Author Archives: Ignat Korchagin
Author Archives: Ignat Korchagin
The Linux kernel is the heart of many modern production systems. It decides when any code is allowed to run and which programs/users can access which resources. It manages memory, mediates access to hardware, and does a bulk of work under the hood on behalf of programs running on top. Since the kernel is always involved in any code execution, it is in the best position to protect the system from malicious programs, enforce the desired system security policy, and provide security features for safer production environments.
In this post, we will review some Linux kernel security configurations we use at Cloudflare and how they help to block or minimize a potential system compromise.
When a machine (either a laptop or a server) boots, it goes through several boot stages:
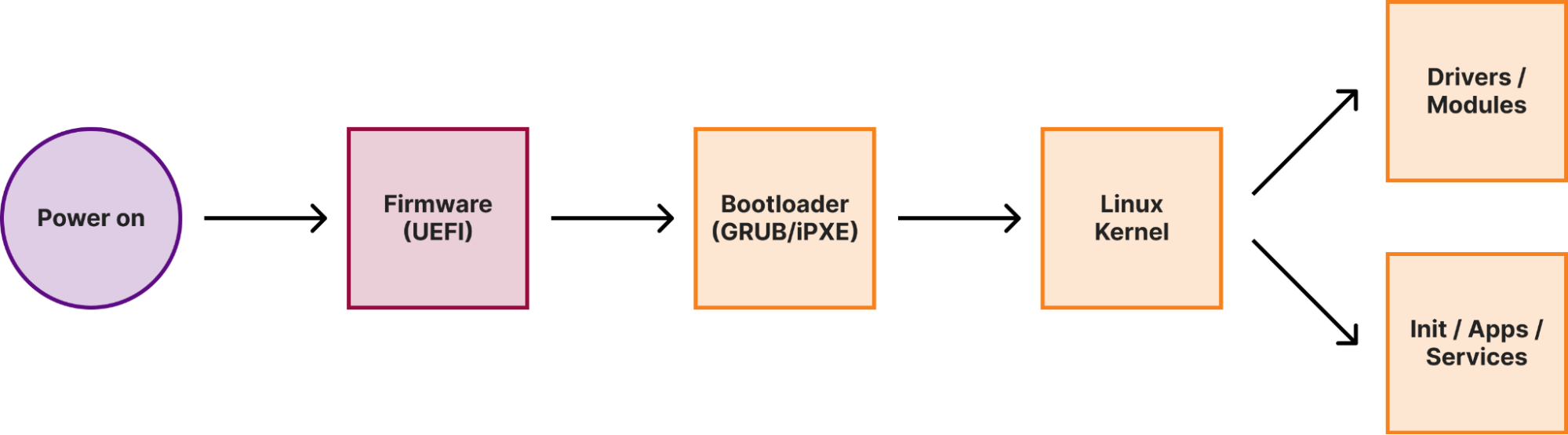
Within a secure boot architecture each stage from the above diagram verifies the integrity of the next stage before passing execution to it, thus forming a so-called secure boot chain. This way “trustworthiness” is extended to every component in the boot chain, because if we verified the code integrity of a particular stage, we can trust this code to verify the integrity of the next stage.

In the part 2 of our series we learned how to process relocations in object files in order to properly wire up internal dependencies in the code. In this post we will look into what happens if the code has external dependencies — that is, it tries to call functions from external libraries. As before, we will be building upon the code from part 2. Let's add another function to our toy object file:
obj.c:
#include <stdio.h>
...
void say_hello(void)
{
puts("Hello, world!");
}
In the above scenario our say_hello function now depends on the puts function from the C standard library. To try it out we also need to modify our loader to import the new function and execute it:
loader.c:
...
static void execute_funcs(void)
{
/* pointers to imported functions */
int (*add5)(int);
int (*add10)(int);
const char *(*get_hello)(void);
int (*get_var)(void);
void (*set_var)(int num);
void (*say_hello)(void);
...
say_hello = lookup_function("say_hello");
if (!say_hello) {
fputs("Failed to find say_hello function\n", stderr);
exit(ENOENT);
}
puts("Executing say_hello...");
say_hello();
}
...
Let's run it:
$ gcc -c obj.c
$ gcc -o loader loader.c
$ ./loader
No runtime base address for section
Seems something went Continue reading
In the previous post, we learned how to parse an object file and import and execute some functions from it. However, the functions in our toy object file were simple and self-contained: they computed their output solely based on their inputs and didn't have any external code or data dependencies. In this post we will build upon the code from part 1, exploring additional steps needed to handle code with some dependencies.
As an example, we may notice that we can actually rewrite our add10 function using our add5 function:
obj.c:
int add5(int num)
{
return num + 5;
}
int add10(int num)
{
num = add5(num);
return add5(num);
}
Let's recompile the object file and try to use it as a library with our loader program:
$ gcc -c obj.c
$ ./loader
Executing add5...
add5(42) = 47
Executing add10...
add10(42) = 42
Whoa! Something is not right here. add5 still produces the correct result, but add10 does not . Depending on your environment and code composition, you may even see the loader program crashing instead of outputting incorrect results. To understand what happened, let's investigate the machine code generated by the compiler. We Continue reading

When we write software using a high-level compiled programming language, there are usually a number of steps involved in transforming our source code into the final executable binary:
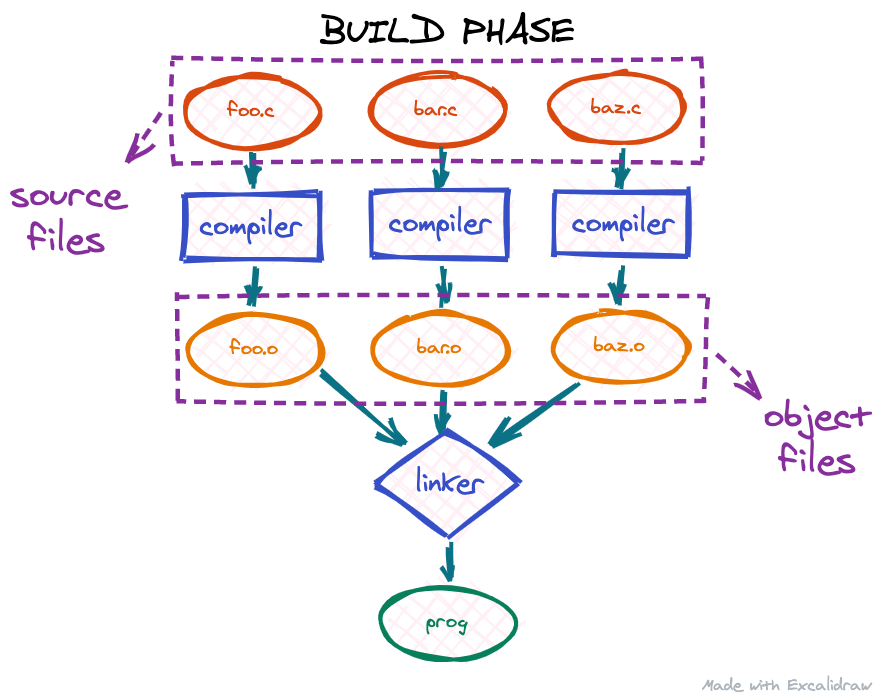
First, our source files are compiled by a compiler translating the high-level programming language into machine code. The output of the compiler is a number of object files. If the project contains multiple source files, we usually get as many object files. The next step is the linker: since the code in different object files may reference each other, the linker is responsible for assembling all these object files into one big program and binding these references together. The output of the linker is usually our target executable, so only one file.
However, at this point, our executable might still be incomplete. These days, most executables on Linux are dynamically linked: the executable itself does not have all the code it needs to run a program. Instead it expects to "borrow" part of the code at runtime from shared libraries for some of its functionality:
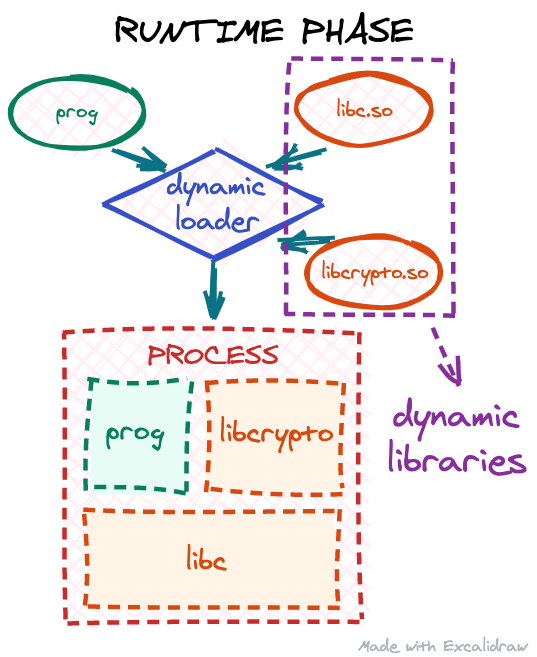
This process is called runtime linking: when our executable is being started, the operating system will invoke the dynamic Continue reading

Modern Linux operating systems provide many tools to run code more securely. There are namespaces (the basic building blocks for containers), Linux Security Modules, Integrity Measurement Architecture etc.
In this post we will review Linux seccomp and learn how to sandbox any (even a proprietary) application without writing a single line of code.

Tux by Iwan Gabovitch, GPL
Sandbox, Simplified Pixabay License
System calls (syscalls) is a well-defined interface between userspace applications and the operating system (OS) kernel. On modern operating systems most applications provide only application-specific logic as code. Applications do not, and most of the time cannot, directly access low-level hardware or networking, when they need to store data or send something over the wire. Instead they use system calls to ask the OS kernel to do specific hardware and networking tasks on their behalf:
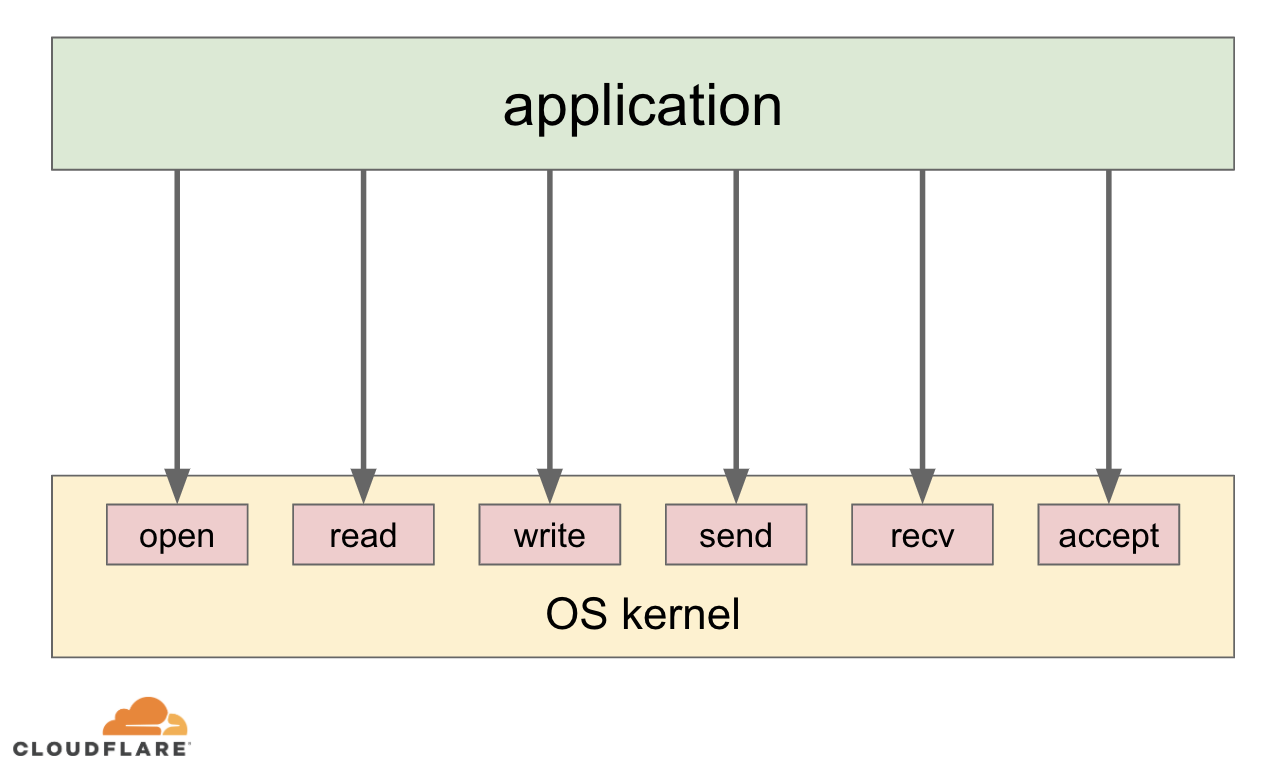
Apart from providing a generic high level way for applications to interact with the low level hardware, the system call architecture allows the OS kernel to manage available resources between applications as well as enforce policies, like application permissions, networking access control lists etc.
Linux seccomp is yet another syscall on Linux, but it is a bit Continue reading
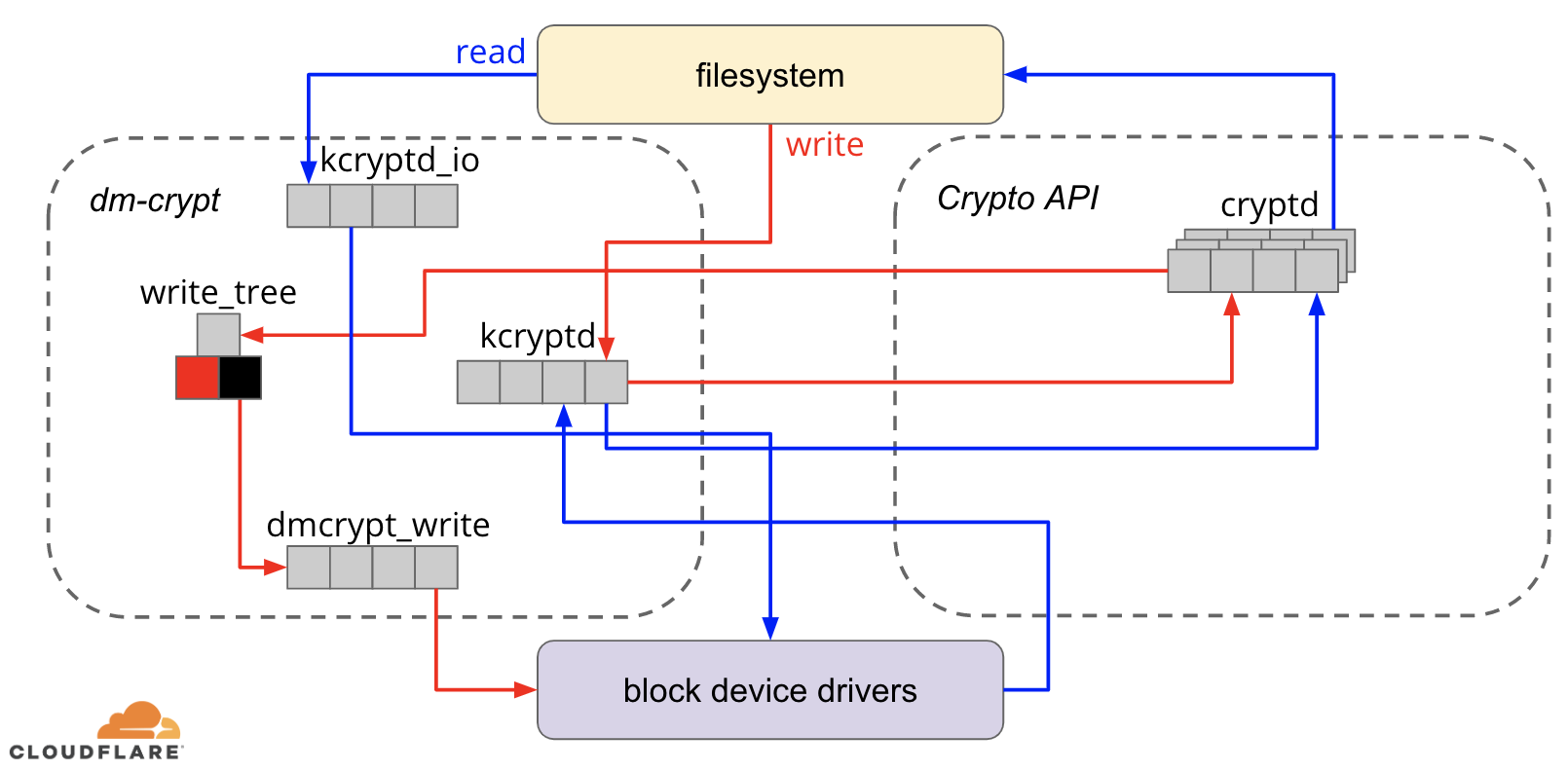
Data encryption at rest is a must-have for any modern Internet company. Many companies, however, don't encrypt their disks, because they fear the potential performance penalty caused by encryption overhead.
Encrypting data at rest is vital for Cloudflare with more than 200 data centres across the world. In this post, we will investigate the performance of disk encryption on Linux and explain how we made it at least two times faster for ourselves and our customers!
When it comes to encrypting data at rest there are several ways it can be implemented on a modern operating system (OS). Available techniques are tightly coupled with a typical OS storage stack. A simplified version of the storage stack and encryption solutions can be found on the diagram below:
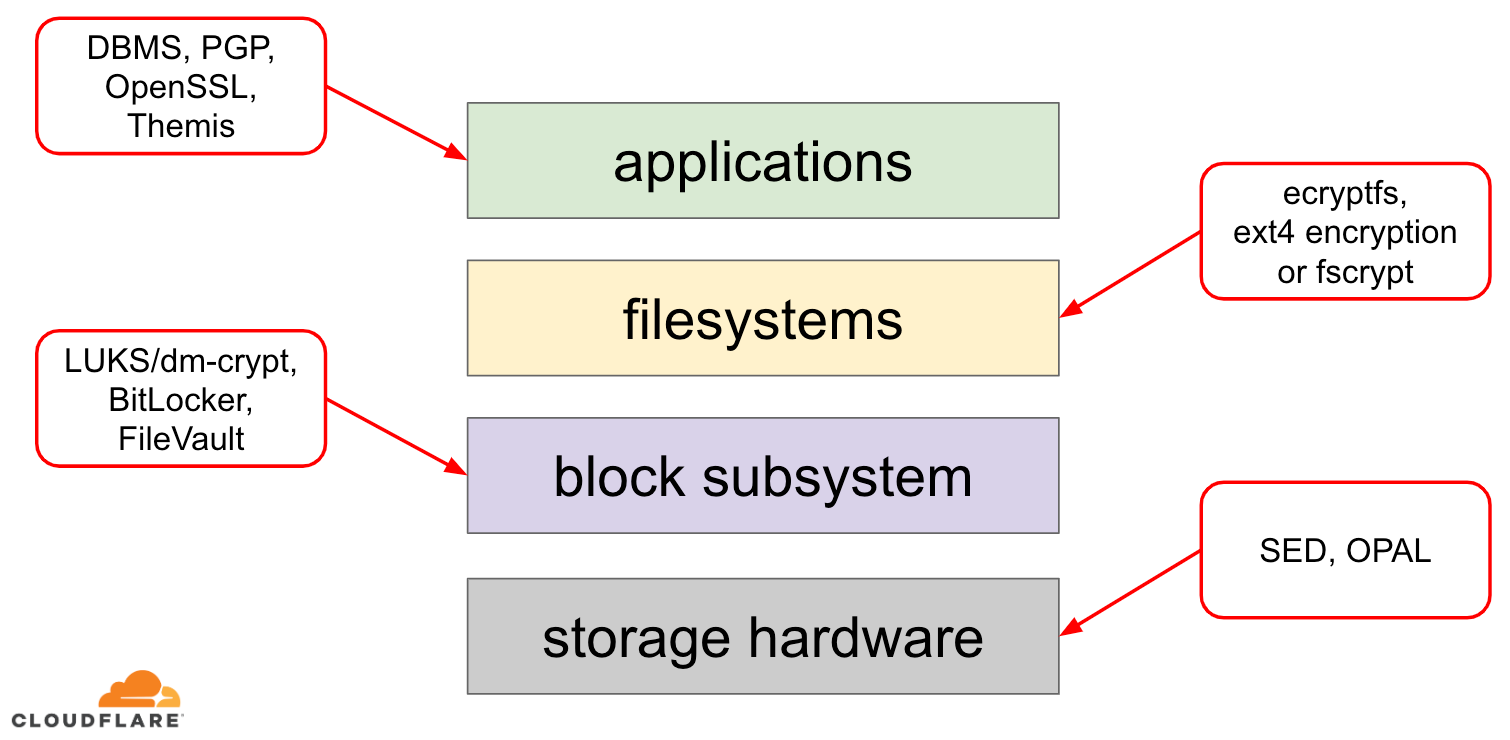
On the top of the stack are applications, which read and write data in files (or streams). The file system in the OS kernel keeps track of which blocks of the underlying block device belong to which files and translates these file reads and writes into block reads and writes, however the hardware specifics of the underlying storage device is abstracted away from the filesystem. Finally, the block subsystem actually Continue reading

At Cloudflare we like Go. We use it in many in-house software projects as well as parts of bigger pipeline systems. But can we take Go to the next level and use it as a scripting language for our favourite operating system, Linux?

gopher image CC BY 3.0 Renee French
Tux image CC0 BY OpenClipart-Vectors
Short answer: why not? Go is relatively easy to learn, not too verbose and there is a huge ecosystem of libraries which can be reused to avoid writing all the code from scratch. Some other potential advantages it might bring:
go build command is mostly suitable for small, self-contained projects. More complex projects usually adopt some build system/set of scripts. Why not have these scripts written in Go then as well?go get it. And because the code will be installed in your GOPATH, getting a third-party library does not require administrative privileges on the system (unlike some other scripting languages). This is especially useful in large Continue reading{kind=link}