Author Archives: Vlad Krasnov
Author Archives: Vlad Krasnov
Inference powers some of today’s most powerful AI products: chat bot replies, AI agents, autonomous vehicle decisions, and fraud detection. The problem is, if you’re building one of these products on top of a hyperscaler, you’ll likely need to rent expensive GPUs from large centralized data centers to run your inference tasks. That model doesn’t work for Cloudflare — there’s a mismatch between Cloudflare’s globally-distributed network and a typical centralized AI deployment using large multi-GPU nodes. As a company that operates our own compute on a lean, fast, and widely distributed network within 50ms of 95% of the world’s Internet-connected population, we need to be running inference tasks more efficiently than anywhere else.
This is further compounded by the fact that AI models are getting larger and more complex. As we started to support these models, like the Llama 4 herd and gpt-oss, we realized that we couldn’t just throw money at the scaling problems by buying more GPUs. We needed to utilize every bit of idle capacity and be agile with where each model is deployed.
After running most of our models on the widely used open source inference and serving engine vLLM, we figured out it Continue reading
Today we are happy to release the source code of a project we’ve been working on for the past few months. It is called BoringTun, and is a userspace implementation of the WireGuard® protocol written in Rust.
![]()
WireGuard is relatively new project that attempts to replace old VPN protocols, with a simple, fast, and safe protocol. Unlike legacy VPNs, WireGuard is built around the Noise Protocol Framework and relies only on a select few, modern, cryptographic primitives: X25519 for public key operations, ChaCha20-Poly1305 for authenticated encryption, and Blake2s for message authentication.
Like QUIC, WireGuard works over UDP, but its only goal is to securely encapsulate IP packets. As a result, it does not guarantee the delivery of packets, or that packets are delivered in the order they are sent.
The simplicity of the protocol means it is more robust than old, unmaintainable codebases, and can also be implemented relatively quickly. Despite its relatively young age, WireGuard is quickly gaining in popularity.
While evaluating the potential value WireGuard could provide us, we first considered the existing implementations. Currently, there are three usable implementations
As TLS 1.3 was ratified earlier this year, I was recollecting how we got started with it here at Cloudflare. We made the decision to be early adopters of TLS 1.3 a little over two years ago. It was a very important decision, and we took it very seriously.
It is no secret that Cloudflare uses nginx to handle user traffic. A little less known fact, is that we have several instances of nginx running. I won’t go into detail, but there is one instance whose job is to accept connections on port 443, and proxy them to another instance of nginx that actually handles the requests. It has pretty limited functionality otherwise. We fondly call it nginx-ssl.
Back then we were using OpenSSL for TLS and Crypto in nginx, but OpenSSL (and BoringSSL) had yet to announce a timeline for TLS 1.3 support, therefore we had to implement our own TLS 1.3 stack. Obviously we wanted an implementation that would not affect any customer or client that would not enable TLS 1.3. We also needed something that we could iterate on quickly, because the spec was very fluid back then, and also something Continue reading

As engineers at Cloudflare quickly adapt our software stack to run on ARM, a few parts of our software stack have not been performing as well on ARM processors as they currently do on our Xeon® Silver 4116 CPUs. For the most part this is a matter of Intel specific optimizations some of which utilize SIMD or other special instructions.
One such example is the venerable jpegtran, one of the workhorses behind our Polish image optimization service.
A while ago I optimized our version of jpegtran for Intel processors. So when I ran a comparison on my test image, I was expecting that the Xeon would outperform ARM:
vlad@xeon:~$ time ./jpegtran -outfile /dev/null -progressive -optimise -copy none test.jpg
real 0m2.305s
user 0m2.059s
sys 0m0.252s
vlad@arm:~$ time ./jpegtran -outfile /dev/null -progressive -optimise -copy none test.jpg
real 0m8.654s
user 0m8.433s
sys 0m0.225s
Ideally we want to have the ARM performing at or above 50% of the Xeon performance per core. This would make sure we have no performance regressions, and net performance gain, since the ARM CPUs have double the core count as our current 2 socket setup.
In this case, however, I Continue reading
I wouldn’t be surprised if the title of this post attracts some Bitcoin aficionados, but if you are such, I want to disappoint you. For me crypto means cryptography, not cybermoney, and the price we pay for it is measured in CPU cycles, not USD.
If you got to this second paragraph you probably heard that TLS today is very cheap to deploy. Considerable effort was put to optimize the cryptography stacks of OpenSSL and BoringSSL, as well as the hardware that runs them. However, aside for the occasional benchmark, that can tell us how many GB/s a given algorithm can encrypt, or how many signatures a certain elliptic curve can generate, I did not find much information about the cost of crypto in real world TLS deployments.
 CC BY-SA 2.0 image by Michele M. F.
CC BY-SA 2.0 image by Michele M. F.
As Cloudflare is the largest provider of TLS on the planet, one would think we perform a lot of cryptography related tasks, and one would be absolutely correct. More than half of our external traffic is now TLS, as well as all of our internal traffic. Being in that position means that crypto performance is critical to our success, and as it Continue reading
I wouldn’t be surprised if the title of this post attracts some Bitcoin aficionados, but if you are such, I want to disappoint you. For me crypto means cryptography, not cybermoney, and the price we pay for it is measured in CPU cycles, not USD.
If you got to this second paragraph you probably heard that TLS today is very cheap to deploy. Considerable effort was put to optimize the cryptography stacks of OpenSSL and BoringSSL, as well as the hardware that runs them. However, aside for the occasional benchmark, that can tell us how many GB/s a given algorithm can encrypt, or how many signatures a certain elliptic curve can generate, I did not find much information about the cost of crypto in real world TLS deployments.
CC BY-SA 2.0 image by Michele M. F.
As Cloudflare is the largest provider of TLS on the planet, one would think we perform a lot of cryptography related tasks, and one would be absolutely correct. More than half of our external traffic is now TLS, as well as all of our internal traffic. Being in that position means that crypto performance is critical to our success, and as it Continue reading
Not long ago I needed to benchmark the performance of Golang on a many-core machine. I took several of the benchmarks that are bundled with the Go source code, copied them, and modified them to run on all available threads. In that case the machine has 24 cores and 48 threads.
 CC BY-SA 2.0 image by sponki25
CC BY-SA 2.0 image by sponki25
I started with ECDSA P256 Sign, probably because I have warm feeling for that function, since I optimized it for amd64.
First, I ran the benchmark on a single goroutine: ECDSA-P256 Sign,30618.50, op/s
That looks good; next I ran it on 48 goroutines: ECDSA-P256 Sign,78940.67, op/s.
OK, that is not what I expected. Just over 2X speedup, from 24 physical cores? I must be doing something wrong. Maybe Go only uses two cores? I ran top, it showed 2,266% utilization. That is not the 4,800% I expected, but it is also way above 400%.
How about taking a step back, and running the benchmark on two goroutines? ECDSA-P256 Sign,55966.40, op/s. Almost double, so pretty good. How about four goroutines? ECDSA-P256 Sign,108731.00, op/s. That is actually faster than 48 goroutines, what is going on?
I ran the benchmark Continue reading
While I was writing the post comparing the new Qualcomm server chip, Centriq, to our current stock of Intel Skylake-based Xeons, I noticed a disturbing phenomena.
When benchmarking OpenSSL 1.1.1dev, I discovered that the performance of the cipher ChaCha20-Poly1305 does not scale very well. On a single thread, it performed at the speed of approximately 2.89GB/s, whereas on 24 cores, and 48 threads it performed at just over 35 GB/s.
 CC BY-SA 2.0 image by blumblaum
CC BY-SA 2.0 image by blumblaum
Now this is a very high number, but I would like to see something closer to 69GB/s. 35GB/s is just 1.46GB/s/core, or roughly 50% of the single core performance. AES-GCM scales much better, to 80% of single core performance, which is understandable, because the CPU can sustain higher frequency turbo on a single core, but not all cores.
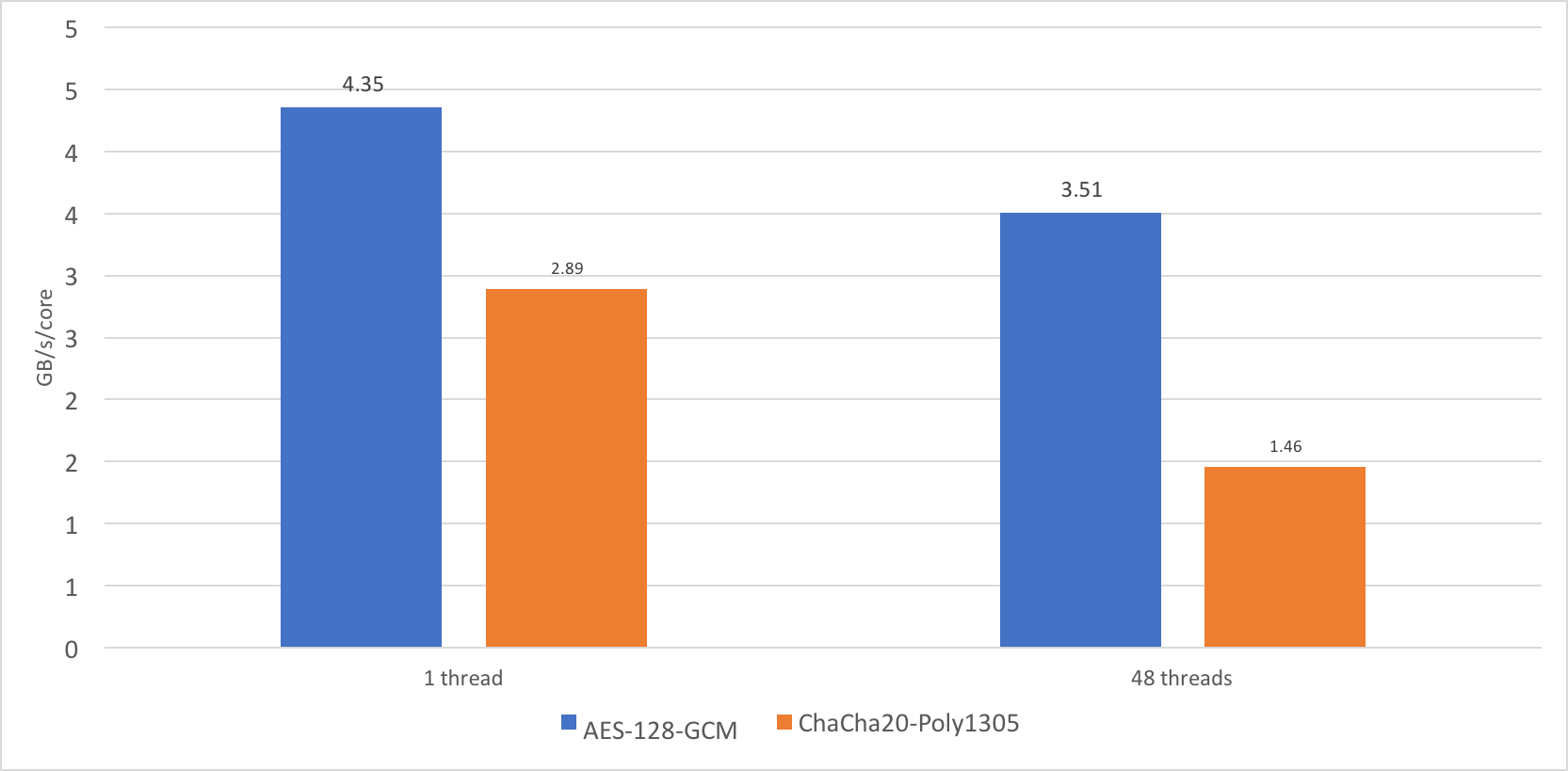
Why is the scaling of ChaCha20-Poly1305 so poor? Meet AVX-512. AVX-512 is a new Intel instruction set that adds many new 512-bit wide SIMD instructions and promotes most of the existing ones to 512-bit. The problem with such wide instructions is that they consume power. A lot of power. Imagine a single instruction that does the work of 64 regular Continue reading
One of the nicer perks I have here at Cloudflare is access to the latest hardware, long before it even reaches the market.
Until recently I mostly played with Intel hardware. For example Intel supplied us with an engineering sample of their Skylake based Purley platform back in August 2016, to give us time to evaluate it and optimize our software. As a former Intel Architect, who did a lot of work on Skylake (as well as Sandy Bridge, Ivy Bridge and Icelake), I really enjoy that.
Our previous generation of servers was based on the Intel Broadwell micro-architecture. Our configuration includes dual-socket Xeons E5-2630 v4, with 10 cores each, running at 2.2GHz, with a 3.1GHz turbo boost and hyper-threading enabled, for a total of 40 threads per server.
Since Intel was, and still is, the undisputed leader of the server CPU market with greater than 98% market share, our upgrade process until now was pretty straightforward: every year Intel releases a new generation of CPUs, and every year we buy them. In the process we usually get two extra cores per socket, and all the extra architectural features such upgrade brings: hardware AES and CLMUL in Westmere, Continue reading
A little over a year ago, Nick Sullivan talked about the beginning of the end for AES-CBC cipher suites, following a plethora of attacks on this cipher mode.
Today we can safely confirm that this prediction is coming true, as for the first time ever the share of AES-CBC cipher suites on Cloudflare’s edge network dropped below that of ChaCha20-Poly1305 suites, and is fast approaching the 10% mark.
Over the course of the last six months, AES-CBC shed more than 33% of its “market” share, dropping from 20% to just 13.4%.
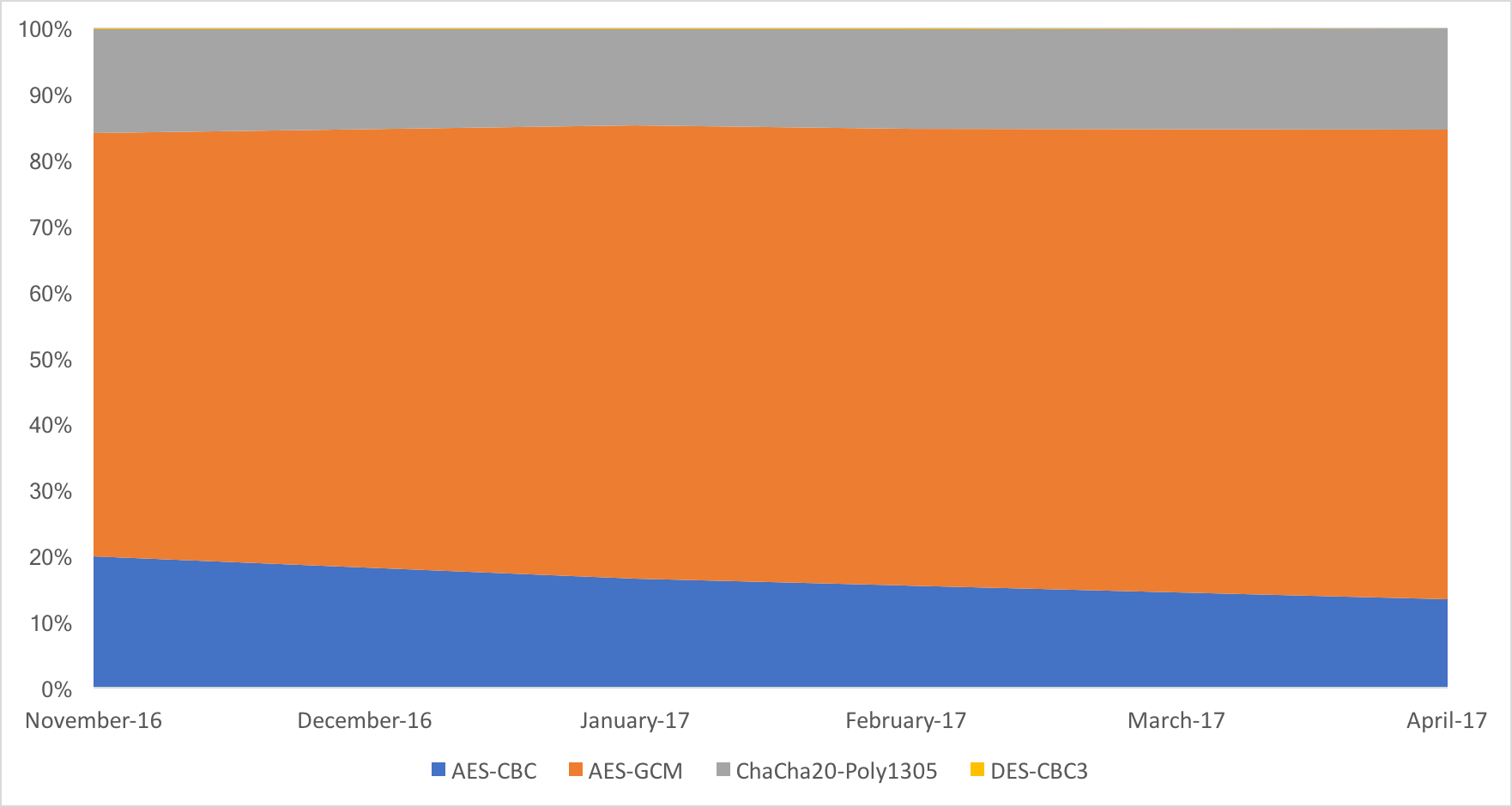
All of that share, went to AES-GCM, that currently encrypts over 71.2% of all connections. ChaCha20-Poly1305 is stable, with 15.3% of all connections opting for that cipher. Surprisingly 3DES is still around, with 0.1% of the connections.
The internal AES-CBC cipher suite breakdown as follows:
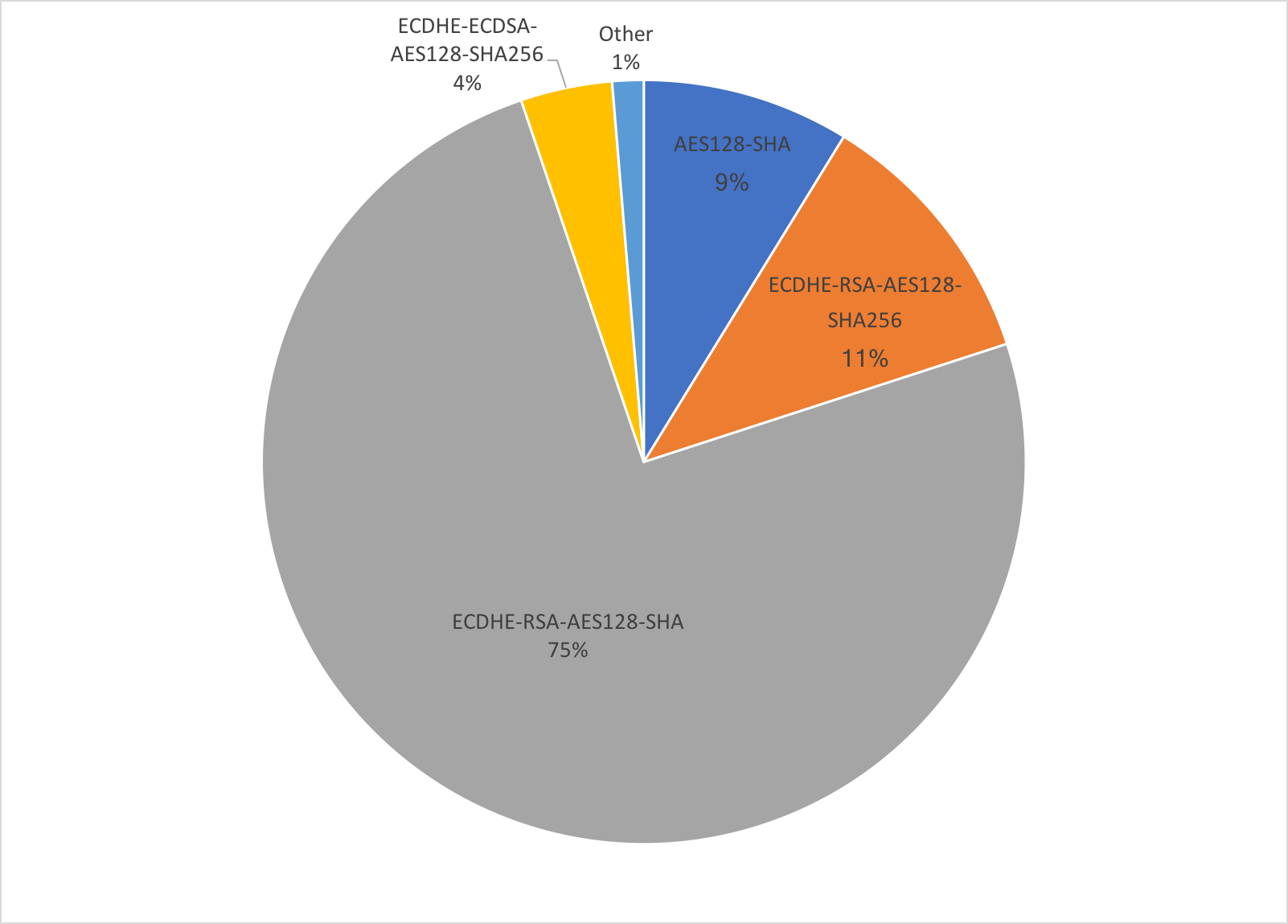
The majority of AES-CBC connections use ECDHE-RSA or RSA key exchange, and not ECDHE-ECDSA, which implies that we mostly deal with older clients.
In other good new, the use of ECDSA surpassed that of RSA at the beginning of the year. Currently more than 60% of all connections use Continue reading
If you have experienced HTTP/2 for yourself, you are probably aware of the visible performance gains possible with HTTP/2 due to features like stream multiplexing, explicit stream dependencies, and Server Push.
There is however one important feature that is not obvious to the eye. This is the HPACK header compression. Current implementations of Apache and nginx servers, as well edge networks and CDNs using them, do not support the full HPACK implementation. We have, however, implemented the full HPACK in nginx, and upstreamed the part that performs Huffman encoding.
 CC BY 2.0 image by Conor Lawless
CC BY 2.0 image by Conor Lawless
This blog post gives an overview of the reasons for the development of HPACK, and the hidden bandwidth and latency benefits it brings.
As you probably know, a regular HTTPS connection is in fact an overlay of several connections in the multi-layer model. The most basic connection you usually care about is the TCP connection (the transport layer), on top of that you have the TLS connection (mix of transport/application layers), and finally the HTTP connection (application layer).
In the the days of yore, HTTP compression was performed in the TLS layer, using gzip. Both headers and body were compressed indiscriminately, Continue reading
Last November, we rolled out HTTP/2 support for all our customers. At the time, HTTP/2 was not in wide use, but more than 88k of the Alexa 2 million websites are now HTTP/2-enabled. Today, more than 70% of sites that use HTTP/2 are served via CloudFlare.
 CC BY 2.0 image by Roger Price
CC BY 2.0 image by Roger Price
HTTP/2’s main benefit is multiplexing, which allows multiple HTTP requests to share a single TCP connection. This has a huge impact on performance compared to HTTP/1.1, but it’s nothing new—SPDY has been multiplexing TCP connections since at least 2012.
Some of the most important aspects of HTTP/2 have yet to be implemented by major web servers or edge networks. The real promise of HTTP/2 comes from brand new features like Header Compression and Server Push. Since February, we’ve been quietly testing and deploying HTTP/2 Header Compression, which resulted in an average 30% reduction in header size for all of our clients using HTTP/2. That's awesome. However, the real opportunity for a quantum leap in web performance comes from Server Push.
Today, we’re happy to announce HTTP/2 Server Push support for all of our customers. Server Push enables websites and Continue reading
Not long ago we introduced support for TLS cipher suites based on the ChaCha20-Poly1305 AEAD, for all our customers. Back then those cipher suites were only supported by the Chrome browser and Google's websites, but were in the process of standardization. We introduced these cipher suites to give end users on mobile devices the best possible performance and security.
 CC BY-ND 2.0 image by Edwin Lee
CC BY-ND 2.0 image by Edwin Lee
Today the standardization process is all but complete and implementations of the most recent specification of the cipher suites have begun to surface. Firefox and OpenSSL have both implemented the new cipher suites for upcoming versions, and Chrome updated its implementation as well.
We, as pioneers of ChaCha20-Poly1305 adoption on the web, also updated our open sourced patch for OpenSSL. It implements both the older "draft" version, to keep supporting millions of users of the existing versions of Chrome, and the newer "RFC" version that supports the upcoming browsers from day one.
In this blog entry I review the history of ChaCha20-Poly1305, its standardization process, as well as its importance for the future of the web. I will also take a peek at its performance, compared to the other standard AEAD.
Compression is one of the most important tools CloudFlare has to accelerate website performance. Compressed content takes less time to transfer, and consequently reduces load times. On expensive mobile data plans, compression even saves money for consumers. However, compression is not free—it comes at a price. It is one of the most compute expensive operations our servers perform, and the better the compression rate we want, the more effort we have to spend.
The most popular compression format on the web is gzip. We put a great deal of effort into improving the performance of the gzip compression, so we can perform compression on the fly with fewer CPU cycles. Recently a potential replacement for gzip, called Brotli, was announced by Google. Being early adopters for many technologies, we at CloudFlare want to see for ourselves if it is as good as claimed.
This post takes a look at a bit of history behind gzip and Brotli, followed by a performance comparison.
Many popular lossless compression algorithms rely on LZ77 and Huffman coding, so it’s important to have a basic understanding of these two techniques before getting into gzip or Brotli.
LZ77 is a simple technique developed Continue reading
It is no secret that at CloudFlare we put a great effort into accelerating our customers' websites. One way to do it is to reduce the size of the images on the website. This is what our Polish product is for. It takes various images and makes them smaller using open source tools, such as jpegtran, gifsicle and pngcrush.
However those tools are computationally expensive, and making them go faster, makes our servers go faster, and subsequently our customers' websites as well.
Recently, I noticed that we spent ten times as much time "polishing" jpeg images as we do when polishing pngs.
We already improved the performance of pngcrush by using our supercharged version of zlib. So it was time to look what can be done for jpegtran (part of the libjpeg distribution).
To get fast results I usually use the Linux perf utility. It gives a nice, if simple, view of the hotspots in the code. I used this image for my benchmark.
perf record ./jpegtran -outfile /dev/null -progressive -optimise -copy none test.jpeg
And we get:
perf report
54.90% lt-jpegtran libjpeg.so.9.1.0 [.] encode_mcu_AC_refine
Continue reading
Recently I was contacted by Dr. Igor Kozin from The Institute of Cancer Research in London. He asked about the optimal way to compile CloudFlare's open source fork of zlib. It turns out that zlib is widely used to compress the SAM/BAM files that are used for DNA sequencing. And it turns out our zlib fork is the best open source solution for that file format.
 CC BY-SA 2.0 image by Shaury Nash
CC BY-SA 2.0 image by Shaury Nash
The files used for this kind of research reach hundreds of gigabytes and every time they are compressed and decompressed with our library many important seconds are saved, bringing the cure for cancer that much closer. At least that's what I am going to tell myself when I go to bed.
This made me realize that the benefits of open source go much farther than one can imagine, and you never know where a piece of code may end up. Open sourcing makes sophisticated algorithms and software accessible to individuals and organizations that would not have the resources to develop them on their own, or the money pay for a proprietary solution.
It also made me wonder exactly what we did to zlib that makes it Continue reading
It is no secret that we at CloudFlare love Go. We use it, and we use it a LOT. There are many things to love about Go, but what I personally find appealing is the ability to write assembly code!
That is probably not the first thing that pops to your mind when you think of Go, but yes, it does allow you to write code "close to the metal" if you need the performance!
Another thing we do a lot in CloudFlare is... cryptography. To keep your data safe we encrypt everything. And everything in CloudFlare is a LOT.
Unfortunately the built-in cryptography libraries in Go do not perform nearly as well as state-of-the-art implementations such as OpenSSL. That is not acceptable at CloudFlare's scale, therefore we created assembly implementations of Elliptic Curves and AES-GCM for Go on the amd64 architecture, supporting the AES and CLMUL NI to bring performance up to par with the OpenSSL implementation we use for Universal SSL.
We have been using those improved implementations for a while, and attempting to make them part of the official Go build for the good of the community. For now Continue reading
A few years ago Google made a proposal for a new HTTP compression method, called SDCH (SanDwiCH). The idea behind the method is to create a dictionary of long strings that appear throughout many pages of the same domain (or popular search results). The compression is then simply searching for the appearance of the long strings in a dictionary and replacing them with references to the aforementioned dictionary. Afterwards the output is further compressed with DEFLATE.
 CC BY SA 2.0 image by Quinn Dombrowski
CC BY SA 2.0 image by Quinn Dombrowski
With the right dictionary for the right page the savings can be spectacular, even 70% smaller than gzip alone. In theory, a whole file can be replaced by a single token.
The drawbacks of the method are twofold: first - the dictionary that is created is fairly large and must be distributed as a separate file, in fact the dictionary is often larger than the individual pages it compresses; second - the dictionary is usually absolutely useless for another set of pages.
For large domains that are visited repeatedly the advantage is huge: at a cost of single dictionary download, all the following page views can be compressed with much higher efficiency. Currently we aware Continue reading
Vlad Krasnov recently joined CloudFlare to work on low level optimization of CloudFlare's servers. This is the first of a number of blog posts that will include code he's optimized and open sourced.
In a recent post, Kazuho's Weblog describes an improvement to PicoHTTPParser. This improvement utilizes the SSE4.2 instruction PCMPESTRI in order to find the delimiters in a HTTP request/response and parse them accordingly. This update, compared to the previous version of the code, is impressive.
 CC BY-SA 2.0 image by Intel Free Press
CC BY-SA 2.0 image by Intel Free Press
PCMPESTRI is a versatile instruction that allows scanning of up to 16 bytes at once for occurrences of up to 16 distinct characters (bytes), or up to 8 ranges of characters (bytes). It can also be used for string and substring comparison. However, there are a few drawbacks: the instruction has a high latency of 11 cycles, and is limited to 16 bytes per instruction. It's also under utilized for range comparison in PicoHTTPParser, because it only tests two or three ranges per invocation (out of eight it is capable of). Furthermore, some simple math (16 bytes / 11 cycles) shows that using this instruction limits the parser to 1.45 bytes/cycle throughput.



{kind=link}
.jpg){kind=link}