Author Archives: Ivan Pepelnjak
Author Archives: Ivan Pepelnjak
When looking for the latest SR Linux container image, I noticed images with -arm-preview tags and wondered whether they would run on Apple Silicon.
TL&DR: YES, IT WORKS 🎉 🎉
Here’s what you have to do to make SR Linux work with netlab running on a Ubuntu VM on Apple silicon:
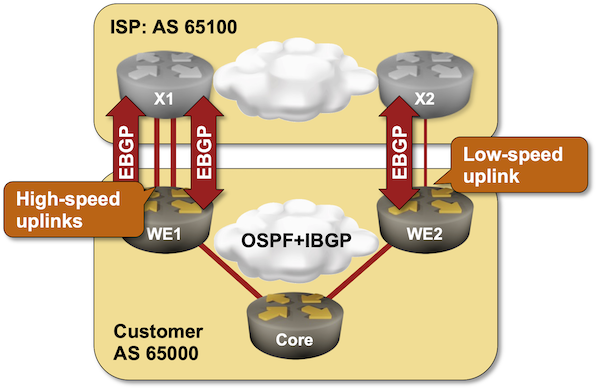
All our previous designs of the hub-and-spoke VPN (single PE, EVPN) used two VRFs for the hub device (ingress VRF and egress VRF). Is it possible to build a one-arm hub-and-spoke VPN where the hub device exchanges traffic with the PE router over a single link?
TL&DR: Yes, but only on some devices (for example, Cisco IOS or FRRouting) when using MPLS transport.
Here’s a high-level diagram of what we’d like to achieve:
In the previous BGP load balancing lab exercise, I described the BGP Link Bandwidth attribute and how you can use it on EBGP sessions. This lab moves the unequal-cost load balancing into your network; we’ll use the BGP Link Bandwidth attribute on IBGP sessions.
Retirement obviously does not sit well with my friend Tiziano Tofoni; the English version of his IPv6 book just came out.
It is a bit sad, though, that we still need “how to use IPv6” books when the protocol is old enough to enjoy a nice glass of whiskey (in the US) trying to drown its sorrow at its slow adoption.
In early August, I published step-by-step instructions for a lab you can use to explore how to implement pure L3VPN with an EVPN control plane.
A previous blog post described how you can use the netlab report functionality to generate addressing, wiring, BGP, and OSPF reports from a running lab. But what could you do if you need a report that doesn’t exist yet? It’s straightforward to define one (what else did you expect?).
Let’s create the report I used in the EVPN Hub-and-Spoke Layer-3 VPN blog post to create the VRF table.
Now that we figured out how to implement a hub-and-spoke VPN design on a single PE-router, let’s do the same thing with EVPN. It turns out to be trivial:
As we want to use EVPN and have a larger core network, we’ll also have to enable VLANs, VXLAN, BGP, and OSPF on the PE devices.
This is the topology of our expanded lab:
Yesterday’s blog post discussed the traffic flow and the routing information flow in a hub-and-spoke VPN design (a design in which all traffic between spokes flows through the hub site). It’s time to implement and test it, starting with the simplest possible scenario: a single PE router using inter-VRF route leaking to connect the VRFs.
Hub-and-spoke topology is by far the most complex topology I’ve ever encountered in the MPLS/VPN (and now EVPN) world. It’s used when you want to push all the traffic between sites attached to a VPN (spokes) through a central site (hub), for example, when using a central firewall.

You get the following diagram when you model the traffic flow requirements with VRFs. The forward traffic uses light yellow arrows, and the return traffic uses dark orange ones.
A quick reminder in case you were on vacation in late July: I published a short guide to creating netlab reports. Hope you’ll find it useful.
A year after I started the open-source BGP configuration labs project, I was persuaded to do something similar for IS-IS. The first labs are already online (with plenty of additional ideas already in the queue), and you can run them on any device for which we implemented IS-IS support in netlab.
Want an easy start? Use GitHub Codespaces. Have a laptop with Apple Silicon? We have you covered ;)
I’ll talk about the BGP labs and the magic behind the scenes that ensures the lab configurations are correct at the SINOG 8 meeting later today (selecting the English version of the website is counter-intuitive; choose English from the drop-down field on the right-hand side of the page).
The SINOG 8 presentations will be live-streamed; I should start around 13:15 Central European Time (11:15 GMT; figuring out the local time is left as an exercise for the reader).

In May 2024, I made public the first half of the Network Connectivity and Graph Theory videos by Rachel Traylor.
Now, you can also enjoy the second part of the webinar without a valid ipSpace.net account; it describes trees, spanning trees, and the Spanning Tree Protocol. Enjoy!
Did you know that some vendors use the ancient MPLS/VPN (RFC 4364) control plane when implementing L3VPN with SRv6?
That’s just one of the unexpected tidbits I discovered when explaining why you can’t compare BGP, EVPN, and SRv6.
In the previous blog posts, we explored the simplest possible IBGP-based EVPN design and tried to figure out whether BGP route reflectors do more harm than good. Ignoring that tiny detail for the moment, let’s see how we could add route reflectors to our leaf-and-spine fabric.
As before, this is the fabric we’re working with:
Ages ago, I described how “traditional” network operating systems used the BGP Routing Information Base (BGP RIB), the system routing table (RIB), and the forwarding table (FIB). Here’s the TL&DR:
Béla Várkonyi wrote a succinct comment explaining why so many customers prefer layer-2 VPNs over layer-3 VPNs:
The reason of L2VPN is becoming more popular by service providers and customers is about provisioning complexity.
Nick Buraglio and Brian E. Carpenter published a free, open-source IPv6 textbook.
The book seems to be in an early (ever-evolving) stage, but it’s well worth exploring if you’re new to the IPv6 world, and you might consider contributing if you’re a seasoned old-timer.
It would also be nice to have a few online labs to go with it ;)
Urs Baumann loves hands-on teaching and created tons of lab exercises to support his Infrastructure-as-Code automation course.
During the summer, he published some of them in a collection of GitHub repositories and made them work in GitHub Codespaces. An amazing idea well worth exploring!
After discovering that some EVPN implementations support multiple transit VNI values in a single VRF, I had to check whether I could implement a common services L3VPN with EVPN.
TL&DR: It works (on Arista cEOS)1.
Here are the relevant parts of a netlab lab topology I used in my test (you can find the complete lab topology in netlab-examples GitHub repository):