BRKSEC-3005 — An IoT Security Model for Securing IT-OT Assets
Presenter: Jeff Schutt - Cybersecurity Solutions Architect (Jeff works in Adv Services in the IoT team)
Full Title: An IoT Security Model & Architecture for Securing Cyber-Physical and IT-OT Converged Assets

Mix of IT/OT folks in the room.
My CLUS 2015 Schedule
I’m lucky enough to be heading to Cisco Live in San Diego this year to host customers from my area. When I’m not with a customer during the day I plan on attending these sessions:
Monday
- Coding 101: How to Call REST APIs from a REST Client and Python
- IoT Solutions – Connecting Oil and Gas Pipelines
- An IoT Security Model & Architecture for Securing Cyber-Physical and IT-OT Converged Assets
- Keynote
Tuesday
- APIC-EM: Controller Workload and Use Cases
- Designing for the Secure Convergence of Enterprise and Process Control Networks
- Emerging Threats – The State of Cyber Security
Wednesday
- IWAN Customer Case Study
- Industrial Keynote – IoE and the IT Mindset Shift – The Evolution of the IT Career
- Ethernet Evolving – Ethernet at New Speeds, Deterministic Networking, and Power over Everything!
- Advanced Malware Protection
Thursday
- Snort Implementation in Cisco Products
- Cloud Consumption in North America
- No Lights, No Power, No Service? – Defending IoT
- Closing Keynote
My main themes for picking sessions were industrial connectivity (due to the customer base I cover) and cyber security with a sprinkling of strategically chosen sessions to fill the gaps.
I plan on blogging my notes from each session soon after the session ends. Continue reading
My CLUS 2015 Schedule
I'm lucky enough to be heading to Cisco Live in San Diego this year to host customers from my area. When I'm not with a customer during the day I plan on attending these sessions:
MPLS “No Label” vs “Pop Label”
I like MPLS. And I don’t necessarily mean as a solution to solve a problem, but as something to configure in the lab. It’s fun to build things that do something when you’re done. Setting up OSPF or EIGRP and being able to traceroute across routers is meh. But configuring MPLS with all the associated technologies — an IGP, LDP, MP-BGP, — and then getting all of them working in unison… when you get the traceroute working, it’s rewarding.
Here’s something to keep an eye out for when you’re troubleshooting MPLS: An LFIB entry (that is, the Label Forwarding Information Base) that states “No Label” versus one that states “Pop Label”. These mean very different things and can be the difference between a working Label Switched Path (LSP) and a non-working LSP.
The Topology
Here’s the topology I’m working with:

Click to Enlarge
R21 and R8 are Customer Edge (CE) routers and they communicate through the MPLS network in the “BRANCHES” VRF. R4 and R7 are Provider Edge (PE) routers and R1, R5, and R6 are Provider (P) routers.
Working State
I’m going to examine traffic going from R8’s 10.1.8.8 address and destined to R21’s 10. Continue reading
MPLS “No Label” vs “Pop Label”
I like MPLS. And I don't necessarily mean as a solution to solve a problem, but as something to configure in the lab. It's fun to build things that do something when you're done. Setting up OSPF or EIGRP and being able to traceroute across routers is meh. But configuring MPLS with all the associated technologies — an IGP, LDP, MP-BGP, — and then getting all of them working in unison… when you get the traceroute working, it's rewarding.
Here's something to keep an eye out for when you're troubleshooting MPLS: An LFIB entry (that is, the Label Forwarding Information Base) that states “No Label” versus one that states “Pop Label”. These mean very different things and can be the difference between a working Label Switched Path (LSP) and a non-working LSP.
Walking with Packets: Traceroute Through MPLS Cloud
Think about this for a minute: An MPLS network with a two Provider Edge (PE) routers and some Provider (P) routers. The P routers have no VRFs configured on them and therefore have no routes whatsoever for any of the customer networks. A customer then does a traceroute from one of their sites, across the MPLS cloud, and into one of their other sites. The traceroute output shows the P routers as hops along the path.
How is it possible for the P routers to reply to the traceroute if they don’t have routes back to the customer network?
The Lab Setup
Here’s the network:

Click to Enlarge
Here’s the traceroute output from R21’s loopback0 to R8’s loopback0 (the last octet of each IP address corresponds to the name of each router):
R21#traceroute 10.1.8.8 source loopback0
Type escape sequence to abort.
Tracing the route to 10.1.8.8
VRF info: (vrf in name/id, vrf out name/id)
1 10.4.4.4 21 msec 18 msec 17 msec
2 10.2.45.5 [MPLS: Labels 21/24 Exp 0] 19 msec 18 msec 18 msec
3 10.2.15.1 [MPLS: Labels 21/24 Exp Continue readingWalking with Packets: Traceroute Through MPLS Cloud
Think about this for a minute: An MPLS network with a two Provider Edge (PE) routers and some Provider (P) routers. The P routers have no VRFs configured on them and therefore have no routes whatsoever for any of the customer networks. A customer then does a traceroute from one of their sites, across the MPLS cloud, and into one of their other sites. The traceroute output shows the P routers as hops along the path.
How is it possible for the P routers to reply to the traceroute if they don't have routes back to the customer network?
Five Functional Facts about EIGRP
Normally for these FFF articles I’ve taken to writing about new protocols as a way of introducing others to it and also edumacating myself about it. For this post I get all nostalgic and look at good old Enhanced Interior Gateway Routing Protocol (EIGRP).
1 – The EIGRP Metric is Calculated From a Formula
Unlike RIP with its simple hop count or OSPF with its simple bandwidth metric, the EIGRP metric is actually derived by plugging a number of values into a formula and solving the formula. The formula looks like this:

EIGRP Classic Mode Formula
Let’s talk about the k values first. The k values are constants that are configured in IOS and fed into the formula. They have the affect of basically turning on and off the variables that are used in the calculation: bandwidth, delay, load, reliability. They also have the affect of giving more or less emphasis to a variable. For example, setting k3 to 50 would give the “delay” variable more emphasis than if k3 is set to 1. The default settings for the k values are:
- k1 and k3 = 1
- k2, k4, k5 = 0
This has the net result of simplifying the Continue reading
Five Functional Facts about EIGRP
Normally for these FFF articles I've taken to writing about new protocols as a way of introducing others to it and also edumacating myself about it. For this post I get all nostalgic and look at good old Enhanced Interior Gateway Routing Protocol (EIGRP).
EIGRP “FD is Infinity”
Let’s take a look at EIGRP and the state a route can get into where EIGRP tells you “FD is Infinity”.
First of all, every EIGRP speaker maintains a local database called the EIGRP topology table which holds a copy of every route received from every neighbor and every route being advertised by the local system. EIGRP performs its best-path decision process on the entries in this table in order to determine which routes are the best and then hands those best routes to the Routing Information Base (the RIB). By inspecting the entries in this table, you can see things like:
- Bandwidth, Load, Delay, Reliability – the values to go into computing the composite metric
- The actual composite metric that the local system has calculated
- The composite metric that the neighbor calculated
- Whether the route is internal or external
- A list of all neighbors that advertised the route (neighbor’s router ID)
- The feasible distance (FD) for the route
- The metric for the route as seen in the RIB
I’ve used superscript numbers (x) in the output below to indicate where each item in the list above is found.
R12#show ip eigrp topology 10.1.11.0/24
EIGRP-IPv4 Continue readingEIGRP “FD is Infinity”
Let's take a look at EIGRP and the state a route can get into where EIGRP tells you “FD is Infinity”.
OS X – Outlook Search “No Results”
The worst feeling for a geek:

Courtesy of xkcd (http://xkcd.com/979/)
This has happened to me twice now: upgrading Mac OS X from one release to another and after the dust settles, the search function in Outlook 2011 totally breaks and always returns “no results”. As we all know, email sucks and being able to deftly search through that mound of crap in your mail client is the only thing that makes it somewhat bearable.
When I upgraded from 10.8 to 10.9, I was the guy in the cartoon above. I had to resort to uninstalling and reinstalling all of Office to get this repaired. Urgh.
Well, I just upgraded from 10.9 to 10.10 and lo, the same problem with Outlook search. However this time my karma must be right topped off because I found the solution buried in a message board after an hour or so of searching.

Sweet, merciful help!
The post is from the macrumors.com forum and exactly described the issue and how to fix it on my machine. As stated, the permissions on my Microsoft Office 2011 directory allowed only my account to open the directory:
jknight@mac:~% ls -ld /Applications/Microsoft Office Continue readingOS X — Outlook Search “No Results”
The worst feeling for a geek:

Courtesy of xkcd (http://xkcd.com/979/)
This has happened to me twice now: upgrading Mac OS X from one release to another and after the dust settles, the search function in Outlook 2011 totally breaks and always returns “no results”. As we all know, email sucks and being able to deftly search through that mound of crap in your mail client is the only thing that makes it somewhat bearable.
Lab: iBGP and OSPF Traffic Engineering

Click to enlarge
Here’s the scenario: An enterprise network with an MPLS core and two branch locations connected to their own Provider Edge (PE) router. In addition to the MPLS link, the PEs are also connected via a DMVPN tunnel. The PEs are peering via iBGP (of course) and are also OSPF neighbors on the DMVPN. Both Customer Edge (CE) routers at the branch are OSPF neighbors with their local PE.
Task: Use the high speed MPLS network as the primary path between the CE routers and only use the DMVPN network if the MPLS network becomes unavailable.
Question: Is the solution as simple as adjusting the Admin Distance (AD) so that the iBGP routes are more preferred?
Default State
The obvious first issue is the default AD for iBGP (200) is higher than the default AD of OSPF (110) which means the OSPF path over the DMVPN is going to be preferred. This is confirmed if we do a traceroute from R5 to R6:
R5#traceroute 6.6.6.6 source lo5
1 10.0.45.4 2 msec 0 msec 1 msec
2 10.10.10.7 17 msec 17 msec 17 msec
3 10.0.67.6 18 Continue readingLab: iBGP and OSPF Traffic Engineering
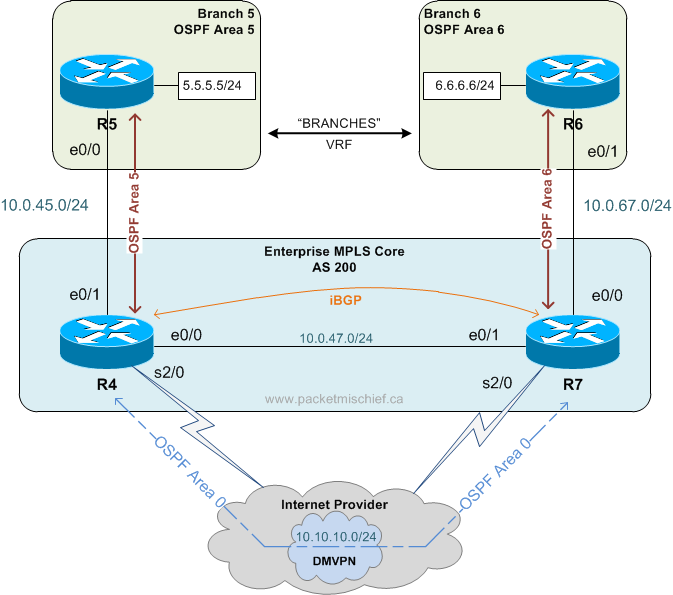
Click to enlarge
Here's the scenario: An enterprise network with an MPLS core and two branch locations connected to their own Provider Edge (PE) router. In addition to the MPLS link, the PEs are also connected via a DMVPN tunnel. The PEs are peering via iBGP (of course) and are also OSPF neighbors on the DMVPN. Both Customer Edge (CE) routers at the branch are OSPF neighbors with their local PE.
Task: Use the high speed MPLS network as the primary path between the CE routers and only use the DMVPN network if the MPLS network becomes unavailable.
Question: Is the solution as simple as adjusting the Admin Distance (AD) so that the iBGP routes are more preferred?
Choosing a Route: Order of Operations
In Cisco IOS packets are forwarded through the router (or Layer 3 switch) by Cisco Express Forwarding (CEF). A data structure called the CEF table contains a list of known IP prefixes and the outgoing interface that packets should be put on in order to get them onwards to their destination. That’s well and good. But how do the IP prefixes make it into the CEF table? To answer that question you have to work backwards and understand the order of operations that IOS goes through in order for a prefix to make it into the CEF table.
The answer to the question of what makes it into the CEF table confused me a bit, particularly when working with complex redistribution schemes. I would end up concentrating so much on admin distance (AD) that I would overlook the other, more important elements that went into determining what went into the CEF table. In order to improve my understanding I came up with this order of operations which helps me not only with redistribution, but in pretty much any situation where I’m trying to do traffic engineering.
You will not find this order of operations on cisco.com or in any Continue reading
Choosing a Route: Order of Operations
In Cisco IOS packets are forwarded through the router (or Layer 3 switch) by Cisco Express Forwarding (CEF). A data structure called the CEF table contains a list of known IP prefixes and the outgoing interface that packets should be put on in order to get them onwards to their destination. That's well and good. But how do the IP prefixes make it into the CEF table? To answer that question you have to work backwards and understand the order of operations that IOS goes through in order for a prefix to make it into the CEF table.
Role Based Access Control in IOS
I don’t believe this is well known: Cisco IOS has Role Based Access Control (RBAC) which can be used to create and assign different levels of privileged access to the device. Without RBAC there are two access levels in IOS: a read-only mode with limited access to commands and no ability to modify the running config (also called privilege level 1) and enable mode with full administrative access. There is no middle ground; it’s all or nothing. RBAC allows creation of access levels somewhere between nothing and everything. A common use case is creating a role for the first line NOC analyst which might allow them to view the running config, configure interfaces, and configure named access-lists.
A “role” in IOS is called a “view” and since views control which commands are available in the command line parser, they are configured under the parser. A view can be assigned a password which allows users to “enable” into the view. More typically, the view is assigned by the RADIUS/TACACS server as part of the authorization process when a user is logging into the device.
A view is configured with the “parser view <view-name>” config command after which commands are added/removed to/from Continue reading
Role Based Access Control in IOS
I don't believe this is well known: Cisco IOS has Role Based Access Control (RBAC) which can be used to create and assign different levels of privileged access to the device. Without RBAC there are two access levels in IOS: a read-only mode with limited access to commands and no ability to modify the running config (also called privilege level 1) and enable mode with full administrative access. There is no middle ground; it's all or nothing. RBAC allows creation of access levels somewhere between nothing and everything. A common use case is creating a role for the first line NOC analyst which might allow them to view the running config, configure interfaces, and configure named access-lists.
What the *, traceroute?
If you’ve ever done a traceroute from one IOS box to another, you’ve undoubtedly seen output like this:
R8# traceroute 192.168.100.7
Tracing the route to 192.168.100.7
VRF info: (vrf in name/id, vrf out name/id)
1 192.168.0.1 4 msec 3 msec 4 msec
2 192.168.100.7 4 msec * 0 msecThat “msec * msec” output. Why is the middle packet always lost?? And why only on the last hop??
This was always something curious to me but not something I ever bothered to learn about. Well it turns out that IOS has a rate limiter that meters the generation of ICMP Unreachable messages. The default setting for the rate limiter is 1 ICMP Unreach every 500ms. Since IOS’s traceroute doesn’t put a delay between its probe packets, the delay between when 192.168.100.7 receives the first and second probe packets is much less than 500ms. The second packet violates the rate limiter and so 192.168.100.7 drops it.
Why isn’t the third packet also dropped? Because the traceroute command waits for 3 seconds (by default) before deciding that a probe packet was lost and Continue reading