Author Archives: Ivan Pepelnjak
Author Archives: Ivan Pepelnjak
In January 2018 Rodney Brooks made a series of long-term predictions about self-driving cars, robotics, AI, ML, and space travel. Not surprisingly, his predictions were curmudgeonly and pessimistic when compared to the daily hype (or I wouldn’t be blogging about it)… but guess who was right ;)
He’s also the only predictor I’m aware of who is not afraid to compare what he wrote with how reality turned out years down the line. On January 1st he published the 2021 edition of the predictions scorecard and so far he hasn’t been too pessimistic yet. Keep that in mind the next time you’ll be listening to your favorite $vendor droning about the wonders of AI/ML.
In January 2018 Rodney Brooks made a series of long-term predictions about self-driving cars, robotics, AI, ML, and space travel. Not surprisingly, his predictions were curmudgeonly and pessimistic when compared to the daily hype (or I wouldn’t be blogging about it)… but guess who was right ;)
He’s also the only predictor I’m aware of who is not afraid to compare what he wrote with how reality turned out years down the line. On January 1st he published the 2021 edition of the predictions scorecard and so far he hasn’t been too pessimistic yet. Keep that in mind the next time you’ll be listening to your favorite $vendor droning about the wonders of AI/ML.
Right after Cisco SD-WAN devices are onboarded, how are the control and data plane tasks started? In this section, David Penaloza covers how Cisco SD-WAN solution makes the most of its SDN nature: single point of policy application and centralized management platform. The types of policies, the plane on which they act, their application and the actions that can performed are the main focus in this part of the series.
Right after Cisco SD-WAN devices are onboarded, how are the control and data plane tasks started? In this section, David Penaloza covers how Cisco SD-WAN solution makes the most of its SDN nature: single point of policy application and centralized management platform. The types of policies, the plane on which they act, their application and the actions that can performed are the main focus in this part of the series.
This is a guest blog post by Matthias Luft, Principal Platform Security Engineer @ Salesforce, and a regular ipSpace.net guest speaker.
A couple of months ago I had the pleasure to publish my first guest post here and, as to be expected from ipspace.net, it triggered some great discussion.
With this input and some open thoughts from the last post, I want to dive into a few more topics.
One trigger for the initial post was the question whether host-based firewalls (HBFs), potentially combined with solutions to learn rulesets based on flows, are intrinsically better than central firewalls. While we discussed the mileage around that already, comments and questions emphasized how often we have to handle a “software engineering vs. network engineering” mentality – which should not involve any blame in either direction as this mindset is usually enforced by organizational structures.
For whatever it is worth, I can only stress the point that a strong collaboration between software and network engineering will resolve way more issues than any technology. I award myself a “Thanks, Captain Obvious” here, but I still want to make the point to try Continue reading
This is a guest blog post by Matthias Luft, Principal Platform Security Engineer @ Salesforce, and a regular ipSpace.net guest speaker.
A couple of months ago I had the pleasure to publish my first guest post here and, as to be expected from ipspace.net, it triggered some great discussion.
With this input and some open thoughts from the last post, I want to dive into a few more topics.
TL&DR: If you run multiple IGP protocols in your network, and add BGP on top of that, you might get the results you deserve. Even better, the results are platform-dependent.
One of my readers sent me a link to an interesting scenario described by Jeremy Filliben that results in totally unexpected behavior when using too many routing protocols in your network (no surprise there).
Imagine a network in which two edge routers advertise the same (external) BGP prefix. All other things being equal, it would make sense that other routers in the same autonomous system should use the better path out of the autonomous system. Welcome to the final tie-breaker in BGP route selection process: IGP metric.
TL&DR: If you run multiple IGP protocols in your network, and add BGP on top of that, you might get the results you deserve. Even better, the results are platform-dependent.
One of my readers sent me a link to an interesting scenario described by Jeremy Filliben that results in totally unexpected behavior when using too many routing protocols in your network (no surprise there).
Imagine a network in which two edge routers advertise the same (external) BGP prefix. All other things being equal, it would make sense that other routers in the same autonomous system should use the better path out of the autonomous system. Welcome to the final tie-breaker in BGP route selection process: IGP metric.
Long story short: ipSpace.net is going on an extended coffee break on June 24th 2021. You can stop reading; the rest of the blog post is full of details you probably don’t care about.
What exactly does that mean? Honestly, we don’t know yet… but we felt that it’s only fair to let engineers considering our subscriptions know months in advance what might happen.
Also, after investing two lifetimes into this project, and a few planned changes coming just before our regular summer hiatus (see below) it’s time for a longer break. ipSpace.net might be back to business-as-usual after a few months (unlikely), or it could be Ivan working on some interesting stuff (most likely) or ipSpace.net slowly disappearing into the sunset (not impossible).
Long story short: ipSpace.net is going on an extended coffee break on June 24th 2021 reducing the scope of activities on July 1st 2021. You can stop reading; the rest of the blog post is full of details you probably don’t care about.
What exactly does that mean? Since this blog post was published in January 2021, we pretty much figured out a way forward, and I’m glad we let engineers considering our subscriptions know months in advance what might happen.
Anyway, after investing two lifetimes into this project, and a few planned changes coming just before our regular summer hiatus (see below) it’s time for a longer break an adjustment. ipSpace.net will revert back to Ivan working on some interesting stuff.
We had the usual gloomy December weather during the end-of-year holidays, and together with the partial lockdown (with confusing ever-changing rules only someone in Balkans could dream up) it managed to put me in OCD mood… and so I decided to remove broken links from the old blog posts.
While doing that I figured out how fragile our industry is – I encountered a graveyard of ideas and products that would make Google proud. Some of those blog posts were removed, I left others intact because they still have some technical merits, and I made sure to write sarcastic update notices on product-focused ones. Consider those comments Easter eggs… now go and find them ;))
Anyway, I also salvaged some of the old content I was stupid enough to publish somewhere else from archive.org. Here it is:
We had the usual gloomy December weather during the end-of-year holidays, and together with the partial lockdown (with confusing ever-changing rules only someone in Balkans could dream up) it managed to put me in OCD mood… and so I decided to remove broken links from the old blog posts.
While doing that I figured out how fragile our industry is – I encountered a graveyard of ideas and products that would make Google proud. Some of those blog posts were removed, I left others intact because they still have some technical merits, and I made sure to write sarcastic update notices on product-focused ones. Consider those comments Easter eggs… now go and find them ;))
As always, it’s time to shut down our virtual office and disappear until early January… unless of course you have an urgent support problem. Any paperwork ideas your purchasing department might have will have to wait until 2021.
I hope you’ll be able to disconnect from the crazy pace of networking world, forget all the unicorns and rainbows (and broccoli forest of despair), and focus on your loved ones – they need you more than the dusty router sitting in a remote office. We would also like to wish you all the best in 2021!
As always, it’s time to shut down our virtual office and disappear until early January… unless of course you have an urgent support problem. Any paperwork ideas your purchasing department might have will have to wait until 2021.
I hope you’ll be able to disconnect from the crazy pace of networking world, forget all the unicorns and rainbows (and broccoli forest of despair), and focus on your loved ones – they need you more than the dusty router sitting in a remote office. We would also like to wish you all the best in 2021!
Imagine the following network running OSPF as the routing protocol. PE1–P1–PE2 is the primary path and PE1–P2–PE2 is the backup path. What happens on PE1 when the PE1–P1 link fails? What happens on PE2?
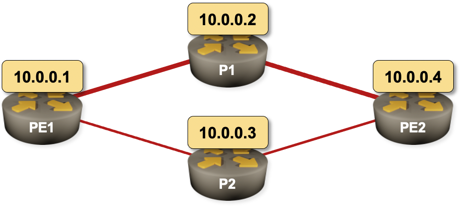
Sample 4-router network with a primary and a backup path
The second question is much easier to answer, and the answer is totally unambiguous as it only involves OSPF:
Imagine the following network running OSPF as the routing protocol. PE1–P1–PE2 is the primary path and PE1–P2–PE2 is the backup path. What happens on PE1 when the PE1–P1 link fails? What happens on PE2?
Sample 4-router network with a primary and a backup path
The second question is much easier to answer, and the answer is totally unambiguous as it only involves OSPF:
Deciding to create AWS Networking and Azure Networking webinars wasn’t easy – after all, there’s so much content out there covering all aspects of public cloud services, and a plethora of certification trainings (including free training from AWS).
Having that in mind, it’s so nice to hear from people who found our AWS webinar useful ;)
Even though we are working with these technologies and have the certifications, there are always nuggets of information in these webinars that make it totally worthwhile. A good example in this series was the ingress routing feature updates in AWS.
It can be hard to filter through the noise from cloud providers to get to the new features that actually make a difference to what we are doing. This series does exactly that for me. Brilliant as always.
AWS Networking and Azure Networking webinars are available with Standard ipSpace.net Subscription. For even deeper dive into cloud networking check out our Networking in Public Cloud Deployments online course.
Deciding to create AWS Networking and Azure Networking webinars wasn’t easy – after all, there’s so much content out there covering all aspects of public cloud services, and a plethora of certification trainings (including free training from AWS).
Having that in mind, it’s so nice to hear from people who found our AWS webinar useful ;)
Even though we are working with these technologies and have the certifications, there are always nuggets of information in these webinars that make it totally worthwhile. A good example in this series was the ingress routing feature updates in AWS.
It can be hard to filter through the noise from cloud providers to get to the new features that actually make a difference to what we are doing. This series does exactly that for me. Brilliant as always.
Other engineers use our webinars to prepare for AWS certifications – read this blog post by Jedadiah Casey for more details.
AWS Networking and Azure Networking webinars are available with Standard ipSpace.net Subscription. For even deeper dive into cloud networking check out our Networking in Public Cloud Deployments online course.
Yesterday I wrote a frustrated tweet after wasting an hour trying to figure out why a combination of OSPF and IS-IS routing worked on Cisco IOS but not on Nexus OS. Having to wait for a minute (after Vagrant told me SSH on Nexus 9300v was ready) for NX-OS to “boot” its Ethernet module did’t improve my mood either, and the inconsistencies in NX-OS interface naming (Ethernet1/1 is uppercase while loopback0 and mgmt0 are lowercase) were just the cherry on top of the pile of ****. Anyway, here’s what I wrote:
Can’t tell you how much I hate Ansible’s lame attempts to do idempotent device configuration changes. Wasted an hour trying to figure out what’s wrong with my Nexus OS config… only to find out that “interface X” cannot appear twice in the configuration you want to push.
Not unexpectedly, I got a few (polite and diplomatic) replies from engineers who felt addressed by that tweet, so it’s only fair to document exactly what made me so angry.
Yesterday I wrote a frustrated tweet after wasting an hour trying to figure out why a combination of OSPF and IS-IS routing worked on Cisco IOS but not on Nexus OS. Having to wait for a minute (after Vagrant told me SSH on Nexus 9300v was ready) for NX-OS to “boot” its Ethernet module did’t improve my mood either, and the inconsistencies in NX-OS interface naming (Ethernet1/1 is uppercase while loopback0 and mgmt0 are lowercase) were just the cherry on top of the pile of ****. Anyway, here’s what I wrote:
Can’t tell you how much I hate Ansible’s lame attempts to do idempotent device configuration changes. Wasted an hour trying to figure out what’s wrong with my Nexus OS config… only to find out that “interface X” cannot appear twice in the configuration you want to push.
Not unexpectedly, I got a few (polite and diplomatic) replies from engineers who felt addressed by that tweet, and less enthusiastic response from the product manager (no surprise there), so it’s only fair to document exactly what made me so angry.
Update 2020-12-23: In the meantime, Ganesh Nalawade already implemented a fix that solves my problem. Thanks you, awesome job!