Author Archives: Todd Hoff
Author Archives: Todd Hoff

This is a guest repost from Christophe Limpalair of his interview with Max Schnur, Web Developer at Wistia.
Wistia is video hosting for business. They offer video analytics like heatmaps, and they give you the ability to add calls to action, for example. I was really interested in learning how all the different components work and how they’re able to stream so much video content, so that’s what this episode focuses on.
As you will see, Wistia is made up of different parts. Here are some of the technologies powering these different parts:
Hey, it's HighScalability time:

If you are very comfortable with math and modeling Dr. Neil Gunther's Universal Scalability Law is a powerful way of predicting system performance and whittling down those bottlenecks. If not, the USL can be hard to wrap your head around.
There's a free eBook for that. Performance and scalability expert Baron Schwartz, founder of VividCortex, has written a wonderful exploration of scalability truths using the USL as a lens: Practical Scalablility Analysis with the Universal Scalability Law.
As a sample of what you'll learn, here are some of the key takeaways from the book:
I noticed on Facebook during this horrible tragedy in Paris that there was some worry because not everyone had checked in using Safety Check. So I thought people might want to know a little more about how Safety Check works.
If a friend or family member hasn't checked-in yet it doesn't mean anything bad has happened to them. Please keep that in mind. Safety Check is a good system, but not a perfect system, so keep your hopes up.
This is a really short version, there's a longer article if you are interested.
How it works:
If you are in an area impacted by a disaster Facebook will send you a push notification asking if you are OK.
Tapping the “I’m Safe” button marks that your are safe.
All your friends are notified that you are safe.
Friends can also see a list of all the people impacted by the disaster and how they are doing.
How do you build the pool of people impacted by a disaster in a certain area? Building a geoindex is the obvious solution, but it has weaknesses.
People are constantly moving so the index will be stale.
A geoindex of 1.5 billion Continue reading
Hey, it's HighScalability time:

As we research and dig deeper into scaling, we keep running into Netflix. They are very public with their stories. This post is a round up that we put together with Bryan’s help. We collected info from all over the internet. If you’d like to reach out with more info, we’ll append this post. Otherwise, please enjoy!
–Chris / ScaleScale / MaxCDN

Hey, it's HighScalability time:

I've been bitten by this one. It happens when you quite naturally use the file system as a quick and dirty database. A directory is a lot like a table and a file name looks a lot like a key. You can store many-to-one relationships via subdirectories. And the path to a file makes a handy quick lookup key.
The problem is a file system isn't a database. That realization doesn't hit until you reach a threshold where there are actually lots of files. Everything works perfectly until then.
When the threshold is hit iterating a directory becomes very slow because most file system directory data structures are not optimized for the lots of small files case. And even opening a file becomes slow.
According to Steve Gibson on Security Now (@16:10) LastPass ran into this problem. LastPass stored every item in their vault in an individual file. This allowed standard file syncing technology to be used to update only the changed files. Updating a password changes just one file so only that file is synced.
Steve thinks this is a design mistake, but this approach makes perfect sense. It's simple and robust, which is good design given, what I assume, Continue reading

Peter Bailis has released the work of a lifetime, his dissertion is now available online: Coordination Avoidance in Distributed Databases.
The topic Peter is addressing is summed up nicely by his thesis statement:
Many semantic requirements of database-backed applications can be efficiently enforced without coordination, thus improving scalability, latency, and availability.
I'd like to say I've read the entire dissertation and can offer cogent insightful analysis, but that would be a lie. Though I have watched several of Peter's videos (see Related Articles). He's doing important and interesting work, that as much University research has done, may change the future of what everyone is doing.
From the introduction:
The rise of Internet-scale geo-replicated services has led to upheaval in the design of modern data management systems. Given the availability, latency, and throughput penalties associated with classic mechanisms such as serializable transactions, a broad class of systems (e.g., “NoSQL”) has sought weaker alternatives that reduce the use of expensive coordination during system operation, often at the cost of application integrity. When can we safely forego the cost of this expensive coordination, and when must we pay the price?
In this thesis, we investigate the potential for coordination avoidance—the Continue reading

This is a guest repost by Christophe Limpalair, creator of Scale Your Code.
In this article, we take a look at methods used by Shopify to make their platform resilient. Not only is this interesting to read about, but it can also be practical and help you with your own applications.
Shopify, an ecommerce solution, handles about 300 million unique visitors a month, but as you'll see, these 300M people don't show up in an evenly distributed fashion.
One of their biggest challenge is what they call "flash sales". These flash sales are when tremendously popular stores sell something at a specific time.
For example, Kanye West might sell new shoes. Combined with Kim Kardashian, they have a following of 50 million people on Twitter alone.
They also have customers who advertise on the Superbowl. Because of this, they have no idea how much traffic to expect. It could be 200,000 people showing up at 3:00 for a special sale that ends within a few hours.
How does Shopify scale to these sudden increases in traffic? Even if they can't scale that well for a particular sale, how can they make sure it doesn't affect Continue reading
Hey, it's HighScalability time:


IEEE Spectrum has a wonderful article series on Lessons From a Decade of IT Failures. It’s not your typical series in that there are very cool interactive graphs and charts based on data collected from past project failures. They are really fun to play with and I can only imagine how much work it took to put them together.
The overall takeaway of the series is:
Even given the limitations of the data, the lessons we draw from them indicate that IT project failures and operational issues are occurring more regularly and with bigger consequences. This isn’t surprising as IT in all its various forms now permeates every aspect of global society. It is easy to forget that Facebook launched in 2004, YouTube in 2005, Apple’s iPhone in 2007, or that there has been three new versions of Microsoft Windows released since 2005. IT systems are definitely getting more complex and larger (in terms of data captured, stored and manipulated), which means not only are they increasing difficult and costly to develop, but they’re also harder to maintain.
Here are the specific lessons:

Are there ideas in IT that must die for progress to be made?
Max Planck wryly observed that scientific progress is often less meritocracy and more Lord of the Flies:
A new scientific truth does not triumph by convincing its opponents and making them see the light, but rather because its opponents eventually die, and a new generation grows up that is familiar with it.
Playing off this insight is a thought provoking book collection of responses to a question posed on the Edge: This Idea Must Die: Scientific Theories That Are Blocking Progress. From the book blurb some of the ideas that should transition into the postmortem are: Jared Diamond explores the diverse ways that new ideas emerge; Nassim Nicholas Taleb takes down the standard deviation; Richard Thaler and novelist Ian McEwan reveal the usefulness of "bad" ideas; Steven Pinker dismantles the working theory of human behavior.
Let’s get edgy: Are there ideas that should die in IT?
What ideas do you think should pass into the great version control system called history? What ideas if garbage collected would allow us to transmigrate into a bright shiny new future? Be as deep and bizarre as you want. This is Continue reading
Hey, it's HighScalability time:
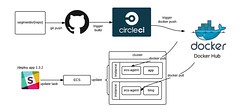
This is a guest repost from Calvin French-Owen, CTO/Co-Founder of Segment.
In Segment’s early days, our infrastructure was pretty hacked together. We provisioned instances through the AWS UI, had a graveyard of unused AMIs, and configuration was implemented three different ways.
As the business started taking off, we grew the size of the eng team and the complexity of our architecture. But working with production was still limited to a handful of folks who knew the arcane gotchas. We’d been improving the process incrementally, but we needed to give our infrastructure a deeper overhaul to keep moving quickly.
So a few months ago, we sat down and asked ourselves: “What would an infrastructure setup look like if we designed it today?”
Over the course of 10 weeks, we completely re-worked our infrastructure. We retired nearly every single instance and old config, moved our services to run in Docker containers, and switched over to use fresh AWS accounts.
We spent a lot of time thinking about how we could make a production setup that’s auditable, simple, and easy to use–while still allowing for the flexibility to scale and grow.
Here’s our solution.
Hey, it's HighScalability time:


Looking at https://tools.ietf.org/html/rfc1323 there is a nice title: 'TCP Extensions for High Performance'. It's worth to take a look at date May 1992. Timestamps option may appear in any data or ACK segment, adding 12 bytes to the 20-byte TCP header.
Using TCP options, the sender places a timestamp in each data segment, and the receiver reflects these timestamps back in ACK segments. Then a single subtract gives the sender an accurate RTT measurement for every ACK segment.
To prove this let's dig into kernel source:
./include/net/tcp.h:#define TCPOLEN_TSTAMP_ALIGNED 12
./net/ipv4/tcp_output.c:static void tcp_connect_init(struct sock *sk)
...
tp->tcp_header_len = sizeof(struct tcphdr) +
(sysctl_tcp_timestamps ? TCPOLEN_TSTAMP_ALIGNED : 0);



