Author Archives: Matt Silverlock
Author Archives: Matt Silverlock
We’re not burying the lede on this one: you can now connect Cloudflare Workers to your PlanetScale databases directly and ship full-stack applications backed by Postgres or MySQL.

We’ve teamed up with PlanetScale because we wanted to partner with a database provider that we could confidently recommend to our users: one that shares our obsession with performance, reliability and developer experience. These are all critical factors for any development team building a serious application.
Now, when connecting to PlanetScale databases, your connections are automatically configured for optimal performance with Hyperdrive, ensuring that you have the fastest access from your Workers to your databases, regardless of where your Workers are running.
As Workers has matured into a full-stack platform, we’ve introduced more options to facilitate your connectivity to data. With Workers KV, we made it easy to store configuration and cache unstructured data on the edge. With D1 and Durable Objects, we made it possible to build multi-tenant apps with simple, isolated SQL databases. And with Hyperdrive, we made connecting to external databases fast and scalable from Workers.
Today, we’re introducing a new choice for building on Cloudflare: Postgres and MySQL PlanetScale databases, directly Continue reading
Multiple Cloudflare services, including our R2 object storage, were unavailable for 59 minutes on Thursday, February 6, 2025. This caused all operations against R2 to fail for the duration of the incident, and caused a number of other Cloudflare services that depend on R2 — including Stream, Images, Cache Reserve, Vectorize and Log Delivery — to suffer significant failures.
The incident occurred due to human error and insufficient validation safeguards during a routine abuse remediation for a report about a phishing site hosted on R2. The action taken on the complaint resulted in an advanced product disablement action on the site that led to disabling the production R2 Gateway service responsible for the R2 API.
Critically, this incident did not result in the loss or corruption of any data stored on R2.
We’re deeply sorry for this incident: this was a failure of a number of controls, and we are prioritizing work to implement additional system-level controls related not only to our abuse processing systems, but so that we continue to reduce the blast radius of any system- or human- action that could result in disabling any production service at Cloudflare.

Data is fundamental to any real-world application: the database storing your user data and inventory, the analytics tracking sales events and/or error rates, the object storage with your web assets and/or the Parquet files driving your data science team, and the vector database enabling semantic search or AI-powered recommendations for your users.
When we first announced Workers back in 2017, and then Workers KV, Cloudflare R2, and D1, it was obvious that the next big challenge to solve for developers would be in making it easier to ingest, store, and query the data needed to build scalable, full-stack applications.
To that end, as part of our quest to make building stateful, distributed-by-default applications even easier, we’re launching our new Event Notifications service; a preview of our upcoming streaming ingestion product, Pipelines; and a sneak peek into our take on durable execution, Workflows.
When you’re writing data — whether that’s new data, changing existing data, or deleting old data — you often want to trigger other, asynchronous work to run in response. That could be processing user-driven uploads, updating search indexes as the underlying data changes, or removing associated rows in your SQL database when Continue reading

Multiple Cloudflare services were unavailable for 37 minutes on October 30, 2023. This was due to the misconfiguration of a deployment tool used by Workers KV. This was a frustrating incident, made more difficult by Cloudflare’s reliance on our own suite of products. We are deeply sorry for the impact it had on customers. What follows is a discussion of what went wrong, how the incident was resolved, and the work we are undertaking to ensure it does not happen again.
Workers KV is our globally distributed key-value store. It is used by both customers and Cloudflare teams alike to manage configuration data, routing lookups, static asset bundles, authentication tokens, and other data that needs low-latency access.
During this incident, KV returned what it believed was a valid HTTP 401 (Unauthorized) status code instead of the requested key-value pair(s) due to a bug in a new deployment tool used by KV.
These errors manifested differently for each product depending on how KV is used by each service, with their impact detailed below.
A number of Cloudflare services depend on Workers KV for distributing configuration, routing information, static asset serving, and authentication state globally. These services instead received Continue reading


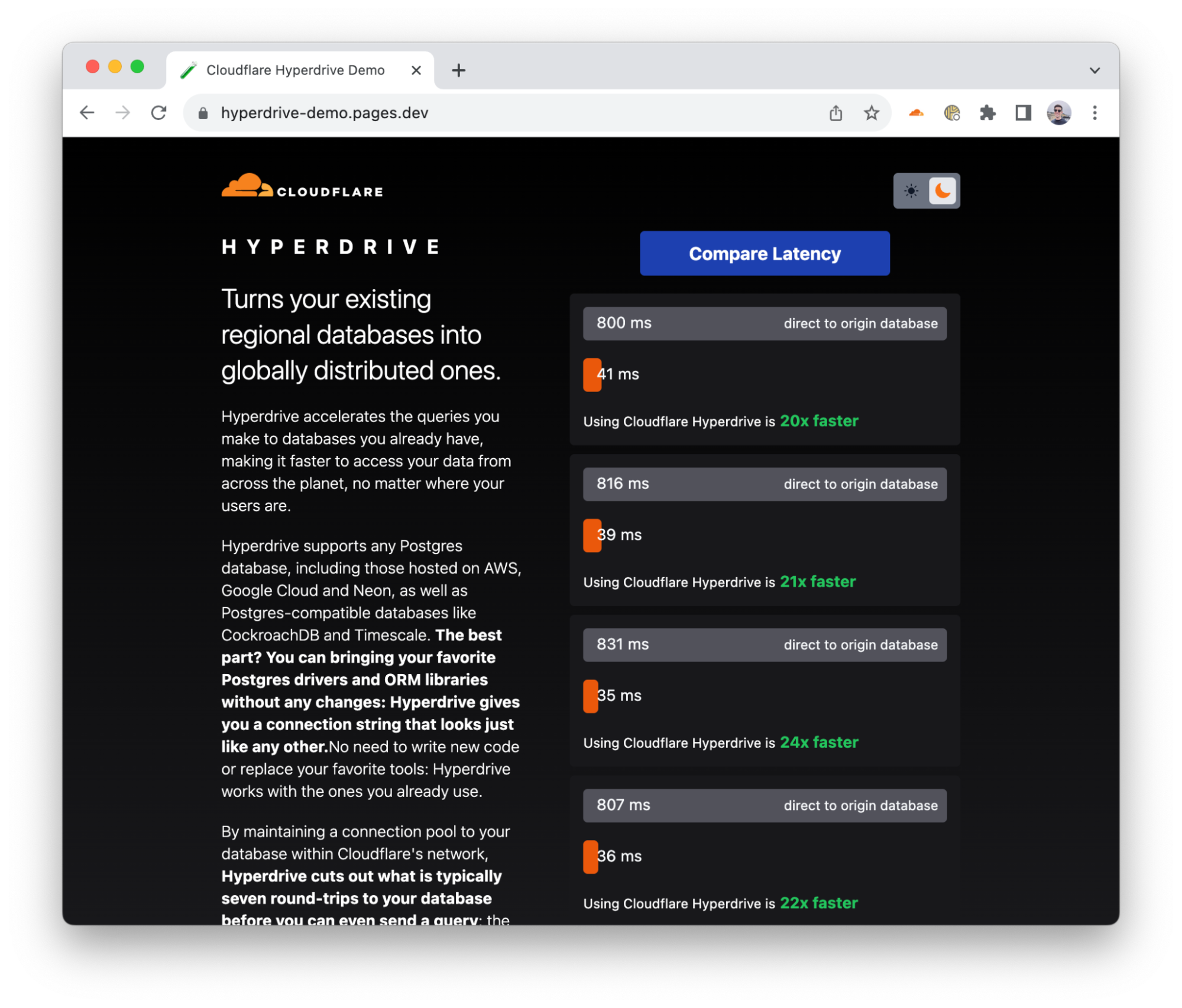
Hyperdrive makes accessing your existing databases from Cloudflare Workers, wherever they are running, hyper fast. You connect Hyperdrive to your database, change one line of code to connect through Hyperdrive, and voilà: connections and queries get faster (and spoiler: you can use it today).
In a nutshell, Hyperdrive uses our global network to speed up queries to your existing databases, whether they’re in a legacy cloud provider or with your favorite serverless database provider; dramatically reduces the latency incurred from repeatedly setting up new database connections; and caches the most popular read queries against your database, often avoiding the need to go back to your database at all.
Without Hyperdrive, that core database — the one with your user profiles, product inventory, or running your critical web app — sitting in the us-east1 region of a legacy cloud provider is going to be really slow to access for users in Paris, Singapore and Dubai and slower than it should be for users in Los Angeles or Vancouver. With each round trip taking up to 200ms, it’s easy to burn up to a second (or more!) on the multiple round-trips needed just to set up a connection, before you’ve Continue reading
Hyperdrive vous permet d'accéder très rapidement à vos bases de données existantes à partir de Cloudflare Workers, quel que soit leur lieu d'exécution. Il vous suffit de connecter Hyperdrive à votre base de données, de modifier une ligne de code pour vous connecter via Hyperdrive, et voilà : les connexions et les requêtes sont accélérées (et spoiler : vous pouvez l'utiliser dès aujourd'hui).
En un mot, Hyperdrive s'appuie sur notre réseau mondial pour accélérer les requêtes vers vos bases de données existantes, qu'elles se situent chez un fournisseur de cloud traditionnel ou chez votre fournisseur de base de données serverless préféré. La solution réduit considérablement la latence induite par l'établissement répété de nouvelles connexions avec la base de données. En outre, elle met en cache les requêtes de lecture les plus populaires adressées à votre base de données, une opération qui évite souvent d'avoir à s'adresser à nouveau à votre base de données.
Sans Hyperdrive, l'accès à votre base de données principale (celle qui contient les profils de vos utilisateurs, votre stock de produits ou qui exécute votre application web essentielle) hébergée dans la région us-east1 d'un fournisseur de cloud traditionnel se révèlera très lent pour les utilisateurs situés Continue reading
Hyperdrive macht den Zugriff auf Ihre bestehenden Datenbanken von Cloudflare Workers aus hyperschnell, egal wo sie laufen. Sie verbinden Hyperdrive mit Ihrer Datenbank, ändern eine Codezeile, um eine Verbindung über Hyperdrive herzustellen, und voilà: Verbindungen und Abfragen werden schneller (und Spoiler: Sie können es schon heute nutzen).
Kurz gesagt: Hyperdrive nutzt unser globales Netzwerk, um Abfragen an Ihre bestehenden Datenbanken zu beschleunigen, unabhängig davon, ob sich diese bei einem alten Cloud-Provider oder bei Ihrem bevorzugten Provider für Serverless-Datenbanken befinden. Die Latenz, die durch das wiederholte Einrichten neuer Datenbankverbindungen entsteht, wird drastisch reduziert, und die beliebtesten Leseabfragen an Ihre Datenbank werden zwischengespeichert, sodass Sie oft gar nicht mehr zu Ihrer Datenbank zurückkehren müssen.
Wenn Ihre Kerndatenbank – mit Ihren Nutzerprofilen, Ihrem Produktbestand oder Ihrer wichtigen Web-App – in der us-east1-Region eines veralteten Cloud-Anbieters angesiedelt ist, wird der Zugriff für Nutzende in Paris, Singapur und Dubai ohne Hyperdrive sehr langsam sein und selbst für Nutzende in Los Angeles oder Vancouver langsamer, als er sein sollte. Da jeder Roundtrip bis zu 200 ms dauert, können die mehrfachen Roundtrips, die allein für den Verbindungsaufbau erforderlich sind, leicht bis zu einer Sekunde (oder mehr!) in Anspruch nehmen; und das, bevor Sie überhaupt eine Continue reading
Hyperdrive te permite un acceso ultrarrápido a tus bases de datos existentes desde Cloudflare Workers, dondequiera que se ejecuten. Conectas Hyperdrive a tu base de datos, modificas una línea de código para conectarte a través de Hyperdrive, y listo: las conexiones y las consultas son más rápidas (spoiler: puedes utilizarlo hoy mismo).
En pocas palabras, Hyperdrive utiliza nuestra red global para acelerar las consultas a tus bases de datos existentes, tanto si se encuentran en un proveedor de nube heredado como en tu proveedor favorito de bases de datos sin servidor; reduce drásticamente la latencia que implica configurar repetidamente nuevas conexiones a la base de datos; y almacena en caché las consultas de lectura a tu base de datos más populares, lo que a menudo evita incluso la necesidad de volver a tu base de datos.
Sin Hyperdrive, esa base de datos principal (la que contiene tus perfiles de usuario, tu inventario de productos o que ejecuta tus aplicaciones web críticas), ubicada en la región us-east1 de tu proveedor de nube heredado, ofrecerá un acceso muy lento a los usuarios en París, Singapur y Dubái, y más lento de lo que debería ser para los usuarios en Los Ángeles Continue reading
Hyperdriveは、実行されている場所を問わず、Cloudflare Workersから既存のデータベースへのアクセスを超高速にします。Hyperdriveをデータベースに接続し、Hyperdriveを経由して接続するようにコードを1行変更するだけで、接続とクエリーが高速化されます(秘密:本日から 使えます ) 。
一言で言えば、Hyperdriveは当社のグローバルネットワークを使用して、レガシーなクラウドプロバイダーであろうとお気に入りのサーバーレスデータベースプロバイダーであろうと、既存のデータベースへのクエリーを高速化し、新しいデータベース接続を繰り返し設定することで発生する遅延を劇的に短縮し、データベースに対して最も一般的な読取りクエリーをキャッシュします。これにより、データベースに戻る必要がなくなります。
Hyperdriveがなければ、レガシークラウドプロバイダーのus-east1リージョンにあるコアデータベース(ユーザープロファイル、製品在庫、または重要なWebアプリを実行しているデータベース)へのアクセスは、パリ、シンガポール、ドバイのユーザーにとっては非常に遅くなり、ロサンゼルスやバンクーバーのユーザーにとっては必要以上に遅くなります。各ラウンドトリップに最大200msかかるため、データのクエリーを行う前に、接続をセットアップするためだけに何度もラウンドトリップすることになり、1秒(またはそれ以上)も費やしてしまうことになります。Hyperdrive はこれを解決するために設計されています。
Hyperdriveのパフォーマンスを実証するため、 Hyperdriveを使用した場合とHyperdriveを使用しない場合(直接)の両方で、同じデータベースに対して連続してクエリーを実行するデモアプリケーションを作成しました。このアプリケーションは、近隣の大陸のデータベースを選択します。ヨーロッパにいる場合は米国のデータベースを選択します。これは、多くのヨーロッパのインターネットユーザーにとって非常に一般的です。アフリカにいる場合はヨーロッパのデータベースを選択します(以下同様)。このクエリーは、厳選された平均値や厳選された指標を使用せず、単純な`SELECT`クエリーから生の結果を返します。
社内テスト、初期ユーザーレポート、およびベンチマークでの複数回の実行を通じて、Hyperdriveは、キャッシュされたクエリーではデータベースに直接アクセスする場合と比較して17~25倍、キャッシュされていないクエリーおよび書き込みでは6~8倍のパフォーマンス向上を実現しています。キャッシュされた遅延は驚くことではないかもしれませんが、キャッシュされていないクエリーで6~8倍速くなることは、お客様のご意見を「Cloudflare Workersから集中管理されたデータベースにクエリーできない」を「非常に有用な機能だ!」に変えると私たちは考えています。また、パフォーマンスの改善にも引き続き取り組んでいます。すでに、さらなる遅延の低減を確認しており、今後数週間のうちに、その低減分を推進していく予定です。
一番の魅力は?Workersの有料プランにお申込みいただいている開発者は、すぐにHyperdriveオープンベータを使い始めることができます。待機リストや専用の登録フォームへの登録は不要です。
私たちはしばらくの間、Hyperdriveに秘密裏に取り組んできました。ですが、開発者がすでに持っているデータベース(既存のデータ、クエリー、ツール)に接続できるようにすることは、かなり以前から考えていたことでした。
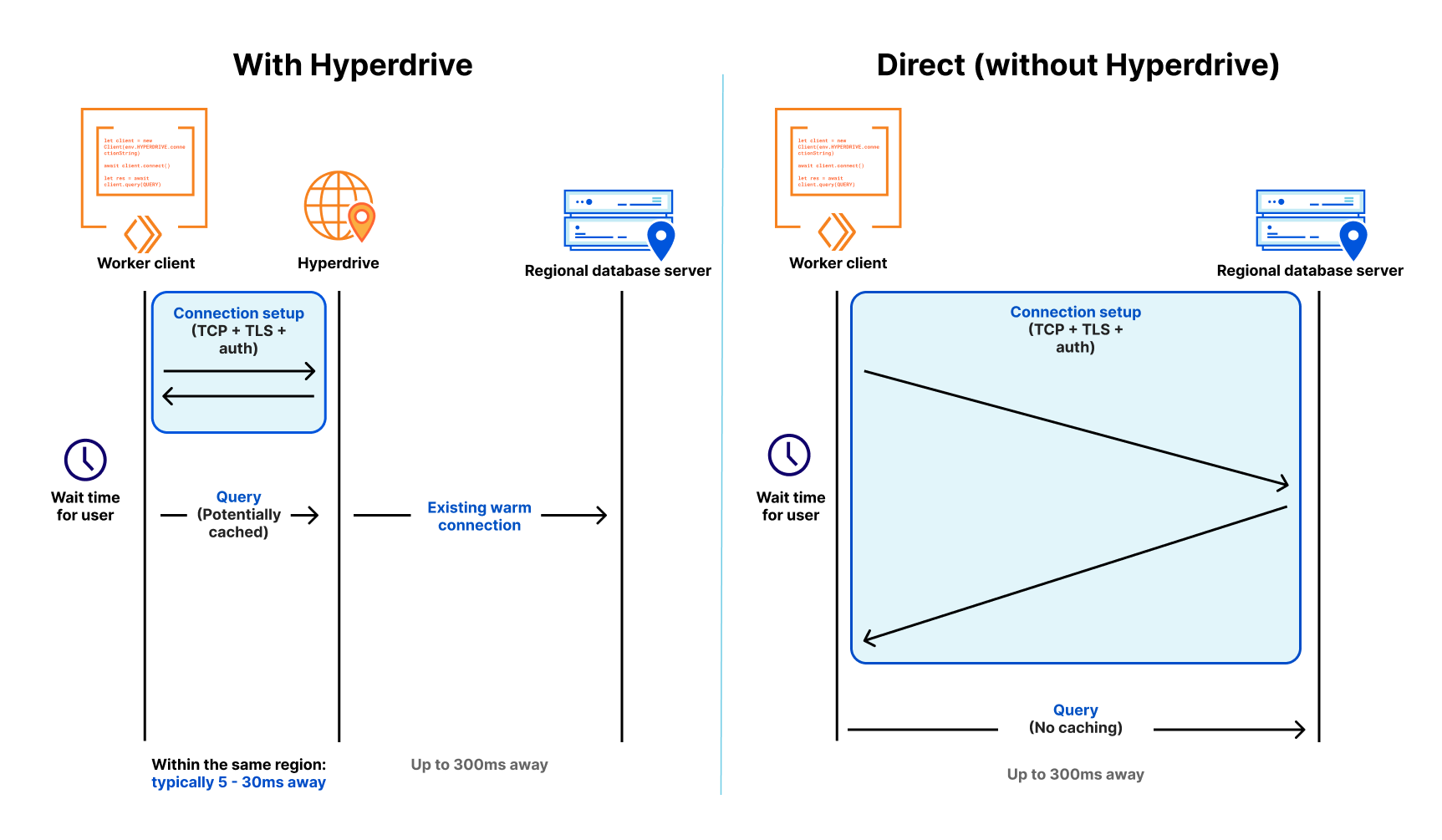
Workersのような最新の分散型クラウド環境では、コンピューティングはグローバルに分散され(そのためユーザーの近くにある)、関数は短時間で終了する(そのため必要以上の課金はされない)ため、従来のデータベースへの接続は遅くて拡張性がありませんでした。遅いというのは、接続を確立するのに7往復(TCPハンドシェイク、TLSネゴシエーション、認証)以上かかるためであり、拡張性がないというのは、PostgreSQLのようなデータベースは接続あたりのリソースコストが高いためです。データベースへの数百の接続でさえ、クエリーに必要なメモリとは別に、無視できないメモリを消費します。
Neon(人気のあるサーバーレスPostgresプロバイダー)の友人たちはこのことについて書いており、接続のオーバーヘッドを減らすためのWebSocketプロキシとドライバまでリリースしていますが、それでもまだ力戦奮闘しています。カスタムドライバを使うと4往復まで減らすことができますが、それでもそれぞれに50~200ミリ秒以上かかる可能性があります。これらの接続が長寿命であれば、それは問題ありません。しかし、接続が個々の関数呼び出しにスコープ化され、せいぜい数ミリ秒から数分しか役に立たない場合、コードはより多くの待ち時間を費やすことになります。これは事実上、別の種類のコールドスタートです。クエリーを実行する前にデータベースへの新しい接続を開始する必要があるため、分散環境やサーバーレス環境で従来のデータベースを使用するのは(控えめに言っても)本当に遅いのです。
これに対抗するため、Hyperdriveは2つのことを行います。
第一に、Cloudflare WorkerはCloudflareのネットワーク全体にわたる地域データベース接続プールのセットを維持するので、リクエストごとにデータベースへの新規接続を行う必要がありません。その代わりに、WorkerはHyperdriveへの接続を(高速で)確立し、Hyperdriveはデータベースへの接続プールを維持します。データベースは1回のラウンドトリップで30msから300msとなることがあるため (新しい接続に必要な7回以上の接続は別として)、利用可能な接続のプールを持つことで、短時間の接続が被る遅延の問題を劇的に減らすことができます。
第二に、読み取り(non-mutating)クエリーと書き込み(mutating)クエリーとトランザクションの違いを理解し、最もよく使われる読み取りクエリーを自動的にキャッシュすることができます。このクエリーは、一般的なWebアプリのデータベースに対して行われるクエリーの80%以上を占めます。何万人ものユーザーが毎時間訪れる商品一覧ページ、大手求人サイトの求人情報、あるいは時折変更される設定データに対するクエリーなど、クエリーされる内容の膨大な部分は頻繁に変更されるものではないため、ユーザーがクエリーを実行する場所の近くにキャッシュすることで、次の1万人のユーザーのデータへのアクセスを劇的に高速化することができます。安全にキャッシュすることができない書き込みクエリーは、Hyperdriveの接続プールとCloudflareのグローバルネットワークの両方から恩恵を受けることができます。つまり、バックボーンを介してインターネット上で最も早い経路をとることができれば、そこでの待ち時間も短縮できるのです。
Hyperdriveは、Neon、GoogleクラウドSQL、AWS RDS、 TimescaleなどのPostgreSQLデータベースだけでなく、 Materialize(強力なストリーム処理データベース)、CockroachDB(主要な分散データベース)、GoogleクラウドのAlloyDB、AWS Aurora PostgresなどのPostgreSQL互換データベースでも動作します。
また、PlanetScaleのようなプロバイダーも含め、MySQLのサポートを年内に実現するよう取り組んでおり、将来的にはさらに多くのデータベースエンジンをサポートする予定です。
Hyperdriveの主要な設計目標の1つは、開発者が既存のドライバ、クエリービルダー、ORM(Object-Relational Mapper)ライブラリを使い続ける必要性でした。Hyperdriveのパフォーマンスの恩恵を受けるために、お気に入りのORMからの移行や、数百行(またはそれ以上)のコードの書き換えが必要であれば、Hyperdriveがどれほど高速であるかは重要ではなかったでしょう。
これを達成するために、私たちはnode-postgresやPostgres.jsを含む人気のあるオープンソースドライバのメンテナーと協力し、標準化プロセスを経ているWorkerの新しいTCPソケットAPIをライブラリがサポートできるように支援しました。そして、Node.js、Deno、Bunに対するサポートも拡充予定です。
地味なデータベース接続文字列は、データベースドライバの共有言語であり、通常、次の形式をとります。
postgres://user:[email protected]:5432/postgres
Hyperdriveの魔法は、接続文字列をHyperdriveが生成するものに置き換えるだけで、既存のWorkersアプリで、既存のクエリーで、Hyperdriveを使い始めることができるということです。
既存のデータベース(この例では、NeonのPostgresデータベースを使用)が準備できていれば、Hyperdriveを起動させるのに1分もかかりません(実際、時間を計測しました)。
既存のCloudflare Workersプロジェクトがない場合は、すぐに作成できます。
$ npm create cloudflare@latest
# Call the application "hyperdrive-demo"
# Choose "Hello World Worker" as your template
ここからは、データベースの接続文字列と、 Hyperdriveに接続させるための簡単な Wrangler コマンドライン 呼び出しが必要です。
# Using wrangler v3.10.0 or above
wrangler hyperdrive create a-faster-database --connection-string="postgres://user:[email protected]:5432/neondb"
# This will return an ID: we'll use this in the next step
Workerのwrangler.toml構成ファイルにHyperdriveを追加:
[[hyperdrive]]
name = "HYPERDRIVE"
id = "cdb28782-0dfc-4aca-a445-a2c318fb26fd"
これで、Workerを書く、あるいは既存のWorkerスクリプトを利用し、Hyperdriveを使って既存のデータベースへの接続とクエリーを高速化することができます。ここで、node-postgresを使用していますが、単純にDrizzle ORMを使うこともできます。
import { Client } from 'pg';
export interface Env {
HYPERDRIVE: Hyperdrive;
}
export default {
async fetch(request: Request, env: Env, ctx: ExecutionContext) {
console.log(JSON.stringify(env));
// Create a database client that connects to our database via Hyperdrive
//
// Hyperdrive generates a unique connection string you Continue readingHyperdrive는 어디에서 실행되는 Cloudflare Workers에서 기존 데이터베이스에 액세스하는 것을 매우 빠르게 만듭니다. Hyperdrive를 데이터베이스와 연결하고 Hyperdrive로 연결하기 위해 단 한 줄의 코드를 바꾸면 연결과 쿼리가 마법처럼 빨라집니다(오늘 바로 사용할 수 있습니다).
요약하자면, Hyperdrive는 Cloudflare의 전역 네트워크를 사용하므로 기존 데이터베이스에 대한 쿼리 속도가 단축됩니다. 데이터베이스가 레거시 클라우드 공급자에 있든, 여러분이 좋아하는 서버리스 데이터베이스 공급자에 있든 구애받지 않습니다. Hyperdrive를 사용하면 반복적으로 새로운 데이터베이스 연결을 설정할 때 발생하는 대기 시간이 대폭 단축되고, 데이터베이스에 대한 가장 인기 있는 읽기 쿼리가 캐시되어 데이터베이스에 돌아갈 필요가 없어지는 경우가 많습니다.
Hyperdrive가 없으면 기존 클라우드 공급자의 미국 동부1 지역에 있는 핵심 데이터베이스(사용자 프로필, 제품 인벤토리, 중요한 웹 앱을 실행하는 데이터베이스)는 파리, 싱가포르, 두바이에 있는 사용자가 액세스하는 속도가 매우 느려질 수 있습니다. 로스앤젤레스나 밴쿠버에 있는 사용자에게도 예상보다 느려질 것입니다. 각 왕복 시간이 최대 200ms이므로 연결을 설정하는 데 필요한 몇 번의 왕복 자체만으로도 최대 1초(또는 그 이상!)가 걸리기 쉽습니다. 데이터를 위해 쿼리를 작성하기도 전에도 말입니다. Hyperdrive는 이러한 현상을 해결하기 위해 설계되었습니다.
Hyperdrive의 성능을 선보이기 위해 Cloudflare에서는 데모 애플리케이션을 구축했습니다. 이는 Hyperdrive를 사용한 채로 그리고 사용하지 않은 채로 (바로) 동일한 데이터베이스에 대해 연속되는 쿼리를 작성합니다. 이 앱은 주변 대륙에 있는 데이터베이스를 선택합니다. 여러분이 유럽에 있다면 이는 미국에 있는 데이터베이스를 선택합니다. 많은 유럽 인터넷 사용자가 흔히 겪는 상황입니다. Continue reading


D1 is now in open beta, and the theme is “scale”: with higher per-database storage limits and the ability to create more databases, we’re unlocking the ability for developers to build production-scale applications on D1. Any developers with an existing paid Workers plan don’t need to lift a finger to benefit: we’ve retroactively applied this to all existing D1 databases.
If you missed the last D1 update back during Developer Week, the multitude of updates in the changelog, or are just new to D1 in general: read on.
D1 our native serverless database, which we launched into alpha in November last year: the queryable database complement to Workers KV, Durable Objects and R2.
When we set out to build D1, we knew a few things for certain: it needed to be fast, it needed to be incredibly easy to create a database, and it needed to be SQL-based.
That last one was critical: so that developers could a) avoid learning another custom query language and b) make it easier for existing query buildings, ORM (object relational mapper) libraries and other tools to connect to D1 with minimal effort. From this, we’ve seen a Continue reading
Vectorize is our brand-new vector database offering, designed to let you build full-stack, AI-powered applications entirely on Cloudflare’s global network: and you can start building with it right away. Vectorize is in open beta, and is available to any developer using Cloudflare Workers.
You can use Vectorize with Workers AI to power semantic search, classification, recommendation and anomaly detection use-cases directly with Workers, improve the accuracy and context of answers from LLMs (Large Language Models), and/or bring-your-own embeddings from popular platforms, including OpenAI and Cohere.
Visit Vectorize’s developer documentation to get started, or read on if you want to better understand what vector databases do and how Vectorize is different.
Vector databases are designed to solve this, by capturing how an ML model represents data — including structured and unstructured text, images and audio — and storing it in a way that allows you to compare against future inputs. This allows us to leverage the power of existing machine-learning models and LLMs (Large Language Models) for content they haven’t been trained on: which, given the tremendous cost of training models, turns Continue reading
Over the last couple of months, Workers KV has suffered from a series of incidents, culminating in three back-to-back incidents during the week of July 17th, 2023. These incidents have directly impacted customers that rely on KV — and this isn’t good enough.
We’re going to share the work we have done to understand why KV has had such a spate of incidents and, more importantly, share in depth what we’re doing to dramatically improve how we deploy changes to KV going forward.
Workers KV — or just “KV” — is a key-value service for storing data: specifically, data with high read throughput requirements. It’s especially useful for user configuration, service routing, small assets and/or authentication data.
We use KV extensively inside Cloudflare too, with Cloudflare Access (part of our Zero Trust suite) and Cloudflare Pages being some of our highest profile internal customers. Both teams benefit from KV’s ability to keep regularly accessed key-value pairs close to where they’re accessed, as well its ability to scale out horizontally without any need to become an expert in operating KV.
Given Cloudflare’s extensive use of KV, it wasn’t just external customers impacted. Our own internal teams felt the pain Continue reading
This post is also available in Deutsch, 简体中文, 日本語, Español, Français.
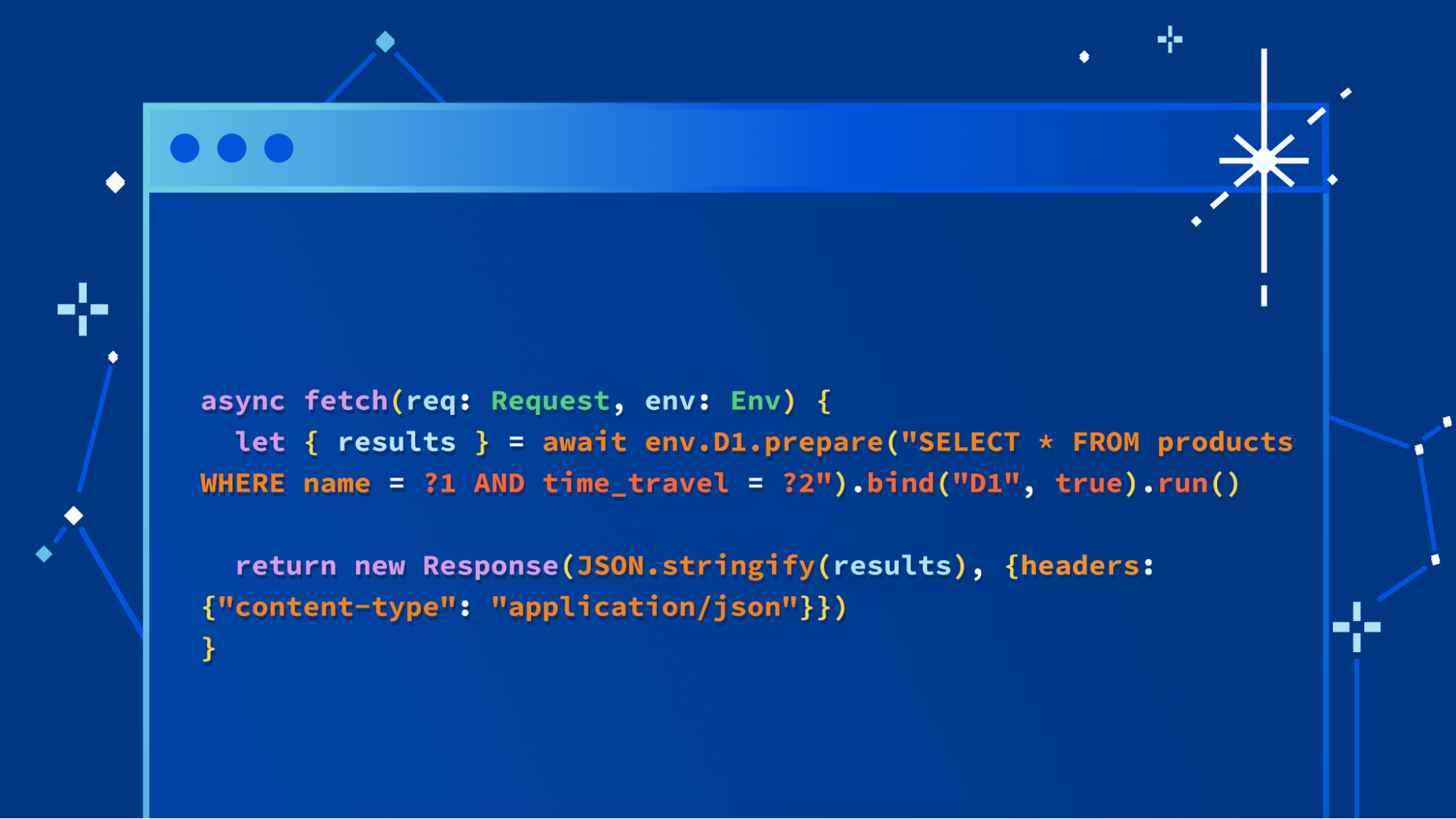
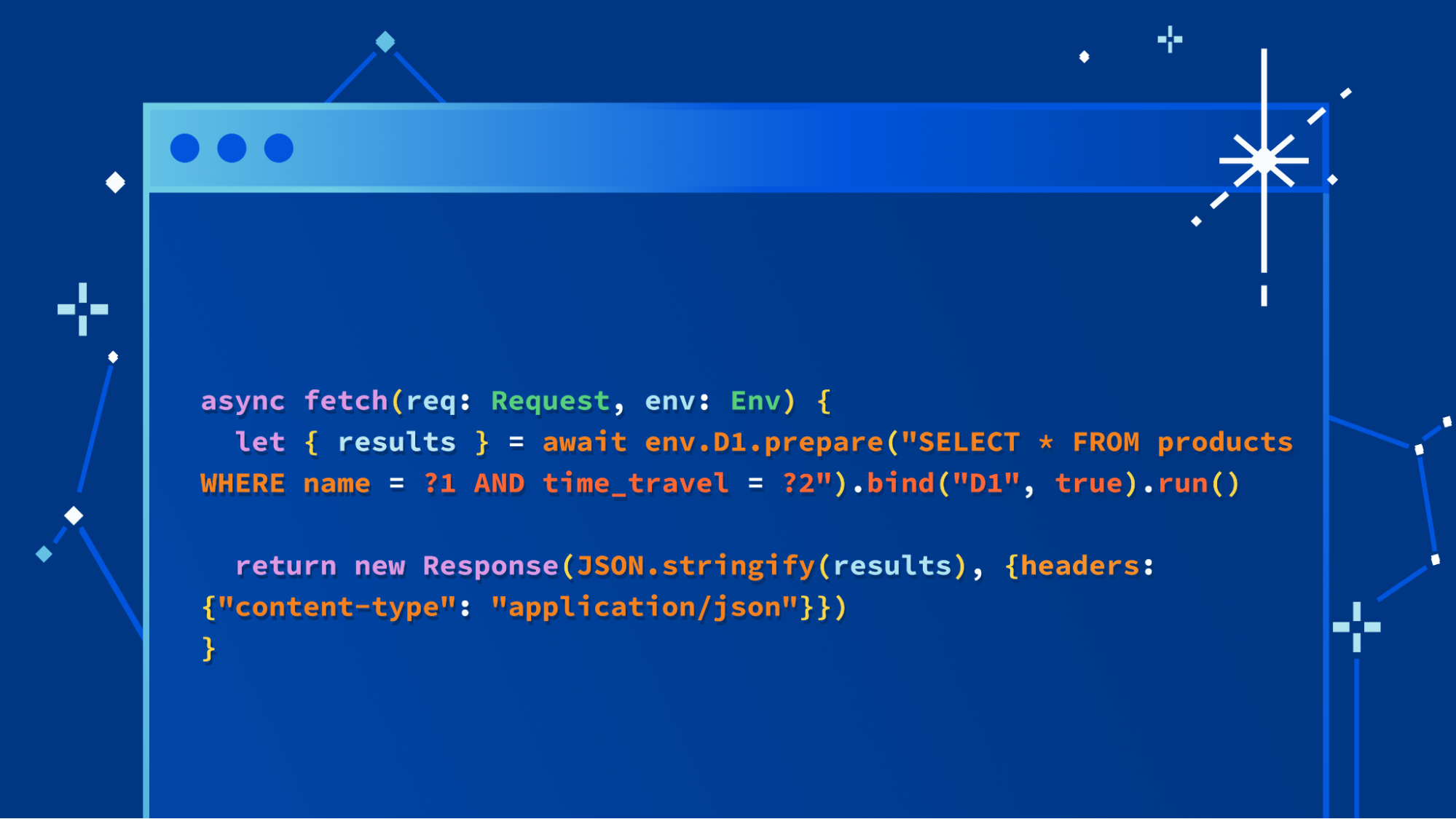
We’re not going to bury the lede: we’re excited to launch a major update to our D1 database, with dramatic improvements to performance and scalability. Alpha users (which includes any Workers user) can create new databases using the new storage backend right now with the following command:
$ wrangler d1 create your-database --experimental-backend
In the coming weeks, it’ll be the default experience for everyone, but we want to invite developers to start experimenting with the new version of D1 immediately. We’ll also be sharing more about how we built D1’s new storage subsystem, and how it benefits from Cloudflare’s distributed network, very soon.
D1 is Cloudflare’s native serverless database, which we launched into alpha in November last year. Developers have been building complex applications with Workers, KV, Durable Objects, and more recently, Queues & R2, but they’ve also been consistently asking us for one thing: a database they can query.
We also heard consistent feedback that it should be SQL-based, scale-to-zero, and (just like Workers itself), take a Region: Earth approach to replication. And so we took that feedback and set Continue reading

This post is also available in Deutsch, Français and Español.

The humble cell phone is now a critical tool in the modern workplace; even more so as the modern workplace has shifted out of the office. Given the billions of mobile devices on the planet — they now outnumber PCs by an order of magnitude — it should come as no surprise that they have become the threat vector of choice for those attempting to break through corporate defenses.
The problem you face in defending against such attacks is that for most Zero Trust solutions, mobile is often a second-class citizen. Those solutions are typically hard to install and manage. And they only work at the software layer, such as with WARP, the mobile (and desktop) apps that connect devices directly into our Zero Trust network. And all this is before you add in the further complication of Bring Your Own Device (BYOD) that more employees are using — you’re trying to deploy Zero Trust on a device that doesn’t belong to the company.
It’s a tricky — and increasingly critical — problem to solve. But it’s also a problem which we think we can help with.
What Continue reading


It’s hard to imagine life without our smartphones. Whereas computers were mostly fixed and often shared, smartphones meant that every individual on the planet became a permanent, mobile node on the Internet — with some 6.5B smartphones on the planet today.
While that represents an explosion of devices on the Internet, it will be dwarfed by the next stage of the Internet’s evolution: connecting devices to give them intelligence. Already, Internet of Things (IoT) devices represent somewhere in the order of double the number of smartphones connected to the Internet today — and unlike smartphones, this number is expected to continue to grow tremendously, since they aren’t bound to the number of humans that can carry them.
But the exponential growth in devices has brought with it an explosion in risk. We’ve been defending against DDoS attacks from Internet of Things (IoT) driven botnets like Mirai and Meris for years now. They keep growing, because securing IoT devices still remains challenging, and manufacturers are often not incentivized to secure them. This has driven NIST (the U.S. National Institute of Standards and Technology) to actively define requirements to address the (lack of) IoT device security, and the EU Continue reading


One of the underlying questions that drives Platform Week is “how do we enable developers to build full stack applications on Cloudflare?”. With Workers as a serverless environment for easily deploying distributed-by-default applications, KV and Durable Objects for caching and coordination, and R2 as our zero-egress cost object store, we’ve continued to discuss what else we need to build to help developers both build new apps and/or bring existing ones over to Cloudflare’s Developer Platform.
With that in mind, we’re excited to announce the private beta of Cloudflare Pub/Sub, a programmable message bus built on the ubiquitous and industry-standard MQTT protocol supported by tens of millions of existing devices today.
In a nutshell, Pub/Sub allows you to:


How do you know the code your web browser downloads when visiting a website is the code the website intended you to run? In contrast to a mobile app downloaded from a trusted app store, the web doesn’t provide the same degree of assurance that the code hasn’t been tampered with. Today, we’re excited to be partnering with WhatsApp to provide a system that assures users that the code run when they visit WhatsApp on the web is the code that WhatsApp intended.
With WhatsApp usage in the browser growing, and the increasing number of at-risk users — including journalists, activists, and human rights defenders — WhatsApp wanted to take steps to provide assurances to browser-based users. They approached us to help dramatically raise the bar for third-parties looking to compromise or otherwise tamper with the code responsible for end-to-end encryption of messages between WhatsApp users.
So how will this work? Cloudflare holds a hash of the code that WhatsApp users should be running. When users run WhatsApp in their browser, the WhatsApp Code Verify extension compares a hash of that code that is executing in their browser with the hash that Cloudflare has — enabling them to easily see Continue reading


For every successful technology, there is a moment where its time comes. Something happens, usually external, to catalyze it — shifting it from being a good idea with promise, to a reality that we can’t imagine living without. Perhaps the best recent example was what happened to the cloud as a result of the introduction of the iPhone in 2007. Smartphones created a huge addressable market for small developers; and even big developers found their customer base could explode in a way that they couldn’t handle without access to public cloud infrastructure. Both wanted to be able to focus on building amazing applications, without having to worry about what lay underneath.
Last year, during the outbreak of COVID-19, a similar moment happened to real time communication. Being able to communicate is the lifeblood of any organization. Before 2020, much of it happened in meeting rooms in offices all around the world. But in March last year — that changed dramatically. Those meeting rooms suddenly were emptied. Fast-forward 18 months, and that massive shift in how we work has persisted.
While, undoubtedly, many organizations would not have been able to get by without the likes of Slack, Zoom and Teams as Continue reading
Cloudflare's Enterprise customers have been using our Load Balancing service since March, and it has been helping them avoid website downtime caused by unreliable hosting providers, Internet outages, or servers. Today, we're bringing Load Balancing to all of our customers.

Even the best caching can't escape the fundamental limitations on performance created by the speed of light. Using Load Balancing, Cloudflare's customers can now route requests between multiple origins, allowing them to serve requests from the closest (and fastest) geographic location.
The Cloudflare Load Balancer automatically sends you notifications when things fail, and when they come back up again, so you can sleep well at night knowing we are keeping your website or API running.
If a DDoS attack can bring down your DNS provider or load balancer, it doesn't matter whether your servers are healthy or not. Our load balancing service runs in Cloudflare's 110+ datacenters, and with experience dealing with some of the largest DDoS attacks, we can withstand traffic volumes that smaller providers, virtual machines or hardware appliances can't. This also allows us to help you avoid business-impacting downtime when major cloud compute providers have issues: when we identify a connectivity reaching your application on AWS, we Continue reading