Author Archives: John Graham-Cumming
Author Archives: John Graham-Cumming
Today, after more than 13 years at the company, I am joining Cloudflare’s board of directors and retiring from my full-time position as CTO.
Back in 2012 I wrote a short post on my personal site simply titled: Programmer. The post announced that I’d recently joined a company called CloudFlare (still sporting that capital “F”) with the job title Programmer. I’d chosen that title in part because it was the very first title I’d ever had, and because it would reflect what I’d be doing at Cloudflare.
I had spent a lot of time working at startups—in technical and then management roles—and wanted to go back to the really technical part that I loved most. Cloudflare gave me that opportunity, and I worked on a lot of systems that make up the Cloudflare that so many people around the world use today.
Looking back on my time at the company it’s really, really hard to pick my top highlights. In 2019 I wrote 6,000 words on the experience of helping build Cloudflare. But here are five that stand out:
The night we finished the preparation to launch Universal SSL sticks in my memory. We set out to Continue reading

In April 2020, we blogged about how to get COBOL running on Cloudflare Workers by compiling to WebAssembly. The ecosystem around WebAssembly has grown significantly since then, and it has become a solid foundation for all types of projects, be they client-side or server-side.
As WebAssembly support has grown, more and more languages are able to compile to WebAssembly for execution on servers and in browsers. As Cloudflare Workers uses the V8 engine and supports WebAssembly natively, we’re able to support languages that compile to WebAssembly on the platform.
Recently, work on LLVM has enabled Fortran to compile to WebAssembly. So, today, we’re writing about running Fortran code on Cloudflare Workers.
Before we dive into how to do this, here’s a little demonstration of number recognition in Fortran. Draw a number from 0 to 9 and Fortran code running somewhere on Cloudflare’s network will predict the number you drew.

Try yourself on handwritten-digit-classifier.fortran.demos.cloudflare.com.
This is taken from the wonderful Fortran on WebAssembly post but instead of running client-side, the Fortran code is running on Cloudflare Workers. Read on to find out how you can use Fortran on Cloudflare Workers and how that demonstration works.


Matthew and Michelle, co-founders of Cloudflare, published their annual founders’ letter today. The letter ends with a poem written by an AI running using Workers AI on Cloudflare’s global network.
Here’s the code that wrote the poem. It uses Workers AI and the Meta Llama 2 model with 7B parameters and 8-bit integers. Just 14 lines of code running on the Cloudflare global network, and you’ve got your very own AI to chat with.
import { Ai } from "@cloudflare/ai";
export default {
async fetch(request: Request, env: Env): Promise<Response> {
const body = await request.json();
const ai = new Ai(env.AI);
const response = await ai.run("@cf/meta/llama-2-7b-chat-int8", body);
return new Response(JSON.stringify(response));
},
};
export interface Env {
AI: any;
}
That was deployed on Workers AI and all I had to do was ask for poems. Here’s my terminal output (with just the domain name changed).
% curl -X POST https://example.com/ -d '{"prompt":"Write a poem \
that talks about the connectivity cloud"}' | jq -r .response
Cloud computing provides a connectivity that's unmatched,A bridge that spans the globe with ease and grace.It brings us closer, no matter where we are,And makes the world a Continue reading


Having been at Cloudflare since it was tiny it’s hard to believe that we’re hitting our teens! But here we are 13 years on from launch. Looking back to 2010 it was the year of iPhone 4, the first iPad, the first Kinect, Inception was in cinemas, and TiK ToK was hot (well, the Kesha song was). Given how long ago all that feels, I'd have a hard time predicting the next 13 years, so I’ll stick to predicting the future by creating it (with a ton of help from the Cloudflare team).
Building the future is, in part, what Birthday Week is about. Over the past 13 years we’ve announced things like Universal SSL (doubling the size of the encrypted web overnight and helping to usher in the largely encrypted web we all use; Cloudflare Radar shows that worldwide 99% of HTTP requests are encrypted), or Cloudflare Workers (helping change the way people build and scale applications), or unmetered DDoS protection (to help with the scourge of DDoS).
This year will be no different.
Winding back to the year I joined Cloudflare we made our first Birthday Week announcement: our automatic IPv6 gateway. Fast-forward to today and Continue reading
The 1947 paper titled “Preparation of Problems for EDVAC-Type Machines” talks about the idea and usefulness of a “subroutine”. At the time there were only a tiny number of computers worldwide and subroutines were a novel idea, and it was clear that these subroutines were going to make programmers more productive: “Many operations which are thus excluded from the built-in set are still of sufficiently frequent occurrence to make undesirable the repetition of their coding in detail.”
Looking back it seems amazing that subroutines had to be invented, but at the time programmers wrote literally everything they needed to complete a task. That made programming slow, error-prone and restricted who could be a programmer to a relatively small group of people.
Luckily, things changed.
You can look at the history of computer programming as improvements in programmer productivity and widening the scope of who is a programmer. Think of syntax highlighting, high-level languages, IDEs, libraries and frameworks, APIs, Visual Basic, code completion, refactoring tools, spreadsheets, and so on.
And here we are with things changing again.
The recent arrival of LLMs capable of assisting programmers in writing, debugging and modifying code is yet Continue reading


In Cloudflare’s S-1 document there’s a section that begins: “The Internet was not built for what it has become”.
That sentence expresses the idea that the Internet, which started as an experiment, has blossomed into something we all need to rely upon for our daily lives and work. And that more is needed than just the Internet as was designed; it needed security and performance and privacy.
Something similar can be said about the cloud: the cloud was not designed for what it must become.
The introduction of services like Amazon EC2 was undoubtedly a huge improvement on the old way of buying and installing racks and racks of servers and storage systems, and then maintaining them.
But by its nature the cloud was a virtualization of the older real world infrastructure and not a radical rethink of what computing should look like to meet the demands of Internet-scale businesses. It’s as if steam locomotives were replaced with efficient electric engines but still required a chimney on top and stopped to take on water every two hundred miles.

The cloud replaced the rituals of buying servers and installing operating systems with new and now familiar rituals of choosing regions, and Continue reading


Today, a change to our Tiered Cache system caused some requests to fail for users with status code 530. The impact lasted for almost six hours in total. We estimate that about 5% of all requests failed at peak. Because of the complexity of our system and a blind spot in our tests, we did not spot this when the change was released to our test environment.
The failures were caused by side effects of how we handle cacheable requests across locations. At first glance, the errors looked like they were caused by a different system that had started a release some time before. It took our teams a number of tries to identify exactly what was causing the problems. Once identified we expedited a rollback which completed in 87 minutes.
We’re sorry, and we’re taking steps to make sure this does not happen again.
One of Cloudflare’s products is our Content Delivery Network, or CDN. This is used to cache assets for websites globally. However, a data center is not guaranteed to have an asset cached. It could be new, expired, or has been purged. If that happens, and a user requests that asset, our CDN needs Continue reading


Almost a teen. With Cloudflare’s 12th birthday last Tuesday, we’re officially into our thirteenth year. And what a birthday we had!
36 announcements ranging from SIM cards to post quantum encryption via hardware keys and so much more. Here’s a review of everything we announced this week.
| What | In a sentence… |
|---|---|
| The First Zero Trust SIM | We’re bringing Zero Trust security controls to the humble SIM card, rethinking how mobile device security is done, with the Cloudflare SIM: the world’s first Zero Trust SIM. |
| Securing the Internet of Things | We’ve been defending customers from Internet of Things botnets for years now, and it’s time to turn the tides: we’re bringing the same security behind our Zero Trust platform to IoT. |
| Bringing Zero Trust to mobile network operators | Helping bring the power of Cloudflare’s Zero Trust platform to mobile operators and their subscribers. |
| What | In a sentence… |
|---|---|
| Workers Launchpad | Leading venture capital firms to provide up to $1.25 BILLION to back startups built on Cloudflare Workers. |
| Startup Plan v2.0 | Increasing the scope, eligibility and products we include under our Startup Plan, enabling more developers and startups to build the next big thing on top of Cloudflare. |
| workerd: Continue reading |

Back in 2019, we worked on a chart for Cloudflare’s IPO S-1 document that showed major releases since Cloudflare was launched in 2010. Here’s that chart:
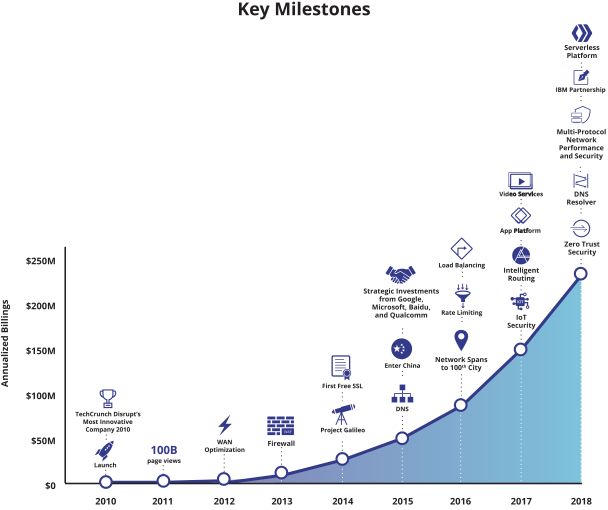
Of course, that chart doesn’t show everything we’ve shipped, but the curve demonstrates a truth about a growing company: we keep shipping more and more products and services. Some of those things start with a beta, sometimes open and sometimes private. But all of them become generally available after the beta period.
Back in, say, 2014, we only had a few major releases per year. But as the years have progressed and the company has grown we have constant updates, releases and changes. This year a confluence of products becoming generally available in September meant it made sense to wrap them all up into GA Week.
GA Week has now finished, and the team is working to put the finishing touches on Birthday Week (coming this Sunday!), but here’s a recap of everything that we launched this week.
| What launched | Summary | Available for? |
|---|---|---|
| Monday (September 19) | ||
| Cloudforce Continue reading |


Cloudflare ships a lot of products. Some of those products are shipped as beta, sometimes open, sometimes closed, and our huge customer base gives those betas an incredible workout. Making products work at scale, and in the heterogeneous environment of the real Internet is a challenge. We’re lucky to have so many enthusiastic customers ready to try out our betas.
And when those products exit beta they’re GA or Generally Available. This week you’ll be hearing a lot about products becoming GA.
But it’s not just about making products work and be available, it’s about making the best-of-breed. We ship early and iterate rapidly. We’ve done this over the years for WAF, DDoS mitigation, bot management, API protection, CDN and our developer platform. Today analyst firms such as Gartner, Forrester and IDC recognize us as leaders in all those areas.
That’s one reason we’re trusted by the likes of Broadcom, NCR, DHL Parcel, Panasonic, Canva, Shopify, L'Oréal, DoorDash, Garmin and more.
Over the years we’ve heard criticism that we’re the new kid on the block. The latest iteration of that is Zero Trust vendors seeing us as novices. It sounds all too familiar. It’s what the Continue reading


Here’s a short list of recent technical blog posts to give you something to read today.
Microsoft has announced the end-of-life for the venerable Internet Explorer browser. Here we take a look at the demise of IE and the rise of the Edge browser. And we investigate how many bots on the Internet continue to impersonate Internet Explorer versions that have long since been replaced.
Looking for something with a lot of technical detail? Look no further than this blog about live-patching the Linux kernel using eBPF. Code, Makefiles and more within!
Feeling mathematical? Or just need a dose of CPU-level antics? Look no further than this deep explainer about how CPU frequency scaling leads to a nasty side channel affecting cryptographic algorithms.
The HTTP standard for Early Hints shows a lot of promise. How much? In this blog post, we dig into data about Early Hints in the real world and show how much faster the web is with it.

Today, March 22, 2022 at 03:30 UTC we learnt of a compromise of Okta. We use Okta internally for employee identity as part of our authentication stack. We have investigated this compromise carefully and do not believe we have been compromised as a result. We do not use Okta for customer accounts; customers do not need to take any action unless they themselves use Okta.
Our understanding is that during January 2022, hackers outside Okta had access to an Okta support employee’s account and were able to take actions as if they were that employee. In a screenshot shared on social media, a Cloudflare employee’s email address was visible, along with a popup indicating the hacker was posing as an Okta employee and could have initiated a password reset.
We learnt of this incident via Cloudflare’s internal SIRT. SIRT is our Security Incident Response Team and any employee at Cloudflare can alert SIRT to a potential problem. At exactly 03:30 UTC, a Cloudflare employee emailed SIRT with a link to a tweet that had been sent at 03:22 UTC. The tweet indicated that Okta had potentially been breached. Multiple other Cloudflare employees contacted SIRT over the following Continue reading
Cloudflare operates in more than 250 cities worldwide where we connect our equipment to the Internet to provide our broad range of services. We have data centers in Ukraine, Belarus and Russia and across the world. To operate our service we monitor traffic trends, performance and errors seen at each data center, aggregate data about DNS, and congestion and packet loss on Internet links.
For reference, here is a map of Ukraine showing its major cities. Note that whenever we talk about dates and times in this post, we are using UTC. Ukraine’s current time zone is UTC+2.
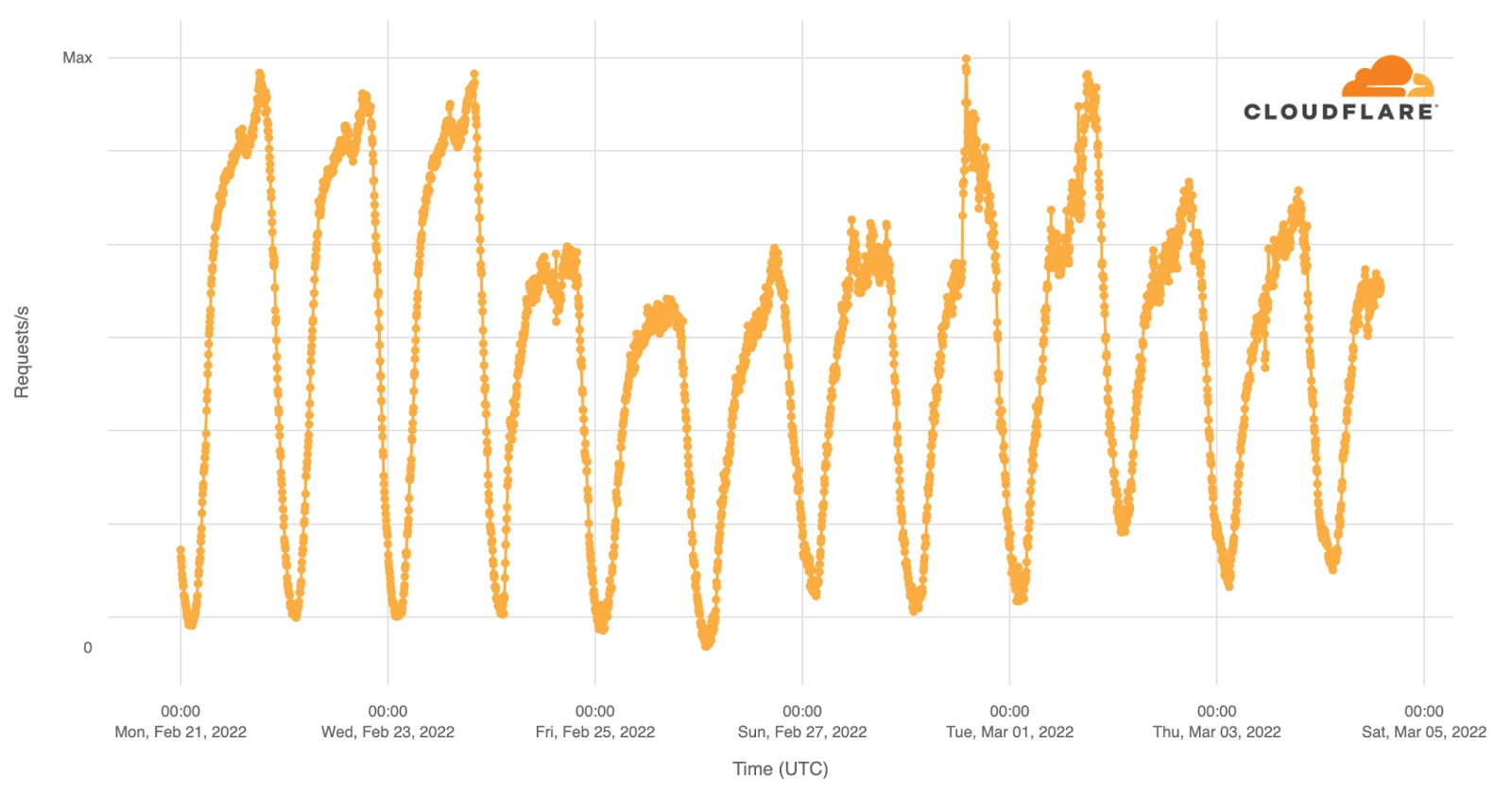
Internet traffic in Ukraine generally follows a pretty predictable pattern based on day and night. Lowest in the hours after local midnight and picking up as people wake up. It’s not uncommon to see a dip around lunchtime and a peak when people go home in the evening. That pattern is clearly visible in this chart of overall Internet traffic seen by Cloudflare for Ukrainian networks on Monday, Tuesday, and Wednesday prior to the invasion.
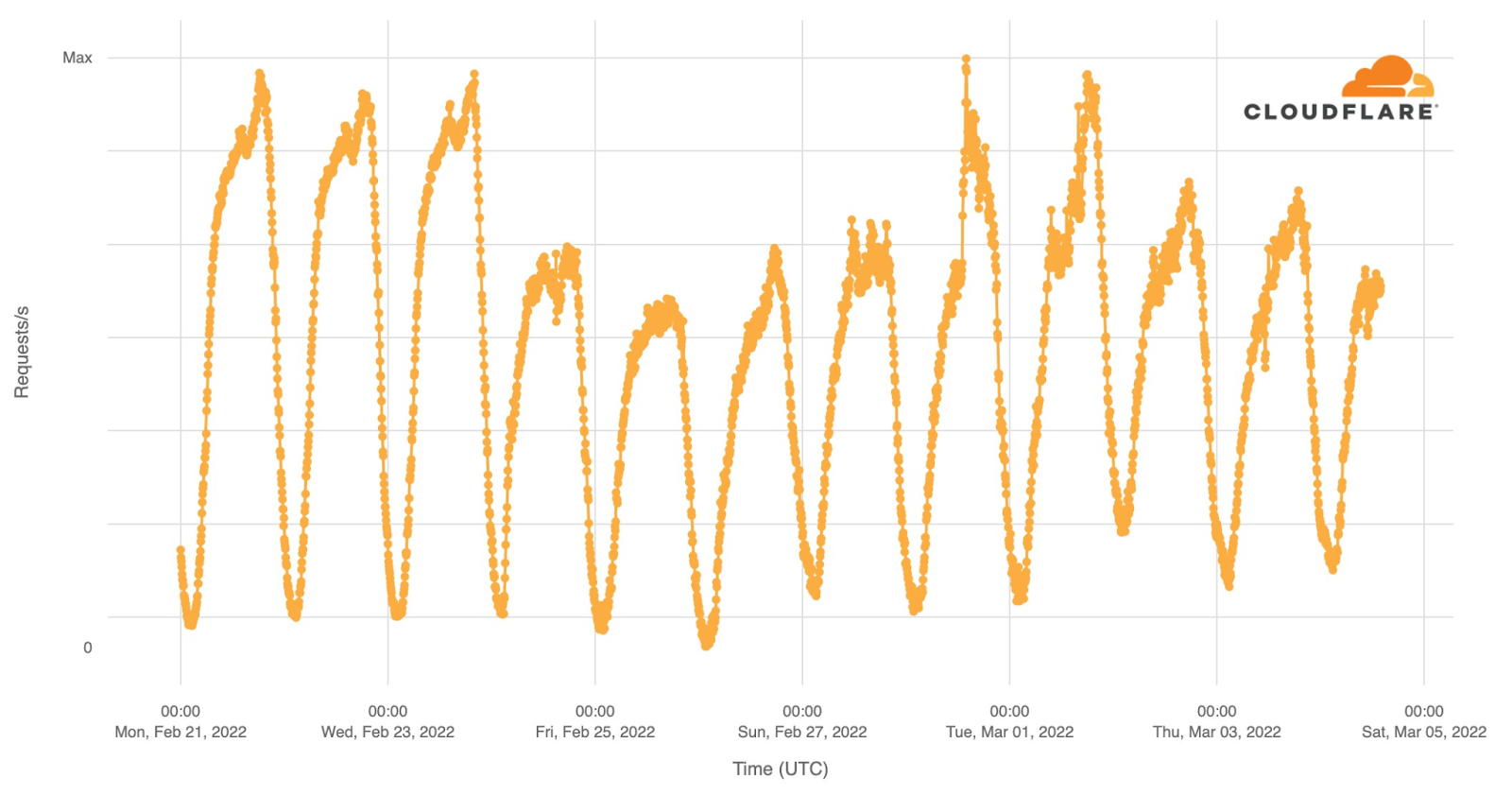
Starting Thursday, traffic was significantly lower. On Thursday, we saw about 70% of our normal request volume and about 60% on Friday. Continue reading

This post is also available in Français and Español.

Cloudflare’s mission is to help build a better Internet. We’ve invested heavily in building the world’s most powerful cloud network to deliver a faster, safer and more reliable Internet for our users. Today, we’re taking a big step towards enhancing our ability to secure our customers.
Earlier today we announced that Cloudflare has agreed to acquire Area 1 Security. Area 1’s team has built exceptional cloud-native technology to protect businesses from email-based security threats. Cloudflare will integrate Area 1’s technology with our global network to give customers the most complete Zero Trust security platform available.
Back at the turn of the century I was involved in the fight against email spam. At the time, before the mass use of cloud-based email, spam was a real scourge. Clogging users’ inboxes, taking excruciatingly long to download, and running up people’s Internet bills. The fight against spam involved two things, one technical and one architectural.
Technically, we figured out how to use machine-learning to successfully differentiate between spam and genuine. And fairly quickly email migrated to being largely cloud-based. But together these changes didn’t kill spam, but they relegated to a Continue reading
In this blog post we will cover WAF evasion patterns and exfiltration attempts seen in the wild, trend data on attempted exploitation, and information on exploitation that we saw prior to the public disclosure of CVE-2021-44228.
In short, we saw limited testing of the vulnerability on December 1, eight days before public disclosure. We saw the first attempt to exploit the vulnerability just nine minutes after public disclosure showing just how fast attackers exploit newly found problems.
We also see mass attempts to evade WAFs that have tried to perform simple blocking, we see mass attempts to exfiltrate data including secret credentials and passwords.
Since the disclosure of CVE-2021-44228 (now commonly referred to as Log4Shell) we have seen attackers go from using simple attack strings to actively trying to evade blocking by WAFs. WAFs provide a useful tool for stopping external attackers and WAF evasion is commonly attempted to get past simplistic rules.
In the earliest stages of exploitation of the Log4j vulnerability attackers were using un-obfuscated strings typically starting with ${jndi:dns, ${jndi:rmi and ${jndi:ldap and simple rules to look for those patterns were effective.
Quickly after those strings were being blocked and attackers Continue reading

I wrote earlier about how to mitigate CVE-2021-44228 in Log4j, how the vulnerability came about and Cloudflare’s mitigations for our customers. As I write we are rolling out protection for our FREE customers as well because of the vulnerability’s severity.
As we now have many hours of data on scanning and attempted exploitation of the vulnerability we can start to look at actual payloads being used in wild and statistics. Let’s begin with requests that Cloudflare is blocking through our WAF.
We saw a slow ramp up in blocked attacks this morning (times here are UTC) with the largest peak at around 1800 (roughly 20,000 blocked exploit requests per minute). But scanning has been continuous throughout the day. We expect this to continue.
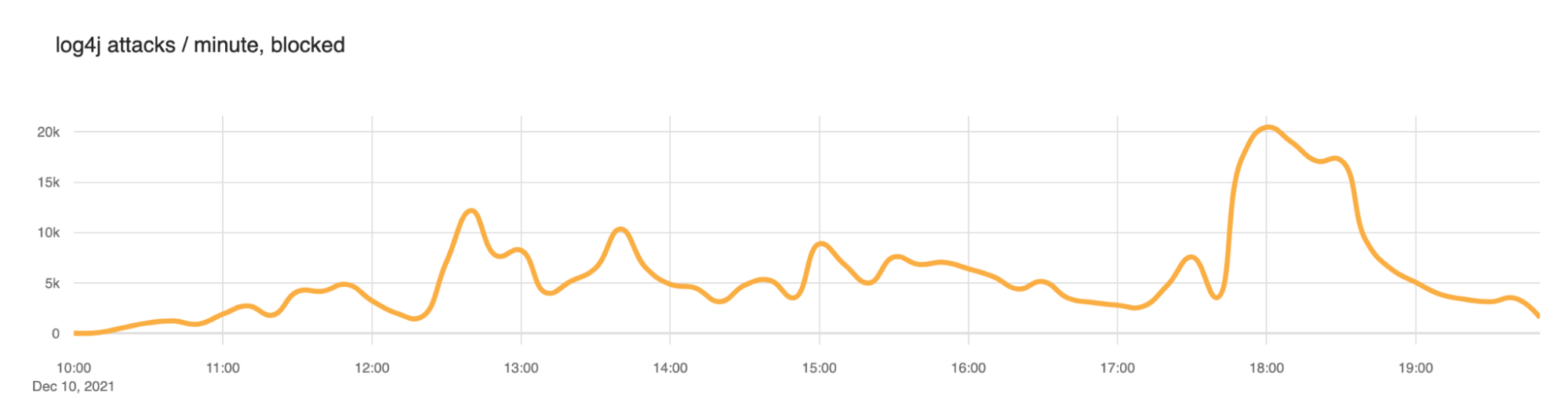
We also took a look at the number of IP addresses that the WAF was blocking. Somewhere between 200 and 400 IPs appear to be actively scanning at any given time.
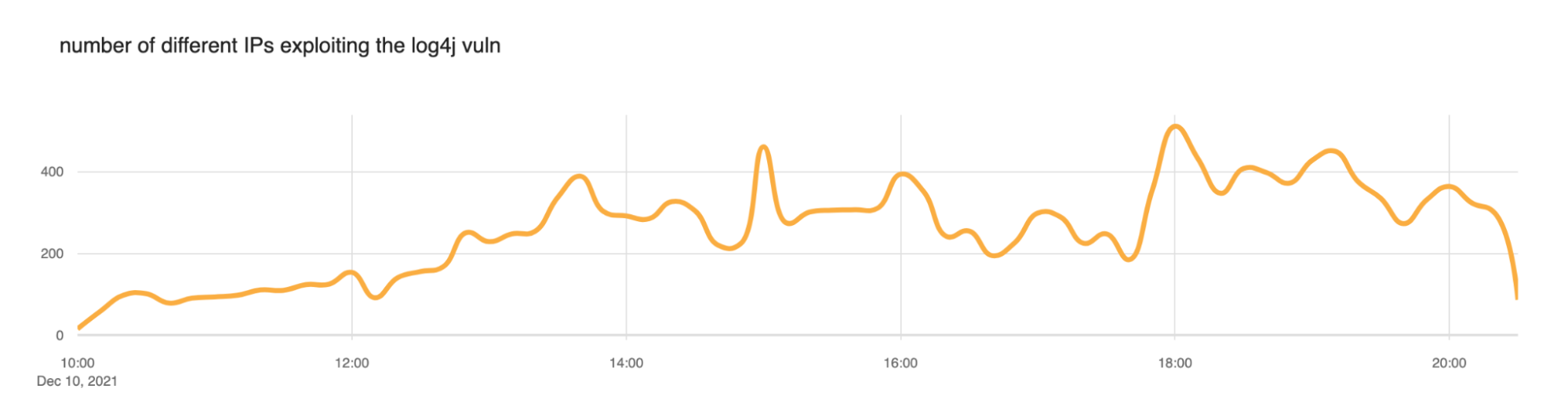
So far today the largest number of scans or exploitation attempts have come from Canada and then the United States.
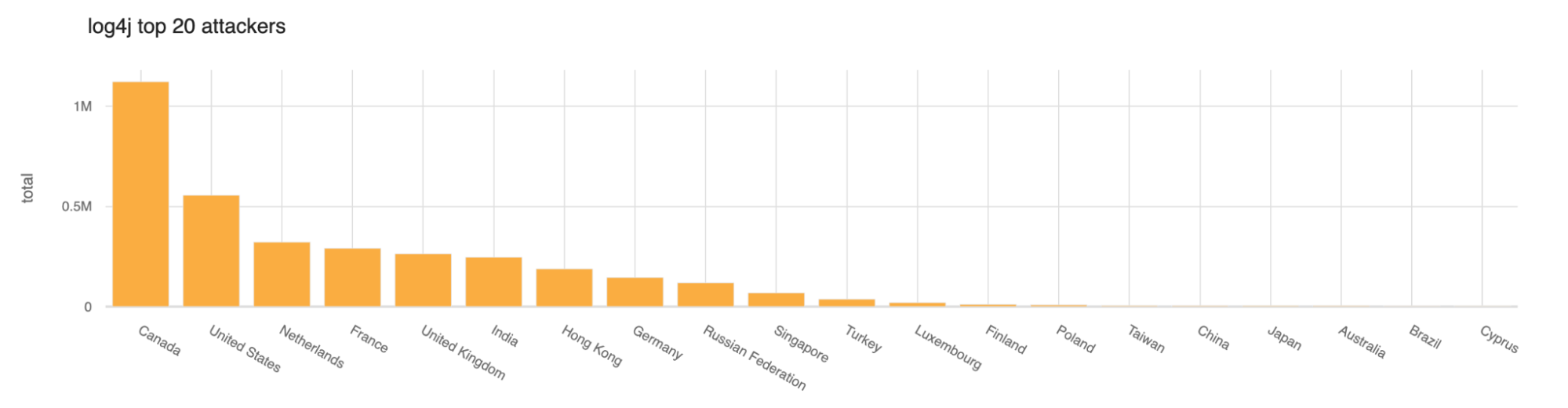
Lots of the blocked requests appear to be in the form of reconnaissance to see if a server is actually exploitable. The top blocked exploit string Continue reading

Yesterday, December 9, 2021, a very serious vulnerability in the popular Java-based logging package Log4j was disclosed. This vulnerability allows an attacker to execute code on a remote server; a so-called Remote Code Execution (RCE). Because of the widespread use of Java and log4j this is likely one of the most serious vulnerabilities on the Internet since both Heartbleed and ShellShock.
It is CVE-2021-44228 and affects version 2 of log4j between versions 2.0-beta-9 and 2.14.1. It is not present in version 1 of log4j and is patched in 2.15.0.
In this post we explain the history of this vulnerability, how it was introduced, how Cloudflare is protecting our clients. Details of actual attempted exploitation we are seeing blocked by our firewall service are in a separate blog post.
Cloudflare uses some Java-based software and our teams worked to ensure that our systems were not vulnerable or that this vulnerability was mitigated. In parallel, we rolled out firewall rules to protect our customers.
But, if you work for a company that is using Java-based software that uses log4j you should immediately read the section on how to mitigate and protect your systems before reading the rest.


During Speed Week we’ve talked a lot about services that make the web faster. Argo 2.0 for better routing around bad Internet weather, Orpheus to ensure that origins are reachable from anywhere, image optimization to send just the right bits to the client, Tiered Cache to maximize cache hit rates and get the most out of Cloudflare’s new 25% bigger network, our expanded fiber backbone and more.
Those things are all great.
But it’s vital that we also measure the performance of our network and benchmark ourselves against industry players large and small to make sure we are providing the best, fastest service.
We recently ran a measurement experiment where we used Real User Measurement (RUM) data from the standard browser API to test the performance of Cloudflare and others in real-world conditions across the globe. We wanted to use third-party tests for this, but they didn’t have the granularity we wanted. We want to drill down to every single ISP in the world to make sure we optimize everywhere. We knew that in some places the answers we got wouldn’t be good, and we’d need to do work to improve our performance. But without detailed analysis across the Continue reading


No one likes to wait. Internet impatience is something we all suffer from.
Waiting for an app to update to show when your lunch is arriving; a website that loads slowly on your phone; a movie that hasn’t started to play… yet.
But building a waitless Internet is hard. And that’s where Cloudflare comes in. We’ve built the global network for Internet applications, be they websites, IoT devices or mobile apps. And we’ve optimized it to cut the wait.
If you believe ISP advertising then you’d think that bandwidth (100Mbps! 1Gbps! 2Gbps!) is the be all and end all of Internet speed. That’s a small component of what it takes to deliver the always on, instant experience we want and need.
The reality is you need three things: ample bandwidth, to have content and applications close to the end user, and to make the software as fast as possible. Simple really. Except not, because all three things require a lot of work at different layers.
In this blog post I’ll look at the factors that go into building our fast global network: bandwidth, latency, reliability, caching, cryptography, DNS, preloading, cold starts, and more; and how Cloudflare zeroes in on Continue reading


Cloudflare is known for innovation, for needle-moving projects that help make the Internet better. For Impact Week, we wanted to take this approach to innovation and apply it to the environmental impact of the Internet. When it comes to tech and the environment, it’s often assumed that the only avenue tech has open to it is harm mitigation: for example, climate credits, carbon offsets, and the like. These are undoubtedly important steps, but we wanted to take it further — to get into harm reduction. So we asked — how can the Internet at large use less energy and be more thoughtful about how we expend computing resources in the first place?
Cloudflare has a global view into the traffic of the Internet. More than 1 in 6 websites use our network, and we observe the traffic flowing to and from them continuously. While most people think of surfing the Internet as a very human activity, nearly half of all traffic on the global network is generated by automated systems.
We've analyzed this automated traffic, from so-called “bots,” in order to understand the environmental impact. Most of the bot traffic is malicious. Cloudflare protects our clients from this malicious traffic Continue reading