Author Archives: Ivan Pepelnjak
Author Archives: Ivan Pepelnjak

What do you get when you write code next to a Christmas tree? You can expect to get tons of eye candy, and that’s what netlab release 1.7.1 is all about.
It all started with a cleanup idea: I could replace the internal ASCII table-drawing code with the prettytable library. Stefan was quick to point out that I should be looking at the rich library, and the rest is history:
What do you get when you write code next to a Christmas tree? You can expect to get tons of eye candy, and that’s what netlab release 1.7.1 is all about.
It all started with a cleanup idea: I could replace the internal ASCII table-drawing code with the prettytable library. Stefan was quick to point out that I should be looking at the rich library, and the rest is history:
I published dozens of free-to-download slide decks on ipSpace.net. Downloading them required the free ipSpace.net subscription which is no longer available because I refuse to play a whack-a-mole game with spammers.
You might like the workaround I had to implement to keep those PDFs accessible: they are no longer behind a regwall.
You can find the list of all the free content ipSpace.net content here. The Conferences and Presentations page is another source of links to public presentations.
I published dozens of free-to-download slide decks on ipSpace.net. Downloading them required the free ipSpace.net subscription which is no longer available because I refuse to play a whack-a-mole game with spammers.
You might like the workaround I had to implement to keep those PDFs accessible: they are no longer behind a regwall.
You can find the list of all the free content ipSpace.net content here. The Conferences and Presentations page is another source of links to public presentations.
When I published the Bidirectional Route Redistribution lab exercise, some readers were quick to point out that you’ll probably have to reuse the same AS number across multiple sites in a real-life MPLS/VPN deployment. That’s what you can practice in today’s lab exercise – an MPLS/VPN service provider allocated the same BGP AS number to all your sites and expects you to deal with the aftermath.
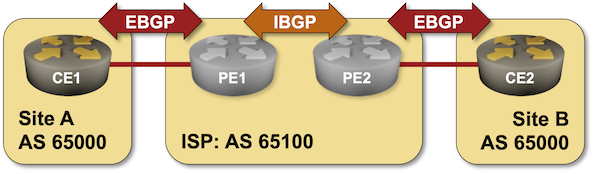
When I published the Bidirectional Route Redistribution lab exercise, some readers were quick to point out that you’ll probably have to reuse the same AS number across multiple sites in a real-life MPLS/VPN deployment. That’s what you can practice in today’s lab exercise – an MPLS/VPN service provider allocated the same BGP AS number to all your sites and expects you to deal with the aftermath.
This LinkedIn snippet just came in from the someone is not exactly right on the Internet department:
Unlike IGP protocols, BGP is not dependent on a single type of metric to choose the best path.
EIGRP is an immediate counterexample that brought the above quote to my attention, but it’s worth exploring the topic in more detail.
This LinkedIn snippet just came in from the someone is not exactly right on the Internet department:
Unlike IGP protocols, BGP is not dependent on a single type of metric to choose the best path.
EIGRP is an immediate counterexample that brought the above quote to my attention, but it’s worth exploring the topic in more detail.
One of the delightful side effects of leaving the paid content business is that I no longer have to try to persuade anyone that my content is any good. That includes the “this video is now public” announcements – instead of elaborate introductions, I’ll just publish a short blog post with the links.
As of today, these videos (along with dozens of previously-released videos) from the Routing Protocols section of the How Networks Really Work webinar are no longer behind a login wall:
It’s that time of the year when we create unreachable goals and make empty promises to ourselves (or others) that we subconsciously know we’ll fail.
I tried to make that process a bit more structured and create external storage for my lab ideas – I started publishing more details on future BGP lab scenarios. The lab descriptions contain a high-level overview of the challenge and the lab topology; the details will be filled in later.
Want to know what’s coming in 2024? Check out the Upcoming Labs page of the BGP Labs project.
It’s that time of the year when we create unreachable goals and make empty promises to ourselves (or others) that we subconsciously know we’ll fail.
I tried to make that process a bit more structured and create external storage for my lab ideas – I started publishing more details on future BGP lab scenarios. The lab descriptions contain a high-level overview of the challenge and the lab topology; the details will be filled in later.
Want to know what’s coming in 2024? Check out the Upcoming Labs page of the BGP Labs project.
I got this request from someone who just missed the opportunity to buy the ipSpace.net subscription (or so he claims) earlier today
I am inspired to learn AWS advanced networking concepts and came across your website and webinar resources. But I cannot access it.
That is not exactly true. I wrote more than 4000 blog posts in the past, and some of them dealt with public cloud networking. There are also the free videos, some of them addressing public cloud networking.
I got this request from someone who just missed the opportunity to buy the ipSpace.net subscription (or so he claims) earlier today
I am inspired to learn AWS advanced networking concepts and came across your website and webinar resources. But I cannot access it.
That is not exactly true. I wrote more than 4000 blog posts in the past, and some of them dealt with public cloud networking. There are also the free videos, some of them addressing public cloud networking.
I ran the first webinar as an independent author almost exactly fourteen years ago1, with the first ticket sold just before New Year’s Eve. I kept focusing on individual webinars until someone asked me, “Would it be possible to buy access to everything you did?” His question effectively created the ipSpace.net subscription, with the first one sold in late 2010 (I still have the email that triggered the whole process).
I ran the first webinar as an independent author almost exactly fourteen years ago1, with the first ticket sold just before New Year’s Eve. I kept focusing on individual webinars until someone asked me, “Would it be possible to buy access to everything you did?” His question effectively created the ipSpace.net subscription, with the first one sold in late 2010 (I still have the email that triggered the whole process).
My video editor sent me the perfect let’s-wrap-up-this-year video:
I wish you a few quiet days disconnected from the technology and all the best in 2024!
After procrastinating for months, I finally spent a few days cleaning up and organizing OSPF blog posts (it turns out I wrote almost 100 blog posts on the topic in the 18 years of blogging).
After procrastinating for months, I finally spent a few days cleaning up and organizing OSPF blog posts (it turns out I wrote almost 100 blog posts on the topic in the 18 years of blogging).
In the Path Failure Detection on Multi-Homed Servers blog post, I mentioned running BGP on servers as one of the best ways to detect server-to-network failures. As always, things aren’t as simple as they look, as Cathal Mooney quickly pointed out:
One annoyance is what IP address gets used by default by the system for outbound traffic. It would be nice to have a generic OS-level way to say, “This IP on lo0 should be default for outbound IP traffic unless to the connected link subnet itself.”
That’s definitely a tough nut to crack, and Cathal described a few solutions he used in the past:
In the Path Failure Detection on Multi-Homed Servers blog post, I mentioned running BGP on servers as one of the best ways to detect server-to-network failures. As always, things aren’t as simple as they look, as Cathal Mooney quickly pointed out:
One annoyance is what IP address gets used by default by the system for outbound traffic. It would be nice to have a generic OS-level way to say, “This IP on lo0 should be default for outbound IP traffic unless to the connected link subnet itself.”
That’s definitely a tough nut to crack, and Cathal described a few solutions he used in the past: