Orbital edge computing: nano satellite constellations as a new class of computer system
Orbital edge computing: nanosatellite constellations as a new class of computer system, Denby & Lucia, ASPLOS’20.
Last time out we looked at the real-world deployment of 5G networks and noted the affinity between 5G and edge computing. In true Crocodile Dundee style, Denby and Lucia are entitled to say “that’s not the edge, this is the edge!”. Today’s paper choice has it all: clusters of formation-flying autonomous nanosatellites working in tandem to overcome the physical limitations of space and the limited bandwidth to earth. The authors call this Orbital Edge Computing in contrast to the request-response style of satellite communications introduced with the previous generation of monolithic satellites. Only space system architects don’t call it request-response, they call it a ‘bent-pipe architecture.’
Momentum towards large constellations of nanosatellites requires a reimagining of space systems as distributed, edge-sensing and edge-computing systems.
Satellites are changing!
Satellites used to be large monolithic devices, e.g. the 500kg, $192M Earth Observing-1 (EO-1) satellite. Over the last couple of decades there’s been a big switch to /nanosatellite/ constellations. Nanosatellites are typically 10cm cubes (for the “CubeSat” standard), weigh just a few kilograms, and cost in the thousands of dollars.
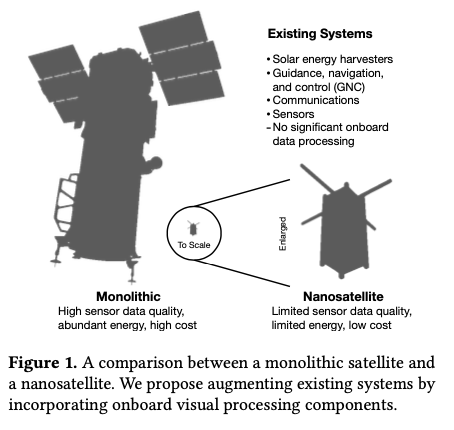
The CubeSat Continue reading
Understanding operational 5G: a first measurement study on its coverage, performance and energy consumption
Understanding operational 5G: a first measurement study on its coverage, performance and energy consumption, Xu et al., SIGCOMM’20
We are standing on the eve of the 5G era… 5G, as a monumental shift in cellular communication technology, holds tremendous potential for spurring innovations across many vertical industries, with its promised multi-Gbps speed, sub-10 ms low latency, and massive connectivity.
There are high hopes for 5G, for example unlocking new applications in UHD streaming and VR, and machine-to-machine communication in IoT. The first 5G networks are now deployed and operational. In today’s paper choice, the authors investigate whether 5G as deployed in practice can live up to the hype. The short answer is no. It’s a great analysis that taught me a lot about the realities of 5G, and the challenges ahead if we are to eventually get there.
The study is based on one of the world’s first commercial 5G network deployments (launched in April 2019), a 0.5 x 0.92 km university campus. As is expected to be common during the roll-out and transition phase of 5G, this network adopts the NSA (Non-Standalone Access) deployment model whereby the 5G radio is used for the data Continue reading
Toward an API for the real numbers
Towards an API for the real numbers, Boehm, PLDI’20
Last time out we saw that even in scientific computing applications built by experts, problems with floating point numbers are commonplace. The idiosyncrasies of floating point representations also show up in more everyday applications such as calculators and spreadsheets. Here the user-base is less inclined to be sympathetic:
If arithmetic computations and results are directly exposed to human users who are not floating point experts, floating point approximations tend to be viewed as bugs.
Hans-J. Boehm, author of today’s paper, should know, because he’s been involved in the development of the Android calculator app. That app is subject to “voluminous (public) user feedback”, and in the 2014 floating-point based calculator, bug reports relating to inaccurate results, unnecessary zeroes, and the like.
It’s a classic software development moment. The bug / feature request that looks just like any other ordinary issue on the outside, but takes you from straightforward implementation to research-level problem on the inside! In this case, the realisation that you can’t just use standard IEEE floating point operations anymore.
For calculators, spreadsheets, and many other applications we don’t need the raw performance of hardware floating point operations. But Continue reading
Spying on the floating point behavior of existing, unmodified scientific applications
Spying on the floating point behavior of existing, unmodified scientific applications Dinda et al., HPDC’20
It’s common knowledge that the IEEE standard floating point number representations used in modern computers have their quirks, for example not being able to accurately represent numbers such as 1/3, or 0.1. The wikipedia page on floating point numbers describes a number of related accuracy problems including the difficulty of testing for equality. In day-to-day usage, beyond judicious use of ‘within’ for equality testing, I suspect most of us ignore the potential difficulties of floating point arithmetic even if we shouldn’t. You’d like to think that scientific computing applications which heavily depend on floating point operations would do better than that, but the results in today’s paper choice give us reason to doubt.
…despite a superficial similarity, floating point arithmetic is not real number arithmetic, and the intuitive framework one might carry forward from real number arithmetic rarely applies. Furthermore, as hardware and compiler optimisations rapidly evolve, it is challenging even for a knowledgeable developer to keep up. In short, floating point and its implementations present sharp edges for its user, and the edges are getting sharper… recent research has determined that the Continue reading
Static Analysis of Java Enterprise Applications: Frameworks and Caches, the Elephants in the Room
Static analysis of Java enterprise applications: frameworks and caches, the elephants in the room, Antoniadis et al., PLDI’20
Static analysis is a key component of many quality and security analysis tools. Being static, it has the advantage that analysis results can be produced solely from source code without the need to execute the program. This means for example that it can be applied to analyse source code repositories and pull requests, be used as an additional test in CI pipelines, and even give assistance in your IDE if it’s fast enough.
Enterprise applications have (more than?) their fair share of quality and security issues, and execute in a commercial context where those come with financial and/or reputational risk. So they would definitely benefit from the kinds of reassurances that static analysis can bring. But there’s a problem:
Enterprise applications represent a major failure of applying programming languages research to the real world — a black eye of the research community. Essentially none of the published algorithms or successful research frameworks for program analysis achieve acceptable results for enterprise applications on the main quality axes of static analysis research: completeness, precision, and scalability.
If you try running Continue reading
Watchman: monitoring dependency conflicts for Python library ecosystem
Watchman: monitoring dependency conflicts for Python library ecosystem Wang et al., ICSE ‘20
There are more than 1.4M Python libraries in the PyPI repository. Figuring out which combinations of those work well together is not always easy. In fact, we have a phrase for navigating the maze of dependencies modern projects seem to accumulate: “dependency hell”. It’s often not the direct dependencies of your project that bite you, but the dependencies of your dependencies, all the way on down to transitive closure. In today’s paper from ICSE ‘20, Wang et al. study the prevalence of dependency conflicts in Python projects and their causes. Having demonstrated (not that many of us would need much convincing) that dependency conflicts are a real problem, they build and evaluate Watchman, a tool to quickly find and report dependency conflicts, and to predict dependency conflicts in the making. Jolly useful it looks too.
Welcome to dependency hell
If you have a set of versioned dependencies that all work together, you can create a lock file to pin those versions. But if you haven’t yet reached that happy place, or you need to upgrade, add or remove a dependency, you’ll be Continue reading
Aligning superhuman AI with human behaviour: chess as a model system
Aligning superhuman AI with human behavior: chess as a model system, McIlroy-Young et al., KDD’20
It’s been a while, but it’s time to start reading CS papers again! We’ll ease back into it with one or two papers a week for a few weeks, building back up to something like 3 papers a week at steady state.
How human-like is superhuman AI?
AI models can learn to perform some tasks to human or even super-human levels, but do they then perform those tasks in a human-like way? And does that even matter so long as the outcomes are good? If we’re going to hand everything over to AI and get out of the way, then maybe not. But where humans are still involved in task performance, supervision, or evaluation, then McIlroy-Young et al. make the case that this difference in approaches really does matter. Human-machine collaboration offers a lot of potential to enhance and augment human performance, but this requires the human and the machine to be ‘on the same page’ to be truly effective (see e.g. ‘Ten challenges for making automation a ‘team player’ in joint human-agent activity‘).
The central challenge in realizing these Continue reading
What’s happening with The Morning Paper?
I hope things have been going well for you during the various stages of covid-19 lockdowns. In the UK where I am things are just starting to ease, although it looks like I’ll still be working remotely for a considerable time to come.
Lockdown so far has been bittersweet for me. Two deaths in my extended family, neither covid related, but both with funerals impacted, and one life-threatening incident in my immediate family (all ok now thank goodness, but it was very stressful at the time!). At the same time it’s been a wonderful opportunity to spend more quality time with my family and I’m grateful for that.
Covid-19, the lack of in-person schooling for children, and fully remote working have interrupted my routines just like they have for many others. I’ve still been studying pretty hard (it’s almost a form of relaxation and retreat for me), but in a different subject area. My current intention is to pick up The Morning Paper again for the new academic term, starting in September. I’ll no doubt have a huge backlog of interesting papers to look at by then – if you’ve encountered any on your travels that you think I Continue reading
An early end of term
The last few weeks have been anything but normal for many of us. I do hope that you and your loved ones are managing to stay safe. My routines have been disrupted too, and with the closure of schools last week it’s essentially the Easter holidays one week earlier than expected for my children. At the moment my priority is to help any family, friends, and neighbours in need. So I’m pressing pause on The Morning Paper for a few weeks and calling an early ‘end of term’ there too.
It’s hard to know exactly what’s going to happen, but my expectation is that you’ll see somewhat more sporadic posting in a few weeks time – or maybe even more posting than usual if I’m locked indoors for weeks on end!!
Until then, my thoughts are with you – stay safe!
Adrian.
In case you missed it…
A few selections from the term so far:
Serverless in the wild: characterizing and optimising the serverless workload at a large cloud provider
Serverless in the wild: characterizing and optimising the serverless workload at a large cloud provider, Shahrad et al., arXiv 2020
This is a fresh-from-the-arXivs paper that Jonathan Mace (@mpi_jcmace) drew my attention to on Twitter last week, thank you Jonathan!
It’s a classic trade-off: the quality of service offered (better service presumably driving more volume at the same cost point), vs the cost to provide that service. It’s a trade-off at least, so long as a classic assumption holds, that a higher quality product costs more to produce/provide. This assumption seems to be deeply ingrained in many of us – explaining for example why higher cost goods are often implicitly associated with higher quality. Every once in a while though a point in the design space can be discovered where we don’t have to trade-off quality and cost, where we can have both a higher quality product and a lower unit cost.
Today’s paper analyses serverless workloads on Azure (the characterisation of those workloads is interesting in its own right), where users want fast function start times (avoiding cold starts), and the cloud provider wants to minimise resources consumed (costs). With fine-grained, usage based billing, resources used to Continue reading
An empirical guide to the behavior and use of scalable persistent memory
An empirical guide to the behavior and use of scalable persistent memory, Yang et al., FAST’20
We’ve looked at multiple papers exploring non-volatile main memory and its implications (e.g. most recently ‘Efficient lock-free durable sets‘). One thing they all had in common is an evaluation using some kind of simulation of the expected behaviour of NVDIMMs, because the real thing wasn’t yet available. But now it is! This paper examines the real-world behaviour of Intel’s Optane DIMM, and finds that not all of the assumptions baked into prior works hold. Based on these findings, the authors present four guidelines to get the best performance out of this memory today. Absolutely fascinating if you like this kind of thing!
The data we have collected demonstrate that many of the assumptions that researchers have made about how NVDIMMs would behave and perform are incorrect. The widely expressed expectation was that NVDIMMs would have behavior that was broadly similiar to DRAM-based DIMMs but with lower performance (i.e., higher latency and lower bandwidth)… We have found the actual behavior of Optane DIMMs to be more complicated and nuanced than the "slower, persistent DRAM" label would suggest.
Optane Continue reading
Understanding, detecting and localizing partial failures in large system software
Understanding, detecting and localizing partial failures in large system software, Lou et al., NSDI’20
Partial failures (gray failures) occur when some but not all of the functionalities of a system are broken. On the surface everything can appear to be fine, but under the covers things may be going astray.
When a partial failure occurs, it often takes a long time to detect the incident. In contrast, a process suffering a total failure can be quickly identified, restarted, or repaired by existing mechanisms, thus limiting the failure impact.
Because everything can look fine on the surface, traditional failure detectors or watchdogs using external probes or monitoring statistics may not be able to pick up on the problem. Today’s paper choice won the authors a best paper award at NSDI’20. It contains a study of partial failure causes, and a novel approach to fault detection using system-specific, auto-generated watchdogs.
Characterising partial failures
Before designing a better system for detecting partial failures, the authors set about understanding their nature and causes through a study of five software systems (ZooKeeper, Cassandra, HDFS, Apache, and Mesos). For each of these systems they crawled the bug databases to find critical issues Continue reading
When correlation (or lack of it) can be causation
Rex: preventing bugs and misconfiguration in large services using correlated change analysis, Mehta et al., NSDI’20
and
Check before you change: preventing correlated failures in service updates, Zhai et al., NSDI’20
Today’s post is a double header. I’ve chosen two papers from NSDI’20 that are both about correlation. Rex is a tool widely deployed across Microsoft that checks for correlations you don’t have but probably should have: it looks at files changed in commits and warns developers if files frequently changed with them have not been changed. CloudCanary on the other hand is about detecting correlations you do have, but probably don’t want: it looks for potential causes of correlated failures across a system, and can make targeted recommendations for improving your system reliability.
Improving system reliability through correlation
"If you change the foo setting, don’t forget that you also need to update all the clients…"
Large-scale services run on a foundation of very large codebases and configuration repositories. To run uninterrupted a service not only depends on correct code, but also on correct network and security configuration, and suitable deployment specification. This causes various dependencies both within and across components/sources of the service which emerge Continue reading
Characterizing, modeling, and benchmarking RocksDB key-value workloads at Facebook
Characterizing, modeling, and benchmarking RocksDB key-value workloads at Facebook, Cao et al., FAST’20
You get good at what you practice. Or in the case of key-value stores, what you benchmark. So if you want to design a system that will offer good real-world performance, it’s really useful to have benchmarks that accurately represent real-world workloads. In this paper, Facebook analyse three of their real-world RocksDB workloads and find (surprise!) that they all look quite different. More interesting, is that there are important differences between the way these real-world workloads behave, and workloads generated by the venerable YCSB benchmark.
Therefore, using the benchmarking results of YCSB as guidance for production might cause some misleading results… To address this issue, we propose a key-range based modelling and develop a benchmark that can better emulate the workloads of real-world key-value stores. This benchmark can synthetically generate more precise key-value queries that represent the reads and writes of key-value stores to the underlying storage system.
The tracing, replay, and analysis tools developed for this work are released in open source as part of the latest RocksDB release, and the new benchmark is now part of the db_bench benchmarking tool.
TL;DR Continue reading
Building an elastic query engine on disaggregated storage
Building an elastic query engine on disaggregated storage, Vuppalapati, NSDI’20
This paper describes the design decisions behind the Snowflake cloud-based data warehouse. As the saying goes, ‘all snowflakes are special’ – but what is it exactly that’s special about this one?
When I think about cloud-native architectures, I think about disaggregation (enabling each resource type to scale independently), fine-grained units of resource allocation (enabling rapid response to changing workload demands, i.e. elasticity), and isolation (keeping tenants apart). Through a study of customer workloads it is revealed that Snowflake scores well on these fronts at a high level, but once you zoom in there are challenges remaining.
This paper presents Snowflake design and implementation along with a discussion on how recent changes in cloud infrastructure (emerging hardware, fine-grained billing, etc.) have altered the many assumptions that guided the design and optimization of the Snowflake system.
From shared-nothing to disaggregation
Traditional data warehouse systems are largely based on shared-nothing designs: persistent data is partitioned across a set of nodes, each responsible for its local data. Analysed from the perspective of cloud-native design this presents a number of issues:
- CPU, memory, storage, and bandwidth resources are all aggregated at each Continue reading
Millions of tiny databases
Millions of tiny databases, Brooker et al., NSDI’20
This paper is a real joy to read. It takes you through the thinking processes and engineering practices behind the design of a key part of the control plane for AWS Elastic Block Storage (EBS): the Physalia database that stores configuration information.
In the same spirit as Paxos Made Live, this paper describes the details, choices and tradeoffs that are required to put a consensus system into production.
The core algorithms (chain-replication, Paxos-based consensus) aren’t the stars of the show here, instead the paper focuses on how these algorithms are deployed, and the software engineering practices behind the creation of a mission-critical production system employing them.
A guiding principle
Engineering decisions involve making lots of trade-offs. If you want to emerge with a coherent design, then it’s well worth spending some time thinking about the principle(s) by which you’re going to make them. For Physalia, and for AWS more generally, the guiding principle is minimise the blast radius.
Over the decade since [the introduction of Availability Zones], our thinking on failure and availability has continued to evolve, and we paid increasing attention to blast radius and correlation of failure. Continue reading
Firecracker: lightweight virtualization for serverless applications
Firecracker: lightweight virtualisation for serverless applications, Agache et al., NSDI’20
Finally the NSDI’20 papers have opened up to the public (as of last week), and what a great looking crop of papers it is. We looked at a couple of papers that had pre-prints available last week, today we’ll be looking at one of the most anticipated papers of this year’s crop: Amazon’s Firecracker.
Firecracker is the virtual machine monitor (VMM) that powers AWS Lambda and AWS Fargate, and has been used in production at AWS since 2018. Firecracker is open source, and there are a number of projects that make it easy to work with outside of the AWS environment too, including Weave Firekube (disclaimer: Accel is an investor in Weaveworks). Firekube exists because none of the existing alternatives (virtualisation, containers or language-specific vms) met the combined needs of multi-tenant efficiency and strong isolation in the AWS environment.
The traditional view is that there is a choice between virtualization with strong security and high overhead, and container technologies with weaker security and minimal overhead. This tradeoff is unacceptable to public infrastructure providers, who need both strong security and minimal overhead.
Approaches to isolation
The first version of Continue reading
Gandalf: an intelligent, end-to-end analytics service for safe deployment in cloud-scale infrastructure
Gandalf: an intelligent, end-to-end analytics service for safe deployment in cloud-scale infrastructure, Li et al., NSDI’20
Modern software systems at scale are incredibly complex ever changing environments. Despite all the pre-deployment testing you might employ, this makes it really tough to change them with confidence. Thus it’s common to use some form of phased rollout, monitoring progress as you go, with the idea of rolling back a change if it looks like it’s causing problems. So far so good, but observing a problem and then connecting it back to a given deployment can be far from straightforward. This paper describes Gandalf, the software deployment monitor in production at Microsoft Azure for the past eighteen months plus. Gandalf analyses more than 20TB of data per day : 270K platform events on average (770K peak), 600 million API calls, with data on over 2,000 different fault types. If Gandalf doesn’t like what that data is telling it, it will pause a rollout and send an alert to the development team.
Since its introduction, Gandalf has significantly improved deployment times, cutting them in half across the entire production fleet. As teams gained more experience with Gandalf, and saw how it was Continue reading
Meaningful availability
Meaningful availability, Hauer et al., NSDI’20
With thanks to Damien Mathieu for the recommendation.
This very clearly written paper describes the Google G Suite team’s search for a meaningful availability metric: one that accurately reflected what their end users experienced, and that could be used by engineers to pinpoint issues and guide improvements.
> A good availability metric should be meaningful, proportional, and actionable. By "meaningful" we mean that it should capture what users experience. By "proportional" we mean that a change in the metric should be proportional to the change in user-perceived availability. By "actionable" we mean that the metric should give system owners insight into why availability for a period was low. This paper shows that none of the commonly used metrics satisfy these requirements…
The alternative that Google settled on is called windowed user-uptime and it’s been used in production across all of G Suite for the past year. We’ll look at how windowed user-uptime works in a moment, but first let’s review commonly used approaches to availability reporting and why they failed Google’s test.
Counting nines
The basic form of an availability metric is the ratio of ‘good’ service to the total demanded service: Continue reading
AnyLog: a grand unification of the Internet of things
AnyLog: a grand unification of the Internet of Things, Abadi et al., CIDR’20
The Web provides decentralised publishing and direct access to unstructured data (searching / querying that data has turned out to be a pretty centralised affair in practice though). AnyLog wants to do for structured (relational) data what the Web has done for unstructured data, with coordinators playing the role of search engines. A key challenge for a web of structured data is that it’s harder to see how it can be supported by advertising, so AnyLog needs a different incentive scheme. This comes in the form of micropayments. Micropayments require an environment of trust, and in a decentralised context that leads us to blockchains.
There have been several efforts to create a version of the WWW for "structured" data, such as the Semantic Web and Freebase. Our approach differs substantially by (1) providing economic incentives for data to be contributed and integrated into existing schemas, (2) offering a SQL interface instead of graph based approaches, (3) including the computational and storage infrastructure in the architectural vision.
Note that AnyLog also differs from projects such as DeepDive or Google’s Knowledge Graph. These aim at extracting Continue reading