero.
How long were they in business for? A couple of years. So how many generations of product were they supporting? One. And did they have complete support structures for users? No. How many products had gone through end of Continue reading
Using Telegraf, InfluxDB and Grafana to Monitor Network Statistics
Two years ago I wrote about how to use InfluxDB & Grafana for better visualization of network statistics. I still loathe MRTG graphs, but configuring InfluxSNMP was a bit of a pain. Luckily it’s now much easier to collect SNMP data using Telegraf. InfluxDB and Grafana have also improved a lot. Read on for details about to monitor network interface statistics using Telegraf, InfluxDB and Grafana.
Background - Telegraf, InfluxDB + Grafana
There’s three parts to this:
-
Grafana: Grafana is “The open platform for beautiful analytics and monitoring.” It makes it easy to create dashboards for displaying data from many sources, particularly time-series data. It works with several different data sources such as Graphite, Elasticsearch, InfluxDB, and OpenTSDB. We’re going to use this as our main front end for visualising our network statistics.
-
InfluxDB: InfluxDB is “…a data store for any use case involving large amounts of timestamped data.” This is where we we’re going to store our network statistics. It is designed for exactly this use-case, where metrics are collected over time.
-
Telegraf: Telegraf is “…a plugin-driven server agent for collecting and reporting metrics.” This can collect data from a wide variety of sources, Continue reading
Extreme Transition At Last
It is now almost 12 months since the first announcement that Broadcom was to acquire Brocade, and sell off the IP parts of the business. It took another 6 months to get confirmation that Extreme Networks would be buying my business unit (SRA).
For regulatory reasons, the Broadcom/Brocade transaction has still not closed. The original plan was to close that deal first, then close the Extreme transaction. But due to the delays, they re-arranged things, and now the Extreme deal has finally closed. Desks have been cleared, moving crews are working all weekend, and come Monday, I will have a new “Extreme Networks” badge.
What does this mean for me? My group is moving to become part of Extreme Networks. In the short term, I keep working with the same core group of people. But now we will be part of a new wider group, with a different strategic focus.
We will have new systems and applications to integrate StackStorm with, new use-cases, and maybe further opportunities beyond StackStorm. So far all signs are pointing to this being a positive move, and I am looking forward to getting this transition behind us.
Sorry, Network Jobs Are Changing
There’s a lot of angst in the networking community about programming, SDN, automation, and what it means for networking careers. Plenty of people will tell you don’t worry about it, focus on the fundamentals, there’s plenty of work, you will be fine.
There is some truth in that. There are still lots of jobs in networking. People with solid skillsets should have no problem finding a good job.
But.
Don’t fool yourself. Things are changing.
I’ve seen some research from Gartner that indicates that organisations have been steadily decreasing their Network Operations teams over the last five years. They have also been reducing their Data Networks spend. (Sadly I don’t have publication rights for this research, so you’ll just have to take my word for it).
This is going to put pressure on networking engineers. Your role will be forced to change, if for no other reason than that you are going to have less budget, and fewer people to do the work.
So you’d better think about what that means for how your role might change.
Do you need to change jobs today? No. You don’t have to outrun the lion’ - but you do want to make Continue reading
Everything Has a Cost
Everything comes at a cost: steak dinners & pre-sales engineering has to get paid for somehow. That should be obvious to most. Feature requests also come at a cost, both upfront, and ongoing. Those ongoing costs are not always understood.
It’s easy to look at vendor gross margins, and assume that there is plenty of fat. But remember that Gross margin is just Revenue minus cost of goods sold. It’s not profit. It doesn’t include sales & marketing costs, or R&D costs. Those costs affect net income, which is ‘real’ income. Companies need to recoup those costs somehow if they want to make money. Gross margin alone doesn’t pay the bills.
Four-Legged SalesDroids, and Steak Dinners
A “four-legged sales call” is when two people show up for sales calls. The usual pattern is an Account Manager for the ‘relationship’ stuff, with a Sales Engineer acting as truth police. These calls can be very useful. It’s a good way to talk about the current business challenges, discuss product roadmaps, provide feedback on what’s working, and what’s not. The Sales Engineer can offer implementation advice, maybe help with some configuration issues.
Often a sales call includes lunch or dinner. Breaking bread together Continue reading
Everything Has a Cost
Everything comes at a cost: steak dinners & pre-sales engineering has to get paid for somehow. That should be obvious to most. Feature requests also come at a cost, both upfront, and ongoing. Those ongoing costs are not always understood.
It’s easy to look at vendor gross margins, and assume that there is plenty of fat. But remember that Gross margin is just Revenue minus cost of goods sold. It’s not profit. It doesn’t include sales & marketing costs, or R&D costs. Those costs affect net income, which is ‘real’ income. Companies need to recoup those costs somehow if they want to make money. Gross margin alone doesn’t pay the bills.
Four-Legged SalesDroids, and Steak Dinners
A “four-legged sales call” is when two people show up for sales calls. The usual pattern is an Account Manager for the ‘relationship’ stuff, with a Sales Engineer acting as truth police. These calls can be very useful. It’s a good way to talk about the current business challenges, discuss product roadmaps, provide feedback on what’s working, and what’s not. The Sales Engineer can offer implementation advice, maybe help with some configuration issues.
Often a sales call includes lunch or dinner. Breaking bread together Continue reading
Recruiters: Must Try Harder
Right now, it’s an employee’s market in the Bay Area. Technology firms are growing, and they’re always trying to hire more people. So I regularly receive emails from recruiters. This is not to brag, it’s just the way things are right now, based upon the economy, my background, my current location, and my age. I’m lucky.
Some of these approaches are outstanding. Well-crafted, tailored to the person and the role. Some are pathetically bad, and I don’t know why they try.
The Right Approach
A good approach goes like this:
Hi Lindsay!
I’m a recruiter at $CoolCompany. We’re looking for great people to work on our teams doing $InterestingThingOne and $InterestingThingsTwo! We’re hoping to do This, That and the Other Thing! Check out our projects on Github <here> and <here>.
We think this would be a good match because of your background working on $RecentProject in $PreviousIndustries.
We were thinking about someone to do these sorts of things: X, Y, Z. But mainly it’s about finding the right people, and we’re fine with re-working the role a bit to suit.
Let us know what you think
Regards, Good Recruiter
The Wrong Approach
Hi
We have a job opening for a Continue reading
Recruiters: Must Try Harder
Right now, it’s an employee’s market in the Bay Area. Technology firms are growing, and they’re always trying to hire more people. So I regularly receive emails from recruiters. This is not to brag, it’s just the way things are right now, based upon the economy, my background, my current location, and my age. I’m lucky.
Some of these approaches are outstanding. Well-crafted, tailored to the person and the role. Some are pathetically bad, and I don’t know why they try.
The Right Approach
A good approach goes like this:
Hi Lindsay!
I’m a recruiter at $CoolCompany. We’re looking for great people to work on our teams doing $InterestingThingOne and $InterestingThingsTwo! We’re hoping to do This, That and the Other Thing! Check out our projects on Github <here> and <here>.
We think this would be a good match because of your background working on $RecentProject in $PreviousIndustries.
We were thinking about someone to do these sorts of things: X, Y, Z. But mainly it’s about finding the right people, and we’re fine with re-working the role a bit to suit.
Let us know what you think
Regards, Good Recruiter
The Wrong Approach
Hi
We have a job opening for a Continue reading
The Difference Between Proper Devs and Me
I spend a lot of time poking around with code, and I can figure out most integration challenges, and simple code fixes. But I do not call myself a developer. I know, we can argue about what constitutes a developer, but I don’t really want to get into that. I’d just like to highlight something that showed the difference between the futzing about that I do, and the way a senior developer thinks about problems.
StackStorm Documentation Process
We use reStructuredText for StackStorm documentation. It’s a form of markup language, with everything is written in plaintext. It gets parsed into HTML (and potentially other formats). The use of special punctuation marks and indentation tells the parser how to render the HTML - e.g. inserting links, highlighting text, bullet points, etc.
When I want to update our documentation, I create a branch on our GitHub st2docs repo. I make my changes, then create a Pull Request against the master branch. When I do this, it triggers our CircleCI checks. These checks include attempting to build the documentation, and failing if there are any parsing errors. If I’ve made a mistake in my syntax, it gets caught at this point, and Continue reading
The Difference Between Proper Devs and Me
I spend a lot of time poking around with code, and I can figure out most integration challenges, and simple code fixes. But I do not call myself a developer. I know, we can argue about what constitutes a developer, but I don’t really want to get into that. I’d just like to highlight something that showed the difference between the futzing about that I do, and the way a senior developer thinks about problems.
StackStorm Documentation Process
We use reStructuredText for StackStorm documentation. It’s a form of markup language, with everything is written in plaintext. It gets parsed into HTML (and potentially other formats). The use of special punctuation marks and indentation tells the parser how to render the HTML - e.g. inserting links, highlighting text, bullet points, etc.
When I want to update our documentation, I create a branch on our GitHub st2docs repo. I make my changes, then create a Pull Request against the master branch. When I do this, it triggers our CircleCI checks. These checks include attempting to build the documentation, and failing if there are any parsing errors. If I’ve made a mistake in my syntax, it gets caught at this point, and Continue reading
RPM Post-Upgrade Scripts
Something different today: Here’s something I learnt about RPM package management, and post-upgrade scripts. It turns out that they don’t work the way I thought they did. Post-uninstall commands are called on both uninstall and upgrade. For my own reference as much as anyone’s here some info about it, and how to deal with it.
RPM Package Management
RPM is a Linux package management system. It is a way of distributing and managing applications installed on Linux systems. Packages get distributed as .rpm files. These contain the application binaries, configuration files, and application metadata such as dependencies. They can also contain scripts to run pre- and post- installations, upgrades and removal.
Using package management systems is a vast improvement over distributing source code, or requiring users to manually copy files around and run scripts themselves.
There is some effort required to get the spec files used to create packages. But once it has been set up, it is easy to create new versions of packages, and distribute them to users. System administrators can easily check which version they’re running, check what new versions are available, and upgrade.
We use RPMs to distribute StackStorm packages for RHEL/CentOS systems. Similarly, we distribute Continue reading
RPM Post-Upgrade Scripts
Something different today: Here’s something I learnt about RPM package management, and post-upgrade scripts. It turns out that they don’t work the way I thought they did. Post-uninstall commands are called on both uninstall and upgrade. For my own reference as much as anyone’s here some info about it, and how to deal with it.
RPM Package Management
RPM is a Linux package management system. It is a way of distributing and managing applications installed on Linux systems. Packages get distributed as .rpm files. These contain the application binaries, configuration files, and application metadata such as dependencies. They can also contain scripts to run pre- and post- installations, upgrades and removal.
Using package management systems is a vast improvement over distributing source code, or requiring users to manually copy files around and run scripts themselves.
There is some effort required to get the spec files used to create packages. But once it has been set up, it is easy to create new versions of packages, and distribute them to users. System administrators can easily check which version they’re running, check what new versions are available, and upgrade.
We use RPMs to distribute StackStorm packages for RHEL/CentOS systems. Similarly, we distribute Continue reading
War Stories: Always Check Your Inputs
The extremely irregular War Stories series returns, with an anecdote from 15 years ago, investigating a problem with a web app that only seemed to crash when one particular person used it. Ultimately a simple problem, but it took me a while to track it down. I blame Perl.
ISPY With my Little Eye
“ispy” was our custom-built system that archived SMS logs from all our SMSCs, aggregating them to one server for analysis. Message contents were kept for a short period, with CDRs stored for longer (i.e. details of sending and receiving numbers, and timestamps, but no content).
The system had a web interface that support staff could use to investigate customer reports of SMS issues. They could enter source and/or destination MSISDNs, and see when messages were sent, and potentially contents. Access to contents was restricted, and was typically only used for things like abuse investigations.
This system worked well, usually.
Except when it didn’t.
Every few weeks, we’d get reports that L2 support couldn’t access the system. We’d login, see that one process was using up 99% CPU, kill it, and it would be OK for a while. Normally the system was I/O bound, so we Continue reading
War Stories: Always Check Your Inputs
The extremely irregular War Stories series returns, with an anecdote from 15 years ago, investigating a problem with a web app that only seemed to crash when one particular person used it. Ultimately a simple problem, but it took me a while to track it down. I blame Perl.
ISPY With my Little Eye
“ispy” was our custom-built system that archived SMS logs from all our SMSCs, aggregating them to one server for analysis. Message contents were kept for a short period, with CDRs stored for longer (i.e. details of sending and receiving numbers, and timestamps, but no content).
The system had a web interface that support staff could use to investigate customer reports of SMS issues. They could enter source and/or destination MSISDNs, and see when messages were sent, and potentially contents. Access to contents was restricted, and was typically only used for things like abuse investigations.
This system worked well, usually.
Except when it didn’t.
Every few weeks, we’d get reports that L2 support couldn’t access the system. We’d login, see that one process was using up 99% CPU, kill it, and it would be OK for a while. Normally the system was I/O bound, so we Continue reading
SREcon, DevOpsDays and Seattle vs Sillicon Valley
I am the Product Manager for StackStorm. This gives me the opportunity to attend several industry events. This year I attended SREcon in San Francisco, and devopsdays Seattle. I found both events interesting, but also found them more different than I expected.
SREcon Americas
This year SREcon Americas was held in San Francisco, a nice walk along the Embarcadero from where I live. This is bliss compared to my regular daily tour of the Californian outdoor antique railway museum, aka Caltrain.
According to the organizers, SREcon is:
…a gathering of engineers who care deeply about site reliability, systems engineering, and working with complex distributed systems at scale
That was pretty much true to form. Two things stood out to me:
- The number of smart people, working on interesting problems
- The number of companies aggressively hiring in this space.
I had many interesting conversations at SREcon. We had a booth, so would briefly start describing what StackStorm is, but would very quickly move past that. Conversations often went “Oh yeah, we’ve built something along those lines in-house, because there was nothing on the market back when we needed it. But I wouldn’t do it again. How did you solve <insert knotty Continue reading
SREcon, DevOpsDays and Seattle vs Sillicon Valley
I am the Product Manager for StackStorm. This gives me the opportunity to attend several industry events. This year I attended SREcon in San Francisco, and devopsdays Seattle. I found both events interesting, but also found them more different than I expected.
SREcon Americas
This year SREcon Americas was held in San Francisco, a nice walk along the Embarcadero from where I live. This is bliss compared to my regular daily tour of the Californian outdoor antique railway museum, aka Caltrain.
According to the organizers, SREcon is:
…a gathering of engineers who care deeply about site reliability, systems engineering, and working with complex distributed systems at scale
That was pretty much true to form. Two things stood out to me:
- The number of smart people, working on interesting problems
- The number of companies aggressively hiring in this space.
I had many interesting conversations at SREcon. We had a booth, so would briefly start describing what StackStorm is, but would very quickly move past that. Conversations often went “Oh yeah, we’ve built something along those lines in-house, because there was nothing on the market back when we needed it. But I wouldn’t do it again. How did you solve <insert knotty Continue reading
Savvius Insight and the use of Elastic
Last week Savvius announced upgraded versions of its Insight network visibility appliances. These have the usual performance and capacity increases you’d expect, and fill a nice gap in the market.
But the bit that was most interesting to me was the use of an on-board Elastic stack, with pre-built Kibana dashboards for visualizing network data, e.g.:
Historically the only way we could realistically create these sorts of dashboards and systems was using Splunk. I’m a big fan of Splunk, but it has a problem: Cost. Especially if you’re trying to analyze large volumes of network data. You might be able to make Splunk pricing work for application data, but network data volumes are often just too large.
Savvius has previously included a Splunk forwarder, to make it easier to get data from their systems into Splunk. But Elastic has reached the point where Splunk is no longer needed. It’s viable for companies like Savvius to ship with a built-in Elastic stack setup.
There’s nothing stopping people centralizing the data either. You can modify the setup on the Insight appliance to send data to a central Elastic setup, and you can copy the Kibana dashboards, and create your own Continue reading
Savvius Insight and the use of Elastic
Last week Savvius announced upgraded versions of its Insight network visibility appliances. These have the usual performance and capacity increases you’d expect, and fill a nice gap in the market.
But the bit that was most interesting to me was the use of an on-board Elastic stack, with pre-built Kibana dashboards for visualizing network data, e.g.:
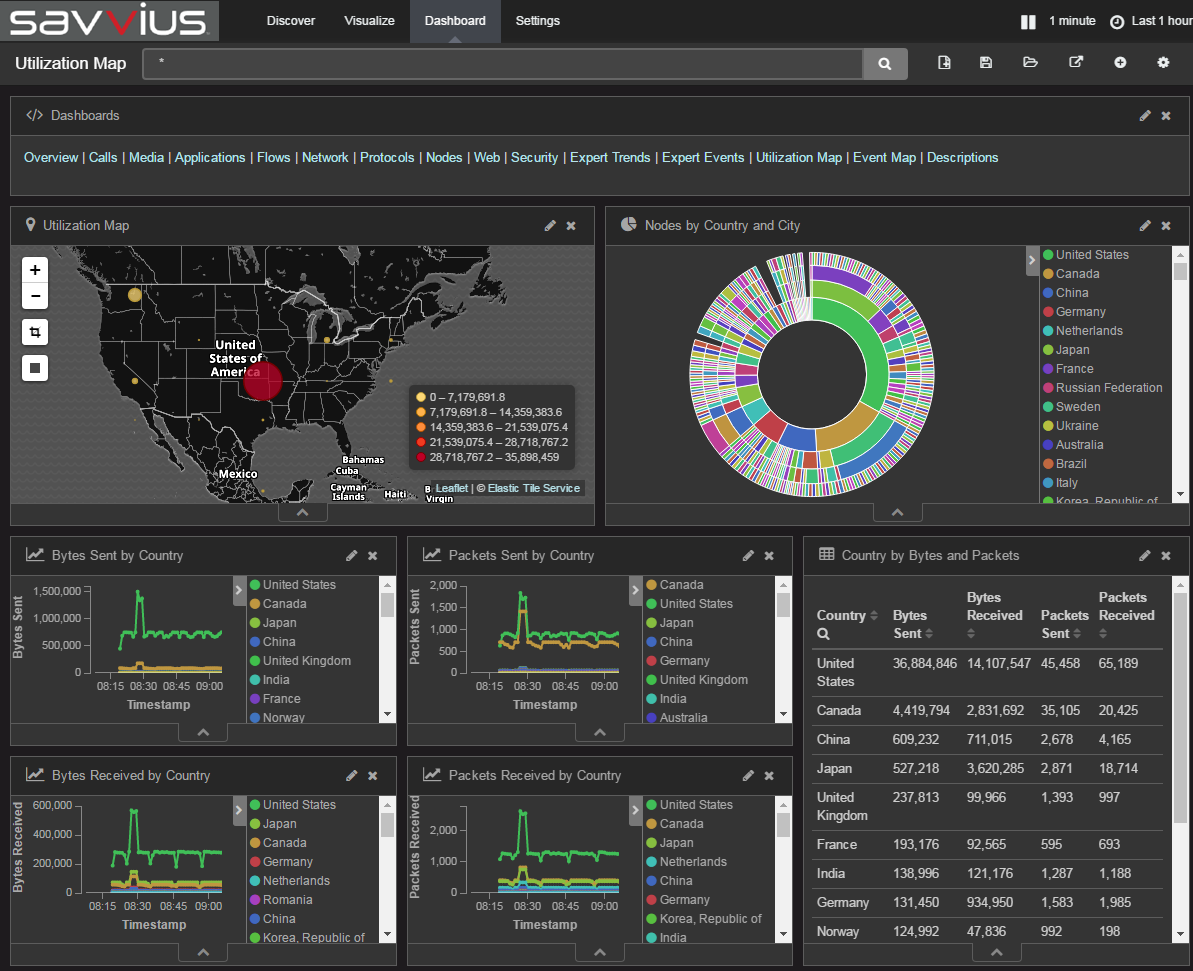
Historically the only way we could realistically create these sorts of dashboards and systems was using Splunk. I’m a big fan of Splunk, but it has a problem: Cost. Especially if you’re trying to analyze large volumes of network data. You might be able to make Splunk pricing work for application data, but network data volumes are often just too large.
Savvius has previously included a Splunk forwarder, to make it easier to get data from their systems into Splunk. But Elastic has reached the point where Splunk is no longer needed. It’s viable for companies like Savvius to ship with a built-in Elastic stack setup.
There’s nothing stopping people centralizing the data either. You can modify the setup on the Insight appliance to send data to a central Elastic setup, and you can copy the Kibana dashboards, and create your own Continue reading
IPv6 Trends, SixXS Sunset and Project Planning
Native IPv6 availability continues to increase, leading to the sunset of SixXS services. But it looks like we don’t like starting any major IPv6 rollouts around Christmas/New Years, but instead start going into production from April onwards.
SixXS Sunset
In March 2017, the SixXS team announced that they are closing down all services in June 2017:
SixXS will be sunset in H1 2017. All services will be turned down on 2017-06-06, after which the SixXS project will be retired. Users will no longer be able to use their IPv6 tunnels or subnets after this date, and are required to obtain IPv6 connectivity elsewhere, primarily with their Internet service provider.
SixXS has provided a free IPv6 tunnel broker service for years, allowing people to get ‘native’ IPv6 connectivity even when their ISP didn’t offer it. A useful service in the early days of IPv6, when ISPs were dragging the chain.
But this is a Good Thing that it is now closing down. It’s closing down because their mission has been achieved, and people no longer require tunnel broker services. IPv6 is now widely available in many countries, and not just from niche ISPs. Mainstream ISPs such as Comcast in Continue reading